Любая автоматизированная информационно-поисковая система (ИПС) состоит из двух основных частей: формирователя собственной базы данных и генератора ответов на запросы пользователей. Главными показателями для первой являются ее объем и продуманность внутренней структуры, а для второй — скорость поиска информации и удобство пользования. На самом деле такое деление очень условно, потому что функциональная гибкость запросов изначально зависит от структуры базы данных: невозможно запросить что-то, что не было заложено в алгоритмы разработчиками.
Скажем, можно создать программу (Интернет-робота), которая будет скачивать все содержимое глобальной сети (если позволяют каналы связи) и сваливать эту информацию в одну кучу. Но, даже обладая всем этим богатством, невозможно потом будет хоть как-нибудь им воспользоваться. Конкретный поиск в неструктурированной базе данных заставит обработчик запросов полностью (!) просмотреть все содержимое кучи. Именно поэтому создатели поисковых систем и баз данных вводят индексацию внутренней структуры. То есть упрощенно под индексом можно понимать нечто, помогающее существенно ускорить поиск (алгоритмы, способы обращения к большим объемам информации, способы упорядочивания и хранения данных и т. д.).
С другой стороны, пусть существует хорошо проработанная база данных. По определенному запросу пользователя программа-обработчик поисковой системы выдаст множество документов, где встречается заданное словосочетание. Задачей номер один для создателей ИПС является такая сортировка результатов поиска, чтобы в самых первых позициях находились именно те документы, которые были затребованы. Этот параметр называется релевантностью ответа. Если задать в поиске только общие слова, например «корм для собак», тогда как вы ищете информацию про его ингредиенты, вряд ли в первой паре страниц отчета вам выдадут то, что вы искали. Поисковая система просто не в состоянии знать ваши мысли. Поэтому, задавая запрос, максимально конкретизируйте его для получения наиболее точного результата.
Давайте изучим внутреннюю структуру ИПС на примере Google (www.google.com).
Google появился сравнительно недавно, в 1998 г. Его создатели, сотрудники Стенфордского университета (США) Сергей Брин и Лоуренс Пейдж, постарались сделать его механизм более гибким и расширяемым, чем существовавшие на то время у грандов поиска — Аltavista и Inktomi. На данный момент Google и Fast (еще одна ИПС, www.alltheweb.com) имеют самый большой объем проиндексированных страниц — более двух миллиардов (данные на июль 2002 г.). Речь идет не только о собственно html- и xml-документах, но и pdf, doc и даже флэш-анимации. Причем только Google, в отличие от других иностранных ИПС (мы не рассматриваем «Яндекс», «Рамблер» и «Апорт»), хорошо индексирует русскоязычные Web-ресурсы в зоне.ru.
Почти в каждой поисковой системе есть своя внутренняя система оценки «качества» документов. В Google она называется PageRank (PR). Суть ее заключается в том, что при решении о порядке выдачи пользователю списка страниц, попадающих под его запрос, во внимание принимается некий коэффициент, зависящий от количества ссылок с других сайтов на эту страницу и от их популярности. На самом деле в этом есть рациональное зерно. Ведь если рассматриваемая страница действительно такая важная, что ее стоит прочитать, скорее всего, на нее уже ссылаются другие источники. Верно и обратное: если на документ никто не ссылается — кому он тогда нужен?! Причем PageRank — это не просто общая сумма ссылок, это нормализованное отношение количества ссылок, приводящих на данную страницу, к количеству исходящих c нее. Расчетная формула, опубликованная С. Брином и Л. Пейджем, выглядит следующим образом:
где d — эмпирически подобранный коэффициент (d=0.85); Т1...Tn — страницы, ссылающиеся на рассматриваемый документ; С(Tn)... С(Tn) — общее количество ссылок, ведущих вовне со страниц Т1...Tn.
Отсюда видно, что PageRank любого документа зависит от PageRank документов, с которых возможен переход на него. Таким образом, он всегда будет высоким для страниц, имеющих популярность в Интернете.
Важно также отметить, что PageRank имеет смысл вероятности, с которой среднестатистический Интернет-путешественник попадет на определенную страницу, хаотически блуждая по ссылкам. Сумма PageRank всех страниц равна единице
(![]()
где N — количество проиндексированных страниц).
Вышеприведенная формула достаточно проста, и если задаться целью построить некоторое количество взаимосвязанных страниц, то, по-видимому, PageRank каждой может быть искусственно завышен. Например, можно попытаться сократить число ведущих вне ссылок и создать большое кольцо, в котором документ ссылается только на «друзей». Тогда каждый из них вследствие итеративности алгоритмов расчета PageRank будет иметь достаточно высокий коэффициент «важности». Несмотря на это в модели Google, вероятно, предусмотрены какие-то механизмы, позволяющие не начислять слишком высокий PageRank «подозрительным» и «нежелательным» сайтам. И естественно, эти механизмы являются ноу-хау и не подлежат разглашению.
