Вследствие постоянного роста количества полнотекстовых документов, представляемых в электронном виде, появляется все больше новых методов навигации в информационных массивах. Сейчас текстовую информацию обычно представляют в форме гипертекста, отличающегося возможностью интерактивной работы с материалом и многомерностью его представления. При этом конкретные реализации гипертекста различаются как способом установления связей, так и формой визуального отображения, начиная с простейших видов систем вроде Web-страниц, справочных или программируемых, в которых используется переход по тексту посредством жестко задаваемых разработчиками приемов, и заканчивая «интеллектуальными» электронными книгами, где каждое слово сопровождается веером раскрывающихся гиперссылок, представляемых понятиями, связанными по смыслу.
Создание поисковых машин в Internet и увеличение объемов публикуемой информации стимулировали развитие гипертекстовых средств нового поколения, иначе называемых тематическими навигаторами. Системы с подобными средствами позволяют передвигаться по связанным тематическим категориям (рубрикам), а к каждой из них может быть отнесено множество текстов, близких по содержанию. С помощью лучших из таких навигаторов можно определить темы, объединяющие нужные тексты (например, содержащие определенные слова), а затем передвигаться по этим темам.
Сведения о наиболее интересных из подобных систем приведены на сайтах http://www.links2go.com, http://www.semio.com, http://www.inxight.com.
Все известные тематические навигаторы подразделяются на две категории. Относящиеся к первой имеют жестко заданную структуру с априори установленными темами и связями между ними. В таких навигаторах используется заранее определенный рубрикатор с иерархической структурой категорий, отражающий общепринятый набор областей знаний. Нижние ветви рубрикатора обычно включают в себя классы слов языка, относящиеся к определенным темам. Подобные навигаторы могут автоматически распределять все входящие тексты по соответствующим тематическим рубрикам и подсчитывать, на какие из ветвей приходится больше слов из текста. Однако рубрикатор стандартной структуры отражает лишь наиболее очевидные связи между темами, а они малоинтересны, поскольку не открывают новой информации.
Для создания навигаторов второй категории требуется участие экспертов для формирования структуры тем на основе анализа содержания собрания текстов. Здесь гипертекстовая структура обычно представляет собой семантическую сеть, связи которой показывают актуальное строение текстов с семантической точки зрения. Такие навигаторы из-за высоких затрат на разработку, требующую привлечения «ручного» труда, обычно предназначаются для небольших собраний текстов в узкой предметной области.
Ниже будет рассказано о некоторых технологиях, позволяющих автоматизировать процесс построения навигатора, выявляющего реальные смысловые связи в тексте. Так, российская компания «Гарант-Парк-Интернет» (http://www.metric.ru) использует технологии подобного типа, основанные на оригинальных алгоритмах, реализующихся с помощью нейросетевых моделей деятельности мозга.
Тематический анализ текста
Многие годы исследователи в области искусственного интеллекта пытались научить компьютер логическому мышлению, основанному на работе с формализованными знаниями. Подобный тип мышления характерен для человеческого мозга, когда он перерабатывает информацию в левом полушарии.
Иерархические рубрикаторы, используемые в информационно-поисковых системах для классификации информации, как раз и представляют пример левополушарной модели знаний. Однако из-за неспособности ЭВМ к языковому мышлению их возможности ограничены рамками изначально заложенной системы знаний. И здесь проблема заключается в том, что невозможно самообучение рубрикатора без участия человека.
В то же время в мозге скрыты и иные механизмы, позволяющие справляться с массой повседневных дел не задумываясь. Они заключены в правом полушарии и производят ассоциативную статистическую обработку. Живые существа «обучались» всему именно так - устанавливалась и развивалась ассоциативная связь между событиями, которая затем закреплялась путем повторений и приводила к возникновению рефлексов.
Чтобы понятнее объяснить, как работают эти механизмы, проведем аналогию с поведением студента, которому нужно срочно подготовиться к экзамену по новому предмету. При этом он может пойти двумя путями.
При первом, дедуктивном, нужно скрупулезно штудировать учебники, погружаясь в определения, изучая основные соотношения и т. п. В этом случае задействуются все ресурсы левого полушария мозга. Так поставлено школьное образование, где, к примеру, обучать иностранному языку обычно начинают с грамматики. Но есть и другой путь, и иногда он бывает более эффективным. Он лежит в основе так называемого «обучения с погружением». Если студент выберет его, то ему придется взять книгу и погрузиться в мир новой информации, читая все страницы подряд. Сначала он ничего не понимает, однако спустя некоторое время он вдруг начинает узнавать слова, пока еще неосознанные. Они-то и станут ключевыми понятиями, на базе которых затем выстроится вся система знаний по изучаемому предмету. При этом правое полушарие проводит статистический анализ, выделяя повторяющиеся фрагменты информации, образующие фундамент будущих знаний.
