

 Изначально графические процессорные устройства (Graphical Processor Unit, GPU) не предназначались для высокопроизводительных вычислений. Задачей GPU первого поколения, получивших благодаря компьютерным играм широкое распространение в середине 90-х годов, было построение в реальном времени изображений по описанию трехмерных сцен. Для этого требовалась быстрая однородная обработка большого количества элементов (вершины, треугольники, пикселы), которая достигалась, прежде всего, за счет аппаратной реализации основных алгоритмов.
Изначально графические процессорные устройства (Graphical Processor Unit, GPU) не предназначались для высокопроизводительных вычислений. Задачей GPU первого поколения, получивших благодаря компьютерным играм широкое распространение в середине 90-х годов, было построение в реальном времени изображений по описанию трехмерных сцен. Для этого требовалась быстрая однородная обработка большого количества элементов (вершины, треугольники, пикселы), которая достигалась, прежде всего, за счет аппаратной реализации основных алгоритмов.
Первые возможности программирования появились в 2001 году в GPU второго поколения. Программы, выполняемые на GPU, стали называться «шейдерами» (от английского shade— «закрашивать»), и основным их назначением было вычисление цвета пиксела на экране. Тогда же стали предприниматься первые попытки использования GPU для общих вычислений, однако из-за низкой точности вычислений, составлявшей лишь 16 бит в формате с фиксированной запятой, и ограниченных возможностей программирования— длина шейдера не превышала 20 команд— это не получило распространения. Ситуация изменилась с появлением в 2003 году серии nVidia GeForce FX, предоставившей поддержку полноценной 32-разрядной вещественной арифметики. Тогда же был предложен термин «общие вычисления на GPU» (General Purpose GPU, GPGPU). Графические процессоры начали активно применяться для решения задач математической физики, обработки изображений и матричных вычислений.
GPU первого поколения— GeForce 6, GeForce 7, ATI Radeon X1K и более поздние— еще больше расширили возможности программирования за счет введения дополнительных команд управления, в частности поддержки полноценных циклов.
Все это время основным средством программирования GPU оставались интерфейсы трехмерной графики DirectX и OpenGL, а также шейдерные языки HLSL, GLSL и Cg. Последние представляют собой модифицированный язык Cи, из которого выброшены массивы и указатели, добавлены специфические для GPU типы данных и встроенные переменные, а также введены некоторые ограничения, в частности запрет на рекурсию. И хотя сам шейдер пишется на них довольно просто, программа для GPU состоит не только из него. Для решения на GPU реальной задачи обрабатываемые данные необходимо представить в виде двухмерных массивов— текстур, загрузить и скомпилировать сам шейдер, установить его параметры и выходные буферы, что делается на основном процессоре, и только после этого исполнить шейдер, «нарисовав квадрат» по размеру выходного буфера. Подобные действия не вызывают вопросов у программиста трехмерной графики, но совершенно непривычны для прикладного программиста, что и сдерживало развитие GPGPU. Требовались средства программирования более высокого уровня, и, конечно же, они были созданы, но прежде посмотрим на скрытые в архитектуре возможности современных GPU, позволяющие говорить о сходстве графических процессоров и суперкомпьютеров.
Архитектура графических процессоров
Современные GPU третьего поколения, такие как nVidia GeForce 8, nVidia GeForce 9, AMD HD 2K и AMD HD 3K, содержат набор одинаковых вычислительных устройств— «потоковых процессоров» (ПП), работающих с общей памятью GPU (видеопамять). Число ПП меняется от четырех до 128, размер видеопамяти может достигать 1 Гбайт. Все ПП синхронно исполняют один и тот же шейдер, что позволяет отнести GPU к классу SIMD (Single Instruction, Multiple Data). За один проход, являющийся этапом вычислений на GPU, шейдер исполняется для всех точек двухмерного массива. Система команд ПП включает в себя арифметические команды для вещественных и целочисленных вычислений с 32-разрядной точностью, команды управления (ветвления и циклы), а также команды обращения к памяти. GPU выполняют операции только с данными на регистрах, число которых может достигать 128. Из-за высоких задержек (до 500 тактов) команды доступа к оперативной памяти выполняются асинхронно. С целью скрытия задержек в очереди выполнения GPU может одновременно находиться до 512 потоков, и, если текущий поток блокируется по доступу к памяти, на исполнение ставится следующий. Поскольку контекст потока полностью хранится на регистрах GPU, переключение осуществляется за один такт— за эту операцию отвечает диспетчер потоков, который не является программируемым.
