
Реляционная модель данных, которая была предложена Э.Ф. Коддом в 1970 году, и за которую десятилетие спустя он получил премию Тьюринга, служит основой современной многомиллиардной отрасли баз данных. За последние десять лет сложилась многомерная модель данных, которая используется, когда целью является именно анализ данных, а не выполнение транзакций. Технология многомерных баз данных — ключевой фактор интерактивного анализа больших массивов данных с целью поддержки принятия решения. Подобные базы данных трактуют данные как многомерные кубы, что очень удобно именно для их анализа.
Многомерные модели рассматривают данные либо как факты с соответствующими численными параметрами, либо как текстовые измерения, которые характеризуют эти факты. В розничной торговле, к примеру, покупка — это факт, объем покупки и стоимость — параметры, а тип приобретенного продукта, время и место покупки — измерения. Запросы агрегируют значения параметров по всему диапазону измерения, и в итоге получают такие величины, как общий месячный объем продаж данного продукта. Многомерные модели данных имеют три важных области применения, связанных с проблематикой анализа данных.
- Хранилища данных интегрируют для анализа информации из нескольких источников на предприятии.
- Системы оперативной аналитической обработки (online analytical processing — OLAP) позволяют оперативно получить ответы на запросы, охватывающие большие объемы данных в поисках общих тенденций.
- Приложения добычи данных служат для выявления знаний за счет полуавтоматического поиска ранее неизвестных шаблонов и связей в базах данных.
Исследователи предложили формальные математические модели многомерных баз данных, а затем эти предложения нашли уточненное отражение в конкретном программном инструментарии, реализующем эти модели [1, 2]. Врезка «История развития многомерных баз данных» описывает эволюцию многомерной модели данных.
Электронные таблицы и отношения
Электронные таблицы, аналогичные показанной в таблице 1, представляют собой удобный инструмент для анализа данных о продажах: какие продукты проданы, сколько совершено сделок и где. Главная таблица (pivot table) — двумерная электронная таблица с соответствующими промежуточными и итоговыми результатами, которая используется для просмотра более комплексных данных путем вложения нескольких измерений по осям x и y и отображения данных на нескольких страницах. Главные таблицы, как правило, поддерживают итеративный выбор подмножеств данных и изменение отображаемого уровня детализации.
Электронные таблицы не подходят для управления и хранения многомерных данных, поскольку они слишком жестко связывают данные с их внешним видом, не отделяя структурную информацию от желаемого представления информации. Скажем, добавление третьего измерения, такого как время, или группировка данных по обобщенным типам продуктов требует значительно более сложной настройки. Очевидное решение состоит в использовании отдельной электронной таблицы для каждого измерения. Но такое решение оправдано только в ограниченной степени, поскольку анализ подобных наборов таблиц быстро становится чересчур громоздким.
Использование баз данных, поддерживающих SQL, значительно увеличивает гибкость обработки структурированных данных. Однако сформулировать многие вычисления, такие как совокупные показатели (объем продаж за год к текущему моменту), сочетание итоговых и промежуточных результатов, ранжирование, например, определение десяти самых продаваемых продуктов, посредством стандартного варианта SQL весьма сложно, если вообще возможно. При перестановке строк и столбцов необходимо вручную специфицировать и комбинировать различные представления. Расширения SQL, такие как оператор кубов данных [3] и окна запросов [4] частично решают эти задачи, в целом чистая реляционная модель не позволяет на приемлемом уровне работать с иерархическими измерениями.
Электронные таблицы и реляционные базы данных адекватно обрабатывают массивы данных, которые имеют незначительное число измерений, но они не полностью отвечают требованиям углубленного анализа данных. Решение же состоит в том, чтобы использовать технологию, которая предусматривает поддержку полного спектра средств многомерного моделирования данных.
Кубы
Многомерные базы данных рассматривают данные как кубы, которые являются обобщением электронных таблиц на любое число измерений. Кроме того, кубы поддерживают иерархию измерений и формул без дублирования их определений. Набор соответствующих кубов составляет многомерную базу данных (или хранилище данных).
