
Сети хранения данных часто образуют костяк важных для предприятия приложений. Поэтому очень многое зависит от безупречной работы SAN и ее постоянной готовности. При помощи мониторинга SAN можно быстро обнаружить и проанализировать ошибки в сети хранения, но хорошее «здоровье» SAN требуется подтвердить, поскольку часто причины падения производительности нужно искать совершенно в других местах.
Понятие мониторинга сети хранения данных часто наполняется совершенно разным содержанием и потому приводит к недоразумениям. Чаще всего путаница возникает между понятиями «управление ресурсами SAN» и «мониторинг SAN». Управление ресурсами SAN, т. е. установка и оптимизация компонентов и наблюдение за ними, осуществляется при помощи соответствующих инструментов конкретного производителя. Главные задачи системы мониторинга — контроль за достижением ожидаемой производительности, опережающее исправление ошибок, рациональная поддержка при локализации и анализе ошибок и, конечно, доказательство работоспособности сети.
Отсюда следуют самые важные и самые сложные требования к мониторингу SAN: совместная работа с компонентами SAN всех производителей и их простое включение, возможность сохранения детализированной информации о состоянии сети хранения в базе данных, а также предоставление и оценка этих дан-ных в соответствии с задачами управления. Дополнительными требованиями являются автоматическая подача сигналов тревоги при превышении граничных значений, а также запись сведений о происходящем в случае возникновения ошибки в SAN. Мониторинг существенно помогает администратору SAN в решении следующих вопросов:
- организации бесперебойной работы SAN;
- быстрого поиска ошибки и ее изоляции в случае возникновения проблемы в сети.
ДОКАЗАТЕЛЬСТВО ХОРОШЕЙ ПРОИЗВОДИТЕЛЬНОСТИ SAN
Часто администраторы SAN попадают в ситуацию, когда им приходится доказывать, что причина слишком медленной работы приложения кроется отнюдь не в SAN. Мониторинга трафика данных в мегабайтах и нагрузки на канал в этом случае недостаточно. Проблемы с производительностью могут быть обусловлены архитектурой программного обеспечения или неудачным расположением серверов приложений. Отслеживания ошибок на коммутаторе также недостаточно, поскольку нередко они появляются без види-мой причины. Однако мониторинг сети хранения данных предлагает различные возможности для доказательства ее правильной работы.
Так, сбор параметров производительности SAN может показать, что сеть функционирует как прежде, хотя работа приложения замедлилась. Система мониторинга SAN обязана, таким образом, следить за специальными параметрами, не связанными с производительностью сервера приложений. В принципе при чтении данных в SAN время отклика должно быть постоянным и не зависеть от состояния приложения или сервера, а глубина очереди операций ввода/вывода не должна достигать значений, превышающих емкость системы хранения. Когда администратор SAN получает жалобы по поводу скорости работы приложений, но не обнаруживает изменений во времени отклика при чтении данных, он может быть уверен, что проблема заключается не в падении производительности SAN.
Кроме того, сбор параметров производительности SAN за продолжительный период и их сравнение предоставляют доказательства соблюдения ожидаемого уровня сервиса SAN. Чтобы подтверждение адекватной работы SAN не вызывало затруднений, необходимы автоматические отчеты. Если в пределах подразделения предприятия какое-либо приложение работает медленно, сравнение ретроспективных данных с текущей информацией помогает в нахождении причины ошибки.
Моментальный обзор статуса здоровья SAN предоставляет «приборная панель» с актуальной информацией мониторинга, информируя о состоянии SAN в простом графическом представлении (см. Рисунок 1). Отображение протекающих процессов между серверами и системами хранения, включая нагрузку в процентах, доступ для чтения и записи, а также превышение граничных значений будут, несомненно, полезны для администратора SAN. Современные инструменты мониторинга сигнализируют об отказах в форме семафора и немедленно предлагают возможности детализации для определения источника ошибки.
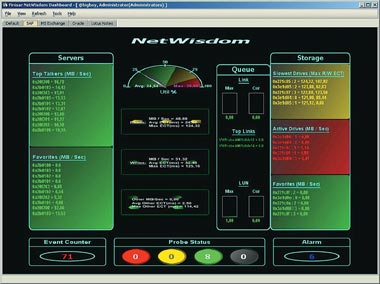
|
| Рисунок 1. Пример отображения статуса на приборной панели системы мониторинга SAN. |
БЫСТРЫЙ АНАЛИЗ ОШИБОК
Условием точного анализа ошибок в сети хранения данных является сбор данных. Он производится посредством программных средств, собирающих сведения от подключенных устройств, к примеру при помощи простого протокола управления сетью (Simple Network Management Protocol, SNMP) и спецификации интерфейса управления хранилищами (Storage Management Interface Specification, SMI-S). Альтернатива им представляют аппаратные зонды, принимающие всю информацию в реальном времени по Fibre Channel и оценивающие ее. Этот подход более точен и исключает возникновение новых ошибок вследствие несовместимости или перегрузок. Важное значение имеют гибкие возможности настройки оповещения для своевременного получения информации об аномалиях и изменениях. Для этого необходимо определить базовые характеристики производительности. Многие администраторы SAN мало что знают о «нормальной» производительности своей сети. В таком случае система мониторинга предлагает безопасность и прозрачность.
