
KnowledgePump как пример «модельного» подхода к обработке потока информации
Сейчас, похоже, возникла противоположная проблема — как вовремя обработать поступающую информацию и адекватно отреагировать на нее. Этого можно добиться только в том случае, когда в компании используются единая модель и концепция обработки информации. К сожалению, сейчас поступающая информация обрабатывается индивидуально, и данные, интересные для одного сотрудника, могут быть отправлены в мусорную корзину другим. В качестве примера «модельного» подхода к обработке потока информации может служить продукт компании «Интертраст», который называется KnowledgePump.
Но сначала полезно несколько слов сказать об эффективности систем обработки информации. Эта операция ресурсоемкая, поэтому для нее следует выбирать данные, которые в дальнейшем будут неоднократно использоваться. Тогда вложения в обработку данных, сделанные на первоначальном этапе, окупятся при их последующем использовании. Естественно, что сумма затрат зависит как от самой информации, так и от срока ее повторного использования. Причем формального правила, ограничивающего глубину начальной обработки, нет. Каждая организация по-своему оценивает объем затрат на первоначальную обработку, поскольку в результате рассчитывает получить свои информационные преимущества.
Смысловая карта документа
Основу KnowledgePump составляет модель документа, которая называется смысловой картой документа (СКД). Она представляет собой набор триад, каждая из которых связывает субъект действия с объектом и самим действием. Модель «субъект — действие — объект», как правило, хорошо описывает событийную информацию, новости. От использования ключевых слов при описании документа смысловая карта отличается существенно, поскольку для ее составления используется модель предметной области. На основе СКД можно делать определенные выводы.
Все элементы триады должны быть описаны в модели предметной области, которая составляется специалистом. Модель предметной области представляет собой рубрикатор, в котором перечислены субъекты предметной области, те действия, которые они могут осуществлять, и те объекты, на которые могут быть направлены действия. Модель предметной области должен составлять аналитик, и она не может быть изменена оператором, генерирующим триады. Любой текст, подходящий к данной предметной области, можно разложить на некоторый набор таких триад, который и образует смысловую карту документа.
Рассмотрим модель автомобильного рынка. Его субъектами являются компании, покупатели, регулирующие органы, СМИ, частные лица. Действия могут быть следующие: приобретения, слияния, выпуск новых моделей автомобилей, публикация статей, покупка товаров и многое другое. Для каждого действия всегда ясно, кто является объектом. Причем при использовании другой модели предметной области для одинаковых текстов набор триад — СКД — может измениться.
СКД позволяет легко моделировать тексты, ориентированные на действия, где событийный характер преобладает над смысловыми оттенками. Естественно, при преобразовании документа в его смысловую карту что-то теряется, но основная идея системы KnowledgePump в том, чтобы сохранить именно те смысловые оттенки, которые существенны для анализа. Впрочем, сам документ также сохраняется в системе, и именно его видит пользователь. СКД же, как правило, скрыта от него и нужна лишь для автоматической обработки документов.
В виде триад можно описать любую информацию, а не только текстовой документ. Именно поэтому в «Интертраст» не предполагают делать системы автоматического создания СКД для текстов, хотя именно в таком виде чаще всего информация и попадает в компанию. СКД всегда должны формировать люди. Во-первых, речь может идти о важных документах, обработку которых рискованно доверять программе. Во-вторых, у каждой программы есть определенная точность работы и стоимость владения. По мнению Вадима Федорова, разработчика KnowledgePump, на данном уровне технологии существенно повысить точность разбора текстов практически невозможно.
Следует отметить, что для представления документа в виде СКД необходимо решить две проблемы: создать модель предметной области и наладить работу оператора, который создает СКД. В KnowledgePump предусмотрен механизм определения качества обоих этих элементов системы. Этот механизм построен на теории планирования экспериментов, которая была разработана для физических исследований. Для использования этого механизма составление СКД поручается разным операторам. В результате можно повысить точность СКД, а также выяснить и качество работы операторов, и точность составления рубрикатора.
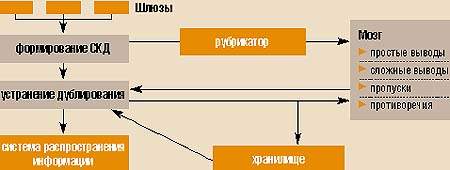
При генерировании СКД следует соблюдать баланс между оправданными затратами ресурсов и невосполнимыми потерями текста. СКД всегда делают люди. Причем не важно, в каком виде поступила информация о событии — в текстовом, в виде телепередачи или любом другом. Важно, чтобы человек понял, о чем идет речь в сообщении, и снабдил его метаданными — триадами. Момент создания СКД в KnowledgePump разделяет этапы инвестиций и их возврата. Все затраты сводятся к тому, чтобы для документа была сформирована смысловая карта. В дальнейшем СКД можно использовать для следующих целей: интеллектуальной рассылки документов, проверки дублирования, простых и сложных выводов, выявления противоречий и пропусков в потоке информации, сохранения документов для накопления знаний.
Использование СКД
Для решения проблемы целевой доставки информации достаточно правильно настроить персональные фильтры служащих, для чего необходимо составить шаблоны триад, которые нужны данному служащему. Для рассылки информации используются специальные фильтры или должностные каналы, в которые посылаются документы, соответствующие определенному шаблону на триаду. Как только в каком-то документе появляется триада, соответствующая этому шаблону, документ автоматически направляется в должностной канал. Причем было бы лучше, если бы должностные каналы настраивали аналитики, которые знают, что нужно конкретным служащим, а не сами служащие. Таким образом, с помощью СКД можно повысить и эффективность, и точность доставки информации.
