

Реляционные СУБД — далеко не идеал, написано об этом достаточно. Хорошо, что пишут и про то, что чисто объектные СУБД тоже не панацея, хотя у них есть свои преимущества. Но ведь и у сетевых, и у иерархических систем были и остаются достоинства, про которые нельзя забывать. Вот бы соединить плюсы таких систем и моделей данных в одной СУБД!
Есть и другая сторона медали. Надо отчетливо представлять, ради чего применять СУБД и какие механизмы в них использовать. Мы имеем в виду случаи длительного хранения данных, отражающих структурно сложные предметные области. Наша цель — показать, какие классические, но часто забываемые возможности должны использоваться, какие средства и инструменты позволяют их практически сочетать с новыми средствами информационных технологий.
Статус-кво
Появление промышленных СУБД устранило несколько основных недостатков файловых хранилищ данных, дав средства устранения избыточности за счет поддержания связанной совокупности агрегатов данных, а также обеспечило сохранение и восстановление всей совокупности данных вне зависимости от способов их хранения и обработки. Вопрос проектирования корректных и эффективных структур данных рассматривался как ключевой.
Что произошло дальше?
Число распространенных промышленных СУБД увеличилось, SQL стал стандартом, а технические возможности хранения данных возросли. В силу этого при выборе СУБД все еще оценивают платформу для ее применения, технологию проектирования, сопровождающую применение СУБД, рассматривают языки программирования приложений. Пожалуй, и все. А вопрос структур логической организации и хранения данных, которые может поддерживать СУБД, вроде бы отошел на второй план.
Вместе с тем в АИС, проектируемых для использования в течение длительного времени, поддержка различных структур данных очень важна. И это оказывается напрямую связано с тем, насколько правильно вложены деньги в СУБД как в базовое ПО для хранения данных, рассчитанное на длительный период, например, на десятки лет. «Плохой» выбор чреват либо заменой СУБД в обозримом будущем, либо постоянными дополнительными инвестициями — закупкой мощностей, перепрограммированием приложений.
Корни проблем и практические мотивы
В качестве пробного камня для проверки плюсов и минусов разных систем и моделей мы выбрали возможности отражения в БД сложных структур данных и, в первую очередь, структурных связей между данными. Это вызвано тем, что при ограниченных возможностях отражения в структуре БД особенностей предметной области будут возникать значительные потери непротиворечивости накапливаемых данных. Как следствие, будут возникать серьезные претензии пользователей к хранилищу данных (то есть к БД), что приведет к необходимости дорогостоящего перепроектирования и перевода накопленных данных на новую СУБД. (Является ли «хранилище» — DataWareHouse — принципиально новой идеей или просто другим названием старых добрых БД? Авторы склонны ко второй точке зрения, поскольку VLDB (Very Large Data Bases) разных типов создаются десятки лет, да и другие особенности, приписываемые DWH, просто выделяют некоторые классы БД из всего разнообразия.)
Конечно, проблемы вызваны не только ограничениями СУБД. На наш взгляд, распространенной бедой является и пробел в самом понимании разработчиками того, что же такое база данных (как их хранилище), хотя определения этого понятия даны еще в шестидесятых-семидесятых годах. К сожалению, этот пробел образуется в вузах, где основное внимание уделяется программированию, в лучшем случае — основам проектирования приложений, но не основам построения хранилищ данных как средству отображения предметной области.
И еще одно: не хотелось бы говорить об упускаемых возможностях, если нет средств их практической реализации. Однако существует промышленная система, которая позволяет разработчикам использовать такие возможности, интегрируя плюсы классических СУБД различных типов, развивая их и дополняя новыми методами обработки данных.
О связях
Рассмотрим некоторые детали отображения предметной области структурами данных. Более конкретно — остановимся на представлении связей между агрегатами данных в БД, как бы они ни назывались в разных СУБД: записями, сегментами, группами, строками таблиц или объектами.
Наиболее известны такие структурные связи (особенности в правилах существования связей мы не рассматриваем): один-к-одному (один экземпляр агрегата данных может быть связан с одним экземпляром агрегата другого типа); один-ко-многим (один экземпляр связан со многими экземплярами другого типа); многие-ко-многим (один экземпляр связан со многими экземплярами другого типа, а каждый из последних — со многими другими экземплярами исходного типа); разветвленная (один экземпляр может быть связан с экземплярами нескольких других типов); рекурсивная (один экземпляр данного типа может быть связан с другими экземплярами этого же типа или сам с собой).
Есть и варианты этих связей, сочетающие разные их свойства.
О моделях данных
Часто, говоря о моделях данных различных СУБД, различают их именно по поддержанию тех или иных связей между агрегатами БД в ее физическом или логическом представлении (мы не претендуем здесь на исчерпание термина «модель данных»).