Тактовые частоты GPU ниже, чем у обычных процессоров, и лежат в диапазоне от 0,5 до 1,5 ГГц, однако благодаря большому количеству потоковых процессоров производительность GPU весьма значительна. Современные GPU верхнего ценового сегмента имеют пиковую производительность 200-500 GFLOPS, что в сочетании с возможностью установки в одну машину двух графических карт позволяет получить пиковую производительность в 1 TFLOPS на одном персональном компьютере. Более того, на некоторых реальных задачах достигается до 70% пиковой производительности. Одновременно с этим, в сравнении с классическими кластерными системами, GPU обладают значительно лучшими характеристиками как по цене (менее 1 долл. на GFLOPS), так и по энергопотреблению (менее 1 Вт на GFLOPS).
nVidia GeForce 8
Архитектура GPU семейства nVidia GeForce 8 представлена на рис. 1. Вообще говоря, она не является классическим представителем архитектур SIMD. В ней 128 ПП объединены в SIMD-группы по 16 мультипроцессоров (МП), но при этом разные МП работают независимо друг от друга, хотя и исполняют один и тот же шейдер. Каждый ПП является суперскалярным устройством и может выполнять до двух команд за такт. При обращении в видеопамять ему доступна вся память, как на чтение, так и на запись. Однако на практике ввиду слабости средств синхронизации между различными МП желательно процесс обработки строить так, чтобы адреса записи не пересекались.

В GeForce 8 программисту доступны 16 Кбайт явно адресуемой статической памяти на мультипроцессоре, которая используется совместно всеми ПП одного мультипроцессора, имеющего внутри механизм барьерной синхронизации потоков. Заметим, что грамотное использование статической памяти как раз и является ключом к написанию эффективных программ для данной архитектуры.
В 2007 году компания nVidia начала производство аппаратных решений на основе GPU, специально ориентированных на выполнение вычислительных задач. Эта серия называется Tesla и включает в себя конфигурации на основе одной, двух и четырех графических карт. Последняя предназначена для установки в серверные системы.
Архитектура GeForce 8 достаточно популярна в сообществе GPGPU, и причина этого— интерфейс программирования CUDA (C Unified Driver Architecture). В nVidia первыми обеспечили возможность написания полных программ на диалекте языка Cи. Это означает, что на этом языке можно одновременно писать код, исполняемый на графическом процессоре, и код, исполняемый на центральном процессоре, и все это в рамках одного проекта. Язык Cи был расширен дополнительными квалификаторами памяти и функций для представления статической памяти и шейдеров соответственно. И хотя остался ряд ограничений, например отсутствие рекурсии на GPU, и программирование перемещения данных по-прежнему лежит на разработчике, язык впервые позволил программировать на GPU в терминах, понятных обычным программистам.
Безусловно, такое решение нельзя считать идеальным. Во-первых, CUDA-программы исполняются только на графических процессорах от nVidia и не могут быть перенесены на другие архитектуры. Во-вторых, CUDA, как и Cи,— это низкоуровневое средство программирования, и для написания эффективных программ необходимо хорошо понимать архитектуру GPU nVidia.
Современные GPU компании AMD, представленные сериями HD 2K и HD 3K, больше похожи на традиционные GPU, чем продукты nVidia. Общая схема их организации представлена на рис. 2.
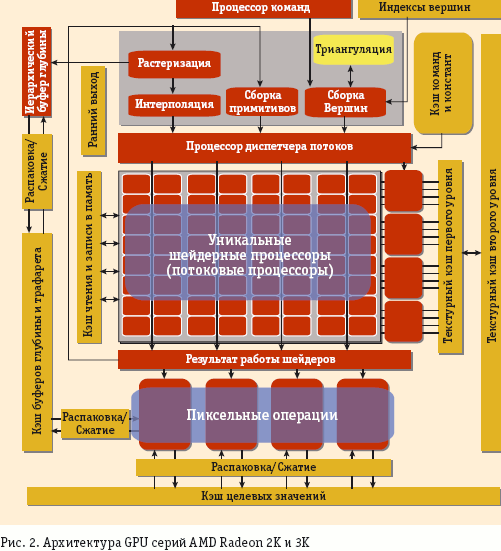
AMD FireStream
В отличие от nVidia, потоковый процессор AMD имеет архитектуру с длинным командным словом. Один ПП содержит шесть функциональных устройств (ФУ), из которых одно отвечает за команды перехода, четыре — за обычные арифметические команды и еще одно — за вычисление элементарных функций (log, sin и т.д.). Арифметические ФУ способны выполнять до двух команд за такт, а ФУ, вычисляющее элементарные функции,— одну. Таким образом, один такой ПП способен выполнять до восьми команд за такт, что больше, чем у nVidia.
