

SQL Server 2005 вводит понятие пользовательского окна, в котором набор результатов может быть разбит на части в зависимости от выбранных строк. Эти разбиения можно использовать для выполнения определенных вычислений по отношению к текущей строке. Поскольку текущая строка может представлять собой как строку суммирования, так и содержать упорядоченные значения, существует две группы функций, применяемых при отображении: функции для агрегирования и функции для ранжирования. Одна из возможных областей применения этих новых функций отображения – проекты бизнес-анализа. Чтобы продемонстрировать, как ими пользоваться, я создал таблицу 1 под названием Employee с помощью T-SQL кода, приведенного ниже:
CREATE TABLE employee
(employee_id INT NOT NULL,
dept_id INT NOT NULL,
first_name VARCHAR(25),
last_name VARCHAR(25),
salary MONEY,
job VARCHAR(20))
INSERT INTO employee VALUES (1111, 10, 'Martha', 'White', 4400, 'IT_PROG');
INSERT INTO employee VALUES (1112, 10, 'John', 'Black', 8800, 'IT_PROG');
INSERT INTO employee VALUES (1113, 20, 'Bill', 'Austin', 7600, 'MK_REP');
INSERT INTO employee VALUES (1114, 20, 'Diana', 'Kimes', 4300, 'MK_MAN');
INSERT INTO employee VALUES (1115, 20, 'David', 'Peters', 7600, 'IT_PROG');
INSERT INTO employee VALUES (1116, 30, 'Sibille', 'Peterson',12000,'AX_ASST');
INSERT INTO employee VALUES (1117, 30, 'Jack', 'Klein', 9900, 'MK_REP');
INSERT INTO employee VALUES (1118, 30, 'Alex', 'Armstrong', 8500, 'MK_REP');
INSERT INTO employee VALUES (1119, 30, 'Jennifer', 'May', 6700, 'AX_ASST');
INSERT INTO employee VALUES (1120, 40, 'Roy', 'Hunt', 9900, 'IT_PROG');
INSERT INTO employee VALUES (1121, 40, 'Wendy', 'Blunt', 8800, 'AX_ASST');
INSERT INTO employee VALUES (1122, 50, 'Valli', 'Begg', 7900, 'MK_MAN');
INSERT INTO employee VALUES (1123, 50, 'Pat', 'Donaldson', 4900, 'MK_MAN');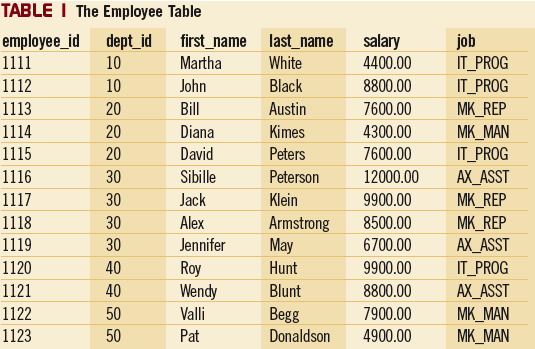
Функции отображения для агрегирования
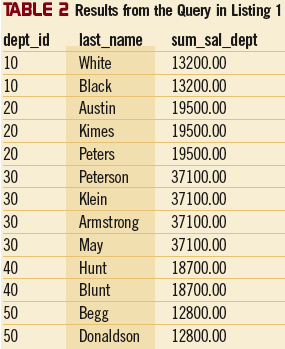 Чтобы определять какие бы то ни было функции отображения, используется выражение OVER. Это выражение группирует результирующий набор запроса в разбиениях так, что каждая строка группы отображается отдельно. Например, выражение OVER в Листинге 1 определяет, что соответствующая функция агрегирования (SUM) является функцией отображения. В данном случае результирующий набор разбивается на четыре группы по идентификатору отдела (dept_id). После этого для каждой группы вычисляется сумма зарплат. Результаты показаны в таблице 2. Обратите внимание, что главное различие между выражениями OVER и GROUP BY состоит в том, что OVER отображает каждую строку группы отдельно, тогда как GROUP BY отображает только одну строку каждой группы.
Чтобы определять какие бы то ни было функции отображения, используется выражение OVER. Это выражение группирует результирующий набор запроса в разбиениях так, что каждая строка группы отображается отдельно. Например, выражение OVER в Листинге 1 определяет, что соответствующая функция агрегирования (SUM) является функцией отображения. В данном случае результирующий набор разбивается на четыре группы по идентификатору отдела (dept_id). После этого для каждой группы вычисляется сумма зарплат. Результаты показаны в таблице 2. Обратите внимание, что главное различие между выражениями OVER и GROUP BY состоит в том, что OVER отображает каждую строку группы отдельно, тогда как GROUP BY отображает только одну строку каждой группы.
