Новая DSP-архитектура NeuroMatrix и традиционный RISC - единое вычислительное ядро процессора NM6403
В настоящее время рядом ведущих микроэлектронных фирм выпускаются процессоры, ориентированные на выполнение задач цифровой обработки сигналов и управления для различных применений. К ним относятся процессоры Digital Baseband для сотовых телефонов, универсальные DSP - процессоры для различных телекоммуникационных и специальных приложений, таких, как эмуляция различных нейронных сетей, обработка изображений и радиолокационных сигналов.
Существуют различные подходы к созданию эффективных процессорных архитектур, реализующих потребности по производительности и гибкости. Широкое распространение и доступность технологии полузаказных интегральных схем и появление мощных автоматизированных систем проектирования и синтеза интегральных схем (Cadence, Synopsys) привело к зарождению нового рынка интеллектуальной собственности - рынка процессорных ядер.
Во всем мире происходит процесс возникновения большого количества (компаний без собственного производства) fabless компаний, производящих интеллектуальную собственность (IP- Intellectual property) в виде процессорных ядер, лицензии на использование которых свободно продаются и покупаются. За последние пять лет этот ранок окреп и выявил ряд лидеров (ARM RISC, OAK DSP, TI ?C54 DSP, Hitachi SH-DSP и др.), ядрами которых пользуется большое число полупроводниковых компаний. Положительные стороны такого подхода очевидны - это повторное использование IP, сокращающее время выпуска конечного продукта, наличие широкого спектра прикладного и системного программного обеспечения, обеспечивающего преемственность поколений процессоров. Вместе с тем простое объединение на кристалле двух или более ядер от разных производителей зачастую приводит к проблемам на системном уровне. К таким проблемам можно отнести синхронизацию процессов и обмен данными, использование различных инструментальных средств программирования, в ряде случаев аппаратную избыточность и невозможность внести изменения в систему команд и формат обрабатываемых данных. Все это приводит к снижению общей производительности и усложнению прикладного ПО. Другим подходом, позволяющим использовать положительные стороны IP методологии и снизить влияние отрицательных, является применение «усовершенствованной схемы обработки потока данных и команд в рамках одного процессора» [1]. В этом случае процессор имеет мощное основание в виде высокопроизводительного RISC-процессора, на базе которого строится все остальное проблемно-ориентированное здание. В качестве дополнительных узлов могут быть использованы всевозможные ускорители: трехмерной графики, DSP, векторно-матричных функций и т.д. Данный подход упрощает архитектуру, делая ее единой, работающей под одной системой команд и способной обрабатывать множественный поток данных (архитектура SIMD). Подобная архитектура реализована в процессоре NeuroMatrix NM6403, разработанном в НТЦ «Модуль» и изготовленном компанией SAMSUNG Semiconductor по 0,5-микронной КМОП технологии в 1998 году.
Концепция
Для большинства DSP-приложений, взвешенное суммирование является доминирующим и требующим применения аппаратных узлов типа матричных умножителей с аккумулятором (MAC), для обеспечения производительности, необходимой для работы в реальном масштабе времени. Полупроводниковые компании, диктующие моду в современной DSP-индустрии, идут путем наращивания числа одновременно исполняемых команд (суперскаляр, VLIW) и/или увеличения количества MAC-операций в единицу времени. Одним из свежих примеров такого подхода является
DSP компании Texas Instruments TMS320C6201 (C6x). Его суперскалярная-VLIW архитектура включает восемь исполнительных узлов и способна эффективно выполнять две MAC-операции за один процессорный такт.
Идея, предложенная авторами статьи [2] и реализованная в процессоре NM6403, заключается в создании универсального узла, одновременно выполняющего столько MAC-операций, сколько требуется для оптимизации критерия производительность/точность. При решении ряда задач, связанных с обработкой большого потока «коротких»данных в реальном масштабе времени (обработка полутонового и черно-белого видео [3], радиолокация [4], нейросети и др.), традиционные DSP-архитектуры, имеющие 16-ти и 32-разрядный формат данных, используются неэффективно. Жесткая фиксация разрядной сетки, не позволяет подстроиться под изменяющийся формат данных. Попытку исправить положение предприняла Intel в своей MMX технологии, где возможна настройка аппаратуры на выполнение четырех 16-разрядных операций умножения и двух 32-разрядных операций сложения за один процессорный такт. Существует ряд нейропроцессоров, выполняющих MAC операции над данными, разрядность которых может быть задана программно в диапазоне от 1 до 16 [5, 6]. Как правило, такие процессоры обрабатывают 1-, 8- и 16- разрядные данные. Исключение составляет процессор L-neuro компании Philips [7], работающий с входными данными любой разрядности от 1 до 8. Однако в данном процессоре используется последовательный способ обработки данных, что является одной из основных причин его относительно низкой производительности.