Затем студент читает по второму разу... Теперь понятия начинают приобретать для него некий смысл — при встрече со знакомыми словами возникают ассоциации. Так формируется и включается в работу ассоциативная семантическая сеть — комплекс связей между понятиями, увязывающий их в модель нового мира, где каждый элемент, в свою очередь, обретает собственный смысл, связываясь с другими. Появление связей — опять же статистика, бессознательный частотный анализ правого полушария мозга, который тщательно запоминает и постоянно оценивает, в каких комбинациях друг с другом различные понятия встречались в тексте.
А пока студент спит, бессознательная часть мозга продолжает трудиться, анализируя накопленную информацию. Сложившаяся в голове модель предмета перестраивается и совершенствуется. Одни локальные фрагменты ассоциативной сети, слабо связанные с остальными, забываются и отбрасываются как случайные, а между другими устанавливается еще более тесная связь, выявляются новые зависимости, определяются главное и второстепенное. А к утру модель предмета бывает вчерне сформирована, и можно с новыми силами продолжить изучение предмета. Ассоциативная система включилась в работу, и теперь содержание становится более-менее ясным. По мере чтения весь материал как бы нанизывается на знакомые понятия и классифицируется. В результате получено знание по темам, выраженное конкретными строчками! А если студент пролистает уже знакомый учебник перед экзаменом, то в его памяти останутся главные тезисы, касающиеся основ, - в общем, получится что-то вроде небольшого реферата.
Проведенное выше сравнение в более полном объеме можно найти на сайте http://www.analyst.ru. Там же представлены первая реализация ассоциативной технологии и принципы, заложенные в основу подхода к анализу содержания текста.
Основные возможности такой технологии и особенности ее использования были описаны ранее (см. «Мир ПК», № 5/01, с. 64), поэтому здесь лишь кратко остановимся на некоторых ключевых моментах.
Технология тематического анализа позволяет автоматически выявлять ключевые темы текста. Они выражаются словами, входящими в него и определяемыми словосочетаниями, которые отражают основное содержание. По каждой из этих тем формируется резюме, составленное из наиболее представительных фрагментов текста, а также общее резюме — реферат. В ходе тематического анализа устанавливаются ассоциативные связи между темами с использованием критерия совместного появления слов в предложениях.
Совокупность тем со связями образует ассоциативную семантическую сеть, работающую аналогично правополушарной модели предметной области обработанных текстов.
TopNet: тематическая навигация на основе семантических сетей
Семантическая сеть главных тем текстов дает основу для навигации по ассоциативным связям между темами (рис.1). Одна из ее особенностей состоит в дифференциации связей по весам — численным характеристикам, отражающим относительную степень связности тем. При этом большее значение веса связи одной темы по отношению к другой указывает на то, что первая тема в тексте почти всегда излагалась в контексте второй. Меньшее значение веса связи отражает тот факт, что относительно небольшая часть информации, касающаяся первой темы, касается в то же время и второй. Связь между парой тем в сети всегда двусторонняя, однако ее веса в разные стороны могут отличаться, ведь известно, что «каждая селедка — рыба, но не каждая рыба - селедка».

|
| Рис. 1. Два фрагмента семантической сети, построенной методом TopNet |
Подобное упорядочение позволяет визуализировать информацию в сети «по слоям связности», отображая более или менее сильные связи. При этом обрыв слабых связей разбивает сеть на ряд подсетей, представляющих отдельные тематические кластеры.
Различие в весах прямой и обратной связей позволяет определить степень общности и частности тем, а также представить сеть в форме леса деревьев, разложив по уровням иерархии «рыб» и «селедок».
Вследствие описанных выше особенностей визуальные формы представления сети могут быть самыми разными, и большинство из них еще ждут своего исследования.
Проиллюстрируем все сказанное конкретными примерами.
На рис. 1 приведена одна из форм отображения фрагмента сети. В виде дерева представлено несколько тем, связанных с темой репрессировать. Дерево сверху содержит темы, общие по отношению к репрессировать, а дерево снизу — более частные (подтемы). Также представлен фрагмент связей одной из подтем темы репрессировать.
При работе навигатором на подобной сети пользователь имеет возможность перемещаться от темы к теме и получать тексты по отдельным из них и по выбранным связям. Например, можно извлечь документы, в которых тема военная прокуратура связана с темой репрессировать.
На рис. 2 дан фрагмент сети, относящийся к запросу азербайджанская нефть.