Иерархическая модель
Эта модель и поддерживающие ее СУБД хорошо реализуют БД, в которых нужно отследить однозначно определенную иерархию агрегатов и при этом реализовать быстрый поиск, соответствующий именно этой иерархии. Но в иерархических моделях невозможно реализовать отношения многие-ко-многим и рекурсии без применения искусственных приемов, из-за которых возникает избыточность хранимой информации. Наиболее характерными представителями СУБД, поддерживающих эту модель, являются IMS, ADABAS, System 2000.
Реляционная модель и ее развитие — объектно-реляционный подход
Самым большим недостатком реляционных БД является то, что на физическом уровне они фактически не работают или почти не работают со связями. Это ограничение лежит в основе проблем представляющих их СУБД. Кроме того, связи многие-ко-многим реализуются дополнительными таблицами.
В отличие от реляционной модели, где данные представляются и обрабатываются на уровне строк и столбцов, при объектно-реляционном подходе операции могут выполняться на более высоком уровне — с объектами, «окружающими» структурно развитые данные (например, совокупность агрегатов нескольких типов).
Практика показывает, что в этом классе СУБД существует необходимость дальнейшего совершенствования аппарата работы со связями — при всех их способностях достаточно адекватно отражать большой спектр структур предметных областей.
Представители — DB2, Sybase, SQL Server, Oracle.
Сетевые модели данных
Эти модели чаще всего связываются со стандартами CODASYL и их развитием в конкретных реализациях. Они представляют совокупности агрегатов (может быть, составных), различные связи между которыми устанавливаются с помощью адресных указателей и индексов. В некоторых вариантах модели данных допускаются и n-арные отношения многие-ко-многим с включением в БД специальных индексов, моделирующих такие связи. А вот произвольные прямые отношения многие-ко-многим недопустимы, что приводит иногда к крайне сложным построениям в структуре БД. Наиболее характерными представителями СУБД, поддерживающих эту модель данных, являются IDMS, IDS и MDBS.
СУБД TITANIUM
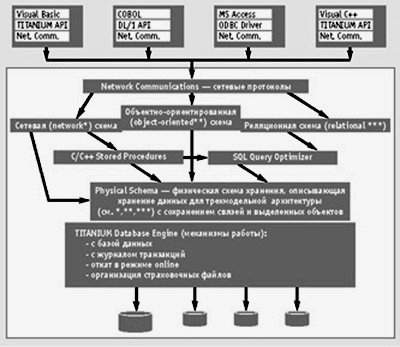 Рис. 2. Архитектура, реализующая мультимодельные возможности TITANIUM |
По мнению авторов, хорошим примером реализации практически полного набора необходимых структур, видов связей и моделей, представляющих данные для обработки, являются системы фирмы MDBS: СУБД MDBS-IV и ее современное развитие СУБД TITANIUM. Причем в TITANIUM достигнуто органичное соединение мультимодельного представления данных с эффективным аппаратом их физического хранения. Поэтому именно на ее примере покажем «интеграцию плюсов».
Общая характеристика
TITANIUM содержит все компоненты классической СУБД как системного программного продукта с функциями, характерными для развитых многопользовательских СУБД (управление буферным пулом, система обработки очередей транзакций, механизмы многопользовательской блокировки данных, ведение журнала транзакций, механизмы разграничения доступа, откат и др.).
Архитектура физического хранения и доступа к данным разработана так, чтобы минимизировать операции ввода/вывода, особенно для сложных операций, охватывающих много таблиц или типов агрегатов данных. Для этого используется т. наз. мультимодельный динамический массив указателей (multi-model Dynamic-Pointer Array — DPA), который основан на специальной запатентованной технологии DPA (патент США, № 5, 611, 076). DPA используется в TITANIUM как самостоятельная конструкция данных для реализации связей в сложных структурных моделях предметной области, отображаемых в физическом устройстве БД. Можно сказать, что тем самым используется положительный опыт применения первых СУБД (IMS, ADABAS).
В дополнение к DPA в TITANIUM используются и другие методы оптимизации работы с памятью: «кластеризация» логически связанных агрегатов в одной физической области, хеширование агрегатов, записи переменной длины, автоматическое сжатие поля, размеры страницы с перестраиваемой конфигурацией и др.
Как физически поддерживаются сложные связи
DPA — это специализированные индексные структуры, которые заменяют потребность в избыточных ключах в связанных агрегатах данных при их физическом хранении и формируют информацию для объединения таблиц (говоря в реляционно-ориентированных терминах). В элементе DPA для каждой отсылочной строки таблицы формируются четырехбайтовые указатели, которые ссылаются на строки таблиц, связанные с исходной строкой. Тем самым дается возможность выполнять объединение нужных строк внутри одной таблицы или из разных таблиц без их предварительной обработки. Алгоритмы DPA построены так, что время выполнения объединения практически не увеличивается с ростом размеров таблиц; оно увеличивается только с фактическим увеличением числа связанных строк. DPA используются для всех уровней агрегатных структур с достаточной эффективностью, например в DPA поддержку связей многие-ко-многим можно описать как естественное добавление к связи один-ко-многим еще одного набора указателей.
