С другой стороны, аудио и видео изображения можно отнести к полностью неструктурированным данным.
Между этими двумя крайностями находится наибольший объем данных. Такие данные и называются полуструктурированными. Примером, полуструктурированных данных может быть форматированный текст, HTML страницы, данные в нетрадиционных форматах (например, в ASN.1), в формате XML и т.д. Кроме того, в последнeе время проводятся большие исследования, связанные с вопросами интеграции распределенных данных. При этом даже при интеграции нескольких источников, данные которых достаточно хорошо структурированы, не удается придумать жесткую схему для полученных обобщенных данных. Таким образом, опять приходится иметь дело с полуструктурированными данными, т.е. схема которых размыта.
Из всего выше сказанного можно заключить, что назрела необходимость в разработке систем управления полуструктурированными данными, которые должны решить две основные задачи.
- Управление данными с «размытой» структурой.
- Интегрировать данные из разных источников.
В этой работе производится обзор технологий, применяемых при построении систем управления полуструктурированными данными. В первой главе обсуждаются особенности полуструктурированных данных, которые необходимо учесть при построении таких систем. Во второй главе рассмотрен вопрос выбора модели данных для работы с полуструктурированной информации. В третьей главе говорится о методах описания схемы баз данных. В четвертой главе рассказывается об основных особенностях языков запросов полуструктурированных данных. В пятой главе подробно рассмотрены методы интеграции данных из разных источников. И, наконец, в шестой главе говорится о применении технологии управления полуструктурированными данными для построения Интернет поисковых систем и систем управления Web-серверами.
Полуструктурированные данные
К полуструктурированным относят такие данные, в которых можно выделить некоторую структуру (в этом их отличие от аудио или видео данных), но структура этих данных не достаточно строгая для хранения их в традиционных системах (реляционных, объектно-ориентированных [GM1]). Ниже перечислены основные особенности полуструктурированных данных, которые раскрывают их сущность и определяют требования к системам управления такими данными.
Неправильная структураВ различных источниках информации одни и те же сущности реального мира могут моделироваться с помощью различных структур и типов данных. Так, например, один источник хранит адрес в виде картежа, а другой в виде строки, или понятие книга характеризуется названием, автором и годом издания, тогда как другая система связывает с этим понятием еще и рецензию, или цена в одном источнике определяется в рублях, в другом во франках. Следовательно, при попытке интеграции разнородных источников необходимо либо приводить данные к общей структуре, либо в результате интеграции данные будут иметь неправильную структуру. Приведение к общей структуре при большом количестве источников может быть невозможным или обобщенная структура будет очень сложной, а ее использование неэффективным. Таким образом, единственное, что нам остается это научиться работать с данными, которые имеют неправильную структуру.
Неявная структураМногие данные хотя и имеют некоторую достаточно строгую структуру, но эта структура неявная. Например, текстовые документы или HTML страницы на Web-серверах (в этом случае некоторое, но не полное представление о структуре помогут дать теги). Поэтому необходимо разрабатывать методы выявления неявной структуры, таких данных. В этом направлении уже ведется ряд работ [AK97,NAM97].
Частичная структурированностьВ некоторых случаях большая часть данных, работу с которыми необходимо автоматизировать, имеют правильную структуру. Тогда для хранения этой части данных используют традиционные системы управления базами данных, и придумывают методы связи этой части данных с оставшимися данными, которые не удалось структурировать и поэтому приходится хранить в других системах (специализированные системы, файловая система и т.д.). Таким образом, системы, построенные по такому принципу, представляют собой надстройку над традиционными СУБД.
Частое изменение структурыСтруктура полуструктурированных данных часто меняется, что необходимо учитывать при разработке систем, работающих с такими данными.
Апостериорная схема против априорной схемы данныхТрадиционные СУБД опираются на принцип фиксированной схемы данных. Поэтому сначала описывают схему базы данных, и только затем можно наполнять ее данными. Системы, использующие подобный подход, можно назвать системами с априорной схемой. При работе с полуструктурированными данными целесообразно применять обратный подход: сначала заполняем базу данных, а затем определяем какую структуру (схему) она имеет, то есть при заполнении базы вырисовывается ее схема. Системы, работающие по последнему принципу, можно назвать системами с апостериорной схемой. Использование такого подхода, дает большую гибкость при формировании базы и предоставляет возможность свободно изменять ее структуру. Благодаря применению описанного подхода системами управления полуструктурированными данными, используемую ими модель данных часто называют самоописательной или самооопределяемой. Методы выявления структуры существующих баз данных рассматриваются в главе «Описание структуры».
Модели данных
При разработке системы управления полуструктурированными данными, прежде всего необходимо определиться в выборе модели данных. Основной вопрос на который надо ответить: должна ли модель быть тяжеловесной (heavyweight) или легковесной (lightweight).
Почему выгодно использовать легковесную модель? К легковесным моделям данных относят простые и очень гибкие модели данных. При использовании таких моделей удается работать с данными, которые имеют сколь угодно сложную или неправильную структуру. Например, используя легковесную модель, удается интегрировать данные из разных источников, каждый из которых использует свою отличную и сложную структуру для хранения данных. Расплатой за гибкость является сложность оптимизации доступа к данным в такой модели. Пример легковесной модели Object Exchange Model (OEM) подробно рассмотрен ниже в этой главе.