При рассмотрении данной архитектуры можно в первом приближении ограничиться только командами, задающими одну и ту же операцию для четырех арифметических ФУ. Это тем более логично, что обмен данными с памятью идет в терминах 128-битовых единиц, а это равно четырем 32-разрядным словам. С этой точки зрения ПП от AMD похож на один элемент SPE (Synergistic Processing Element) процессора Cell или ядро x86-процессора с расширениями SSE2.
Доступ к памяти на чтение возможен через один из 32 сегментных регистров, каждый из которых адресует двухмерный участок памяти, содержащий до 8192*8192 элементов (один элемент = 128 бит). В отличие от nVidia, GPU «в исполнении» AMD предоставляют два режима записи. В режиме регулярной записи шейдер может записать по одному элементу в каждый из выходных буферов, при этом индекс элемента в буфере жестко задан. В режиме произвольной записи доступен только один буфер, зато запись может производиться по произвольному адресу. Средства синхронизации отсутствуют.
Серия GPU от AMD, ориентированная на высокопроизводительные вычисления, носит название FireStream. В отличие от nVidia, в AMD ориентируются только на производство графических карт, оставляя дизайн решений партнерам. Заметим, что в FireStream 9170 впервые появилась поддержка вычислений с двойной точностью, при этом пиковая производительность составляет 100 GFLOPS.
AMD первой обратила внимание на GPGPU, выпустив инструментарий низкоуровневого доступа, библиотеку DPVM (Data-Parallel Virtual Machine). В отличие от CUDA подобные средства скорее являются промежуточным звеном во взаимодействии средств более высокого уровня с GPU.
DPVM представляла GPU на двух уровнях— уровне отдельных шейдеров (они описывались на шейдерном языке PS 3.0 или на ассемблере AMD) и уровне последовательности команд, который отвечал за установку параметров и адресов, работу с кэшем и исполнение шейдера. Сама DPVM предоставляла только два библиотечных вызова: запуск последовательности команд и ожидание его завершения. Средств управления памятью в библиотеке не было. При этом была доступна вся видеопамять, а также память порта PCI-Express. Несмотря на отсутствие развитого языка для написания шейдеров, DPVM давала простой и понятный интерфейс доступа, который позволил ускорить ряд операций, например, умножение матриц, на порядок. По непонятным причинам, от него было решено отказаться. Современная версия библиотеки, CAL (Compute Abstraction Layer), поддерживает несколько GPU и возможность быстрого обмена, однако более сложна в применении и по-прежнему позволяет использовать только шейдерные языки, что, вероятно, и объясняет ее невысокую популярность.
Технологии программирования графических процессоров
Подход потокового программирования, в котором алгоритм разбивается на процессы, выполняющие в конвейере относительно простые операции над элементами данных, известен еще со времен ранних версий ОС Unix. В контексте GPGPU он начал активно использоваться в связи с небольшими размерами шейдера и ограничениями на возможности чтения из памяти на GPU второго поколения. После разбиения задачи на ядра каждое из них реализовывалось в виде шейдера, а в роли потоков данных выступали текстуры. Этот подход позволял перенести управляющую логику на центральный процессор, оставив на GPU основной объем вычислений.
Изначально для реализации идей потокового программирования использовались языки OpenGL или DirectX. В 2003 году появился Brook— первый язык, который позволил писать на GPU полноценные программы, а не только шейдеры. Он опирается на язык Cи, расширенный типом данных двумерных массивов в памяти GPU и некоторыми операциями для работы с ними. Данный язык использовался в ряде проектов в Стэнфордском университете, но изначально не получил широкого распространения. Ситуация изменилась, когда в AMD решили использовать Brook как свой ответ на CUDA и продвигать его в качестве языка программирования собственных GPU. И хотя в некоторых отношениях, например, при работе с памятью, Brook более удобен, чем CUDA, он требует хорошего знания архитектуры GPU от AMD.