Новая архитектура NeuroMatrix, позволяет обойти все вышеперечисленные ограничения и производить MAC операции над данными переменной разрядности от 1- до 64-разрядов, причем количество MAC, выполняемых в единицу времени, зависит от числа и разрядности операндов, умещающихся в 64-разрядном слове данных.
NeuroMatrix Engine
Архитектура NeuroMatrix предоставляет уникальную гибкость в выборе требуемого уровня производительности и точности для процедур умножения с накоплением. Исходя из требований приложения, можно выбрать необходимую длину операндов и результатов, упакованных в 64-разрядные слова данных. Количество MAC будет зависеть от количества и длины операндов и результатов. Наивысшая производительность достигается в случае использования 1-разрядных операндов. В этом случае, при тактовой частоте 50 МГц производительность составляет 14,4 GMAC (миллиардов умножений с накоплением). Для увеличения точности вычислений, можно использовать операнды длиной до 32-разрядов. Длина операндов может быть любой, даже не кратной степени двойки. В предельном случае, где используются 32-разрядные операнды и 64-разрядный результат, производительность составит
50 MMAC (миллионов арифметических умножений с накоплением). Такой подход позволяет делать выбор между точностью вычислений и их производительностью. Пример конфигурации NeuroMatrix Engine, для случая умножения матрицы байт на вектор байт показан на рис. 1.
 |
| Рис. 1. NeuroMatrix Engine |
Ядром архитектуры является регулярная структура, похожая на матричный умножитель. Матрица состоит из 64x64 ячеек, каждая ячейка содержит элемент памяти (flip-flop) и несколько логических элементов. Матрица может быть разделена на несколько подматриц двумя 64-разрядными программируемыми регистрами: MB и DB. Эти регистры определяют границы MAC и входных данных соответственно. Например, для 8-разрядных данных (Xi) и
8-разрядных коэффициентов (Wi) количество подматриц (макроячеек) составляет 24. Каждая макроячейка производит операцию умножения элементов входных данных Xi на предварительно загруженные коэффициенты Wi и накапливает результат из макроячеек, расположенных выше, и входа Vi. Таким образом, каждый столбец вычисляет 21-разрядный результат MAC-операции над восемью данными и восемью коэффициентами. В нашем случае, имеется три таких столбца, которые производят 24 MAC-операции за один процессорный такт. При значении тактовой частоты 50 МГц, производительность составляет 1,2 GMAC.
На загрузку весовых коэффициентов в матрицу, требуется 32 такта. Для снижения накладных расходов, связанных с перезагрузкой матрицы весов, применяется «теневая» матрица SM. Новые коэффициенты загружаются в «теневую» матрицу на фоне вычислений и могут быть переданы в рабочую матрицу за один процессорный такт.
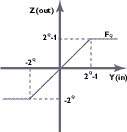 |
| Рис. 2. Функция насыщения |
Функции насыщения (Saturation Functions) рис. 2 используются для снижения разрядности результатов и защиты от арифметического переполнения.
В примере приведенном на рис. 1, функция насыщения снижает число значащих разрядов с 21 до 8. Ширина входов функции насыщения эквивалентна ширине колонки (выхода MAC), ширина выхода функции должна быть эквивалентна входу MAC. На первом проходе функции насыщения снижают количество значащих разрядов, на втором проходе, рабочая матрица упаковывает 8-разрядные выходы в 64- разрядные слова данных. Все параметры функций насыщения программируются.
Конфигурация матрицы может быть изменена динамически в течение вычислений. Вычисления могут быть начаты с максимальной точностью и минимальной производительностью, но при определенных условиях можно достичь пиковой производительность путем снижения точности.
Некоторые результаты вычисления соотношения производительность/точность приведены на диаграмме показанной на рис. 3.