Почему выгодно использовать тяжеловесную модель? Часто из общей совокупности полуструктурированных данных удается выделить часть, которая имеет вполне строгую структуру, тогда для работы с этой частью можно использовать приимущества эффективного доступа, которые нам предоставляют традиционные модели данных. Например, отношения с индексами позволяют эффективно и естественно моделировать многие сущности реального мира. Опираясь на такие рассуждения, можно построить модель данных, которая будет представлять из себя интеграцию общеизвестных структурных элементов из различных моделей (объекты, отношения, упорядоченные коллекции и т.д.). Но какой бы богатой получившаяся модель не была существует возможность, что некоторые данные не впишутся в нее. Кроме того, становится невозможным придумать элегантный язык запросов для такой модели. В качестве примера тяжеловесной модели можно привести ADM (ARANEUS Data Model), используемая в системе ARANEUS [AMM97], которая разработана для интеграции информации Web-серверов.
Большинство созданных на сегодняшний день систем управления полуструктурированными данными используют легковесные модели данных, в которых данные представляются в виде ориентированного графа с именованными ребрами. И практически такие модели являются разновидностями OEM-модели, которая и будет подробно рассмотрена далее.
OEM модель была разработана специально для полуструктурированных данных [PGMW95]. Эта модель используется системой Lore [HAG97], которая является одной из самых развитых систем управления полуструктурированными данными на сегодняшний день. Среди основных достоинств OEM элегантность и гибкость, что позволяет моделировать структуры данных традиционных систем (реляционных, объектно-ориентированных и т.д.). Данные в этой модели представляются в виде ориентированного графа с именованными ребрами. Вершины графа — это объекты. Каждый объект имеет уникальный идентификатор. Объекты могут быть простыми (атомарными) или сложными. Простые объекты не имеют исходящих ребер, но могут принимать значения одного из базовых атомарных типов, таких как целый, вещественный, строковый, звука, видео и т.п. Сложные объекты имеют исходящие ребра и не имеют значения. Некоторым объектам графа приписываются имена. Такое имя используется как точка входа в граф для описания путей при формировании запросов (вершину с именем также называют корнем).
OEM-база данных не имеет фиксированной схемы. Вся семантическая информация содержится в именах ребер графа. Сам же граф может изменяться динамически. Таким образом, база данных имеет «самоописательный» характер. Понятия целостности или корректности данных в OEM не вводится, за счет чего и достигается большая гибкость представления данных.
Рассмотрим пример OEM-базы данных сотрудников университетской группы, занимающейся вопросами управления данными приведенный на рис. 1.
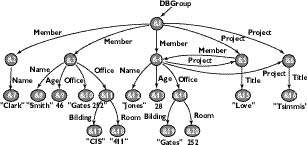 |
| Рис. 1. База данных OEM |
На этом примере видно, что каждый объект имеет свой уникальный идентификатор (на рисунке изображен числом, перед которым стоит символ &), кроме того, одному из объектов с идентификатором &1 присвоено имя DBGroup, таким образом, все пути в графе будут описываться от этой вершины. Обратим особое внимание на то, что одни и те же сущности реального мира представлены в этой базе данных с помощью различных структур или типов данных. Например, о сотруднике группы с именем Clark известно только его имя, в то время как о Smith содержится более полная информация, при этом для ее описания используется два ребра с одним именем, что допустимо в OEM и является типичным примером неправильности данных. Или номер комнаты (&18) представлен в виде строки, тогда как номер другой комнаты (&20) целое число.
ОЕМ-модель в чистом или несущественно модифицированном виде используют практически все системы управления полуструктурированными данными. Так, например, для представления в данной модели XML документов необходимо, чтобы ребра были упорядочены. В системе Strudel (описана в главе «Полуструктурированные данные и WWW») помимо графа существует понятие коллекции, которая представляет собой множество объектов, содержащихся в графе, т.е. на интуитивном уровне множество указателей на вершины графа.
Описание структуры
Как уже было сказано в первой главе, системы управления полуструктурированными данными, как правило, системы с апостериорной схемой. То есть модель данных, используемая этими системами, не предусматривает определения схемы базы данных до ее заполнения. Таким образом, узнать что-либо о структуре базы данных можно только просматривая ее навигационным способом. При таком положении дел, становиться затруднительным использование декларативных языков запросов. Кроме того, наличие информации о структуре базы данных позволило бы оптимизатору запросов работать более эффективно. Для модели данных OEM разработано два метода, позволяющих исправить ситуацию. Суть методов описывается в этой главе.
Первый метод называется путеводитель по данным (DataGuide) [HAG+97] и реализован в системе Lore. Путеводитель по данным представляет собой ориентированный граф с именованными ребрами, соответствующий OEM-модели, который является обобщенным представлением базы данных. Каждый возможный путь в базе данных представлен ровно один раз в путеводителе по данным, верно и обратное, то есть путеводитель по данным не содержит ни одного пути, которого не существует в базе данных. Как правило, путеводитель по данным получается значительно меньше оригинальной базы данных. На рисунке 2 показан пример путеводителя для базы из рисунка 1. В системе Lore путеводитель применяется не только для представления структуры базы для пользователя, но и используется оптимизатором запросов.