Кубами легко управлять, добавляя новые значения измерений. В обычном обиходе этим термином обозначают фигуру с тремя измерениями, однако теоретически куб может иметь любое число измерений. На практике чаще всего кубы данных имеют от 4 до 12 измерений [5, 6]. Современный инструментарий часто сталкивается с нехваткой производительности, когда так называемый гиперкуб имеет свыше 10-15 измерений.
Комбинации значений измерений определяют ячейки куба. В зависимости от конкретного приложения ячейки в кубе могут располагаться как разрозненно, так и плотно. Кубы, как правило, становятся разрозненными по мере увеличения числа размерностей и степени детализации значений измерений.
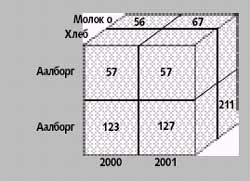
На рис. 1 показан куб, содержащий данные по продажам в двух датских городах, указанных в таблице 1 с дополнительным измерением — «Время». В соответствующих ячейках хранятся данные об объеме продаж. В примере можно обнаружить «факт» — непустую ячейку, содержащую соответствующие числовые параметры — для каждой комбинации время, продукт и город, где была совершена, по крайней мере, одна продажа. В ячейке размещаются числовые значения, связанные с фактом — в данном случае, это объем продаж — единственный параметр.
|
|
Рис. 1. Пример куба, содержащего данные о продажах. В этом случае куб обобщает электронную таблицу из Таблицы 1, добавляя к ней третье измерение — время |
В общем случае куб позволяет представить только два или три измерения одновременно, но можно показывать и больше за счет вложения одного измерения в другое. Таким образом, путем проецирования куба на двух- или трехмерное пространство можно уменьшить размерность куба, агрегировав некоторые размерности, что ведет к работе с более комплексными значениями параметров. К примеру, рассматривая продажи по городам и времени, мы агрегируем информацию для каждого сочетания город и время. Так, на рис. 1, сложив поля 127 и 211, получаем общий объем продаж для Копенгагена в 2001 году.
Измерения
Измерения — ключевая концепция многомерных баз данных. Многомерное моделирование предусматривает использование измерений для предоставления максимально возможного контекста для фактов [5]. В отличие от реляционных баз данных, контролируемая избыточность в многомерных базах данных, в общем, считается оправданной, если она увеличивает информационную ценность. Поскольку данные в многомерный куб часто собираются из других источников, например, из транзакционной системы, проблемы избыточности, связанные с обновлениями, могут решаться намного проще. Как правило, в фактах нет избыточности, она есть только в измерениях.
Измерения используются для выбора и агрегирования данных на требуемом уровне детализации. Измерения организуются в иерархию, состоящую из нескольких уровней, каждый из которых представляет уровень детализации, требуемый для соответствующего анализа.
Иногда бывает полезно определять несколько иерархий для измерения. Например, модель может определять время как в финансовых годах, так и в календарных. Несколько иерархий совместно используют один или несколько общих, самых низких уровней, например, день и месяц, и модель группирует их в несколько более высоких уровней — финансовый квартал и календарный квартал. Чтобы избежать дублирования определений, метаданные многомерной базы данных определяют иерархию измерений.
|
|
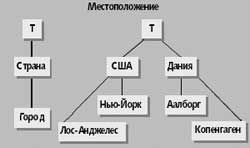
Рис. 2. Пример схемы измерений местоположения. Каждое значение размерности является частью значения T |
На рис. 2 показана схема «Местоположение» для данных продаж из таблицы 1. Из трех уровней измерений местоположения самый низкий — «Город». Значения уровня «Город» группируются в значения на уровне «Страна», к примеру, Аалборг и Копенгаген находятся в Дании. Уровень T представляет все измерения.
В некоторых многомерных моделях уровень имеет несколько связанных свойств, которые содержат простую, неиерархическую информацию. Например, «Размер пакета» может быть свойством уровня в измерении «Продукт». Измерение «Размер пакета» может также получать эту информацию. Использование механизма свойств не приводит к увеличению числа измерений в кубе.