Основной трудностью в программировании ПЗГ была необходимость использовать два языка: один для написания основной программы, и еще один— для шейдеров. Поэтому логичным шагом было предоставление программистам возможности писать ядра на знакомых им языках или их подмножестве. В этом направлении выделилось два типа систем программирования.
Метапрограммирование в C++. Программисту дается набор дополнительных стандартных типов данных и макросов, представляющих конструкции управления на GPU. Макросы преобразуют текст языка в строку, которая подается на вход системе времени исполнения. По этой строке система генерирует шейдер, исполняемый на GPU. Данный подход удобен тем, что не требует создания новых языков или интегрированных сред разработки и не ограничивает возможностей программиста. Впервые такой подход был реализован в свободно распространяемой системе Sh. Заметим, что впоследствии из нее произошли коммерческие системы PeakStream и довольно распространенная сегодня RapidMind, причем последняя также позволяет переносить программы на Cell и многоядерные процессоры.
«Ленивые» вычисления и «массивное» программирование. Этот способ программирования реализуется с помощью системы Accelerator, разрабатываемой в Microsoft Research, которая позволяет писать программу на любом языке .NET, например, на C#. Он вводит понятие массива GPU из вещественных чисел и переопределяет для него стандартные операции (например, сложение и умножение), которые имеют поэлементную семантику. Определяются и более сложные операции: редукция, сканирование, выбор подмассива и т.д. Операции выполняются «лениво», возвращая не реальный массив, а ссылку на некоторое дерево выражений. В момент приведения этого дерева к обычному массиву происходит его разбор, генерация кода, вычисление на GPU и возврат данных обратно. Система свободно доступна для некоммерческого использования, однако широкого распространения не получила. Причина этого лежит не в подходе, а в реализации— отсутствие средств написания собственных функций для исполнения на GPU существенно ограничивало возможности программиста.
RapidMind представляет собой сочетание подходов метапрограммирования и массивного программирования. Метапрограммирование используется при написании ядер для GPU, а массивное программирование— при выполнении стандартных массивных операций. Основными понятиями RapidMind являются «значение», «программа» и «массив». Программа— это некоторый код, написанный при помощи примитивов RapidMind и заключенный между макросами BEGIN и END, что примерно соответствует процедуре в обычных языках программирования. Значение является аналогом переменной или параметра функции и может быть только одного из стандартных типов RapidMind. Наконец, для хранения данных используется массив, с автоматической синхронизацией между оперативной и видеопамятью, выполняемой системой времени исполнения RapidMind.
Технология RapidMind предполагает трехэтапный процесс адаптации программ для GPU: заменить переменные значениями RapidMind; оформить вычисления в виде программ RapidMind; оформить данные в виде массивов RapidMind и передать их в программу для обработки.
Несмотря на явный прогресс в развитии средств программирования GPU, пока они еще далеки от совершенства. Программы приходится писать в терминах специальных библиотечных вызовов или метапрограммирования. За исключением CUDA, нет единого способа описать функцию, которая исполнялась бы и на центральном процессоре, и на GPU. Имеющиеся в распоряжении средства все еще остаются достаточно низкоуровневыми. Даже несмотря на переносимость RapidMind, она не обеспечивает оптимизаций времени выполнения, следовательно, программист должен сам это делать.
Что хотелось бы видеть в технологиях программирования для GPU?
Эффективность. Технология должна поддерживать средства создания эффективных программ для GPU.
Переносимость. Созданные программы должны переноситься с сохранением эффективности как между различными архитектурами GPU, так и, желательно, на схожие архитектуры (SMP, Cell) без существенных изменений.
Высокоуровневость. Технология должна позволять работать в терминах высокого уровня, понятных прикладному программисту.
Простота интеграции. Система должна позволять легко интегрировать работу с GPU в существующие приложения.
Вместе с этим, вне зависимости от технологии программирования, GPU остается спецпроцессором, на котором невозможно реализовать любую задачу с одинаково высокой эффективностью. Развитие архитектуры GPU определяет конкретный набор требований.
Высокая вычислительная мощность. Объем вычислений должен значительно превышать объем необходимых данных, в противном случае вычисления на GPU не покроют даже накладных расходов на пересылку входных данных и результатов.