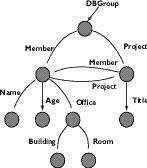 |
| Рис. 2. Путеводитель по данным для рис. 1. |
Суть второго метода состоит в описании схемы OEM базы данных в виде ориентированного графа, где вместо имен ребер и значений простых объектов заданы унарные предикаты. База данных DB соответствует заданной схеме S, если существует соответствие между ребрами и объектами в DB и S, такое что для любого именованного ребра e или любого простого объекта со значением x в DB, существует соответствующее ребро с предикатом p и простой объект с предикатом q в S, такие что p(e) и q(x) принимают истинные значения. Так введенное соответствие есть обобщение понятия подобия [HHK95]. Понятно, что использование этого метода затруднительно для автоматического выведения схемы для существующей базы, как это возможно с помощью первого метода. Этот метод скорее применим для априорного определения схемы. Более подробно с описанным методом и его применением для оптимизации запросов на языке UnQL можно познакомится в работе [BDFS97].
Языки запросов
В конце 80-х годов появилось большое количество работ по использованию графов для моделирования баз данных. Этот всплеск был связан с развитием CASE-средств и систем управления компьютерными сетями. Что привело к появлению таких языков как G,G+ и GraphLog для работы с графами [CMW87,CMW88, CM90]. Эти языки поддерживают возможность описания путей в графах и генерации новых графовых структур. Поскольку, как было сказано в предыдущей главе, большинство систем управления полуструктурированными данными используют разновидности OEM модели, данные в которой представляются в виде ориентированного графа с именованными ребрами, языки запросов над полуструктурированными данными, такие как Lorel [AQM+97] (язык запросов сисмемы Lore), UnQL [BDHS96], StruQL [FFLS97], заимствовали у графовых языков запросов средства описания путей (regular path expression) и генерации новых графовых структур. Но по синтаксису они приближены к широко распространенным SQL и OQL (язык Lorel является расширением OQL).
Средства описания путей в графах включают в себя два вида выражений: описание простого пути (simple path expression) и описание пути с помощью шаблонов (general path expression). Рассмотрим более подробно на примере языка Lorel, каждый из этих видов выражений.
Описание простого пути представляет собой имя вершины, за которым следует последовательность имен ребер, имена разделяются точкой. Используя пример графа на рисунке 1: «DBGroup.Member.Office». Значение данного выражения следующее: это множество всех объектов, которые можно достигнуть начиная с вершины с именем DBGroup, перемещаясь по ребру Member и затем по ребру Office, т.е. объекты: &11, &14. Приведем пример запроса, в котором используется этот вид выражения (запрос 1)
Select DBGroup.Member.Office where DBGroup.Member.Age >30(извлечь информацию об офисах всех челенов группы старше 30 лет)
RESULT
Office «Gates 252»
Office
Building «Cis»
Room «411»
Описание пути с помощью шаблонов является более богатой формой «декларативной навигации» в OEM базах данных, чем описание простого пути. В таких выражениях можно использовать три вида шаблонов:
- Шаблон атомарных значений;
- Шаблон путей (соответсвие последовательности имен ребер);
- Шаблон имен ребер (соответствие последовательности символов в имени ребра).
Рассмотрим пример, содержащий комбинацию всех трех видов шаблонов (запрос 2):
Select DBGroup.Member.Name
Where DBGroup.Member.Office
(.Room%|.Cubicle)?
Like «%252»
RESULT
Name «Jones»
Name «Smith»
В этом запросе выражение Room% является шаблоном имен ребер, который соответствует всем именам, начинающимся с Room. Для шаблона путей символ «|» определяет альтернативу двух имен ребер и символ «?» показывает, что ребра может и не быть. И, наконец, «like %252» определяет, что значением простого объекта должна быть строка, заканчивающаяся «252».
Помимо средств описания путей, языки запросов над полуструктурированными данными, поддерживают многие возможности SQL и OQL, такие как подзапросы, группировку и агрегацию. Кроме того, в большинстве из них существует возможность определения хранимых процедур и внешних предикатов, а также можно использовать «join» и «union» запросы.
Отдельно стоит обсудить формирование вида результата запросов (transformation). Подобная возможность в языке SQL реализуется оператором select. Эта возможность интегрирована в рассматриваемые нами языки запросов для работы с полуструктурированными данными. Но существует и другой подход, навеянный языками запросов над структурированными документами, когда разделяется процесс извлечения информации (язык запросов) и процесс форматирования результата. Так, например, для работы с XML документами используется XQL в качестве языка запросов в совокупности c XSL, предоставляющим богатые возможности форматирования данных. Указанный подход приводит к значительному упрощению языка запросов, переносит часть процесса обработки данных, вырабатываемых в процессе выполнения запроса, на сторону клиента и позволяет с одним и тем же языком запросов использовать различные средства формирования вида результата. Но этот подход имеет и ряд недостатков:
- отсутствует возможность контроля количества данных, передаваемых в ответ на запрос (т.е. клиент получает избыточные данные);
- интеграция средств формирования вида результата и языка запроса позволяет оптимизатору составлять более эффективный план выполнения запроса, так как он имеет больше информации о том, какие данные необходимы клиенту.