В отличие от линейных пространств, с которыми имеет дело алгебра матриц, многомерные модели, как правило, не предусматривают функций упорядочивания или расстояния для значений измерения. Единственное «упорядочивание» состоит в том, что значения более высокого уровня содержат значения более низких уровней. Однако для некоторых измерений, таких как время, упорядоченность значений размерности может использоваться для вычисления совокупной информации, такой как общий объем продаж за определенный период. Большинство моделей требуют определения иерархии измерений для формирования сбалансированных деревьев — иерархии должны иметь одинаковую высоту по всем ветвям, а каждое значение не корневого уровня — только одного родителя.
Факты
Факты представляют субъект — некий шаблон или событие, которые необходимо проанализировать. В большинстве многомерных моделей данных факты однозначно определяются комбинацией значений измерений; факт существует только тогда, когда ячейка для конкретной комбинации значений не пуста. Однако некоторые модели трактуют факты как «объекты первого класса» с особыми свойствами. Большинство многомерных моделей также требуют, чтобы каждому факту соответствовало одно значение на более низком уровне каждого измерения, но в некоторых моделях это не является обязательным требованием [1].
Каждый факт обладает некоторой гранулярностью, определенной уровнями, из которых создается их комбинация значений измерений. Например, гранулярность факта в кубе, представленном на рис. 1 — это (Год x Продукт x Город). (Год x Тип x Город) и (День x Продукт x Город) — соответственно более грубая и более тонкая гранулярности.
Хранилища данных, как правило, содержат следующие три типа фактов [5].
- События (event), по крайней мере, на уровне самой большой гранулярности, как правило, моделируют события реального мира, при этом каждый факт представляет определенный экземпляр изучаемого явления. Примерами могут служить продажи, щелчки мышью на Web-странице или движение товаров на складе.
- Мгновенные снимки (snapshot) моделируют состояние объекта в данный момент времени, такие как уровни наличия товаров в магазине или на складе и число пользователей Web-сайта. Один и тот же экземпляр явления реального мира, например, конкретная банка бобов, может возникать в нескольких фактах.
- Совокупные мгновенные снимки (cumulative snapshot) содержат информацию о деятельности организации за определенный отрезок времени. Например, совокупный объем продаж за предыдущий период, включая текущий месяц, можно легко сравнить с показателями за соответствующие месяцы прошлого года.
Хранилище данных часто содержит все три типа фактов. Одни и те же исходные данные, например, движение товаров на складе, могут содержаться в трех различных типах кубов: поток товаров на складе, список товаров и поток за год к текущей дате.
Параметры
Параметры состоят из двух компонентов:
- численная характеристика факта, например, цена или доход от продаж;
- формула, обычно простая агрегативная функция, скажем, сумма, которая может объединять несколько значений параметров в одно.
В многомерной базе данных параметры, как правило, представляют свойства факта, который пользователь хочет изучить. Параметры принимают различные значения для разных комбинаций измерений. Свойство и формула выбираются таким образом, чтобы представлять осмысленную величину для всех комбинаций уровней агрегирования. Поскольку метаданные определяют формулу, данные, в отличие от случая электронных таблиц, не тиражируются.
При вычислениях три различных класса параметров ведут себя совершенно по-разному.
- Аддитивные параметры могут содержательным образом комбинироваться в любом измерении. Например, имеет смысл суммировать общий объем продаж для продукта, местоположения и времени, поскольку это не вызывает наложения среди явлений реального мира, которые генерируют каждое из этих значений.
- Полуаддитивные параметры, которые не могут комбинироваться в одном или нескольких измерениях. Например, суммирование запасов по разным товарам и складам имеет смысл, но суммирование запасов товаров в разное время бессмысленно, поскольку одно и то же физическое явление может учитываться несколько раз.
- Неаддитивные параметры не комбинируются в любом измерении, обычно потому, что выбранная формула не позволяет объединить средние значения низкого уровня в среднем значении более высокого уровня.
Аддитивные и неаддитивные параметры могут описывать факты любого рода, в то время как полуаддитивные параметры, как правило, используются с мгновенными снимками или совокупными мгновенными снимками.