Программные зонды позволяют проводить пассивный сбор статичных данных непосредственно из коммутаторов. Кроме того, агрегирование статистики коммутаторов во всей SAN дает исчерпывающий обзор производительности и тенденций. Так, пользователь сможет без проблем идентифицировать отклонение от обычного потока трафика в сети хранения. При этом необходимо сохранять статистику со всех коммутаторов, чтобы совместно с данными аппаратных зондов определить пропускную способность всей сети, а также показатели ввода/вывода и ошибки. При мониторинге выявляются такие ошибки, как неправильная сумма CRC, сброс и отказ канала, потеря сигнала, нарушение синхронизации или отбракованные пакеты. Полученная при помощи программных методов информация служит для проверки планирования емкости и определения соответствующей нагрузки на систему.
АППАРАТНЫЕ ЗОНДЫ
Аппаратные зонды — это специальные сборщики данных, которые при помощи пассивной тестовой точки доступа (Test Access Point, TAP) получают информацию непосредственно из канала Fibre Channel (см. Рисунок 2).
Пассивное снятие данных гарантирует, что производительность сети не изменится и не появятся новые источники ошибок. Лишь аппаратный метод благодаря прозрачному доступу предоставляет независимый от производителя обзор производительности в пределах коммутирующей инфраструктуры.
По сравнению с программным методом аппаратный обеспечивает детальное обследование SAN и извлечение параметров, которые опрос коммутаторов предоставить не может. Так, только аппаратный зонд позволяет осуществлять «полный мониторинг со скоростью линии», детализированные измерения времени транзакций приложений, получение информации о глубине очереди и определение времени отклика. Доступные на рынке устройства отслеживают около 40 параметров, включая подробную информацию о вводе/выводе, событиях, ошибках и «незавершенных диалогах», причем они следят за параметрами каждого «инициатора» (обычно адаптер главной шины сервера), каждой «цели» (обычно хранилище) и каждого логического устройства. Помимо детализированной информации о вводе/выводе, чтении, записи и замены поступают и другие данные — о производительности. В целом количество описаний достигает 300.
Поскольку ответвление световых сигналов в SAN происходит пассивно, оценке доступна даже информация SCSI, причем для нее можно задать граничные значения. Она предоставляет важные значения времени отклика и не ограничивается лишь параметрами хранилища или коммутатора. Таким образом измеряется производительность сети хранения данных в целом и оценивается для каждого приложения в отдельности. Мониторинг делает возможным и подтверждение проблем с приложениями. Как правило, при использовании аппаратного зонда под наблюдение попадают порты хранения и каналы между коммутаторами (Inter-Switch Link, ISL). Это наиболее критичные места в отношении готовности и отказоустойчивости, к тому же именно здесь сосредоточена важнейшая информация.
АНАЛИЗ ОШИБОК НА ПРИМЕРЕ ИЗ ПРАКТИКИ
Как же можно установить причины падения производительности путем использования системы мониторинга SAN? Вот типичный пример.
В компании с офисами по всему ми-ру в одном центре обработки данных работают более 800 разработчиков. Для доступа к приложениям и данным они обращаются к центральной сети SAN. Без видимого повода скорость приложения уменьшается настолько, что в службу технической поддержки начинают поступать жалобы.
Сетевой отдел и администраторы приложений и серверов начинают проверять свои системы для выявления причин падения производительности, однако ничего толком установить не могут. В области SAN с помощью специфических для производителя инструментов удается выяснить, что реальное снижение производительности достигает двух третей.
После тщательного анализа и длительного поиска решено интегрировать в систему мониторинга SAN. Порты хранения оснастили оптическими разветвителями и при помощи зондов стали вести полномасштабное наблюдение. Через несколько часов система предложила простое и прозрачное представление ошибки: новый программный агент на некоторых серверах генерирует постоянное переключение между избыточными соединениями Fibre Channel и тем самым вызывает проблемы с производительностью.
ЗАКЛЮЧЕНИЕ
Мониторинг сетей хранения данных становится все более важной темой для администраторов SAN. Профессиональное наблюдение за работой сети и автоматизированное подтверждение ее «здоровья» — требования более чем актуальные. Комбинация программного и аппаратного методов делает постоянный мониторинг эффективным и недорогим, а исчерпывающие возможности оповещения, отчеты и записи автоматизируют оптимизацию SAN и уход за ней.
Томас Брандт — сотрудник компании Menatnet Trade. С ним можно связаться по адресу: pf@lanline.awi.de.
? AWi Verlag