

Хотя сегодня очень редко из-за ошибки либо иной проблемы сеть оказывается полностью парализованной, часто администраторам все же приходится слышать: «Приложение xyz работает некорректно». В чем все-таки дело? Причина ли в плохом контакте, перегрузке какого-либо компонента сети либо что-то не так с сервером или сервисом? Тут-то и начинается поиск иголки в стогу сена.

Выявление ошибок за последние годы стало частью управления производительностью, одной из самых требовательных задач в сетевой области. К тому же во многих случаях еще до начала поиска/устранения ошибки должна быть обеспечена рабочая среда для поддержания бизнес-процессов. Напоследок — или, может быть, это следовало упомянуть до анализа производительности? — сетевой администратор должен позаботиться о том, чтобы влияющие на эффективность работы проблемы или ситуации по возможности не возникали вовсе. Этого можно достичь, например, посредством превентивного управления производительностью.
Измерительный прибор, способный в полной мере справляться с такими задачами, до сих пор не создан. Спектр необходимых инструментов довольно широк — от тестера кабеля, анализаторов протоколов в различных исполнениях до систем на базе RMON и платформ управления сетями. Вид требуемого оборудования определяется в зависимости от стоящих перед специалистами задач, приоритет и формулировка которых меняется от компании к компании. Благодаря усовершенствованным методам ряд классических измерительных приборов за последние два года дополнился важными функциями: длительным мониторингом для поиска ошибок и имитацией приложений и сервисов для предупредительного анализа.
БЫСТРЫЕ КОММУТИРУЕМЫЕ СЕТИ
Большинство компаний использует коммутаторы. Ethernet на рабочих местах и Gigabit Ethernet на магистрали встречаются сплошь и рядом. Более подробное исследование объекта с помощью зеркального порта посредством обычного анализатора протокола удобно в том случае, когда администратор уже определил проблемные станции, т. е. ограничил круг «подозреваемых».
Многие администраторы делают ставку на статистику, каковую добывают, например, системы на базе RMON. Статистическая информация вполне подходит и для общего обзора. К такой информации относятся ответы на следующие вопросы. Какова величина нагрузки? Кто главный источник сообщений/главный пользователь? Какие протоколы преобладают?
Правда, заблуждается тот, кто полагает, что источники ошибок можно установить посредством статистики и за счет дополнительных фильтров данных. Эта работа крайне утомительна и занимает много времени. Чем больше данных нужно исследовать, тем меньше вероятность успешного разрешения проблемы.
Итак, многие сетевые администраторы пытаются напасть на след ошибки при помощи анализатора протоколов и путем измерений на магистрали. Однако классические анализаторы протоколов разработаны таким образом, чтобы при возникновении чрезвычайных ситуаций они позволяли выявлять причину, поэтому емкость их памяти ограничена. В случае Gigabit Ethernet 128 или 256 Мбайт накопительного буфера заполняются за доли секунды. Желающие получать приблизительные исходные данные о неисправностях на магистрали должны с самого начала установить фильтр возможных причин ошибок, что предполагает высокий уровень знаний и опыта.
В какой-то степени здесь могут помочь экспертные системы, однако к их показаниям при больших скоростях нужно относиться с определенным скепсисом. По соединению Gigabit Ethernet иногда за секунду проходят 3 млн пакетов данных, что требует от классического аппаратного анализатора высочайшей производительности, так как он должен записать всю информацию и одновременно проанализировать ее. А потеря хотя бы нескольких пакетов отрицательно влияет на способность экспертной системы выносить заключение.
Что же делать, когда пользователь заявляет: «Приложение xyz работает некорректно?» Вдобавок жалобы поступают не в тот момент, когда событие случается, а когда уже и симптом ошибки исчез, и вся ситуация в сети давно изменилась. Даже после тщательного изучения всех деталей почти никогда нельзя в точности определить, какие именно обстоятельства послужили причиной возникновения проблемы.
КАК ВИДЕОЗАПИСЬ
Выход — и это новый подход к измерениям — предлагают измерительные устройства, которые в течение длительного времени способны регистрировать, сохранять и быстро анализировать данные на высокоскоростных линиях. Такие сверхпроизводительные анализаторы сети имеют внутреннюю емкость хранения до 1,4 Тбайт, а внешнюю — до 50 Тбайт. С их помощью администратор, в зависимости от нагрузки, может круглосуточно записывать весь трафик по соединению Gigabit Ethernet вплоть до уровня пакетов.
Современные измерительные системы анализируют сохраненные данные параллельно с процессом записи и заносят результаты в собственную базу данных. Первичная обработка осуществляется за несколько секунд и посредством логической операции И/ИЛИ позволяет выделять периоды времени, пики нагрузки, отдельные компьютеры, протоколы и другие параметры. У администратора есть возможность анализировать выявленные события вплоть до уровня пакетов. При таком подходе облегчается выявление причины неполадок, не нужно больше сомневаться в адекватности выбранного фильтра, ведь весь трафик записан и имеется в наличии.
Чтобы правильно интерпретировать выявленные события, многие анализаторы сети предлагают экспертные системы. Считается, что чем полнее анализируемые данные о трафике, тем точнее оценка экспертной системы. Следующим критерием является размер и практическая пригодность базы данных с возможными интерпретациями событий в сети. Кроме того, она должна быть, по возможности, подробной и обновляемой.
|
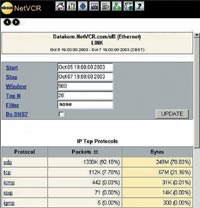
| Рисунок 1. При помощи анализатора для длительного мониторинга NetVCR компании Niksun администратор может прокручивать записанные данные за последние два дня и анализировать их по мере надобности. |
Измерительные устройства для длительного мониторинга должны обладать всеми свойствами, к которым привыкли операторы обычных анализаторов протоколов: например, предоставлять статистические данные или предлагать автоматическое составление отчетов. Решающим же является то, что администратор должен быть уверен, что система действительно записала весь трафик. Только так у него есть возможность разобраться с поступившими через несколько дней жалобами. При наличии современного анализатора для длительного мониторинга он просто «перематывает» событие, как на видеомагнитофоне, до соответствующего момента времени (cм. Рисунки 1 и 2). Такой мониторинг пригоден для выявления неисправностей, а также для анализа производительности.
|
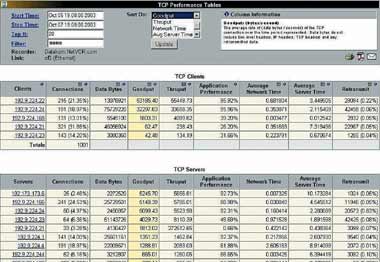
| Рисунок 2. Измерение производительности протокола TCP за два дня посредством NetVCR компании Niksun. |
ПРЕДОТВРАЩЕНИЕ ОШИБОК
Посредством длительного мониторинга администратор может быстро обнаружить ошибку и причину проблемы, но намного важнее предотвратить ее. По этой причине в сетевой технике все больший вес приобретает превентивное управление производительностью.
Большинство помех в сети возникает, когда в нее попадает что-то новое: пользователи, узел пути, сервис, приложение, компонент или всего лишь обновление программного обеспечения. Как ведет себя в этом случае сеть? Теряется ли качество и класс предоставляемых услуг передачи данных (Quality of Service, QoS) для имеющихся приложений из-за того, что введена передача голоса по протоколу IP (Voice over IP, VoIP)? И какие QoS возможны в настоящее время для VoIP?