Запросы
Многомерная база данных естественным образом предназначена для определенных типов запросов.
- Запросы вида slice-and-dice осуществляют выбор, сокращающий куб. К примеру, можно рассмотреть сечение куба на рис. 1, приняв во внимание только те ячейки, которые касаются хлеба, а затем еще больше сократить его, оставив ячейки, относящиеся только к 2000 году. Фиксация значения измерения сокращает размерность куба, но при этом возможны и более общие операции выбора.
- Запросы вида drill-down и roll-up — взаимообратные операции, которые используют иерархию измерений и параметры для агрегирования. Обобщение до высших значений соответствует исключению размерности. Например, свертка от уровня «Город» до уровня «Страна» на рис. 2 агрегирует значения для Аалборга и Копенгагена в одно значение — Дания.
- Запросы вида drill-across комбинируют кубы, которые имеют одно или несколько общих измерений. С точки зрения реляционной алгебры такая операция выполняет слияние (join).
- Запросы вида ranking [6] возвращает только те ячейки, которые появляются в верхней или нижней части упорядоченного определенным образом списка, например, 10 самых продаваемых продуктов в Копенгагене в 2000 году.
- Поворот (rotating) куба дает пользователям возможность увидеть данные, сгруппированные по другим измерениям.
Реализация
Многомерные базы данных реализуют в двух основных формах.
- Системы многомерной оперативной аналитической обработки (MOLAP) хранят данные в специализированных многомерных структурах. Системы MOLAP, как правило, содержат средства для обработки разреженных массивов и применяют усовершенствованную индексацию и хеширование для поиска данных при выполнении запросов [6].
- Реляционные системы OLAP (ROLAP) [5] для хранения данных используют реляционные базы данных, а также применяют специализированные индексные структуры, такие как битовые карты, чтобы добиться высокой скорости выполнения запросов.
Системы MOLAP, как правило, позволяют добиться более эффективного использования дискового пространства, а также меньшего времени ответов при обработке запросов.
Врезка «Сокращение времени ответа при обработке запросов» описывает некоторые из применяемых с этой целью методик. Системы ROLAP, как правило, лучше масштабируются с ростом числа фактов, которые они могут хранить (хотя некоторые инструментальные средства MOLAP теперь становятся столь же масштабируемыми), более гибкими в том, что касается переопределения кубов, и лучше поддерживают частые обновления. Достоинства двух подходов объединены в гибридном решении, при котором для хранения сводных данных более высокого уровня используется технология MOLAP, а в системах ROLAP размещаются детальные данные.
В ROLAP, как правило, используются схемы «звезда» и «снежинка» [5], при которых данные хранятся в таблицах фактов и таблицах измерений. Таблица фактов содержит одну строку для каждого факта в кубе. Для каждого измерения отводится отдельный столбец, содержащий значение параметра для конкретного факта, а также столбец для каждого измерения, которое содержит внешний ключ, ссылающийся на таблицу измерений для конкретного измерения.
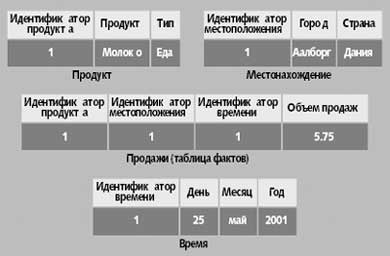
Схемы «звезда» и «снежинка» отличаются в том, как они поддерживают измерения, и выбор между ними, в основном, зависит от того, какими свойствами должна обладать разрабатываемая система. Как показано на рис. 3, в схеме «звезда» на каждое измерение отводится одна таблица. Таблица измерений содержит ключевой столбец, по одному столбцу для каждого уровня измерений с текстовыми описаниями значений этого уровня, и по одному столбцу для каждого свойства уровня в измерении.