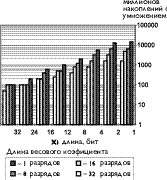 |
| Рис. 3. Диаграмма производительность/точность |
Как видно из диаграммы, программист может выбрать желаемую точку в диапазоне - 50 MMAC - 14400 MMAC. При переходе от арифметических операций к логическим (бинарные данные и коэффициенты), пиковая производительность достигает более 50 GOPS. В какой-то степени, подобную гибкость можно сравнить с действиями водителя автомобиля. При движении по ровной и свободной дороге можно выбрать высшую передачу, дабы не перегружать двигатель и двигаться с высокой скоростью. Как только вы попадаете на разбитую дорогу с множеством ям (высокая точность вычислений), необходимо переключиться на пониженную передачу.
Следует отметить еще одну интересную особенность NeuroMatrix Engine. При использовании бинарных значений (1/0) коэффициентов, матрица превращается в мощный коммутатор, способный перенаправить поток входных данных Xi в любое направление Yi. Другими словами, перемещение любого разряда из 64- разрядных входных данных в любую другую позицию 64-разрядного выходного слова производится за один-два процессорных такта.
Структура процессора
Как уже отмечалось выше, NM6403 представляет собой систему на кристалле (system-on-a-chip), предназначенную для обработки 32-разрядных скалярных данных и векторных данных программируемой разрядности, упакованных в 64-разрядные слова.
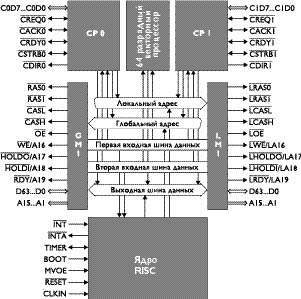 |
| Рис. 4. Структурная схема процессора |
Структурная схема процессора (рис. 4) содержит следующие основные узлы.
RISC CORE - центральный процессорный узел, представляющий собой суперскалярный 5-ти ступенчатый 32-разрядный RISC-процессор с оригинальной системой команд, предназначенный для выполнения арифметико-логических операций над 32-разрядными скалярными данными, формирования 32-разрядных адресов команд и данных при обращениях к внешней памяти и выполнения всех основных функций по управлению работой NM6403 процессора. В состав RISC CORE входят АЛУ, сдвигатель, два генератора адресов данных, 8 регистров общего назначения, 8 адресных регистров, счетчик команд, регистр слова состояния процессора, регистр запросов прерываний, буфер и регистры команд, два программируемых таймера.
VCP - векторный сопроцессор (http:// www.module.ru/files/nm03ao11br.pdf), предназначенный для выполнения арифметических и логических операций над 64-разрядными векторами данных программируемой разрядности. Ядром VCP, является запатентованная реализация NeuroMatrix Engine.
LMI и GMI - два идентичных блока программируемого интерфейса с локальной и глобальной 64-разрядными внешними шинами, к каждой из которых может быть подключена внешняя память, содержащая до 231 32-разрядных ячеек. Каждый блок программируемого интерфейса обеспечивает эффективную работу процессора с двумя банками внешней памяти различной емкости, типа (SRAM, EDO DRAM) и различного быстродействия без использования внешнего контроллера. В каждом блоке предусмотрена аппаратная поддержка режима разделяемой памяти для трех различных мультипроцессорных конфигураций внешней шины (http://www.module.ru/files/nm03ao11br.pdf). Выборка команд из внешней памяти осуществляется 64-разрядными словами, каждое из которых представляет собой одну 64-разрядную команду или две 32-разрядных команды. Процессор использует 32-разрядный вычисляемый адрес при обращении во внешнюю память. Доступное адресное пространство процессора равно 16 Гбайт.
CP1 и CP2 - два идентичных коммуникационных порта, каждый из которых обеспечивает обмен информацией по двунаправленному байтовому линку между процессором и его абонентом. Они предназначены для построения высокопроизводительных многопроцессорных систем на основе процессоров NM6403 и полностью совместимы с коммуникационным портом процессора TMS320C4x компании Texas Instruments. Каждый коммуникационный порт имеет встроенный контроллер ПДП, позволяющий обмениваться 64-разрядными данными с внешней памятью в фоновом режиме.