Еще одна важная черта ИПС Google заключается в том, что в ней хранятся описания ссылок на проиндексированные страницы. Эта особенность позволяет более адекватно проводить поиск в накопленной базе данных. Скажем, автор странички забыл указать ее название между тегами
. Любая ИПС при выдаче результатов поиска ставит высокий приоритет словам, указанным именно в названии. В этом случае Google будет ориентироваться по текстам ссылок на эту страничку, справедливо основываясь на предположении, что если кто-то ставит ссылку на что-то, то уж, по крайней мере, он эту страничку изучил и постарался наиболее емко отобразить ее содержание в тексте ссылки. Именно поэтому во всех наставлениях по правильному оформлению содержимого документов имеется следующий совет.Никогда не ставьте ссылку под словами «здесь», «тут», «сюда» (например: полную версию постановления смотри здесь). Попробуйте написать так: «на сайте есть также и полная версия постановления». Кстати, сказанное верно еще и потому, что почти во всех браузерах текст внутри тега подсвечивается тем или иным образом (выделяется подчеркиванием, цветом). Глаз при беглом просмотре странички более вероятно зацепится за выделенные информативные слова, чем за неконкретное краткое наставление «вам сюда». Как говорится, покупатель и продавец, будьте взаимно вежливы!
Кроме расчетов PageRank и запоминания текста ссылок, Google хранит шрифтовой размер и смещение каждого слова относительно начала документа. (Примечание: некоторые ИПС ориентируются также и на цветовое выделение слов относительно текста.) В спецификации HTML 3.2 было определено семь уровней заголовков по размеру шрифта (от 1> — самого крупного, до 7> — самого мелкого). Поэтому поисковик всегда выдаст по запросу документ, в котором данное слово выделено более крупным шрифтом или находится ближе к его началу. Благодаря тому что система знает конкретное место каждого слова в документе, становится возможен так называемый Proximity search — поиск по наиболее близкому расположению слов друг относительно друга. Например, по запросу «слово1 слово2» ИПС найдет много документов у себя в базе данных, но в отчет в первых строках пойдут только те, в которых «слово1» находится максимально близко слева от «слова2».
Теперь более подробно рассмотрим схему функционирования информационно-поисковой системы Google. Всю основную работу по просеиванию сквозь себя содержимого Сети выполняют Интернет-роботы (боты, crawlers). Каждый из них берет один адрес (URL, uniform resource locator; каждый URL соответствует определенному идентификатору документа) из базы данных URL-сервера, скачивает и передает содержимое странички на сервер хранения документов (рис. 1). Необходимо отметить, что все содержимое сервера хранится в заархивированном виде для увеличения его вместимости.

|
| Рис. 1. Структура информационно-поисковой системы Google |
Другая программа — индексатор — занимается тем, что разлагает текст документа на составляющие его слова (хит в терминологии Google), запоминая при этом местонахождение, шрифтовой вес, а также написано ли слово заглавными или строчными буквами и принадлежит ли оно к категории «особенных» (названия документов, метатеги, URL?ы и тексты ссылок). Вся эта информация складывается в набор контейнеров, именуемых на рисунке прямым индексом. Структура хранимых в нем данных выглядит следующим образом (рис. 2).

|
| Рис. 2. Структура прямого индекса (doc_id — идентификатор документа; word_id — идентификатор слова; null_word — символ окончания документа; n_hits — частота, с которой слово встречается в документе) |
Идентификаторы слов берутся из словаря, который постоянно пополняется. Одновременно с этим индексатор просматривает содержимое тегов и проверяет корректность всех ссылок в службе разрешения имен DNS (domain name service). Если ему встретился URL, которого нет в базе данных по doc_id, он пополняет не только ее, но и коллекцию ссылок. В дальнейшем этот Интернет-адрес попадает в URL-сервер и круг замыкается. Система поиска новых документов, при условии, что на них хоть кто-нибудь ссылается, становится самодостаточной — она сама себя подпитывает.
Но каким образом ИПС узнает о новых Web-ресурсах, которых еще никто не успел посетить? Для разрешения этой проблемы разработчики предусмотрели ручную форму регистрации ресурсов в поисковой системе. Введенные в нее адреса после проверки на корректность также попадают в URL-сервер.
Заметим, что каждая из программ, обозначенных на рис. 1 эллипсом, работает независимо от других, причем аппаратные конфигурации серверов и рабочих станций, на которых функционирует «движок» Google, выбираются так, чтоб не создавать «пробок» при обработке информации, собранной Интернет-роботами.