Большой размер вычисляемого массива. Запуск прохода— достаточно дорогая операция, более того, при малом размере массива не будет достаточного числа потоков для покрытия расходов на чтение из памяти.
Возможность независимого вычисления целевых элементов на каждом из проходов. Это требование напрямую вытекает из отсутствия возможностей синхронизации.
Массивы данных, используемые при вычислении, должны целиком помещаться в видеопамять. Это сразу следует из медленного обмена между оперативной и видеопамятью.
Новый подход к программированию GPU предлагается в проекте C$ (читается «си-эс»). Проект ставит своей целью создание системы программирования GPU, удовлетворяющей перечисленным требованиям. Основной идеей является то, что шейдер представляет собой функцию без побочных эффектов, которая применяется к массивам в памяти GPU. Шейдер можно реализовать как функцию, а массив — как массив языка C$, хранимый в оперативной и видеопамяти и при необходимости синхронизируемый. В этом случае при помощи конструкции применения функции к массиву можно будет исполнять эту функцию на GPU.
Проект C$ состоит из двух частей— системы времени исполнения и собственно языка C$. Система времени исполнения похожа на библиотеки типа RapidMind. Она строит граф операций, динамически транслирует, оптимизирует и исполняет его на GPU. Она же отвечает за выделение памяти под массивы и ее управление при помощи механизма сборки мусора. Программист пишет программы в терминах языка C$, который предоставляет удобную нотацию обращения к API системы времени исполнения C$. Кроме того, C$ — полноценный объектно-ориентированный язык .NET, что позволяет использовать .NET как для его промежуточного представления, так и для выполнения той части программы, которая исполняется на центральном процессоре. По сути, это C#/Java с дополнительными элементами массивного и функционального программирования. Благодаря единой системе типов программа на C$ может быть доступна в виде DLL-файла .NET и легко интегрируется в любой .NET-проект как библиотека классов.
Основным понятием языка является функциональный тип чистой функции. Он представляет собой базовый класс, от которого наследуют конкретные реализации: массивы, функции-выражения, функции, реализованные в коде. Для любой функции определена конструкция суперпозиции, понимаемая в математическом смысле. Поддерживаются операции редукции, а также приведение функции на ограниченной области определения к массиву, что вызывает вычисление на GPU.
Для более сложных случаев предусмотрено понятие связанной переменной. Ее использование представляет собой цикл без заголовка и позволяет задавать более гибкие конструкции. Пользователь записывает алгоритм в терминах обычных массивов, и при этом ему ничего не известно о схеме их хранения: на разных GPU эти схемы могут существенно различаться. Более того, во время выполнения система постарается выбрать как подходящее представление данных в памяти, так и отображение кода на уровни параллелизма GPU. В данном случае для GPU от AMD, например, будет произведена автоматическая векторизация кода для использования четверок вещественных чисел и специфических шаблонов доступа к памяти, что позволит повысить скорость работы до 76 GFLOPS на AMD X1950 PRO, а это около 45% его пиковой производительности.
Что решают на GPU?
В контексте GPU под матричными вычислениями понимается умножение плотных матриц. Другие операции, например сложение, ввиду очень малой вычислительной мощности не достигают производительности выше 2% от пиковой. При нынешних объемах памяти на GPU можно умножать матрицы размером до 8000*8000, и все данные будут размещены в видеопамяти. Реально достигнутая производительность также достаточно высока: на AMD HD 2900— 100 GFLOPS, на nVidia GeForce GTX8800— 125 GFLOPS (на процедуре из CUBLAS, реализованной nVidia). Такая производительность достигается за счет использования блочных алгоритмов умножения матриц, а классические прямые реализации оказываются на порядок медленнее.
Серьезной проблемой остается умножение разреженных матриц. Из-за непредсказуемого шаблона доступа к памяти и более сложной структуры данных эффективных алгоритмов для GPU пока не создано. Как нет и эффективной реализации обращения плотной матрицы, из-за чего для GPU нет и результатов теста Linpack.