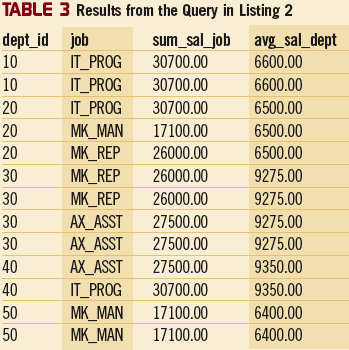
Функции отображения для агрегирования можно использовать и с более сложными вычислениями. Например, можно взять два столбца таблицы и построить по ним различные разбивки, как показано в Листинге 2. У этого запроса одна разбивка по столбцу "вид работы" (job), а другая – по столбцу dept_id. В первой вычисляется сумма зарплат в зависимости от различных видов работ. Во второй вычисляется средняя зарплата по отделам. Результаты запроса Листинга 2 показаны в таблице 3.
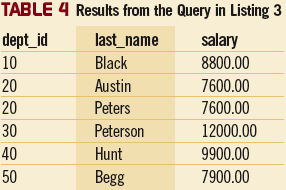 Функции отображения для агрегирования особенно полезны тогда, когда вы используете их в подзапросах, а потом выполняете сравнение, применяя результаты подзапросов. Предположим мы хотим найти в каждом отделе сотрудника с самой высокой зарплатой. Этот запрос содержится в Листинге 3, и его результаты показаны в таблице 4. Используя функцию MAX как функцию отображения для агрегирования, подзапрос в выражении FROM находит максимальное значение зарплаты (max_sal_dept) в каждом отделе. Дальше запрос сравнивает с этим значением зарплату каждого сотрудника отдела. Как видно из этого примера, выражение OVER позволяет использовать строки суммирования одновременно с индивидуализированными строками в каждой разбивке.
Функции отображения для агрегирования особенно полезны тогда, когда вы используете их в подзапросах, а потом выполняете сравнение, применяя результаты подзапросов. Предположим мы хотим найти в каждом отделе сотрудника с самой высокой зарплатой. Этот запрос содержится в Листинге 3, и его результаты показаны в таблице 4. Используя функцию MAX как функцию отображения для агрегирования, подзапрос в выражении FROM находит максимальное значение зарплаты (max_sal_dept) в каждом отделе. Дальше запрос сравнивает с этим значением зарплату каждого сотрудника отдела. Как видно из этого примера, выражение OVER позволяет использовать строки суммирования одновременно с индивидуализированными строками в каждой разбивке.
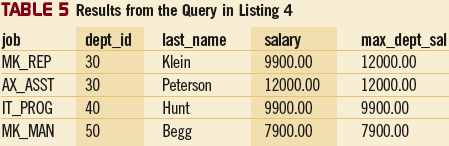
Запрос в Листинге 4 находит сотрудника с самой высокой зарплатой по каждому виду работ, а также самую высокую зарплату в каждом отделе. Для этого запрос создает две разбивки, используя два столбца (job и dept_id) из таблицы Employee. Запрос использует одну и ту же функцию отображения для агрегирования, но применяет их к этим двум разбивкам раздельно. Раздельное применение необходимо потому, что самая высокая зарплата по каждому виду работ не имеет ничего общего с самой высокой зарплатой в каждом отделе. В таблице 5 показаны результаты выполнения запроса Листинга 4.
Функции отображения для ранжирования
 Новые функции отображения для ранжирования в SQL Server 2005 возвращают значение, характеризующее ранг каждой строки в разбивке. T-SQL поддерживает три такие функции: RANK, DENSE_RANK и ROW_NUMBER.
Новые функции отображения для ранжирования в SQL Server 2005 возвращают значение, характеризующее ранг каждой строки в разбивке. T-SQL поддерживает три такие функции: RANK, DENSE_RANK и ROW_NUMBER.
Функцию RANK можно применять к разбивкам, чтобы отобразить ранг строки в результирующем наборе. Например, запрос в Листинге 5 использует функцию RANK, чтобы определить ранг трех самых высокооплачиваемых сотрудников в каждом отделе. Сравнивая операторы SELECT в Листинге 4 и Листинге 5, можно увидеть, что единственное различие между функциями отображения для агрегирования и функцией RANK состоит в том, что функция RANK определяет ранг строк в пределах окна разбивки.
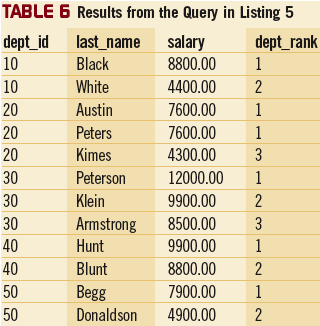
Функция RANK использует логическое группирование – это значит, что когда две или более строки в результирующем наборе имеют одинаковое значение в столбце, по которому производится упорядочение, эти строки будут иметь одинаковый ранг. Следующая строка будет иметь ранг равный единица плюс число строк, предшествовавших этой строке. Например, в таблице 6 имеется два сотрудника (Austin и Peters) из отдела 20 с одинаковой зарплатой. Эти два сотрудника имеют одинаковый ранг (1). Ранг другого сотрудника (Kimes) из этого отдела равен 3. Логическое группирование функции RANK приводит к тому, что числа, соответствующие рангам, идут не подряд, а с промежутками. Если вы не хотите отображать ранжированные строки с неиспользуемыми промежутками, то можете использовать функцию DENSE_RANK. Запрос в Листинге 6 показывает, как пользоваться этой функцией, а в таблице 7 показаны результаты применения запроса. Разницу между функциями DENSE_RANK и RANK можно видеть в строке с данными по сотруднику Kimes. В таблцице 7 в столбце dept_dense против фамилии Kimes стоит ранг 2 (а не 3, как в столбце dept_rank на Рисунке 6) и, таким образом, промежутков неиспользуемых чисел нет.
