

В компаниях, где активно используются информационные технологии, многие полагают, что вопрос непрерывности бизнес-процессов с точки зрения автоматизации информационных потоков должен исходить в первую очередь от ИТ-подразделения.
В компаниях, где активно используются информационные технологии, многие полагают, что вопрос непрерывности бизнес-процессов с точки зрения автоматизации информационных потоков должен исходить в первую очередь от ИТ-подразделения. Однако это заблуждение.
Технологичность нашей жизни растет стремительно, и закрывать глаза на будущие риски по меньшей мере неразумно. Недавний энергетический кризис в Москве со всей яркостью показал, что ключевые структуры не готовы к чрезвычайной ситуации. К сожалению, в России мало кому известны методы подготовки к кризису и даже суть этих методов.
В западном мире инициатива построения процесса управления непрерывностью бизнеса (Business Continuity Management, BCM) исходит от руководителей бизнеса и распространяется по всем подразделениям компании. Задача ИТ - поддержать общий процесс в своем сегменте. Поскольку ИТ-подразделение рассматривается в зрелых компаниях именно как поставщик ИТ-услуг, то его вклад в непрерывность бизнес-процессов сводится к непрерывности предоставления ИТ-сервисов.
Весь жизненный цикл становления процесса BCM можно разделить на четыре основные стадии, три из которых относятся к проектной деятельности, а последняя - к операционной.
Инициация
На этой стадии руководство компании инициирует проект по внедрению методов управления непрерывностью бизнеса. Еще до старта проекта фиксируются его границы, распределяются проектные роли, предоставляются необходимые ресурсы, устанавливаются критерии контрольных точек. Инициирование проекта может исходить только от высшего руководства и им же поддерживаться. Дальнейшая реализация проекта может происходить по любому открытому проектному стандарту, в частности PMI, PRINCE2. Метод управления проектами PRINCE (PRojects IN Controlled Environments) определяет организацию, управление и контроль исполнения проектов. PRINCE был разработан агентством CCTA (Central Computer and Telecommunications Agency) в 1989 году как правительственный стандарт Великобритании для управления проектами в информационных технологиях.
Разработка требований и стратегии
В случае наступления кризиса ИТ-подразделение, очевидно, не сможет предоставлять все услуги на том же уровне, что и при штатной работе. В числе предоставляемых услуг в любой компании всегда будут те, которые поддерживают критичные бизнес-функции. К примеру, отсутствие сервиса электронной почты вряд ли будет бизнес-критичным при наличии иных средств коммуникации, а вот остановка биллинговой системы будет означать миллионные убытки для операторов сотовой связи. Понятно, что в случае возникновения чрезвычайной ситуации все ресурсы ИТ должны быть сосредоточены именно на бизнес-критичных ИТ-сервисах. Задача этой стадии проекта как раз и заключается в определении списка ключевых ИТ-услуг и минимально необходимого уровня их предоставления в кризисной ситуации. На этой же стадии формируются схемы восстановления ключевых сервисов в кризисных ситуациях и схемы уменьшения рисков, наступления самих катастроф.
Анализ влияния на бизнес
Многие ИТ-директора сталкиваются с ситуацией, когда бизнес-подразделения требуют автоматизировать те или иные бизнес-процессы, причем сами процессы нигде не регламентированы и даже не представлены в виде общих схем. Одна из важных черт проекта по созданию процесса управления непрерывностью бизнеса заключается в том, что сами бизнес-подразделения будут вынуждены выявлять внутренние процессы и выделять среди них критичные. Это еще одна из причин, почему подобный проект должен инициироваться высшим руководством компании, а не ИТ-подразделением.
Любая компания подвержена воздействию внешних факторов. Негативное влияние этих факторов можно разделить на различные группы, например: финансовые потери; увеличение накладных расходов; потеря имиджа на рынке; потеря заказчиков и т. д.
Рассматривая ситуацию, когда внешние факторы воздействуют только на критичные бизнес-процессы, владельцы этих процессов оценивают возможные негативные влияния по вышеуказанным категориям. Исходя из допустимых потерь владельцы процессов определяют минимально допустимый уровень функционирования бизнес-процессов в кризисной ситуации, в частности совместно с руководством ИТ-подразделения они фиксируют минимальный уровень тех ИТ-услуг, которые эти процессы поддерживают. Также определяется время восстановления ИТ-сервисов до минимального уровня и полное время восстановления до штатного уровня. Эти данные будут использоваться руководителями ИТ-отделов в дальнейшем при построении стратегии непрерывности ИТ-услуг.
