Прежде чем обсуждать перспективы, давайте разберемся с основными характеристиками проектов Веб 1.0 и Веб 2.0. Это позволит понять, почему семантические технологии способны стать основой нового поколения веб-проектов.
В Сети «первого поколения» страницы отделены друг от друга. Для того чтобы посмотреть следующую страницу, необходимо либо уйти с предыдущей, либо открыть ее в новом окне. Обмен информацией между отдельными страницами и сайтами минимален — это в основном простые гиперссылки. Создание сайтов и веб-страниц требует специальных навыков. Следовательно, публикацией в Сети занимаются, как правило, подготовленные люди.
О поколении Веб 2.0 написано много, существуют различные точки зрения на данный предмет, однако здесь будут рассмотрены только основные. Девиз проектов Веб 2.0 — социальность и мобильность. Прежде всего, проекты Веб 2.0 во многом стерли грань между потребителями информации и авторами. Широкое распространение таких готовых решений, как блог-платформы, медиахостинги и другие подобные сервисы, сделало публикацию в Сети простым делом, не требующим специфических познаний в области программирования и дизайна, доступным даже начинающему пользователю. Контент крупнейших проектов Веб 2.0 генерируется и публикуется самими пользователями, причем всячески поощряется коммуникация между ними — это и комментирование сообщений, и создание групп пользователей, и прямой обмен данными. Кроме того, веб-приложения становятся мобильными. Разрешается обратиться к своему аккаунту с любого устройства, способного запустить современный браузер, в любой точке, где есть доступ к Сети, и оказаться в привычном, однократно настроенном рабочем пространстве, где находятся все нужные файлы и приложения.
В общем, проекты поколения «веб два-ноль» серьезно изменили стиль и способы работы пользователей в Сети. От претендентов на роль поколения Веб 3.0 следует ожидать неменьшего эффекта, они также должны существенно изменить способы работы пользователей в Сети. Этому требованию вполне соответствуют приложения семантического веба.
Кардинальное отличие сервисов Semantic Web от остальных, существующих сейчас, состоит в том, что они предназначены для машинной обработки, а не для непосредственного просмотра людьми. Идея семантического веба принадлежит небезызвестному Тимоти Бернесу-Ли. В принципе она сводится к следующему: поскольку создание программ, способных интеллектуально обрабатывать и сопоставлять разбросанные в Сети данные, является делом будущего, необходимо помочь машинам, используя специальную разметку, внедряемую в код уже существующих документов. Дополнительный бонус такого решения — отсутствие необходимости «разрушать до основания» существующую Сеть. Новые средства могут постепенно дополнять уже имеющиеся.
Реализуются все эти идеи с помощью группы взаимо связанных технологий, состав которых может быть представлен в виде так называемого «семантического пирога» — своеобразной пирамиды технологий Semantic Web. Основа «пирога» — технологии Unicode и URI. Первая из них обеспечивает совместимость данных, а вторая позволяет присвоить идентификаторы любым порциям данных, циркулирующих в семантической сети. По своему назначению идентификатор URI подобен URL, однако он может быть присвоен не только отдельному документу, но и любому факту, утверждению либо объекту. Второй уровень «пирога» — технология XML и пространства имен. С помощью XML создается дополнительная разметка сетевых документов, характеризующая их семантику. Пространства имен представляют собой своеобразные словари тегов, создаваемые для конкретных XML-форматов. Каждый тег в пространстве имен обладает уникальным URI. Это позволяет избежать конфликтов в тех случаях, когда различные разработчики используют одинаковые имена тегов для разных объектов.
Следующий уровень Semantic Web — технология Resource Description Framework (RDF). Она помогает описать смысловые связи и отношения между отдельными объектами. В качестве описываемых сущностей могут выступать не только информационные объекты (сайты, изображения, тексты), но все что угодно — люди, города, абстрактные понятия. Выражаются они с помощью высказываний (триплетов). Правила данного описания задаются так называемыми онтологиями — более высоким уровнем семантического веба. Все описания онтологий хранятся в формате RDF, что обеспечивает совместимость и возможность обмена данными. Именно с построением этого уровня семантическая сеть и становится глобальной распределенной базой знаний. Для создания онтологий разработаны соответствующие языки.