Самая важная особенность, которая отличает языки запросов над полуструктурированными данными от графовых, реляционных и объектно-ориентированных языков запросов, обусловлена тем, что данные, из которых необходимо произвести выборку, имеют «размытую структуру», то есть, не существует понятия схемы данных и нет понятия корректности или целостности данных (например, одни и те же сущности реального мира могут моделироваться с помощью различных атомарных типов данных или даже различными подграфами). Это привело к тому, что если реальная структура данных не соответствует предполагаемой структуре при написании запроса, то в ответ на такой запрос не генерируется ошибка, а оптимизатор запроса старается сделать что в его силах (например, в Lorel строковые данные могут быть преобразованы в числовые) и даже если не удается исправить положение ошибка все равно не будет зафиксирована.
В заключении обсуждении языков запросов рассмотрим пример модификации базы данных на примере все того же языка Lorel (структура базы данных изображена на рисунке 1):
Update P.Member +=
( select DBGroup.Member
where DBGroup.Member.Name = «Clark» )
from DBGroup.Project P
where P.Title = «Lore» or
P.Title = «Tsimmis»
В этом примере все члены группы с именем «Clark» добавляются к проектам «Lore» and «Tsimmis». На интуитивном уровне, операторы from и where выполняются первые, для того чтобы определить значение переменной P. Затем, для каждого найденного значения переменной P выражение «P.Member +=» добавляет ребра с именем Мember между P и каждым объектом, возвращаемым подзапросом. В общем говоря, под модификацией данных в Lore понимается создание новых и удаление существующих ребер, создание новых объектов, а также модификация значений простых объектов и имен ребер (удаление объектов в Lore производит система сборки мусора).
Интеграция данных
Основные положенияВо введении говорилось, что одна из главных задач, которую призваны решать системы управления полуструктурированными данными, это интеграция данных из различных источников.
Системы интеграции данных должны обрабатывать запросы для ответа на которые может потребоваться извлечение и обобщение данных из различных источников. При этом трудности интеграции обусловлены следующим.
- Источники могут использовать различные модели данных и предоставлять различные интерфейсы для доступа к своим данным (реляционные, объектные или унаследованные СУБД) или данные источника могут быть не структурированными (HTML файлы, текстовые файлы и т.д.).
- Источники атомарные (т.е. взаимодействовать с источником можно только через предоставляемый им интерфейс и нет никакой возможности повлиять на его внутренние процессы).
Наибольшую популярность приобрели два подхода к решению задачи интеграции данных - хранилища данных и виртуальные хранилища. При использовании первого подхода хранилище заполняется данными из различных источников и затем все запросы обрабатываются с использованием этих данных. Таким образом, актуальность данных не гарантируется, поскольку никакой синхронизации с источником не происходит, но преимущество заключается в том, что время выполнения запроса не велико. При использовании второго подхода, данные хранятся в источниках, а запросы к системе интеграции транслируются в запросы или операции понятные источнику. Данные полученные в ответ на эти запросы к источникам объединяются и предоставляются пользователю. Преимущество виртуальных хранилищ заключается в гарантии того, что пользователь получает только «свежие» данные. Но поскольку источники могут значительно отличаться, возникают трудности связанные с оптимизацией запросов и дополнительные расходы на конвертацию данных во время выполнения запроса, что существенно снижает производительность систем, использующих данный подход. Для построения систем объединяющих большое количество источников, содержание которых часто изменяется (например, Web-серверы), наиболее предпочтителным является виртуальный подход. Поэтому в последнее время активно ведутся исследования именно в этом направлении. Переходя к подробному рассмотрению виртуального подхода, отметим что многие методы, используемые при решении проблем в контексте этого подхода, часто при небольшой модификации применимы и при реализации хранилищ данных.
Рассматривая типичную организацию виртуального хранилища, выделим два уровня логический и физический.
Логический уровень определяется выбором модели данных и языка запросов для этой модели. Выбранная модель используется для представления данных, извлекаемых из всех источников. Таким образом, пользователь системы интеграции получает возможность унифицированного доступа ко всем интегрируемым данным. Выжным требованием к модели данных является обеспечение прозрачности доступа к внешним источникам, т.е. пользователь видит внешние данные как локальные в выбранной модели и не заботится об управлении доступом к источнику.
Физический уровень виртуального хранилища изображена на рисунке 3.
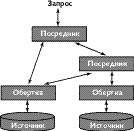 |
| Рис. 3. Сеть посредников и информационных источников |
Данная архитектура основана на распространенной концепции посредников (mediators), предложенной в работе [Wie92]. Рассмотрим два типа компонентов этой архитектуры:
- Обертка (wrapper) используется для хранения информации о внешнем источнике и огранизации к ниму доступа. Происходит это следующим образом. При получении запроса обертка обращается к источнику через предоставляемый им интерфейс. Полученные от источника данные конвертируются во внутренний формат данных хранилища (т.е. в модель данных хранилища). Понятно, что для каждого источника необходима своя обертка.
- Посредник осуществляет интеграцию данных из различных источников (из различных оберток). Посредник может взаимодействовать как с обертками, так и с другими посредниками. Таким образом, предоставляется возможность построения сложной сети взаимодействующих между собой посредников, что позволит обобщать данные различными способами для удовлетворения нужд различных приложений, взаимодействующих с виртуальным хранилищем. Важно отметить, что посредник не содержит данных, а интеграция происходит, как правило, за счет использования техники представлений.