Проверка дублирования документов также решается просто. Даже если два текста существенно отличаются друг от друга, но описывают одно событие, они выражаются в одинаковых наборах триад. Поэтому, сопоставляя триады, связанные с разными документами, можно определить, насколько документы похожи, и даже выделить из каждого документа эксклюзивную информацию.
Наиболее важное применение триад — это возможность делать определенные выводы. Рубрикатор можно расширить системой причинно-следственных связей типа «если — то». Например, в нем можно задать такую связку: «Если компания X вышла на новый рынок с новым продуктом, то она становится конкурентом всех игроков этого рынка». Если появляется сообщение о том, что какая-либо компания выпустила продукт, предназначенный для нового рынка, то система автоматически сгенерирует соответствующие триады типа «Компания X является конкурентом компании Y» (для всех Y, перечисленных как игроки этого рынка). Причем для выводов можно использовать триады из разных предметных областей. В результате, просто контролируя появление новых триад и имея заранее определенные причинно-следственные связи между событиями, система может самостоятельно порождать новые триады, то есть делать выводы. Таким образом, наиболее простые и подразумеваемые выводы делаются автоматически; фактически наличие такого механизма выводов превращает систему в экспертную. Процесс порождения новых триад может быть рекурсивным, поскольку новая триада опять посылается в систему и на ее основе могут быть сделаны новые выводы.
С помощью триад можно также выявлять и противоречия в данных. С точки зрения системы для выявления противоречия достаточно определить шаблоны триад, которые противоречат друг другу. Однако эксперт не всегда может установить, какие именно события противоречат друг другу. Если это прямое противоречие, то все просто. Допустим, две компании объединились, а их уставной капитал уменьшился. В более общих случаях, если один поток событий противоречит другому, то, скорее всего, где-то появился недобросовестный канал информации, и установить его достаточно сложно.
СКД можно также использовать для поиска документов, поскольку она является хорошим описанием документа и на ее основе можно реализовать систему поиска любой сложности. В некоторых случаях достаточно хранить только триады, а не документы. На качестве автоматических выводов это не отразится. Смысловая карта устанавливает связи между важными словами документа, чего нельзя сделать с помощью традиционной поисковой технологии с использованием ключевых слов. Кроме того, рубрикатор определяет структуру данных предметной области, которая позволяет структурировать документы в хранилище и впоследствии искать их более быстро. К тому же в хранилище могут содержаться как смысловые карты, так и сами документы.
Анализ данных, накопленных в таком хранилище, позволяет выделить из потока информации допустимые последовательности событий. Например, мы фиксируем все события, происходящие на определенном рынке. И вдруг появляется сообщение, что компания X выпустила продукт Y, предназначенный для этого рынка, а у нас в хранилище такой компании нет. Следовательно, мы пропустили событие образования новой компании или переориентации уже существующей. Эту информацию нужно восполнить. Таким образом, с помощью простого анализа данных можно делать выводы о пропусках во входящей информации. Причем причинно-следственные связи, по которым делаются выводы о пропуске информации, входят в модель предметной области.
Применение
Для работы KnowledgePump необходима правильно построенная модель предметной области. Это работа аналитика, который хорошо знает предмет и может строить не только простые, но и более сложные взаимосвязи. Фактически данный продукт является заготовкой для экспертной системы. Чтобы заготовку эту закончить, необходимо разработать модель предметной области на основе знаний экспертов. Таким образом, «Интертраст» создала инструментарий для разработки экспертных систем.
Когда модель предметной области уже построена, то систему можно использовать для эффективной и целенаправленной доставки информации. В частности, KnowledgePump хорошо подходит для новостных агентств, которые преобразуют события в СКД и рассылают их своим клиентам. Такие новости могут эффективно использоваться аналитическими агентствами, каждое из которых может иметь свою систему причинно-следственных связей в предметной области и тем самым автоматизировать свою деятельность.
В целом KnowledgePump — система, которая не только способна решать определенные информационные задачи, но и позволяет создавать новые виды бизнеса, например, составление и разработку предметной области. «Интертраст», как разработчик технологии, не может заниматься созданием моделей предметной области и СКД. Она лишь разрабатывает и поддерживает информационную систему, которая позволяет выделять важную информацию из большого потока информационных сообщений и эффективно ее обрабатывать. Очевидно, что для правильного использования этой технологии нужны еще разработчики моделей предметных областей и операторы, генерирующие СКД событий. Если компании удастся найти себе соответствующих партнеров, то продукт будет иметь большие перспективы.
Взаимодействие блоков KnowledgePump
Основу KnowledgePump составляет модель документа, которая называется смысловой картой документа (СКД). Она представляет собой набор триад, каждая из которых связывает субъект действия с объектом и самим действием На основе СКД можно делать определенные выводы
 |
Колодец знаний
- Разработчик: компания «Интертраст»; ее основная специализация — разработка сложных приложений на платформе Lotus
- Назначение: автоматизация обработки потока событийной информации
- Используемые технологии: Lotus и Java. Ядром системы является инструментарий ChangePump, разработанный в «Интертраст» на языке Java и предназначенный для построения больших систем на платформе Lotus
- История: ПО KnowledgePump выпущено на рынок в 1999 году