Последние два уровня «семантического пирога» связаны с непосредственным применением новых технологий. Прежде всего, это программы-агенты, способные собирать и обобщать сведения, найденные в Сети, а также система определения достоверности информации, опирающаяся на широкое применение цифровых подписей, «черных» и «белых» списков и другие технологии. Подразумевается, что подобные ухищрения позволят автоматически устанавливать степень достоверности информации и сообщать ее пользователю в максимально простом и удобном виде.
В общем, семантический веб состоит из страниц, содержащих специальную разметку, позволяющую компьютерам автоматически собирать и интерпретировать информацию. Характерной особенностью современного семантического веба является наличие двух взаимосвязанных проблем: недостаточное количество подготовленных ресурсов и отсутствие необходимого числа простых в использовании программ, обладающих решающим преимуществом над конкурентами и способных привлечь большую аудиторию пользователей независимо от уровня их подготовки. Еще одна отличительная черта современного Веб 3.0 заключается в том, что все большее количество веб-проектов отдают предпочтение не революционным изменениям, а постепенному внедрению отдельных элементов технологий Веб 3.0. Благодаря этому уже сейчас можно опробовать такие технологии в реальной работе.
Swoogle
Поисковик Swoogle предназначен для индексирования и последующего поиска в Сети различных документов, созданных с применением семантических форматов. Поддерживаются документы как целиком созданные с помощью RDF/XML, N-Triples, N3(RDF), так и содержащие отдельные фрагменты RDF/XML-кода. Данные собираются с помощью индексирования открытых сетевых источников. В настоящее время индекс этого поисковика объединяет около трех миллионов документов в семантических форматах, а также немногим более миллиона документов, содержащих отдельные элементы семантического кода. В общем, Swoogle охватывает более миллиарда триплетов. Данная машина является исследовательским проектом Мэрилендского университета.
Доступны несколько режимов поиска, которые выделены отдельными ссылками, расположенными рядом с полем ввода запроса. Первый режим — поиск по онтологиям. В этом случае в выдачу попадают только документы, размеченные по всем правилам семантических технологий и содержащие определения классов и свойств объектов. Кроме того, можно искать по любым документам с семантической разметкой или вести поиск отдельных терминов, встречающихся в проиндексированных Swoogle документах. В системе действует собственный, достаточно подробный язык составления запросов.
Интерфейс страницы выдачи Swoogle по-спартански прост: лишь ссылки и минимум справочной информации. Swoogle способен выдавать результаты поиска в формате RDF, что позволяет обращаться к нему с помощью собственных приложений. Разработчики Swoogle, в частности, рекомендуют использовать для этого технологии проекта Apache Lucene.
На данном поисковике предлагается бесплатная регистрация. Получив аккаунт, вы снимете ряд ограничений. Например, для незарегистрированных пользователей объем списка выдачи ограничен только первой сотней результатов.
Sig.ma
В настоящее время наиболее интересны и удобны в работе гибридные приложения, объединяющие возможности привычных сервисов и технологии семантического веба. Одним из хороших примеров такого слияния является проект Sig.ma. Данный ресурс предназначен для поиска документов в семантических форматах, однако он выдает результаты в удобном интерактивном интерфейсе. Это еще один исследовательский проект, на сей раз ирландского института DERI.