Поскольку при использовании предложенной архитектуры задача построения виртуального хранилища сводится к созданию оберток и посредников, необходимо иметь утилиты, позволяющие легко их генерировать. С этой целью разработаны специальные декларативные языки, на которых описываются обертки и посредники. По этим описаниям и происходит их генерация.
Для демонстрации изложенных выше общих принципов построения виртуальных хранилищ далее будет рассмотрена одна из университетских реализаций системы интеграции данных: TSIMMIS. В качестве примера выбрана именно эта система, поскольку используемый в ней метод описания оберток и посредников с помощью логических правил широко применяется во многих других разработках.
Система итеграции данных TSIMMIS
Система TSIMMIS (The Stanford-IBM Manager of Multiple Information Sources) была разработана в Стенсфордсоком университете (США), при поддержки IBM, специально для решения вопроса интеграции данных из различных источников и является полнофункциональным виртуальным хранилищем [GPQ+96,PGGU95, LYV+97, HGN+97]. На рисунке 4 изображена взаимосвязь основных компонентов системы TSIMMIS.
В слудующих подразделах обсуждаются определенные на рисунке 4 понятия.
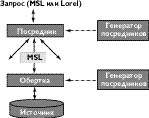 |
| Рис. 4. Компоненты системы TSIMMIS |
Логический уровень
В качестве модели данных для обобщения информации внешних источников была выбрана уже известная нам OEM. В качестве языков запросов пользователю предлагается Lorel (используемый в системе Lore и упоминавшийся выше) и MSL (The Mediator Specification Language). Язык MSL в различных модификациях используется и как язык запросов к хранилищу и как язык для описания оберток и посредников с целью их последующей генерации.
Язык MSLMSL (The Mediator Specification Language) — это логический язык запросов над OEM моделью. Этот язык можно рассматривать как вариант языка Datalog [Ull88, Ull89], предназначенный для работы с полуструктурированными данными.
Запрос на языке MSL представляет собой совокупность правил (rules). Каждое правило состоит из заголовка, символа :- и тела. Заголовок описывает объекты, определяющие вид результата запроса, которые формируются на основе объектов, удовлетворяющих условиям описанным в теле запроса. Для описания заголовка и тела используются шаблоны. Полное описание языка MSL, включающее синтаксис и семантику, можно найти в статье [PGU95]. Здесь мы ограничимся примером, который дает общее представление о языке.
Пример. «Найти имена всех книг, написанных Aho»:- }> }>
Треугольные скобки ассоциируют объекты (точнее имена ребер, которые указывают на объекты) и их значения, тогда как с помощью фигурных скобок описывается структура графа базы данных.
Процесс выполнения приведенного запроса состоит в поиске в базе данных путей вида library.book.author, начиная с корневой вершины (library), для каждого найденного пути происходит связывание переменной X c значением объекта title, если соответствующий объект author имеет значение ?Aho?. Заголовок определяет, что для каждого связанного с X значения создается объект booktitle. Все объекты, созданные в результате выполнения запроса, являются подобъектами объекта answer, который представляет собой корень результата запроса.
Физический уровеньФизический уровень системы TSIMMIS составляют традиционные компоненты: посредники (mediator) и обертки (wrapper). Взаимодействие между этими компонентами происходит таким же образом как было описано выше в разделе «Oбщие положения», т.е. обертки предоставляют возможность доступа к внешним источникам, тогда как посредники используются для интеграции данных из различных источников и могут взаимодействовать как с обертками, так и с другими посредниками. При этом взаимодействие между ними происходит в терминах OEM модели. Обертки и посредники системы TSIMMIS генерируются с помощью специальных утилит по описанию на языке МSL. Рассмотрим, каким образом создается каждая из этих компонент.
Генерация оберткиГенерация обертки производится с помощью утилиты, подробно описанной в статье [Vas96]. На входе эта утилита получает описание обертки в форме правил (множества пар) вида:
МSL шаблон // действие //
Действие представляет собой последовательность операций, которые необходимо выполнить при выполнении запроса удовлетворяющего шаблону.
Например, предположим что мы хотим создать обертку для доступа к библиографической поисковой системе. Для этого определяем правила подобные следующему:
:- }> }> // sprintf(lookup-query, «find author %s», $Au) //
Сгенерированная по такому описанию обертка, получая запросы, сравнивает их с шаблонами из описания. Если запрос удовлетворяет нашему шаблону, то происходит связывание переменной $AU со значением взятым из запроса и выполняется связанное с шаблоном действие (которое использует переменную $AU). Примером запроса, удовлетворяющего шаблону, может быть следующий (о нем говорилось в предыдущем разделе):
:- }> }>
Для этого запроса выполняется C функция sprintf из раздела действие приведенного выше шаблона, результатом которой будет присвоение переменной lookup-query строки «find author Aho». Эта строка затем будет послана библиографической поисковой системе.
Если обертка получает запрос, который не соответствует не одному из указанных при генерации шаблонов, то применяется метод декомпозиции запроса на составляющие, каждая из которых проверяется на соответствие шаблонам.