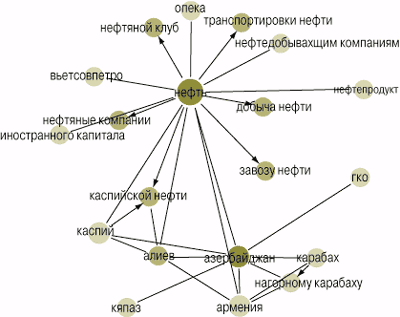
|
| Рис. 2. Фрагмент семантической сети, построенной методом TopNet |
Представленная сеть была построена автоматически по небольшому собранию материалов периодической печати, а описанная технология получила название TopNet — тематическая сеть.
TopSOM: навигация на основе самоорганизующихся тематических карт
Теперь о еще одном методе визуализации под названием WebSOM (Web Self-Organaizing Maps), предназначенном для представления массивов текстов в виде двумерной карты. Он основан на отображении многомерного пространства гипертекста на плоскость. Конкретные тексты при этом связываются со своими областями карты, причем к каждой из них может относиться множество близких по содержанию текстов — тематический класс. Близким областям карты, в свою очередь, обычно соответствуют и близкие классы текстов, и в этом ее основная особенность. Эти области карты именуются в зависимости от содержания относящихся к ним текстов. Пользователь выбирает на карте интересующую его область и получает класс соответствующих ей текстов близкого содержания. Если же ищутся тексты, включающие определенные слова, то результаты поиска также отражаются на карте путем выделения тех областей, к которым принадлежат найденные тексты. Так что в итоге можно оценить тематическое распределение искомой информации.
Карта строится стандартным методом, базирующимся на нейронной сети Кохонена. На сайте http://websom.hut.fi можно найти описание метода WebSOM, а также пример нескольких англоязычных карт; на http://www.neurok.ru показано, как его применять к текстам на русском языке.
К сожалению, информация с упомянутых выше сайтов свидетельствует о том, что использование WebSOM пока не дает качественного представления предмета и не может заинтересовать реального потребителя информационных систем. Технология остается в рамках лабораторных исследований, поскольку в ней ключевым моментом является выбор подобного описания содержания текста для построения карты, а ведь именно знание ключевых тем позволяет решить основную проблему и выбрать адекватные признаки, используемые для классификации текстов, что определяет эффективность карты. Кроме этого, можно автоматически маркировать области карты названиями тем.
Это-то и привело к возникновению модификации WebSOM, базирующейся на технологии тематического анализа, получившей название TopSOM — метод тематической самоорганизующейся карты.
Фрагмент карты, построенной с помощью этого метода, приведен на рис. 3.
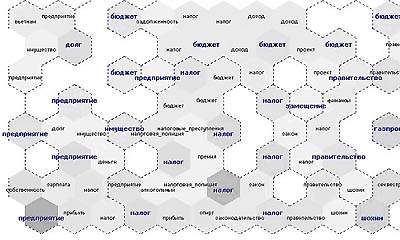
|
| Рис. 3. Фрагмент тематической карты, построенной методом TopSOM |
Тематические классы близких текстов здесь представлены шестиугольными областями. К каждой из них, вообще говоря, относятся несколько тем, выделенных в соответствующих ей текстах и упорядоченных по значимости. В силу свойств карты большинство соседних областей образуют группы с общей главной темой, которые обведены пунктиром, а название такой темы написано в определенных местах и выделено шрифтом. Можно отметить основные группы: долг, бюджет, правительство, налог, предприятие. Более мелким шрифтом даны названия тех тем, которые следуют по значимости за главной. Выбранный способ отображения позволяет детализировать информацию. Так, тексты тематической группы предприятие в левом нижнем углу делятся на ряд классов, где преобладают следующие темы: собственность, зарплата, прибыль, налог, деньги, имущество и долг.
Поскольку подавляющее большинство текстов — политематические, на карте реальные границы между темами оказываются континуальными. Так, в правом нижнем углу находятся три близких по содержанию класса текстов, объединенных темой Шохин, причем в одном из них тексты относятся в основном к тематической группе налог, а в другом — правительство.
Яркость фона зависит от числа текстов, имеющих отношение к области.
На рис. 4 представлена вся карта, где красным цветом подсвечены те области, к которым принадлежат тексты, найденные по запросу наркотики.

|
| Рис. 4. Тематическая карта TopSOM с подсветкой результатов поиска по запросу наркотик |
Основные их скопления, содержащие слово наркотики, соответствуют тем областям, где преобладает тема преступление. Еще одна часть текстов относится к темам, связанным с таможней и инфекцией, иные рассеяны по прочим областям.
Если выбрать какую-либо из них, например в окрестности темы таможня, можно более детально рассмотреть фрагмент карты, увеличить масштаб, а затем выбрать документы, связанные, в частности, с наркокурьерами.
По адресу http://research.metric.ru можно познакомиться с технологиями, представленными компанией «Гарант-Парк-Интернет» на русском и английском языках.