|
|
Рис. 3. Схема «звезда» для куба продаж. Информация со всех уровней в измерении хранится в одной таблице измерений, например, названия продуктов и типы продуктов хранятся в таблице «Продукт» |
Таблица фактов в схеме «звезда» в нашем примере содержит цены продаж для одной конкретной продажи и соответствующие значения измерений. Она включает столбец внешнего ключа для каждого из трех измерений: продукт, местоположение и время. Таблицы измерений имеют соответствующие ключевые столбцы и по одному столбцу для каждого уровня измерений, например, «Идентификатор местоположения», «Город» и «Страна». Для уровня T столбца не требуется, поскольку в нем всегда содержится одно и то же значение. Столбец ключа таблицы измерений, как правило, представляет собой искусственный целочисленный ключ без какой-либо семантики. Это позволяет избежать некорректной трактовки ключей, обеспечить более эффективное использование памяти и лучшую поддержку обновлений измерений, чем при работе с информативными ключами, получаемыми из систем-источников [5].
На более высоком уровне данных возникнет избыточность. Например, поскольку в мае 2001 года 31 день, значение 2001 будет повторено 31 раз. Поскольку измерения, как правило, занимают 1-5% всего пространства, требуемого для хранения куба, такая избыточность не вызывает нехватки памяти. Кроме того, централизованная поддержка обновления измерений гарантирует согласованность. Таким образом, использование денормализованных таблиц измерений, необходимых для поддержки упрощенного формулирования запросов, которые к тому же эффективно вычисляются, часто дает дополнительные преимущества.
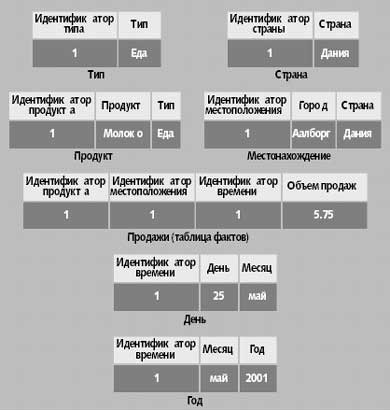
Схема «снежинка» содержит по одной таблице для каждого уровня измерений, избегая избыточности, что может оказаться весьма полезным в некоторых ситуациях. Каждая из таблиц измерений содержит ключ, столбец с текстовыми описаниями значений уровней, возможно, столбцы для свойств уровней. Таблицы более низких уровней могут также содержать внешний ключ для доступа к более высокому уровню. Например, таблица дней на рис. 4 содержит целочисленный ключ, дату и внешний ключ для связи с таблицей месяцев.
|
|
Рис. 4. Схема «снежинка» для куба продаж. Информация из различных уровней в измерении хранится в различных таблицах. Например, названия продуктов и типы продуктов хранятся в таблицах «Продукт» и «Тип» соответственно |
Сложные многомерные данные
Традиционные многомерные модели данных и методы их реализации предполагают, что:
- все факты напрямую отображаются на значения измерений более низкого уровня, причем ровно на одно значение в каждом измерении;
- иерархии измерений представляют собой сбалансированные деревья.
Если эти предположения не выполняются, то стандартные модели и системы оказываются неадекватными. Особенно серьезные проблемы вызывают комплексные многомерные данные, поскольку они не являются суммируемыми (summarizable) — агрегированные результаты более высокого уровня нельзя получить из агрегированных результатов более низкого уровня. Запросы по результатам более низкого уровня будут приносить неверные данные, или предварительные вычисления, сохранение и последующее использование их результатов в данном случае невозможны. Вместо этого агрегированные результаты должны вычисляться непосредственно из базовых данных, что значительно увеличивает затраты на вычисления.
Суммирование требует применения распределенных агрегированных функций и значений иерархии измерений [1, 7]. Неформально иерархия измерений является «строгой», если ни одно из значений измерений не имеет более одного прямого родителя, «сюрьективной» (onto), если иерархия сбалансирована, и «покрывающей» (covering), если ни один локальный путь не «перескакивает» через уровень. Интуитивно это значит, что иерархии измерений должны быть сбалансированными деревьями. Как показано на рис. 5, в случае нерегулярных иерархий измерений некоторые значения более низкого уровня при повторном использовании промежуточных результатов запросов будут либо посчитаны дважды, либо ни разу.