Оценка рисков
Существует много различных способов идентификации и оценки рисков в предоставлении ИТ-услуг. Одним из самых устоявшихся и рекомендуемых в ИТ-подразделениях является метод CRAMM (the UK Government Risk Analysis and Management Method). Этот метод разработан Службой безопасности Великобритании (UK Security Service) по заданию британского правительства и взят на вооружение в качестве государственного стандарта. Он используется начиная с 1985 года правительственными и коммерческими организациями Великобритании. За это время CRAMM приобрел популярность во всем мире. Фирма Insight Consulting Limited занимается разработкой и сопровождением одноименного программного продукта, реализующего метод CRAMM. В настоящее время CRAMM - это довольно мощный инструмент, позволяющий, помимо анализа рисков, решать также и ряд других аудиторских задач. В его основе лежит комплексный подход к оценке рисков, сочетающий количественные и качественные аналитические компоненты. Метод является универсальным и подходит не только для больших, но и для мелких организаций как правительственного, так и коммерческого сектора.
Суть метода состоит в следующем. После идентификации бизнес-критичных ИТ-услуг внутри ИТ-подразделения составляется список всех ИТ-активов, входящих в состав этих сервисов. Для каждого ИТ-актива определяются угрозы, то есть список негативных внешних воздействий, могущих привести к недоступности этого актива. К угрозам относится:
- умышленная порча оборудования;
- уход с рынка ключевого провайдера;
- сетевые атаки;
- пожар в помещении;
- террористическая атака;
- саботаж;
- отключение электричества;
- нарушение процедур эксплуатации (человеческая ошибка) и т. д.
Для каждой угрозы определяется величина, то есть вероятность ее наступления. Она может быть оценена по статистическим данным либо субъективно.
Далее для каждого ИТ-актива определяется его уязвимость по отношению к угрозам. Это означает степень влияния внешнего фактора на общий ИТ-сервис в случае воздействия этого фактора на данный ИТ-актив. Обычно высокая уязвимость ИТ-актива связана с тем, что он является единой точкой сбоя в процессе предоставления ИТ-услуги. Например, если один источник питания обслуживает кластер серверов, предоставляющих бизнес-критичную информацию, то такой источник питания будет уязвимым компонентом ИТ-услуги по отношению к отключению электричества.
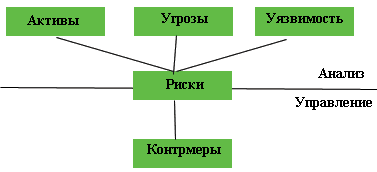
|
| Рис. 2. Метод анализа рисков CRAMM |
Наступление угрозы в одном из ИТ-компонентов означает определенный вид нарушения ИТ-сервиса в целом, например недоступность технического персонала, потеря данных, полное разрушение ИТ-систем (в случае глобальных угроз), недоступность сети и т. д. Возможность подобных нарушений идентифицируется в качестве рисков, связанных с ИТ-сервисом в целом.
Наконец, степень риска ИТ-сервиса определяется как произведение вероятности угрозы на уязвимость актива по отношению к этой угрозе.
Количество оцененных таким образом рисков для каждого ИТ-сервиса может быть очень велико, поэтому часто в крупных компаниях пользуются правилом Tор 10, когда рассматриваются лишь первые десять самых распространенных рисков.
Разработка стратегии непрерывности бизнеса
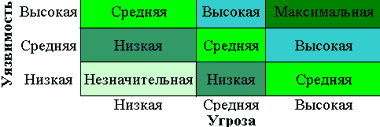
|
| Определение степени риска |
Идентификация и оценка степени - это первый шаг к управлению рисками. Управлять рисками означает принимать меры по уменьшению вероятности и степени воздействия риска и быть готовым к кризисным ситуациям в случае их наступления. На этой стадии ИТ-подразделение разрабатывает методы уменьшения рисков и методы работ в чрезвычайных ситуациях. Различные системы резервного копирования, бесперебойные источники питания, системы информационной защиты - все это примеры принятия мер по увеличению отказоустойчивости ИТ-сервисов. Однако подготовка и применение мер по восстановлению работы ИТ в кризисной ситуации не столь распространены сейчас в России. Существует несколько возможностей восстановления ИТ-сервисов в случае их полного или частичного разрушения.