Генерация посредникаСоздание посредников в системе TSIMMIS происходит аналогично процессу генерации оберток, рассмотренному в предыдущем разделе. То есть с помощью утилиты, по описанию на языке MSL, происходит генерация посредника. Отличие состоит в том, что при написании MSL правил не надо указывать никаких действий, поскольку посредники в системе TSIMMIS сами не содержат данных, а являются суть представлениями над обертками или другими посредниками.
Рассмотрим пример интеграции двух источников. Первый источник является реляционной базой данных, которая содержит информацию о сотрудниках и студентах одного из факультетов (Faculty of Computer Science или сокращенно cs) университета в виде двух отношений:
Employee (name, age, salary) Student (name, age, course)
Обертка cs_faculty предоставляет интерфейс для доступа к этому источнику.
Второй источник представляет собой некоторое хранилище информации о сотрудниках и студентах всего университета. В этом хранилище (помимо всего прочего) для каждого человека указано кто он студент или сотрудник и также информацию о том к какому факультету он принадлежит. Доступ ко второму источнику осуществляется с помощью обертки с именем university.
Опишем посредник med, который предоставляет информацию, интегрированную из двух описанных выше источников, о всех лицах (cs_person) имеющих отношение к факультету cs:
}> :-
}> @university
AND
}> @cs_faculty
Здесь после символа @ указано имя компонента, к которому относится данная часть правила. В общем случае это может быть имя обертки или посредника.
Полуструктурированные данные и WWW
Последние работы по интеграции информации и управлению полуструктурированными данными используются для решения проблем связанных с глобальной сетью Интернет. Многие рассмотренные в этой работе идеи применяются (возможно с небольшими изменениями) для создания Интернет поисковых систем и систем управления Web-серверами.
До недавнего времени системы поиска в Интернет использовали метод контекстно-зависимого поиска, то есть поиск производился по ключевым словам и без учета структуры анализируемых данных. В последнее время ведутся работы по созданию Интернет поисковые системы разработанные на основе технологии виртуальных хранилищ. Архитектура виртуальных хранилищ, рассмотренная в предыдущей главе, полностью подходит для построения таких систем. Но графовую модель данных, такую как OEM, в чистом виде использовать неудобно. Поэтому, как правило, используют расширенную графовую модель, в которой объекты представляют собой Web-страницы или ее части, а для отображения связей между страницами (например, гипертекстовые ссылки) или их частями используются различные виды ребер. Такая адаптация модели данных привела к созданию специализированных Web языков запросов, хотя в основе своей эти языки мало отличаются от рассмотренных в главе «Языки запросов». Например, существует две разновидности языка UnQL: одна для ОЕМ подобной модели данных, вторая для модели данных созданной для работы с HTML файлами.
Условно, Web языки запросов (и модели данных соответственно) можно разделить на два поколения. К первому поколению относятся языки, которые трактуют Web-страницы как атомарные объекты с двумя свойствами: страницы содержат или не содержат текст удовлетворяющий шаблону, описанному в запросе, и могут указывать друг на друга, за счет использования гипертекстовых ссылок. Таким образом, внутренняя структура страницы не учитывается. К таким языкам можно отнести WebSQL [MMM97], W3QL [KS95], WebLog [LSS96] и WQL[LSCH98]. Языки второго поколения расширяют языки первого в следующем направлении: на ряду с внешними ссылками соединяющими Web-страницы моделируется и внутренняя структура документа. Примерами языков второго поколения могут служить
WebOQL [AM98], StruQL [FFLS97] и Florid HLLS97].
Поскольку Web-серверы предоставляют доступ к информации со сложной структурой, к тому же источники этой информации очень разнородны (например, базы данных или информация с других Web-серверов), целесообразно применить для построения и поддержания этих серверов методы работы с полуструктурированными данными. Для понимания проблем, возникающих при работе с Web-сервером, рассмотрим задачи, которые необходимо решить при формировании его информационного наполнения.
- Определить какие данные и из каких источников должны быть доступны.
- Спроектировать структуру информации, доступную пользователю Web-сервера.
- Разработать визуальное представление данных.
Во многих случаях администратор пишет HTML страницы вручную или создает программы для их генерации. Таким образом, одновременно происходит процесс определения структуры Web-сервера (гипертекстовые ссылки между страницами и наполнение страниц) и визуального представления (например, форматирование информации на странице), а следовательно все три перечисленные проблемы решаются одновременно. Как правило, большинство систем управления Web-серверами, разработанные на сегодняшний день, позволяют решать эти проблемы раздельно, что существенно упрощает создание и поддержание Web-сервера. Достигается это следующим образом: архитектура системы управления Web-сервером строится таким образом, что выделяются три логических уровня, на каждом из которых решается одна из перечисленных задач.
В качестве примера системы управления Web-серверами рассмотрим систему Strudel [FFLS97, FFLS98]. Одна из основных целей, преследуемая разработчиками при создании этой системы, была-развитие и применение разработанных метода управления полуструктурированными данными для решения проблем построения и поддержания информационного наполнения Web-серверов.
Архитектура системы Strudel изображена на рисунке 5.