Области применения
Бурно развивающиеся рынки телекоммуникаций, растущая интеллектуальность бытовой электроники, снижение массо-габаритных характеристик встраиваемых систем требуют все новой и более мощной элементной базы и/или нетрадиционных подходов к решению задач (нейросети). Архитектура большинства телекоммуникационных приложений (например, сотовая телефония) представляет собой объединение управляющей части (protocol stack) и обрабатывающей части (voice&data encoding). Такое построение систем требует наличия высокоэффективных аппаратных средств поддержки задач управления (MCU) и обработки (DSP). Процессор NM6403 имеет необходимые аппаратные ресурсы для эффективной поддержки обеих задач. Некоторые наиболее типичные функции, используемые для обработки сигналов, изображений и эмуляции нейросетей приведены в табл. 1.
Таблица 1
| Компания, тип процессора | Фильтр Собеля* | Быстрое преобразование Фурье** | Быстрое преобразование Уолша-Адамара*** | Нейросеть прямого распространения**** |
| Intel, Pentium II/300МГц | Нет данных | 200 мкс | 2,58 сек | Нет данных |
| Intel, Pentium/200 МГц | 21 кадр/сек | Нет данных | 2,80 сек | Нет данных |
| Texas Instruments, TMS320C40/50 МГц | 6,80 кадров/сек | 464 мкс (11588 тактов) | Нет данных | Нет данных |
| НТЦ «Модуль», NM6403/40 МГц | 68 кадров/сек | 102 мкс (4070 тактов) | 0,42 сек | 1,54 сек |
** 256 точек, 32 разряда,
*** 2М точек, входные данные - 5 разрядов, результат - 32 разряда,
**** 1024 слоя,1024 нейрона/слой, входы и веса - 8 разрядов
Следует отметить, что результаты производительности получены путем прогона реальных ассемблерных программ, оптимизированных для различных платформ. Для процессора NM6403 использовался набор инструментальных программ (SDK) (http://www.module.ru/ruproducts/basesoft.html) и ускорительная плата NM1 для шины PCI (http://www.module.ru/ ruproducts/mc401.html), разработанные в НТЦ «Модуль».
Как видно из таблицы 1, наиболее эффектные результаты были получены при решении задач двумерной фильтрации видеоизображений (фильтр Собеля) и преобразования Уолша-Адамара, применяемого, например, в сотовой телефонии стандарта CDMA. В задаче преобразования Адамара, уникальные возможности NeuroMatrix Engine, позволили настроить рабочую матрицу на выполнение 128 операций сложения/вычитания за один процессорный такт. Это дало выигрыш в производительности, по сравнению с Pentium II/300МГц в шесть раз, что эквивалентно производительности 500-мегагерцевого процессора Alpha.
Наиболее часто используемое преобразование в DSP приложениях - Быстрое Преобразование Фурье - выполняется процессором NM6403 (0,5 мкм, 40 МГц) за 102 мкс. В таб. 1 приведено сравнение с наиболее распространенным среди российских разработчиков TI DSP TMS320C4x (0,8 мкм, 25 МГц). Этот DSP был разработан около десяти лет назад по 0,8 микронной технологии и сравнение с ним не вполне корректно. Наиболее современный DSP с фиксированной точкой - TI TMS320C62x(0.35 мкм, 200 МГц) выполняет эту задачу за 20 мкс. Как можно заметить, соотношение производительностей C62x/NM6403 составляет 5 раз. Эта величина полностью определяется технологией изготовления и, следовательно, тактовой частотой. Если сравнить количество тактов, требуемых для выполнения данного преобразования, то в этом случае соотношение C62/NM6403 составляет примерно 1, что является показателем эффективности NeuroMatrix архитектуры и для традиционных DSP-приложений. Сравнение архитектурных особенностей и производительности NM6403 с рядом современных DSP с фиксированной точкой приведено в таблице (http://wwwwin.module.ru/files/dsp_comp.pdf).
В октябре 1998 года НТЦ «Модуль» анонсировал следующую версию процессора из семейства NeuroMatrix - NM6404 (http://wwwwin.module.ru/ruproducts/nm6404.html). Этот процессор будет разработан и изготовлен по 0.25 микронной технологии компании Fujitsu. Использование более высокой технологии впервые позволит российской компании выйти на мировой рынок DSP с конкурентно способной продукцией.