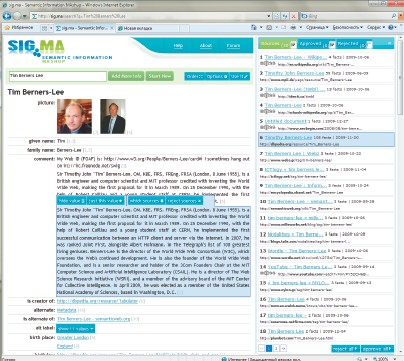
Поиск начинается привычным способом — указанием ключевых слов в поле поиска. Далее система проводит его по собственной индексной базе документов с семантической разметкой. После отработки запроса рабочее пространство делится на две панели: в левой появляется сводная информация о предмете поиска, в правой — общий список тех источников, откуда она извлекалась. Для сортировки списка предлагаются фильтры, с помощью которых можно исключать из него не соответствующие запросу документы. При этом сводка на соседней панели автоматически перестраивается.
Панель сводки делится на тематические разделы, в которых выводятся соответствующие текстовые фрагменты или изображения. Состав разделов зависит от объекта поиска. Например, при поиске информации о человеке система попытается найти его фото, биографические сведения и список публикаций, если у данной персоны таковые есть. Более того, даются сведения о связанных с ней людях, например о коллегах или членах семьи. Отдельно предлагаются ссылки на сайты связанных с объектом поиска учреждений, информация об участии в некоторых социальных сетях, а также список однофамильцев. Заметим, что в настоящее время настолько подробную информацию можно получить лишь о достаточно известных людях. Аналогичным образом обрабатывается и демонстрируется информация об организациях и объектах тематического поиска по ключевым словам.
Кроме проведения непосредственного поиска на сайте проекта, Sig.ma может быть использован для создания виджетов, которые можно внедрить на своем сайте или в своем блоге. В соответствии с требованиями Веб 3.0 предлагается и программный интерфейс, позволяющий обращаться к системе внешним программам-агентам. Информация выдается в форматах RDF и JSON (текстовый формат обмена данными, основанный на JavaScript).
Twine
Эксперименты по совершенствованию социальных ресурсов с помощью элементов семантического веба весьма любопытны. За кажущейся простотой такого решения скрыты довольно интересные идеи. Пожалуй, лучшим из подобных гибридных проектов в настоящее время является ресурс Twine.
Как и обычные социальные менеджеры закладок, Twine позволяет сохранять ссылки на интересные проекты и делиться ими с другими пользователями. Сотрудничество пользователей здесь строится вокруг тематических «твайнов», которые содержат все сообщения и ссылки по теме и в наполнении которых могут участвовать несколько пользователей. Кроме закладок и текстовых фрагментов веб-страниц в аккаунте Twine допустимо сохранять изображения и видеоролики, а кроме того, составлять небольшие собственные заметки. Поддерживается загрузка аналогичных файлов с локального компьютера.

Внутри Twine широко используются технологии RDF и OWL (Web Ontology Language — язык описания онтологий для семантического веба). Накопленный массив данных в семантических форматах позволил реализовать ряд интересных инструментов. Первый из них — автоматический поиск в тексте сохраняемой веб-страницы ключевых слов. Работает он пока лишь для английского языка. По опыту применения Twine могу добавить, что этот механизм, постепенно совершенствуемый, сейчас функционирует весьма достойно, несмотря на некоторый процент ошибок.
Пожалуй, наиболее заметной реализацией семантических технологий в Twine является система поиска. Если посмотреть на боковую панель интерфейса приложения, то можно увидеть не только привычные списки тегов, но и тематические фильтры, помогающие отобрать упоминаемые в сохраненных документах имена, названия организаций, мест и т.п.
Семантические инструменты используются и в работе системы рекомендаций, привычной по многим другим социальным сервисам. Она сообщает пользователю о потенциально интересных «твайнах», сообщениях, а также о других пользователях со схожими интересами.
Twine предлагает ряд дополнительных инструментов. Удобнее всего работать с этим ресурсом с помощью дополнения — «букмарклета» (англ. bookmarklet от bookmark — «закладка» и applet — «аплет», небольшая JavaScript-программа), который размещается на панели закладок браузера. Чтобы отслеживать интересующие темы, можно использовать встроенный агрегатор Interest Feed. Предлагаются почтовые рассылки и RSS-каналы.