Ничего не делать. Пожалуй, не самый популярный в последнее время метод. Однако он существует.
Обходные пути вручную. Это метод восстановления критичных бизнес-процессов за счет перевода их на «бумажный» режим. Бухгалтерия, служба охраны и прочие подразделения компании в этом случае должны иметь возможность быстрого переключения на бумажную работу, а это означает наличие сейфов с томами различных разлинованных журналов.
Взаимные соглашения. Этот метод заключается в поиске организации с аналогичной структурой автоматизации основных бизнес-процессов и заключения двустороннего соглашения об использовании ее инфраструктуры в критических ситуациях. Более того, две аналогичные в смысле ИТ-сервисов организации могут объединить некоторые свои системы, делая их распределенными, то есть более устойчивыми к угрозам.
Постепенное восстановление. Применимо для организаций, чей бизнес не пострадает при простое ключевых ИТ-сервисов в течение 72 часов. За это время ИТ-подразделению может быть предоставлено третьей стороной на коммерческой основе либо самой организацией новое, полностью оборудованное телекоммуникационной сетью помещение. Также при выборе помещения необходимо учитывать количество сотрудников, которые будут находиться при восстановлении и потреблении ключевых ИТ-сервисов. Обычно заранее оговаривается количество, состав рабочих мест и серверов в помещении, а также то, чьими силами будут переноситься данные из зоны чрезвычайной ситуации в новое помещение.
Промежуточное восстановление. Этот вид восстановления применим для организаций, в которых простой критичных ИТ-сервисов допустим в пределе от 24 до 72 часов. Обычно этот вид восстановления доступен на коммерческой основе. Специальные поставщики восстановления ИТ-услуг предлагают единое, хорошо охраняемое помещение с уже работающей ИТ-инфраструктурой, предоставляющей определенные, общие для различных организаций ключевые ИТ-услуги. В случае наступления кризиса организация использует внешние работающие ИТ-сервисы на территории поставщика. Минусом здесь может быть удаленность от организации-заказчика. Зачастую поставщик предоставляет мобильные ИТ-услуги: полностью снабженный необходимым телекоммуникационным оборудованием трейлер доставляется до территории заказчика. Этот трейлер соединен беспроводной связью с центром обработки данных поставщика. В стоимость использования внешних ИТ-услуг входит их техническое обслуживание и их бесперебойное предоставление. Стоимость за пользование внешними услугами обычно взимается на ежедневной основе.
Максимальное время пользования услугами восстанавливающих компаний оговаривается в контракте и обычно составляет 6-12 недель.
Немедленное восстановление. Этот метод восстановления применим для компаний, чей бизнес почти полностью зависит от ИТ, таких как брокерские компании, банки, операторы сотовой связи и т. д. Суть заключается в том, что компания снимает у сторонней коммерческой организации помещение, в котором уже сформирована инфраструктура, полностью совпадающая с инфраструктурой компании. Все основные приложения поддерживаются в рабочем состоянии командой поставщика, а все данные в этих зеркальных инфраструктурах полностью синхронизированы. В случае катастроф организация переключается на зеркальную инфраструктуру, при этом все ИТ-сервисы доступны из другого источника. Подобный вид переключения и потребления ИТ-сервисов из зеркальной инфраструктуры означает наличие устойчивого канала связи. Иногда организации предпочитают снять у поставщика дополнительные площадь и рабочие места для своих ключевых сотрудников (например, ключевых брокеров на случай «падения» основного канала связи). Конечно, подобный вид услуги восстановления оказывается весьма дорогим удовольствием, но многие организации готовы идти на это, так как возможные убытки от простоя бизнеса существенно превышают абонентскую плату за ренту зеркальной инфраструктуры.
Планирование внедрения
После того как выработана стратегия уменьшения рисков и методов восстановления, начинается стадия внедрения механизмов управления непрерывностью бизнеса. На этой стадии различные подразделения разрабатывают детальные планы по распределению ролей и ответственности в организации в случае катастроф, взаимодействию с общественностью, управлению безопасностью, оценке ущерба, спасению имущества и т. д. Подразделение ИТ в свою очередь детально разрабатывает планы по восстановлению телекоммуникационного и компьютерного оборудования в кризисной ситуации.