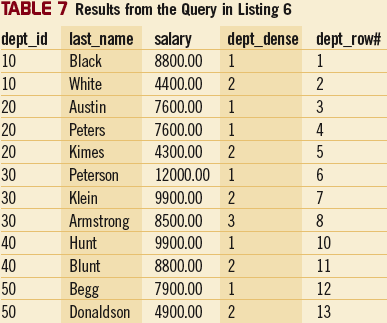
Запрос в Листинге 6 иллюстрирует использование не только функции DENSE_RANK, но и функции ROW_NUMBER. Функция ROW_NUMBER возвращает последовательный номер строки в пределах результирующего набора, начиная с номера 1 для первой строки. Во фрагменте A можно увидеть, что функция ROW_NUMBER использует выражение OVER без параметра PARTITION. В таких случаях вся таблица целиком обрабатывается как одна разбивка. Обратите внимание на то, что в столбце dept_row# пропущен номер 9. Эта строка содержит данные по сотруднику May (employee_id 1119 в таблице 1), который работает в отделе 30. Данные этого сотрудника исключены, поскольку они не удовлетворяют условиям выражения WHERE оператора SELECT (т.е. сотрудник не является одним из трех самых высокооплачиваемых сотрудников отдела).
Стандартизированное решение
Появление в SQL Server 2005 функций отображения для агрегирования и для ранжирования не является воплощением запоздалой идеи. Microsoft реализовала эти функции стараясь оставаться приверженной стандарту SQL:1999. В базах данных IBM DB2 и Oracle также имеются эти функции, а это значит, что их можно использовать в любой из этих трех баз данных.
Душан Петкович (petkovic@fh-rosenheim.de) – профессор в области баз данных политехнического института в Розенхейме (Германия). Он является автором нескольких книг по системам баз данных, в том числе SQL Server 2005: A Beginner’s Guide (Osborne McGraw-Hill).
Листинг 1. Запрос, который находит суммарную зарплату по каждому отделу.
SELECT dept_id, last_name AS name,
SUM(salary) OVER(PARTITION BY dept_id) AS sum_sal_dept
FROM employee;
Листинг 2. Запрос, который находит суммарную и среднюю зарплаты.
SELECT dept_id, job,
SUM(salary) OVER(PARTITION BY job) AS sum_sal_job,
AVG(salary) OVER(PARTITION BY dept_id) AS avg_sal_dept
FROM employee;
Листинг 3. Запрос, который находит в каждом отделе сотрудника с самой высокой зарплатой.
SELECT dept_id, last_name, salary
FROM (SELECT dept_id, last_name, MAX(salary)
OVER (PARTITION BY dept_id) max_sal_dept, salary
FROM employee) AS part_deptid
WHERE salary = max_sal_dept
Листинг 4. Запрос, который находит сотрудника с самой высокой зарплатой по каждому виду работ и самую высокую зарплату в каждом отделе.
SELECT job, dept_id, last_name AS name, salary, max_dept_sal
FROM (SELECT dept_id, job, last_name,
MAX(salary) OVER (PARTITION BY job) max_job_sal, salary,
MAX(salary) OVER (PARTITION BY dept_id) max_dept_sal
FROM employee) AS part_deptid
WHERE salary = max_job_sal
Листинг 5. Запрос, использующий функцию RANK, чтобы определить трех самый высокооплачиваемых сотрудников в каждом отделе.
SELECT dept_id, last_name, salary, dept_rank
FROM (SELECT dept_id, job, last_name, salary,
RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) dept_rank
FROM employee) AS part_dept
WHERE dept_rank <= 3
ORDER BY dept_id, dept_rank
Листинг 6. Запрос, использующий функцию DENSE_RANK, чтобы определить трех самых высокооплачиваемых сотрудников в каждом отделе.
SELECT dept_id, last_name, salary, dept_dense, dept_row#
FROM (SELECT dept_id, job, last_name, salary,
DENSE_RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) dept_dense,
-- BEGIN CALLOUT A
ROW_NUMBER() OVER (ORDER BY dept_id ASC) dept_row#
-- END CALLOUT A
FROM employee) AS part_dept
WHERE dept_dense <= 3
ORDER BY dept_id, dept_dense, dept_row#