
«Открытые системы»
Десятилетиями создатели информационных технологий упускали из виду предмет своей деятельности — информацию. Точнее, информация присутствовала, но как-то неявно, обычно ее отождествляли с данными. Semantic Web — одно из тех явлений в мире ИТ, которые заставляют всерьез задуматься о различии между данными и информацией
За создание World Wide Web англичанин Тим Бернерс-Ли был удостоен дворянского звания, и теперь с позиции признанного гуру сэр Бернерс-Ли регулярно выступает перед компьютерной общественностью, излагая взгляды на будущее WWW. В своих лекциях он признается, что изобретение Web оказалось не слишком сложным делом, ведь к тому моменту необходимый базис был сформирован. Протокол HTTP и язык HTML оказались декоративными деталями, которые требовалось добавить к готовому костюму Internet, состоящему из протоколов TCP/IP и ряда других стандартов. Возникшие вскоре «e-коммерция» и «е-бизнес» придали Web особую популярность, но на самом деле они оказались незаконнорожденными детьми Паутины. Ее авторы (а говоря на эту тему, не следует забывать об оставшемся в тени Бернерса-Ли его коллеге, швейцарце Роберте Калио) задумывали Web лишь как средство, расширяющее возможности общения. В этом смысле самыми естественными порождениями Паутины оказались вики и блоги, служащие усилению креативности в процессе межличностного взаимодействия.
|
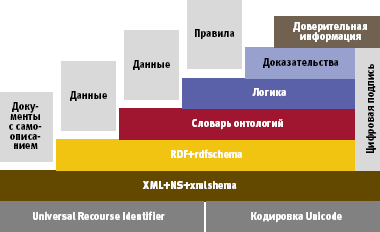
| Оригинальная модель Semantic Web |
Но еще в начале 90-х годов Бернерс-Ли и Калио предполагали возможность включения метаданных в гиперсвязи, задумываясь о том, как дополнить их сведениями, относящимися к передаваемым данным. Практика показывает, что для общения между людьми метаданные критического значения не имеют: люди сами являются носителями контекста, в большинстве случаев им достаточного для понимания смысла сообщения, описывать переданное сообщение не требуется; правда, нередко неверное понимание контекста приводит к ошибкам. Иное дело машины. Здесь контекст должен быть зашит жестко, чтобы полученное сообщение однозначно интерпретировалось (скажем, если данные поступают в систему от датчика). Если же это невозможно, то нужны дополнительные сведения о том, как следует интерпретировать полученное сообщение; такие дополнительные данные и называют метаданными. Эти метаданные могут интерпретироваться машинными средствами, а потому открывают возможность установить взаимоотношения не только между людьми, но и между сайтами, и между устройствами, включенными в Сеть. Встраивание метаданных в гиперсвязи — главное отличие пропагандируемого Бернерсом-Ли второго поколения Всемирной Паутины, которое он называет Semantic Web, или Web для машин.
Обобщив многочисленные высказывания относительно Semantic Web, нетрудно сделать очень простое умозаключение. Передавая человеку сообщение, мы неявно предполагаем, что он сам может извлечь из данных полезную ему информацию, хотя далеко не всегда это делается верно. Создавая Web для машин, мы должны дать им возможность извлекать из данных полезную машинам информацию, но как это выполнить? Сделаем акцент на слове «информация», подчеркнув, что объектом обмена является информация, а не данные. По причинам, о которых можно только догадываться, нигде и никогда соотношение между данными и информацией проповедниками нового поколения Web явно не озвучивалось. Но в этом-то и состоит суть. К тому же нужно признать, что необходимость в работе с информацией не является чем-то исключительным, присущим только Semantic Web. Бернерс-Ли и его коллеги по консорциуму W3C занимают кулуарную позицию, они, похоже, не замечают параллельных тенденций, возникающих в других областях ИТ. Не углубляясь в определение того, что есть информация, иначе можно уйти в непроходимые дебри, остановимся на самом простейшем толковании. Допустим, что информация является суммой данных и метаданных, относящихся к этим данным.