Нерегулярные иерархии возникают в разных приложениях, в том числе в иерархии административных структур [8], иерархии медицинских диагнозов [9] и иерархии концепций для Web-порталов, подобных Yahoo. Одно из решений — нормализовать нерегулярные иерархии, процесс, который предусматривает пополнение несюрьективных и непокрывающих иерархий фиктивными значениями измерений, и перестраивает наборы родителей, для того чтобы решить проблемы нестрогих иерархий. Это преобразование может выполняться прозрачным для пользователя образом [10].
За 30 лет с момента своего возникновения технология многомерных баз данных прошла серьезную эволюцию. С недавних пор она стала реализовываться в решениях, предназначенных для массового рынка, а ведущие производители теперь выпускают многомерные ядра вместе со своими реляционными базами данных, причем часто без дополнительной оплаты. Многомерная технология стала значительно более масштабируемой и зрелой.
Это порождает несколько важных тенденций. Данные, которые необходимо анализировать, становятся все более распределенными. К примеру, это часто необходимо для выполнения анализа, при котором используются данные в формате XML, получаемые с определенных Web-сайтов. Растущая распределенность данных, в свою очередь, требует применения методов, которые позволяют легко добавлять новые данные в многомерные базы данных, тем самым, упрощая задачу создания интегрированного хранилища данных. Среди примеров — автоматическая генерация измерений и кубов из новых источников данных и методы простой и динамической очистки данных.
Технология многомерных баз данных также применяется к новым типам данных, которые современные технологии зачастую не в состоянии адекватно анализировать. К примеру, классические методики, такие как предагрегирование не могут гарантировать небольшое время ответа на запросы, если данные постоянно меняются, как это происходит, например, когда информация поступает с датчиков или от движущихся объектов, таких как автомобили, оснащенные средствами глобального позиционирования.
Наконец, технология многомерных баз данных все больше будет применяться там, где результаты анализа напрямую передаются в другие системы, тем самым, исключая участие человека в этом процессе. Этот контекст в совокупности с необходимостью постоянного обновления предъявляет более жесткие требования к производительности, которым не удовлетворяет современная технология.
Литература
- T.B. Pedersen, C.S. Jensen, C.E. Dyreson, «A Foundation for Capturing and Querying Complex Multidimensional Data», Information Systems, vol. 26, no. 5, 2001
- P. Vassiliadis, T.K. Sellis, «A Survey of Logical Models for OLAP Databases», ACM SIGMOD Record, vol. 28, no. 4, 1999
- J. Gray et al., «Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab and Sub-Totals», Data Mining and Knowledge Discovery, vol. 1, no. 1, 1997
- A. Eisenberg, J. Melton, «SQL Standardization: The Next Steps», ACM SIGMOD Record, vol. 29, no. 1, 2000
- R. Kimball, The Data Warehouse Toolkit: Practical Techniques for Building Dimensional Data Warehouses, John Wiley & Sons, New York, 1996
- E. Thomsen, OLAP Solutions: Building Multidimensional Information Systems, John Wiley & Sons, New York, 1997
- H.-J. Lenz, A. Shoshani, «Summarizability in OLAP and Statistical Data Bases», Proc. 9th Int?l Conf. Scientific and Statistical Database Management, IEEE CS Press, Los Alamitos, Calif., 1997
- T. Zurek, M. Sinnwell, «Data Warehousing Has More Colours Than Just Black and White», Proc. 25th Int?l Conf. Very Large Databases, Morgan Kaufmann, San Mateo, Calif., 1999
- UK National Health Service, Read Codes Version 3, Sept. 1999, www.cams.co.uk/readcode.htm (current Nov. 2001)
- T.B. Pedersen, C.S. Jensen, C.E. Dyreson, «Extending Practical Pre-Aggregation in On-Line Analytical Processing», Proc. 25th Int?l Conf. Very Large Databases, Morgan Kaufmann, San Mateo, Calif., 1999
Торбен Бэч Педерсон (tbp@cs.auc.dk) — адъюнкт-профессор информатики университета Аалборга (Дания). К области его научных интересов относятся многомерные базы данных, OLAP, хранилища данных, федеративные базы данных и службы с учетом местоположения.
