Технология FRF.11 базируется на стандартах МСЭ (Международного Союза Электросвязи) и ANSI, определяющих форматы кадров, сигнализации и кодирования голоса. Изюминкой соответствующих спецификаций является формат «подкадра», который позволяет упаковать в один кадр несколько сессий передачи голоса или данных. Каждый кадр, согласно технологии ретрансляции кадров, содержит или множество подкадров одного диалога, или один кадр из нескольких логических каналов, или то и другое одновременно. Подкадр может состоять из любой цифровой информации — данных или голоса.
Объединение трафика по одному идентификатору канала передачи данных (Data Link Connector Identifier, DLCI) — номеру виртуального канала frame relay — исключает необходимость в дополнительном DLCI. Соответственно, упрощается работа магистрали: для связи конфигурируется только один виртуальный канал frame relay, и число подлежащих обработке кадров существенно сокращается. Это весьма важно, так как коммутаторы часто переполняются пакетами (т.е. начинают получать максимальное число пакетов, которое они способны обработать за секунду) раньше, чем они достигают предела своей пропускной способности, измеряемой в бит/с.
Но у технологии FRF.11 есть и недостатки. Создание одного голосового потока из многих подкадров приводит к увеличению как времени их накопления, так и времени задержки, связанной с подтверждением приема, что ведет к ухудшению качества голосового сигнала. Альтернативное решение — посылать кадры через короткие временные интервалы, заполняя их любыми подкадрами, готовыми к данному моменту. Такой подход позволяет свести искажения сигнала к минимуму.
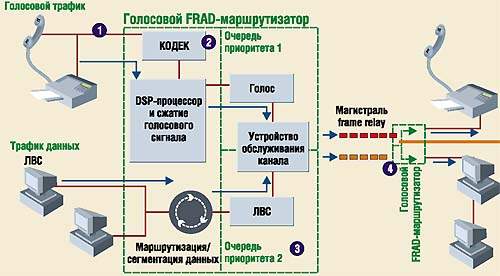
Для передачи голоса его необходимо преобразовать (закодировать) в цифровой формат. В качестве аналогового интерфейса для телефонов и УПАТС используются небольшие устройства доступа frame relay (FRAD) и маршрутизаторы. Аналого-цифровое преобразование выполняется этими устройствами за счет кодирования/декодирования с помощью КОДЕКа. Вначале КОДЕК преобразует голос в поток битов с импульсно-кодовой модуляцией (PCM) полосой 64 кбит/с — в стандартный голосовой формат коммутируемых телефонных сетей общего пользования. Однако наиболее часто услуги доступа по каналу frame relay предоставляются на скорости 56 кбит/с. Поэтому, как правило, устройства FRAD производят дополнительное сжатие голосового потока с импульсно-кодовой модуляцией.
Качество передачи голоса в большой степени определяется алгоритмом сжатия, который применяется в чипе цифрового сигнального процессора. В устройствах, реализующих стандарт FRF.11, используется алгоритм CELP (определен в рекомендациях G.729 МСЭ), который обеспечивает хорошее качество передачи голоса.
На каждом голосовом маршруте образуется отдельный поток подкадров, каждый из которых, в свою очередь, промаркирован собственным идентификатором канала, указывающим его «происхождение». Другими словами, идентификатор свидетельствует, является ли этот подкадр фрагментом активной речи, последним пакетом перед прекращением передачи (для минимизации полосы частот за счет сокращения пауз), факсимильным сообщением или информацией, сопровождающей передачу (сигнализацией).
Сигнализация для тонального и импульсного набора формируется по-разному. При тональном наборе номера с разделением частот (DTMF) сигнальный процессор в режиме сжатия выделяет пары звуковых частот и преобразует их в коды, которые указывают на номер нажатой кнопки, время начала и прекращения звукового сигнала. При импульсном наборе проверяется наличие входного аналогового сигнала, определяющего закрытое/открытое состояние коммутатора, т.е. наличие импульсов набора. Этот алгоритм позволяет получить очень точную картину происходящего на стороне отправителя сигнала. Кроме того, в нем весьма просто реализуется передача статуса сигнала: ответ абонента или отбой.
В процессе вызова на вызывающей стороне непрерывно генерируются подкадры сигнализации, заменяющие речь на пакеты. Чтобы избежать потери кадров, каждый интервал передачи сигнальной информации разбивается на три последовательных подкадра с перекрытием их содержания. Раздельная передача голоса и сигнализации исключает неверную интерпретацию передаваемой речи.
При передаче факсов используется тот же формат подкадров. Но это не означает, что кодирование выполняется точно так же. В речевых устройствах FRAD предусмотрено переключение сигнального процессора с режима сжатия голоса на режим факс-модема. В пакеты помещаются оригинальные данные, отсканированные до их передачи по модему. При использовании факсимильных аппаратов, работающих на скорости 9600 бит/с, при передаче по каналу frame relay пропускная способность будет чуть выше 10 кбит/с.