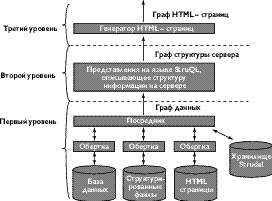 |
| Рис. 5. Архитектура систмы Strudel |
Как видно из рисунка, в системе можно выделить три логических уровня. На каждом уровне для представления данных используется одна модель данных (разновидность OEM модели). Причем, для доступа к каждому уровню применяется один язык запросов StruQL (Site Transformation Und Query Language) (об этом языке рассказывалось в главе «Языки запросов»). На первом уровне граф данных (Data Graph) описывает логическую структуру информации доступной на Web-сервере. Эта информация интегрируется из различных внешних источников и собственного хранилища данных Strudel. Методы используемые при интеграции информации заимствованы из системы TSIMMIS, рассмотренной в предыдущей главе. На втором уровне создается один или несколько графов структуры сервера (Site Graphs) с помощью представлений на языке StruQL. Возможность использования нескольких графов структуры сервера позволяет учитывать потребности различных пользователей, использующих Web-сервер. На третьем уровне для каждого графа структуры сервера генерируется один или несколько графов HTML страниц (HTML Graphs), т.е. визуальное представление информации на Web-сервере.
Основные преимущества системы Strudel заключаются в декларативном описании структуры информации на Web-сервере (второй уровень) и разделение данных и их визуального представления (выделение третьего уровня). Таким образом, структура Web-сервера становиться более гибкой и процесс ее создания и поддержания существенно упрощается.
Заключение
Управление полуструктурированными данными — это новое направление исследований, которое зародилось несколько лет назад. Летом 1998 года 16 ведущих мировых специалистов в области управления данными издали манифест [BBC+98], в котором перечислены три основные направления исследований на ближайшие десять лет, среди которых и управление полуструктурированными данными.
Описанные методы управления полуструктурированными данными не решают в полной мере всех назревших проблем и нуждаются в существенной доработке. Кроме того, многие механизмы реализованные в большинстве традиционных СУБД, такие как триггеры и транзакции, совершенно не изучены в контексте полуструктурированных данных. Скорость работы существующих на сегодняшний день систем управления полуструктурированными данными не удовлетворительна, поэтому одна из основных задач повышение эффективности их работы, например, за счет разработки методов индексирования полуструктурированных данных. В настоящее время активно ведутся работы по развитию техники представлений над полуструктурированными данными [AGM+98, AMR+98].
Выход в начале 1998 года стандарта XML, оказал большое влияние на работы по управлению полуструктурированными данными. В последнее время появилась тенденция к изменению существующих систем и созданию новых для хранения полуструктурированных данных в формате XML. Например, ведется работа по созданию на основе системы Lorel системы управления XML базами данных, в работе [DFS98] рассказано, как можно использовать реляционную СУБД для хранения данных в формате XML, разработан язык запросов XML-QL [DFF+98] для работы с данными в XML формате и даже появилась первая коммерческая реализация: XML информационный сервер Tamino компании Software AG.
Об авторe
C Максимом Гриневым можно связаться по электронной почте по адресу: E-mail: maxim-grinev@mtu-net.ru| Литература |
| [A96] S. Abiteboul. Querying Semi-Structured Data. Доступна по адресу: http://pub-db.stanford.edu/publist.html [AGM+98] S. Abiteboul, R. Goldman, J. McHugh, V. Vassalos, Y. Zhuge. Views for Semistructured Data Доступна по адресу: http://pub-db.stanford.edu/publist.html [AK97] N. Ashish, C. A. Knoblock. Wrapper Generation for Semi-structured Internet Sources. Workshop on Management of Semistructured Data, May 1997. Доступна по адресу: www.research.att.com/~suciu/workshop-papers.html [AM98] G. Arocena, A. Mendelzon. WebOQL: Restructuring documents, databases and webs. In Proc. of Int. Conf. on Data Engineering (ICDE), Orlando, Florida, 1998. [AMM97] P. Anzeni, G. Mecca, P. Merialdo. Semistructured and Structured Data in the Web: Going Back and Forth. Workshop on Management of Semistructured Data, May 1997. Доступна по адресу: www.research.att.com/~suciu/ workshop-papers.html [AMR+98] S.Abiteboul, J. McHugh, M. Rys, V. Vassalos, J. Wiener. Incremental Manintenance for Materialized Views over Semistructured Data. Proceedings of the 24th VLDB Conference New York, USA, 1998. Доступна по адресу: http://pub-db.stanford.edu/ publist.html [AQM+97] S. Abiteboul, D. Quass, J. McHugh, J. Widom, J. Weiner. The Lorel query language for semistructured data. International Journal on Digital Libraries, 1(1):68-88, April 1997. Доступна по адресу: http://pub-db.stanford.edu/ publist.html [BBC+98] P. Bernstein, M. Brodie, S. Ceri, D. DeWitt, M. Franklin, H. Garcia-Molina, J. Gray, J. Gray, J. Held, J. Hellerstein, H. V. Jagadish, Michael