Описанная выше структура прямого индекса не очень удобна при поиске документов на основании встречающихся в них слов (пользователь задает слово или словосочетание, а система должна найти подходящий документ). Чтобы решить эту проблему, был введен так называемый инверсный, или обратный, индекс (рис. 3). В нем любому слову из словаря соответствует набор doc_id-документов, в которых это слово встречается. Работой по постоянному формированию инверсного индекса занимаются сортировщики. Так как, во-первых, всегда появляются новые документы и, во-вторых, обновляются старые, индекс приходится постоянно перестраивать.

|
| Рис. 3. Структура инверсного индекса (word_id — идентификатор слова; ndocs — количество документов с этим словом; doc_id — идентификатор документа; n_hits — частота, с которой слово встречается в документе) |
Пусть от пользователя поступил запрос найти документы со словом «мухобойка». Программа, формирующая ответы, посмотрит в словарь, найдет там word_id для «мухобойки», сформирует запрос в базу данных с использованием инверсного индекса и получит набор документов, в которых это слово встречается. Далее на основании PageRank, количества хитов, их качества и, может быть, других ограничений и приоритетов разработчиков будут распределены порядковые номера страниц в выходном списке. В итоге Интернет-пользователь получит самую оптимальную, по мнению ИПС, информацию о том, где и что писали о правилах и способах мухоубийства.
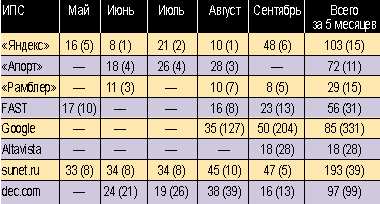
Качество поисковой системы, как уже было отмечено, зависит не только от количества проиндексированных документов, правил их отбора в итоговый список, но и от того, как часто Интернет-роботы заново проверяют содержимое ранее обработанных сайтов. В таблице на примере thermo.karelia.ru приведены данные об общем объеме запрошенных роботами документов и количестве заходов на сайт (по данным Webalizer — анализатора журналов Web-сервера).
Из таблицы видно, что роботы «Яндекса» и Google ведут себя по-разному. «Яндекс» останавливается на корневом документе Web-сервера (например, index.html) и скачивает содержимое сайта последовательно, документ за документом, в один поток. Google распараллеливает работу между несколькими роботами, причем каждый из них при скачивании может «отвлекаться» на другие дела. То есть эти две поисковые системы характеризуются совершенно различными структурами URL-серверов и способами пополнения информации из Интернета.
Второй важный вывод, который напрашивается по результатам изучения приведенной таблицы, заключается в том, что русскоязычные поисковики «лучше» иностранных, они более часто посещают ресурсы постсоветского пространства. Даже «Апорт», уступивший на данный момент третье место Google по общему количеству обрабатываемых запросов (данные с www.spylog.ru), как минимум раз в месяц просматривает содержимое каждого сайта.
Последние две строчки в таблице требуют некоторых пояснений. За надписью Sunet.ru скрывается один из московских провайдеров Интернет-услуг (e-Style). Причем поражает завидное постоянство, с которым действует их робот. Какой из поисковых систем они предоставляют информацию и предоставляют ли ее вообще — автору неизвестно.
Dec.com — робот некогда существовавшего гиганта Digital Equipment Corporation (впоследствии он был перекуплен компанией Compaq). Dec поддерживал Altavista, поэтому можно предположить, что получаемая информация идет в закрома самой известной ИПС.
В заключение хотелось бы заметить, что каждый сайт строится уникальным образом, имея линейную, древовидную или смешанную структуру. Одни построены на документах с динамическим контентом, другие вообще статичны и не изменяются. По-видимому, будет существовать разница даже в процессе индексации постоянно изменяющихся сайтов, имеющих динамическое содержимое. Не секрет, что целая категория Web-ресурсов, отнесенных к разделу новостных, просматривается чуть ли не ежеминутно.
На основании изложенных соображений можно выделить ряд рекомендаций создателям Web-ресурсов для улучшения позиций их проектов в рейтингах информационно-поисковых систем (впрочем, не только для этого):
- четко продумывать структуру каждого сайта;
- называть каждую страницу уникальным именем, максимально отражающим ее содержимое;
- избегать использования одного и того же имени файла для группы документов с передачей после него различных параметров (например, index.php? razdel=1&document=2) (программисты иногда забывают менять значение переменной, содержащей название документа);
- избегать навигации "плохо индексируемыми" способами (формы, флэш-анимация).
Об авторе
Алексей Петрович Мощевикин — к.ф.-м.н., Петрозаводский государственный университет, alexmou@dfe3300.karelia.ru
Объем документов, загруженных роботами поисковых систем с thermo.karelia.ru, Мбайт
Примечание. в скобках указано количество заходов роботом на сайт за месяц