Подкадры данных содержат сегменты любого протокола, который посылается на FRAD терминальным оборудованием. Заголовки подкадра указывают начало, продолжение и конец блока данных. При объединении телефонии и передачи данных можно выбрать такой размер подкадра, который позволяет минимизировать искажения речевых пакетов, возникающие в результате задержки речевых кадров при их передаче после кадров с данными. Однако следует отметить, что в реализациях FRF.11 приоритет чаще всего отдается речевым пакетам, а не пакетам данных.
ОБ АВТОРЕ
Уильям Фленаган, директор по ПО компании NetReference. С ним можно связаться по электронной почте flanagan@netreference.com|
Главное преимущество технологии FRF.11 состоит в том, что она определяет способ упаковки в один кадр множества сессий любого типа. При передаче голоса по сетям frame relay не только снижается стоимость стандартного вызова, но и более эффективно используются сети с ретрансляцией кадров |
Трудности конвергенции
Многие специалисты в области вычислительных сетей, услышав разговор о слиянии служб передачи голоса и данных, вспоминают о таких приложениях, как интегрированные системы отправки электронных сообщений, Web-сайты с возможностями передачи речи или службы хранения и пересылки факсимильных сообщений. Однако большая часть этих приложений была разработана для существующих инфраструктур на базе IP-протоколов передачи данных, которые (после незначительных инженерных доработок сетевого оборудования и качества сервиса) позволяют передавать по одной сети голос, факсимильные и/или видеосигналы при незначительных дополнительных расходах. Но возможна ли конвергенция в территориально-распеределенных сетях, где используются технология frame relay или ATM? Ответ на этот вопрос будет положительным при условии, что сетевой специалист сумеет основательно разобраться во всех этапах прохождения голосового сигнала. Для кодирования и формирования пакетов телефонии необходим большой объем обработки сигнала. Он не зависит от системы транспортировки, так как операции, которые нужно выполнить над голосовым трафиком, совершаются задолго до его «соприкосновения» с интерфейсом территориально-распределенной сети. Львиную долю этих функций берет на себя расположенный в VoIP-шлюзе чип цифрового сигнального процессора (DSP), обычно встраиваемый в цифровую УПАТС. Поступающий в шлюз аналоговый сигнал обрабатывается, делится на пакеты (кадры, ячейки), а затем отправляется в далекое путешествие по распределенной сети. Множество алгоритмов DSP, управляющих этим процессом, создавалось в соответствии с высокими требованиями пользователей к надежности и качеству передачи голоса. И естественно, что при передаче голоса в сетях frame relay или ATM пользователи рассчитывают на те же качество и надежность, что и в коммутируемых телефонных сетях общего пользования. При пересылке пакетов голосового сигнала, независимо от типа распределенной сети, возникают следующие технические задачи:
Если все эти задачи решены и аналоговый сигнал прошел обработку, можно считать, что главная работа выполнена. Остается лишь транспортировать сигнал на физическом уровне в территориально-распределенную сеть, для чего необходимо задать такт передачи битов, установки для телефонных вызовов (соединений и отключений), а также обеспечить перевод телефонных номеров в сетевые адреса, например в идентификаторы DLCI сети frame relay. Только на данном этапе имеют значение элементы технологий frame relay и ATM, которые определены в спецификациях, разработанных Frame Relay Forum и ATM Forum. Так, первая из рабочих групп выработала документ «Соглашение о реализации передачи голоса поверх frame relay», определяющий параметры транспортировки сжатого голосового сигнала по сети frame relay, возможные алгоритмы сжатия, сигнальную информацию об установке и разъединении вызова, способы передачи цифр при наборе номера и отправки факсимильных данных. Этот документ содержит спецификации, реализуемые голосовыми устройствами доступа frame relay (VFRAD), которые обычно размещаются между УПАТС и сетью frame relay. ATM Forum разработал аналогичный документ «Передача речевых сигналов и телефоннии поверх ATM до настольного компьютера». В нем определены функции ATM-терминала, межсетевого взаимодействия сетей различных типов (например, B-ISDN (ATM) и N-ISDN), а также параметры сигнала, качества сервиса и т.п. Вопрос состоит в том, скоро ли интегрированная передача голоса, данных, факсимильных сообщений и видеосигналов по обычным территориально-распределенным сетям встанет на «промышленную» основу. Поскольку эти сети создавались в основном для передачи данных, то естественно, что их главная задача — передавать трафик как можно большего объема. В то же время рост интереса к передаче голоса по WAN в значительной мере способствует появлению усовершенствованных алгоритмов кодирования голоса и средств, позволяющих улучшить сервис. Вероятно, все это сделает передачу голосового сигнала поверх кадров или ячеек реальностью, и весьма скоро. Марк МИЛЛЕР |