Lesk, D. Maier, J. Naughton, H. Pirahesh, M. Stonebraker, J. Ullman. The Asilomar Report on Database Research. ACM SIGMOD Records, 1998. [BDFS97] P. Buneman, S. Davidson, M. Fernandez, D.Suciu. Adding Structure to Unstructured Data. http://db.cis.upenn.edu/Publications/ [BDHS96] P. Buneman, S. Davidson, G. Hillebrand, D.Suciu. A query language and optimization techniques for unstructured data. In Proc. of ACM SIGMOD Conf. On Management of Data, pages 505-516, Montreal, Canada, 1996. [CM90] M. Consens, A. Mendelzon. GraphLog: a visual formalism for real life recursion. In Proc. Of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), page 404-416, Atlantic City, NJ, 1990. [CMW87] I. F. Cruz, A. O. Mendelzon, P. T. Wood. A graphical query language supporting recursion. In Proc. Of ACM SIGMOD Conf. On Management of Data, pages 323-330, San Francisco, CA, 1987. [CMW88] I. F. Cruz, A. O. Mendelzon, P. T. Wood. G+: Recursive queries without recursion. In Proc. Of the Second International Conference on Expert Database Systems, pages 355-368, 1988. [DFS98] A. Deutsch, M. Fernandez, D. Suciu. Storing Semistructured Data with STORED. http://db.cis.upenn.edu/Publications/ [DFF+98] A. Deutsch, M. Fernandez, D. Florescu, A. Levy, D. Susiu. A query Language for XML. http://db.cis.upenn.edu/Publications/ [FFLS97] M. Fernandez, D. Florescu, A. Levy, D. Suciu. A query language for a web-site management system. SIGMOD Record, 26(3):4-11, September 1997. Доступна по адресу: www.acm.org/sigs/sigmod/record [FFLS98] M. Fernandez, D. Florescu, A. Levy, D. Suciu. Reasoning About Web-Site Structure. [GPQ+96] H. Garcia-Molina, Y. Papakonstantinou, D. Quass, A. Rajaraman, Y. Sagiv, J. Ullman, V. Vassalos, J. Widom. The TSIMMIS Approach to Mediation: Data Models and Languages. Доступна по адресу: www.db.stanford.edu/tsimmis [HAG97] J. McHugh, S. Abiteboul, R. Goldman, D. Quass, J. Widom. Lore: A Database Management System for Semistructured Data. Доступна по адресу: www.db.stanford.edu/lore [HGH+97] J. Hammer, H. Garcia-Molina, S. Nestorov, Ramana Yerneni. Template-Based Wrappers in the TSIMMIS System. Доступна по адресу: www.db.stanford.edu/tsimmis [HHK95] M. Henzinger, T. Henzinger, P. Kopke. Computing simulations on finite and infinite graphs. In Proceedings of 20th Symposium of Foundations of Computer Science, pages 453-462, 1995. [HLLS97] R. Himmeroder, G. Lausen, B. Ludascher, C. Schlepphorst. On a declarative semantics for web queries. In Proc. of the Int. Conf. on Deductive and Object-Oriented Databases (DOOD), pages 386-398, Singapore, December 1997. Springer. [KS95] D. Konopnicki, O. Shmueli. W3QL: A query system for the World Wide Web. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), pages 54-65, Zurich, Switzerland, 1995. [LSCH98] W. Li, J. Shim, K. Canadan, Y. Hara. WebDB: A web query system and its modeling, language, and implementation. In Proc. IEEE Advances in Digital Libraries 1998. [LSS96] L. Lakshmanan, F. Sabri, I. Subramanian. A declarative language for querying and restructuring the Web. In Proc. of 6th International Workshop on Research Issues in Data Engineering, RIDE 1996, New Orleans, February, 1996. [LYV+97] C. Li, R. Yerneni, V. Vassalos, H. Garcia-Molina, Y. Papakonstantinou, J. Ullman, M. Valiveli. Capability Based Mediation in TSIMMIS. Доступна по адресу: www.db.stanford.edu/tsimmis [MMM97] A. Mendelzon, G. Mihaila, T. Milo. Querying the WWW. International Journal on Digital Libraries, 1(1):54-67, April 1997. [NAM97] S. Nestorov, S. Abiteboul, R. Motwani. Inferring Structure in Semistructured Data. Workshop on Management of Semistructured Data, May 1997. Доступна по адресу: www.research.att.com/~suciu/workshop-papers.html [PGGU95] Y. Papakonstantinou, A. Gupta, H. Garcia-Molina, J. Ullman. A Query Translation Scheme for Rapid Implementation of Wrappers. Доступна по адресу: www.db.stanford.edu/tsimmis [PGMW95] Y. Papakonstantinou, H. Garcia-Molina, J. Widom. Object exchange across heterogeneous information sources. In Proceedings of the Eleventh International Conference on Data Engineering, pages 251-260, Taipei, Taiwan, March 1995. [PGU95] Y. Papakonstantinou, H. Garcia-Molina, J. Ullman. MedMaker: A Mediation System Based on Declarative Specifications. Proc. Intl. Conf. on Data Engineering, March, 1996. [Ull88] J. Ullman. Principles of Database and Knowledge-Base Systems, Vol I: Classical Database Systems. Computer Science Press, New York, NY, 1988. [Ull89] J. Ullman. Principles of Database and Knowledge-Base Systems, Vol II: The New Technologies. Computer Science Press, New York, NY, 1989. [Vas96] V. Vassalos. Wrapper specification and query processing in the TSIMMIS project. [Wie92] G. Wiederhold. Mediators in the architecture of future information systems. In IEEE Computer 25:3, pp. 38-49. |