Есть еще один немаловажный аспект использования архитектуры NeuroMatrix. Как уже отмечалось, ошеломляющие технологические достижения в микроэлектронике, переход высоких технологий из научных лабораторий, доступных избранным, в промышленные стандарты с ясной и открытой архитектурой позволяет многим разработчикам использовать технологию ASIC/IP для своих изделий. В этом случае, NeuroMatrix Engine и RISC-процессор может быть использован как ядро будущего DSP-процессора или любой другой специализированной СБИС. Представление NM6403 процессора в виде технологически независимого описания на языке Verilog позволяет всем заинтересованным пользователям добавить любые периферийные узлы к существующим ядрам и выпустить собственную микросхему, имеющую мощность самого современного DSP-процессора.
Заключение
Предлагаемый новый 64-разрядный процессор NeuroMatrix NM6403 является высокопроизводительным вычислителем, в котором аппаратно поддерживаются такие операции, как умножение матрицы на матрицу или матрицы на вектор, сложение векторов, вычисление функций насыщения для элементов векторов и другие операции матричной арифметики. Данный процессор производит за один такт обработку векторов, каждый из которых представляет собой 64-разрядное слово, в котором упакованы целочисленные данные. Причем разрядность каждого элемента вектора задается программно и может принимать любое значение в диапазоне от 1 до 64. С уменьшением разрядности данных увеличивается их количество в каждом векторе и тем самым повышается производительность процессора. Процессор имеет аппаратные средства для построения на его основе многопроцессорных систем. Он может интегрироваться в различных системах цифровой обработки сигналов (видеопроцессинг, радиолокация), телекоммуникаций (системы CDMA, интеллектуальные маршрутизаторы, системы защиты информации), а также в перспективной области - эмуляции нейросетей любой размерности.
Напряжение питания процессора 3,3В, частота тактовых импульсов 50МГц, производительность 50 MIPS, 150 MOPS, 50-14.400 MMAC (50.000 MOPS), динамический ток потребления 120 мА (typ), тип корпуса - ball grid array BGA256, цена 39.5 долл. в партии 1000 шт.
Благодарности
Авторы благодарны: Евгению Зуеву (МедиаЛингва, Москва) за участие в разработке компилятора C++, Чен-Бук Ли и Ки-Джин Сонг (Samsung, Франкфурт) за участие в разработке топологии процессора, Хонг-Йонг Ли и Питеру Шельперу (Samsung, Франкфурт) за организацию производства микросхем, Владимиру Маслову (Samsung, Москва) за содействие в решении организационных вопросов. Мы также благодарны многим инженерам фирм Samsung, Cadence и Synopsys за оказание своевременной и квалифицированной технической поддержки, а также всем сотрудникам НТЦ «Модуль», принимавшим участие в этом проекте.
Об авторах
Дмитрий Фомин, Владимир Черников, Павел Виксне, Михаил Яфраков, Павел Шевченко - сотрудники НТЦ «Модуль» (Москва). С ними можно связаться по электронной почте по адресу: dfomine@module.ruЛитература
[1] Манфред Шлетт, Hitachi Europe GmbH, «Тенденции индустрии встроенных микропроцессоров», «Открытые системы» №06, 98, стр.6-11. http://www.osp.ru/os/1998/06/06.htm
[2] П.Е.Виксне, Д.В.Фомин, В.М.Черников, НТЦ «Модуль», «Однокристальный цифровой нейропроцессор с переменной разрядностью операндов», Известия Вузов, Приборостроение, 1996, т.39, №7, стр.13-21, http://www.module.ru/runeuro/proc.html
[3] В.А. Кашкаров, НТЦ «Модуль», «Метод повышения производительности при программировании вычислительных систем обработки изображений», Известия Вузов, Приборостроение, 1996, т.39, №7, стр. 34-39
[4] В. Стручев, В. Левшин, «Цифровая обработка РЛ сигналов. Высокоэффективные процессоры на основе поразрядно-логических методов свертки», ЭЛЕКТРОНИКА: Наука, Технология, Бизнес, № 4, 96. стр. 7-13
[5] NLX420 Data Sheet, June 1992, Neurologix, Inc., 800 Charcot Av., Suite 112, San Jose, Ca. USA.
[6] D. Hammerstrom, «A VLSI Architecture for High Performance, Low Cost, On-chip Learning», Proc. Int. Joint Conf. On Neural Networks IJCNN`90, June 1990, vol.II, pp.537-544, San Diego, Ca, USA.
[7] N.Mauduit, M.Duration, J.Gobert, «Lneuro 1.0: A Piece of Hardware LEGO for Building Neural Network Systems», IEEE Trans. On Neural Networks, vol.3, no. 3, pp. 414-422, May 1992.