Кристиан Йенсен (csj@cs.auc.dk) — профессор информатики университета Аалборга. Он специализируется на проблематике многомерных баз данных, хранилищ данных, временных и пространственно-временных баз данных, а также службах с учетом местоположения.
История развития многомерных баз данных
Источником для многомерных баз данных послужили не современные технологии баз данных, а алгебра многомерных матриц, которая использовалась для ручного анализа данных с конца XIX столетия.
В конце 60-х годов компании IRI Software и Comshare независимо друг от друга начали разрабатывать то, что позднее стали называть системами управления многомерными базами данных. IRI Express, популярный в конце 70-х и начале 80-х годов инструментарий маркетингового анализа, стал лидером рынка средств оперативной аналитической обработки и был куплен корпорацией Oracle. На базе системы Comshare был создан инструментарий System W, в 80-х годах активно применявшийся для финансового планирования, анализа и формирования отчетов.
Образованная в 1991 году компания Arbor Software (теперь Hyperion Solutions) в качестве своей специализации выбрала создание многопользовательских серверов многомерных баз данных; результатом этих работ стала система Essbase. Позже Arbor лицензировала базовую версию Essbase корпорации IBM, которая интегрировала ее в DB2.
В 1993 году Э.Ф. Кодд ввел термин OLAP [1]. В начале 90-х сложилась еще одна важная концепция — крупные хранилища данных, которые, как правило, базируются на схемах «звезда» и «снежинка». При таком подходе для реализации многомерных баз удается использовать технологию реляционных баз данных.
В 1998 году корпорация Microsoft выпустила OLAP Server, первую многомерную систему, предназначенную для массового рынка, и теперь такие системы становятся распространенными продуктами и предлагаются без дополнительной оплаты вместе с популярными системами управления реляционными базами данных.
Литература
1. E.F. Codd, S.B. Codd, C.T. Salley, «Providing OLAP (On-Line Analytical Processing) to User-Analysts: An IT Mandate», www.hyperion.com/solutions/whitepapers.cfm
Сокращение времени ответа при обработке запросов
Самые важные методы увеличения производительности в многомерных базах данных — это предвычисления (precomputation). Их специализированный аналог — предагрегирование (preaggregation), которое позволяет сократить время ответа на запросы, охватывающие потенциально огромные объемы данных, в степени, достаточной для проведения интерактивного анализа данных.
Вычисление и сохранение, или «материализация», сводных объемов продаж по странам и месяцам, — пример предагрегирования. Такой подход позволяет быстро получать ответы на запросы, касающиеся общего объема продаж, к примеру, в одном месяце, в одной стране или по кварталу и стране одновременно. Эти ответы можно получить из предварительно вычисленных данных и нет необходимости обращаться к информации, размещенной в хранилище данных.
Современные коммерческие реляционные базы данных, а также специализированные многомерные системы, содержат средства оптимизации запросов на основе предварительно вычисленных агрегатов (aggregate) и автоматического перевычисления хранимых агрегатов при обновлении базовых данных [1].
Полное предагрегирование — материализация всех сочетаний агрегатов — невозможно, поскольку требует слишком большого дискового пространства и времени на предварительные вычисления. Вместо этого современные системы OLAP следуют более практическому подходу к предагрегированию, материализуя только избранные комбинации агрегатов, а затем используя их для более эффективного вычисления других агрегатов [2]. Повторное использование агрегатов требует поддержания корректной многомерной структуры данных.
Литература
- R. Winter, «Databases: Back in the OLAP Game», Intelligent Enterprise Magazine, vol. 1, no. 4, 1998
- E. Thomsen, G. Spofford, D. Chase, Microsoft OLAP Solutions, John Wiley & Sons, New York, 1999
Torben Bach Pedersen, Christian S. Jensen, Multidimensional Database Technology. IEEE Computer, December 2001. Copyright IEEE Computer Society, 2001. All rights reserved. Reprinted with permission.