Особняком стоит задача расчета цены опционов по формуле Блэка-Шоулза, часто решаемая на практике. Это тот редкий случай, когда большое количество вычислений сочетается с очень простой параллельной структурой. На вход подаются три массива параметров опционов, и требуется рассчитать стоимость опциона для каждой тройки параметров. Формула для расчетов содержит только одно ветвление, а в остальном абсолютно линейна. Более того, в расчетах активно используются операции логарифма и экспоненты, которые намного эффективнее реализованы на современных графических процессорах, чем на центральных процессорах. В результате системы на GPU демонстрируют на этой задаче практически 100-кратное ускорение по сравнению с обычным процессором. На nVidia GeForce 8800GTX достигнутая производительность составляет 260 GFLOPS.
Обработка изображений была одной из первых задач, решаемых на GPU. Наиболее важными алгоритмами здесь являются фильтрация изображений и преобразование Фурье. Фильтрация, благодаря относительно простой структуре, легко отображается на GPU, однако коэффициент повторного использования данных значительно меньше, чем у умножения матриц, что и объясняет значительно меньшую эффективность GPU в решении данной задачи. При размере ядра 3*3 производительность кода на nVidia GeForce 8800GTX составляет около 14,1 GFLOPS (то есть загрузка— всего 4%). Часто применяемая на практике отдельная фильтрация при помощи фильтра Гаусса показывает худшие результаты ввиду еще более низкого коэффициента повторного использования.
Преобразование Фурье относится к классу алгоритмов, которые на GPU выполняются за время, пропорциональное N lg N, где N— размер задачи. Оба алгоритма реализуются при помощи многопроходной схемы, где на каждом проходе применяется ядро типа «бабочки». И хотя вычислительная сложность подобного ядра относительно невысока, GPU от nVidia удается достичь на нем неплохих результатов. На первых этапах работы весь рабочий набор умещается в статическую память, что позволяет собрать его в один проход и получить порядка 40 GFLOPS на графической карте nVidia GeForce 8800GTX.
Естественно, далеко не на всех задачах удается получить высокую производительность даже на одном GPU. Вместе с тем существует множество задач, которые очень хорошо масштабируются и на кластерах GPU, и даже в распределенных вычислительных средах, построенных из графических процессоров.
Показательный пример использования GPU в grid— проект Folding@Home, начатый в 2000 году с целью использования распределенных вычислений для решения задачи определения пространственных структур белка. Понимание этих процессов чрезвычайно важно в лечении целого ряда заболеваний, в частности болезней Альцгеймера и Паркинсона. Пользователи могут скачать программу-клиент, которая загружает данные с сервера и выполняет расчеты. Изначально проект ориентировался на обычные процессоры и предполагал использование оптимизированных под SSE вычислительных ядер. В октябре 2006 года был выпущен клиент для AMD X1K на основе DPVM. Через несколько дней вклад GPU в общую производительность проекта составлял порядка 31 TFLOPS, при этом использовалось всего 450 графических карт. Общий вклад GPU с тех пор остается примерно на том же уровне. С выходом в марте 2007 года клиента для Sony PlayStation 3, использующего процессор Cell, общий вклад GPU стал достаточно небольшим по сравнению с остальными архитектурами (общая производительность системы равна 1,5 PFLOPS, при этом более 80% приходится на PlayStation 3), и составляет всего около 2%. Однако GPU лидируют по вкладу одного устройства определенного типа: каждое GPU вносит порядка 63 GFLOPS в общую производительность, а это вдвое больше, чем Cell, и в 60 раз больше вклада одного процессора с классической архитектурой x86.
Кластеры из GPU позволяют получить высокую пиковую производительность, однако приблизиться к ней на практике непросто. Наиболее существенным физическим ограничением является низкая пропускная способность канала «GPU— центральный процессор», особенно по направлению к центральному процессору, поскольку сетевая карта напрямую с GPU недоступна. С распространением PCI-Express и быстрой обратной пересылки ситуация значительно улучшилась: скорости порядка 1 Гбайт/с сделали кластеры GPU эффективными и реально используемыми компьютерными системами.
Хорошим примером решения задачи на кластере GPU является задача N тел, активно применяемая в астрономических расчетах. Имеется система из N тел, заданы их положения и начальные скорости. Между частицами действует сила взаимного притяжения, которая вычисляется по формуле Ньютона. Требуется рассчитать эволюцию всей системы. Самый очевидный подход— это рассчитывать на каждом шаге ускорение каждой частицы, и в соответствии с этим изменять ее положение. Для расчета движения одной частицы необходимо просуммировать вклад всех других частиц в ее ускорение, поэтому сложность одного шага расчета составляет O(N2), где O— некоторая константа. Поскольку задача может применяться для больших скоплений частиц, например галактик или астероидов солнечной системы, а число шагов по времени может быть большим, то задача в целом будет обладать значительной вычислительной сложностью.