GroupMe
На первый взгляд GroupMe — банальный сервис хранения онлайновых закладок. Однако, как и в случае Twine, за простым фасадом скрываются технологии нового поколения. Семантические элементы присутствуют даже на странице регистрации аккаунта. Если у вас есть личная запись проекта FOAF (Friend of a Friend, т.е. «друг друга», в смысле «друг второго уровня», — проект по созданию модели машиночитаемых домашних страниц и социальных сетей), который собирает персональные сведения и хранит их в семантических форматах, то вы можете указать собственный URI в аккаунте GroupMe.
Семантические технологии на данном сервисе применяются для автоматизации простановки тегов к записям. Выставляемые пользователями теги объединяются в тематические группы и затем предлагаются в качестве дополнительных, если пользователь ставит в своей записи какой-либо тег из такой группы. В результате, с одной стороны, для пользователей значительно упрощается и ускоряется работа по описанию сохраняемых ресурсов, с другой — на GroupMe формируется иерархическая структура понятий. Можно даже сказать, что это некая автоматически сгенерированная на основе применяемых пользователями тегов универсальная классификация.
Работа с аккаунтом GroupMe достаточно проста. Пользователю предлагается не только проставлять теги на сохраняемые ресурсы, но и объединять их в тематические группы с помощью удобных рабочих пространств. Наполнение группы контентом осуществляется несколькими способами: стандартным указанием URL нужных ресурсов, посредством поиска в Google и Flickr, а также путем поиска по базе GroupMe. Поддерживается хранение текстов, изображений, аудио- и видеофайлов. Добавить к своей группе ресурсы можно просто перетаскиванием найденных ссылок на рабочее пространство открытой группы. Элементы группы свободно располагаются на рабочем пространстве. Каждый объект имеет собственное контекстное меню. Конечно, такое решение делает работу с объектами максимально наглядной, однако оно усложняет сортировку в группах с большим количеством элементов.
Информация о группах, тегах и документах сохраняется в единой базе ресурса в формате RDF. Кстати, информацию данного сервиса можно экспортировать как в RSS, так и в RDF, что позволяет применять для работы с проектом программы-агенты. Заметим, что вся сохраняемая в GroupMe информация является общедоступной. Каких-либо приватных или групповых хранилищ не предусмотрено, что несколько ограничивает сферу применения ресурса.
Swoogle
Оценка: 3 / 5
Язык интерфейса: английский
Разработчик: UMBC ebiquity group
Сайт: swoogle.umbc.edu
Sig.ma
Оценка: 4 / 5
Язык интерфейса: английский
Разработчик: DERI
Сайт: sig.ma
Twine
Оценка: 4 / 5
Язык интерфейса: английский
Разработчик: Radar Networks
Сайт: www.twine.com
GroupMe
Оценка: 3 / 5
Язык интерфейса: английский
Разработчик: Distributed Systems Institute, University of Hannover
Сайт: groupme.org
О поколении Веб 2.0 написано много, существуют различные точки зрения на данный предмет, однако здесь будут рассмотрены только основные. Девиз проектов Веб 2.0 — социальность и мобильность.
От претендентов на роль поколения Веб 3.0 следует ожидать неменьшего эффекта, они также должны существенно изменить способы работы пользователей в Сети. Этому требованию вполне соответствуют приложения семантического веба.
Отличительная черта современного Веб 3.0 заключается в том, что все большее количество веб-проектов отдают предпочтение не революционным изменениям, а постепенному внедрению отдельных элементов технологий Веб 3.0. Благодаря этому уже сейчас можно опробовать такие технологии в реальной работе
Интерфейс страницы выдачи Swoogle по-спартански прост: лишь ссылки и минимум справочной информации. Swoogle способен выдавать результаты поиска в формате RDF, что позволяет обращаться к нему с помощью собственных приложений. Разработчики Swoogle, в частности, рекомендуют использовать для этого технологии проекта Apache Lucene