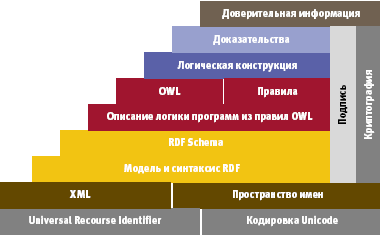
Предшествующий опыт подсказывает, что для создания Semantic Web следует построить информационную коммуникационную модель, аналогичную семиуровневой модели OSI (но в приложении к Web) и ориентированную на обмен информацией, а не данными. Именно так и поступил Бернерс-Ли. Начиная с 1998 года, он популяризирует разработанную им многоуровневую модель Semantic Web. В наиболее наглядном виде она может быть оформлена в форме стека уже существующих и проектируемых стандартов. На рисунках представлена редакция стека, датируемая 2000-м и 2005 годом. Используемые для построения модели понятия и конструкции достаточно сложны и специфичны, поэтому опишем эти модели на самом поверхностном уровне, предоставив возможность тем, кто пожелает разобраться в этом вопросе глубже, сделать это самостоятельно.
|
| Стек стандартов Semantic Web в редакции 2005 года |
Если проводить аналогию с моделью OSI, то нижние уровни URI (Uniform Resource Identifier), кодировка Unicode, XML и XML Schema соответствуют нижним уровням семиуровневой модели, они обеспечивают представление, но не налагают никаких семантических ограничений на содержание этих документов. Основу модели составляют RDF (Resource Description Framework). Модель RDF представляет собой структуру метаданных, предназначенную для описания ресурсов в форме триады. Эту триаду называют субъектно-предикативно-объектным выражением на языке XML. В 1999 году работы по созданию RDF были инициированы компаниями Apple и Netscape, в 2004 году была опубликована совершенно новая редакция RDF 2.0. Уровнем выше стоит RDF Schema, она служит средством для описания свойств и классов RDF-ресурсов, а также задает семантику для иерархий-обобщений таких свойств и классов.
Для представления модели данных, отражающей свойства реального мира, используется еще одно довольно непростое понятие — «онтология». Оно заимствовано из теории систем, в данном случае его можно интерпретировать как некоторый объем знаний. Для описания онтологий служит специальный язык OWL.
Развивая аналогию между моделью OSI и стеком стандартов Semantic Web, отметим, что в обеих моделях на нижнем уровне располагается «физическое представление», но в первом случае — представление данных, а во втором — информации. А на верхнем уровне — «очищенное» представление, готовое для использования. Различие состоит в том, что в модели OSI — это данные, а в модели Semantic Web — информация. Работа и той, и другой модели сводится к установлению соответствия между нижним и верхним уровнями.
Стек стандартов Semantic Web описывает интерфейсы между уровнями, не более того. На эту тему сказано и написано немало, однако пока стек далеко не полон, а в некоторых местах противоречив, поэтому находится в процессе доработки. Но кроме стандартов нужны еще и средства для реализации, поэтому кроме самого стека активно развиваются сервисы, обеспечивающие работу Semantic Web (Semantic Web Services). К сожалению, архитектура Semantic Web Services Architecture еще меньше проработана, чем Semantic Web, известны лишь отдельные исследования, выполненные в университетских лабораториях.
С практической точки зрения наибольший интерес представляет не собственно Semantic Web, а процесс конвергенции идей Semantic Web и Web-сервисов. Развитие в этом направлении может привести к созданию нового поколения сервисов, которые пока условно называют «интеллектуальными Web-сервисами».
Semantic Web
По количеству компьютеризированных данных World Wide Web не имеет себе равных и является самым большим из когда-либо существовавших хранилищ информации. Безусловно, Web — уникальный инструмент и для изучения, и для распространения идей и знаний. Но факт остается фактом: компьютер напрямую не может использовать информацию из Web. Страницы Web изначально рассчитаны на то, что их будут читать люди, а не машины.
Тим Бернерc-Ли, написавший первый Web-сервер и Web-браузер в 1990 году, сегодня руководит консорциумом World Wide Web Consortium. Он считает, что у Web грандиозное будущее, которое он называет Semantic Web. По его словам, в Semantic Web будет добавлена инфраструктура метаданных, состоящая из тэгов и служащая для определения элементов информации на страницах Web. Причем эта структура будет связывать элементы информации так же легко, как Internet сейчас связывает отдельные документы, в результате чего компьютеры смогут воспринимать смысл широко распределенных данных. Semantic Web позволит как машинам, так и людям искать, читать, воспринимать и использовать данные из Web для выполнения полезных задач. Semantic Web расширит, а не заменит Web в том виде, в каком мы знаем ее сейчас.
В некоторых случаях мы уже используем специализированное программное обеспечение для работы с тщательно отобранными данными Web, но это скорее исключение, чем правило. Такой программный инструментарий позволяет работать в Web и делать покупки в Internet-магазинах, воспринимать результаты, предоставленные механизмами поиска, и решать, по каким дополнительным ссылкам переходить. Semantic Web, как только она станет реальностью, даст пользователям возможность инициировать агента или процесс, который затем будет действовать самостоятельно, хотя, возможно, пользователь периодически станет контролировать его работу.