Авторы одной из подобных работ сначала реализовали свою систему на одном графическом процессоре GeForce 8 с использованием CUDA. Была достигнута производительность 250 GFLOPS (загруженность 78%). На графическом процессоре вычислялось только ускорение частиц и его производная по времени, а изменение положения и последующее построение их орбит проводилось на центральном процессоре.
Реализация алгоритма на кластере GPU (16 компьютеров по две карты nVidia GeForce 8800GTX в каждом) выполнена за счет разбиения частиц на группы. Все GPU были организованы в логическое кольцо, частицы были разделены поровну между различными GPU. Каждый шаг эволюции рассчитывался в M этапов, где M— это общее число GPU в системе. На каждом шаге GPU рассчитывал воздействие текущего блока частиц на свои частицы, после чего передавал текущий блок следующему по кругу процессору и принимал новый текущий блок от предыдущего. После этого результаты вычислений суммировались. Для работы с сетью использовался MPI и его возможности по асинхронной пересылке данных, что позволяло выполнять передачу данных на фоне вычисления силы взаимодействия. Пиковая производительность кластера из 32 GPU составила 16,7 TFLOPS. При этом реальная достигнутая производительность равнялась 7,1 TFLOPS на задаче моделирования одного миллиона частиц. Это соответствует эффективности 42% и является очень хорошим результатом. Начиная со 100 тыс. частиц задача масштабировалась на 32 GPU почти линейно.
***
Сегодня имеется хорошая перспектива использования графических процессоров для высокопроизводительных вычислений. Для рассмотренных архитектур GPU ясно видны как разрыв между высокой пиковой производительностью и возможностью ее реального достижения для широкого класса задач, так и отсутствие адекватных средств программирования. Определенные шаги в этом направлении уже выполнены в системах типа RapidMind или C$, однако здесь еще многое нужно сделать.
Куда движутся архитектуры GPU? Если проследить вектор развития по первым трем поколениям, то они меняются в сторону увеличения их универсальности при дальнейшем росте производительности. Важным шагом в этом направлении является GeForce 8, который отходит от традиционной SIMD-архитектуры для GPU. В том же направлении движутся не только GPU. Действительно, процессор Cell, экспериментальные 80-ядерные процессоры Intel и находящийся в настоящее время на стадии разработки графический процессор Larrabee от Intel также идут в русле этих тенденций. Наблюдается конвергенция различных параллельных архитектур в сторону создания высокопроизводительной и доступной MIMD-архитектуры общего вида.
Параллелизм в современных архитектурах не ограничивается суперкомпьютерами— он идет «в массы» в виде многоядерных процессоров, GPU, ПЛИС и других архитектур. Поэтому, с одной стороны, стоит ожидать появления стандартов, которые предоставят единый способ организации программ в неоднородных вычислительных средах, а с другой— высокоуровневых языков программирования, которые будут способны эффективно отображать параллельные программы на различные целевые архитектуры.
Андрей Адинец (adinetz@gmail.com ) — программист, Владимир Воеводин (voevodin@parallel.ru ) — заместитель директора НИВЦ МГУ (Москва).
Особенности работы с GPU
Возможности современных GPU впечатляют, однако пользоваться ими нужно исключительно аккуратно, учитывая особенности архитектур графических процессоров для эффективного программирования подобных систем.
Высокая стоимость чтения из видеопамяти в шейдере на GPU. Операция чтения из видеопамяти занимает на два порядка больше времени, чем выполнение одной арифметической операции.
Большое время запуска прохода. Время запуска шейдера намного превышает время обработки одного элемента, и, чтобы его компенсировать, требуется обрабатывать большое (10000 и более) количество элементов за один запуск.
Поддержка аппаратной многопоточности. Если готовых к исполнению потоков будет мало, то высокую латентность обращения в видеопамяти скрыть не удастся.
Медленный обмен данными между оперативной и видеопамятью. Канал обмена данными между ними является узким, что нужно иметь в виду при организации программы.
Разнородность архитектур. Следует учитывать, что оптимальные программы для nVidia и AMD будут сильно различаться.