Логика связей в TITANIUM
TITANIUM для базы данных поддерживает следующие типы связей (мы называем их в оригинальной нотации).
One-to-one, One-to-one recursive One-to-many, One-to-many recursive Many-to-one, Many-to-one recursive Many-to-many, Many-to-many recursive, а также: One-to-many (n-ary), One-to-many (n-ary) recursive, Many (n-ary)-to-one, Many (n-ary)-to-one recursive, Many (n-ary)-to-many (n-ary), Many (n-ary)-to-many (n-ary) recursive
Связи (n-ary) позволяют из одного агрегата (объекта) БД одновременно «видеть» несколько объектов, причем с возможностью их связывания по разным типам обычных связей.
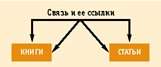 Рис. 1. Фрагмент схемы базы данных, содержащей (n-ary)-ную связь, реализующую и рекурсивные связи и связи многие-ко-многим |
Для иллюстрации возможностей разработчика, обладающего таким арсеналом связей, приведем пример представления связи many (n-ary)-to-many (n-ary) recursive (см. рис. 1). В этом примере одна книга или статья может ссылаться на несколько книг и статей, ссылки на одну книгу или статью могут содержаться в нескольких книгах или статьях. Здесь связь типа «ссылка» заменяет (или объединяет) три не (n-ary)-ные связи: «книги — статьи», «книги — книги», «статьи — статьи»; при этом, за счет такой связи, из объекта «книга» сразу доступны как книги, так и статьи, на которые имеются ссылки в просматриваемой книге.
Мультимодельная архитектура
Для описания предметных областей TITANIUM продолжает (развивая MDBS-IV) опыт реализации мультимодельной архитектуры БД, которая позволяет использовать одновременно и «на равных» возможности реляционных, объектных, иерархических и сетевых моделей данных. Мультимодельная архитектура TITANIUM позволяет каждому разработчику выбирать ту модель данных, которая наиболее соответствует разрабатываемому им приложению, при этом обеспечивает несколько API-интерфейсов, включая ODBC, DL/1 IMS, DMN1100/2200 и библиотеки объекто-ориентированного класса для C++, Smalltalk и Object/1.
Особенности моделей
Реляционная модель позволяет пользователям и разработчикам обрабатывать на SQL базу данных как набор таблиц. Никакие расширения к SQL не нужны, реляционные пользователи имеют полный доступ для операций чтения записи в базе данных. Синтаксис SQL соответствует стандарту ANSI2 и поддерживает стандартный API уровня Microsoft ODBC. Поддерживаются также механизмы триггеров и хранимых процедур.
Объектная модель обеспечивает стандартный ODMG-интерфейс для разработчиков, использующих языки типа C++ и JAVA. Плюсы модели:
- объявление и манипулирование объектами базы данных интуитивно понятно и естественно для объектно-ориентированного разработчика;
- навигация по сложным связям между объектами осуществляется быстро из-за доступа к объектному интерфейсу низкого уровня для каждого объекта и связи.
Навигационная модель (предлагается как расширение сетевой) обеспечивает прямо вызываемый через API-интерфейс для необъектных языков типа C, Visual Basic и COBOL доступ к описанной для приложения структуры БД.
От симуляции — к непосредственному представлению
Многие системы, предлагаемые как СУБД, имеют хороший интерфейс прикладного программирования и позволяют быстро автоматизировать простые информационные процессы, но имеют «недоразвитые» механизмы в смысле соответствия самым изначальным понятиям баз данных и зачастую разукрашиваются на рынке под модные течения. Они не обладают полным набором фундаментальных свойств, особенно с позиции полноты возможностей двух уровней описания данных в их взаимосвязи: логической организации данных и структуры их хранения. Все возможные режимы «симуляции» (моделирования) для представления нужных пользователям моделей и связей на основе одной, непосредственно реализованной в такой СУБД, модели так или иначе приводят к критическим состояниям в разработке приложений и в эксплуатации АИС (длительность разработки, неудобно общаться, большие времена ответов на запросы, требуется более мощная техника и т. п.).
Может показаться, что положение безвыходное: или имей ограничения какой-то одной модели с ее недостатками (см. выше), или столкнешься с проблемами при моделировании недостающих возможностей. Однако нам кажется, что есть путь, на котором все богатство классических возможностей интегрируется, но не игнорируются и новые технологии. Разработчик не должен ограничивать себя ни в использовании самых разных структур данных и связей, ни в выборе модели данных при разработке приложений (на наш взгляд, этому и служит СУБД TITANIUM). И тогда путь к проектированию «правильных» баз данных станет прямее, а создаваемые АИС — более живучими и экономными.
Алексей Дмитриевич Агеев — генеральный директор, Евгений Викторович Розанов — заместитель генерального директора фирмы ЭКСИНТ. С ними можно связаться по адресу: exint@rinet.ru.