|
| Рисунок 3. Модульная платформа Ixia-250 имитирует тысячу пользователей, сеть или приложения. |
На эти вопросы можно ответить, комбинируя моделирование и анализ сети. Такие измерительные системы в состоянии определять наряду с производительностью сети вплоть до третьего уровня также QoS для приложений (уровни с четвертого по седьмой). Они эмулируют реальные приложения, измеряют время отклика, анализируют транзакции и осуществляют специфические для приложений измерения (см. Рисунок 3). Администратор может использовать их для функционального, а также нагрузочного теста. Они имитируют, например, дальнейшее поведение сети до ее ввода в эксплуатацию или внедрения новых приложений. Результаты документируются и, таким образом, являются проверяемыми. Предварительные тесты будут необходимы, когда дело коснется соблюдения соглашений об уровне сервиса (Service Level Agreement, SLA), так как при развертывании нового приложения всегда есть риск, что оно ухудшит QoS имеющегося приложения. Превентивные тесты соответствуют сертификации на уровнях со второго по седьмой.
Кроме того, эти тесты предназначены для базового анализа всего сетевого трафика или трафика конкретного приложения в целях определения статус-кво. Результаты служат основой для заключения реалистичных соглашений об уровне сервиса и в любой момент могут быть проверены и скорректированы посредством измерительной техники. Проведенные мероприятия по усовершенствованию проверяются при помощи превентивных систем без привлечения пользователей.
ВЫВОД
Чем больше сеть, тем сложнее источники ошибок. Часто наложение нескольких событий приводит к сбоям или потере производительности. Давление на администраторов очень велико, поскольку почти все современные приложения работают по сети. Потеря производительности или даже сбой сети коснутся многих пользователей и, вероятно, важных для компании приложений. Выявление неисправностей и анализ производительности — не те задачи, которые можно решить мимоходом. Они требуют от ответственных лиц знаний и опыта, умения выбрать именно тот измерительный прибор, который нужен для решения соответствующей задачи. Тот, кто задумает на этом сэкономить, должен осознавать всю меру ответственности.
Лидия Кровка — коммерческий директор компании Datakom. С ней можно связаться по адресу: http://www.datakom.de.
? AWi Verlag