Изначально Internet создавали как средство, позволяющее ученым обмениваться друг с другом данными. Для пересылки файлов применялись базовые методы, такие как протокол передачи файлов FTP. Данные транслировались по Internet в виде битов и байтов, однако основной воспринимаемой единицей оставался файл, поскольку для этого были задействованы компьютерные системы.
Ситуация изменилась с появлением Web. Бернерc-Ли создал Web-страницы в виде документов, написанных на HTML. Благодаря своей гибкости язык HTML объединяет интерактивные формы, текстовые и мультимедиа-объекты, описывает, как эти элементы должны быть воспроизведены, а также как в целом должна выглядеть страница. К сожалению, HTML обладает весьма ограниченной возможностью классифицировать блоки текста на странице, что частично объясняется той ролью, которую он играет в типичной организации документов и в выборе графической структуры. Ограничения HTML начали препятствовать все более активному использованию Web. Это привело к созданию XML и XHTML, которые содержат в себе механизмы для указания семантики Web-страниц. Simple Object Access Protocol и Web-сервисы существенно упростили работу пользователей и даже автоматизировали процессы сбора конкретной информации или выполнения определенных функций в Web. Когда будет создана Semantic Web, программное обеспечение сможет локализовывать информацию на самих Web-страницах, тем самым преодолев границы документа и обращаясь к реальным данным, которые будут использоваться напрямую. В определенном смысле Semantic Web станет своего рода глобальной базой данных.
Обучение машин
Иногда трудно осознать, сколько указаний и команд необходимо дать компьютеру для того, чтобы добиться от него чего-нибудь. Машины не могут использовать неполную информацию, они не знают, что изображено на картинке, они не в состоянии проводить аналогии или объединять информацию из различных источников и у них довольно маленький словарный запас.
С помощью Web человек может легко найти статью в Computerworld или в блоге музыкальную запись, которую слышали по радио, купить книгу, найти окулиста, чей кабинет расположен недалеко от офиса, или задать вопрос в форуме или на доске объявлений. Но попросите свой компьютер сделать то же самое, и он не поймет, с чего нужно начинать, если вы не дадите ему точных указаний, корректную серию команд и ответов в нужной последовательности.
Например, с помощью HTML и Web-браузера можно создавать и представить страницу каталога продаваемых товаров. Но у HTML нет встроенной возможности знать, что, скажем, товар No. JG1896 — это сувенир от Acme, и стоит он 9,95 долл. Все, что может указать HTML, — это то, что текст «JG1896» должен быть расположен рядом с текстом «Acme widget» и «$$». HTML «не понимает», что эти фрагменты информации описывают товар, который отличается от других товаров, перечисленных на той же самой странице.
Semantic Web даст компьютерам возможность находить, читать, воспринимать и использовать информацию, содержащуюся в документах Web, для того чтобы решать некие полезные задачи с помощью автоматизированных агентов и Web-сервисов.
Компоненты Semantic Web
Semantic Web создается на основе ряда стандартов и инструментальных средств.
XML определяет основной формат структурированных документов, хотя не имеет конкретной семантики.
XML Schema — это язык, который поддерживает типизацию данных и позволяет накладывать ограничения на структуру документов для того, чтобы обеспечить предсказуемость обработки.
Resource Description Framework (RDF) — это простая трехкомпонентная модель данных (субъект, предикат, объект) для ссылки на объекты или ресурсы и указывающая, как они связаны друг с другом. Модель на базе RDF часто представляется с помощью XML.
Унифицированные (или универсальные) идентификаторы ресурсов (URI) — это короткие символьные строки, которые идентифицируют ресурсы в Web: документы, изображения, загружаемые файлы, сервисы, электронные почтовые ящики и т. п. URI (их также называют универсальными локаторами ресурсов или URL) обеспечивают программам простой доступ к указанным ресурсам.
RDF Schema (RDF-S) описывает свойства, классы и иерархии ресурсов RDF.
Web Ontology Language (OWL) используется для точного представления значений терминов в словарях и описания взаимосвязей между этими терминами. Это представление терминов и их взаимосвязей называется онтологией. OWL имеет больше механизмов для выражения значений, чем XML, RDF и RDF-S, и он превосходит эти языки по возможности представлять контент, который могут интерпретировать машины.
Рассел Кей, Computerworld, США