Внедрение
Дальнейшее внедрение разработанных планов идет по трем направлениям.
Принятие мер по уменьшению рисков. Собственно, это знакомое всем внедрение систем повышения безопасности и отказоустойчивости - от различных смарт-карт до создания распределенных систем.
Поиск запасных площадок. На этой стадии проводится поиск коммерческих организаций, предоставляющих услуги по восстановлению ИТ в кризисных ситуациях, выбор нужных площадок, подготовку и настройку ИТ-систем, закупку нового оборудования.
Разработка плана и процедур восстановления. На этой стадии руководство ИТ разрабатывает детальный план по управлению непрерывности ИТ-сервисов. Стоит напомнить, что управление непрерывностью ИТ-сервисов - это лишь малая часть большого процесса управления непрерывностью бизнеса. На этой стадии определяются процедуры по восстановлению ключевых ИТ-сервисов в определенном порядке за минимально допустимое время до минимально допустимого уровня. Эти процедуры могут включать, например, разработку инструкций, согласно которым любой ИТ-специалист, незнакомый со спецификой ИТ-сервиса, мог бы шаг за шагом восстановить его в указанный временной период.
Начальное тестирование. Эта стадия предполагает первое эмулирование кризисной ситуации, в ходе которой определяются реальное время восстановления определенных ИТ-систем. К процедуре тестирования привлекается весь ИТ-персонал - от системных администраторов до службы Service Desk. Первое тестирование может происходить и без сотрудников бизнес-подразделений, однако для полноценного тестирования рекомендуется их привлечение.
Операционное управление
Тактика «внедрить и забыть» неизбежно приведет к тому, что организация будет не готова к кризисной ситуации. Руководство должно заботиться о поддержании планов в актуальном состоянии, а также к тому, чтобы персонал был готов к встрече с кризисом. Это осуществляется через операционное управление и включает в себя следующие мероприятия.
Обучение и оповещение. Обучение и оповещение должно проводиться с сотрудниками абсолютно всех подразделений организации. Персонал компании должен знать о существовании процессов управления непрерывностью бизнеса (в частности, ИТ-персонал - об управлении непрерывностью ИТ-сервисов) и воспринимать это как часть повседневной жизни.
Пересмотр и аудит. Возможное появление новых внешних угроз или автоматизация новых бизнес-процессов означает неизбежное изменение требований к имеющимся ключевым ИТ-сервисам. Регулярное обновление планов и процедур по обеспечению непрерывности ключевых ИТ-услуг позволит ИТ-подразделению гибко приспосабливаться к изменяющемуся бизнесу организации.
Тестирование. Как и в случае первого эмулирования кризисной ситуации, организация должна быть постоянно готова к принятию быстрых мер. «Учебные тревоги» должны стать частью штатной жизнедеятельности крупных организаций.
Управление изменениями. Процесс управления изменениями, если таковой внедрен в организации, должен быть привлечен к управлению непрерывностью ИТ-услуг для четкого понимания того, как изменение внутри ИТ может повлиять на доступность ключевых ИТ-услуг в кризисной ситуации.
Обучение ИТ. ИТ-персонал может быть привлечен к обучению функционирования ключевых бизнес-процессов с целью понять собственный вклад в управление непрерывностью бизнеса.
Управление непрерывностью бизнеса дает организации гарантии устойчивости к внешним рискам.
В западных компаниях, где управление рисками уже давно стало нормой функционирования любого крупного бизнеса, внедрение подобного процесса уже вошло в повседневную практику.
Однако необходимость внедрения столь недешевого и полномасштабного процесса в российских компаниях наверняка еще долгое время будет темой для обсуждения на конференциях. И дело здесь скорее не в отсутствии денежных средств, а в готовности сознания бизнес-руководителей принять данный процесс как жизненную необходимость. Однако повышенный интерес к этой теме со стороны ИТ-руководителей оставляет надежду на рост интереса к данному процессу со стороны и бизнес-руководителей. А это в свою очередь означает перспективу развития новой ниши российского ИТ-рынка - рынка поставщиков услуг по восстановлению ИТ в кризисных ситуациях.
Алексей Авакян - руководитель направления консалтинга по построению процессов ITIL/ITSM, CROC, AAvakyan@croc.ru