

Создаем высоконадежное и устойчивое к сбоям решение, которое легко настраивать и поддерживать
Я работаю старшим консультантом в группе Financial Services Group подразделения Microsoft Consulting Services. Моя задача – помогать клиентам, работающим в финансовой сфере, эффективно использовать технологии баз данных Microsoft. Недавно одному заказчику потребовалось высоконадежное и восстанавливаемое после сбоя решение. Администратор баз данных в его компании не имел практического опыта поддержки решений с высоким коэффициентом надежности (включая репликацию), поэтому клиент хотел получить решение, которое будет несложно настраивать и поддерживать. Я расскажу об этом случае и перечислю шаги, выполненные мной при разработке решения, которое не требует глубоких знаний в области написания сценариев. Если требуется простое в использовании решение с хорошей производительностью и возможностью восстановления после сбоя, изучите этот пример. Возможно, он поможет понять, является ли репликация слиянием правильным выбором в той или иной ситуации.
Требования заказчика
У пользователя, с которым я работал, было два процессинговых центра, удаленных друг от друга на большое расстояние и связанных каналом T2. Заказчику нужно было гибкое высокопроизводительное решение, которое позволило бы в будущем с минимальными усилиями добавить третий сайт. Каждый имеющийся сайт играл роль ведущего узла базы данных SQL Server 2000 на сервере Windows 2000. Оба сервера Windows имели два процессора и 2 Гбайт оперативной памяти. База данных заказчика имела объем около 25 Гбайт и росла медленно (от 200 Mбайт до 500 Mбайт в месяц). Загрузка базы данных была относительно низкой (от 10 до 50 транзакций в минуту). Приложение заказчика находилось в работе в основном с 7 до 9 часов вечера, 5 дней в неделю, и база данных должна была быть доступной на обоих сайтах в рабочее время.
Заказчику хотелось выполнять обработку данных на одном сайте и получать отчеты на другом. В случае аварии на одном вычислительном центре он хотел иметь систему, перехватывающую управление, так, чтобы оставшийся вычислительный центр мог быстро совместить все функции без какой-либо перестройки структуры. Заказчик планировал разделение операций загрузки данных между центрами, но осознавал, что операторы данных могут изменить или удалить вместе одну и ту же запись на обоих сайтах. Для устранения этих возможных конфликтов между двумя сайтами клиент хотел соединить изменения, сделанные пользователями на различных сайтах в разных столбцах, если это возможно. Например, если пользователь на сайте А изменяет столбец 1 и пользователь на сайте В изменяет столбец 2, требовалось объединить оба изменения в результирующей таблице. Многие таблицы имеют одно или более текстовых полей. Некоторые таблицы имеют поля IDENTITY.
Исходя из этих требований, мы вместе с заказчиком определили, что искомое решение будет обеспечивать перенос постоянных данных, автономность абонентов (так, что операции на одном сайте будут оказывать минимальное влияние на другой сайт), обработку изменений на обоих сайтах и разрешение конфликтов данных.
Отдать ли предпочтение репликации слиянием?
SQL Server предлагает несколько дополнительных программных средств, которые поддерживают состояние базы данных близко к реальному времени, включая двухфазную фиксацию, транзакционную репликацию при непрерывном потоке подписчиков на изменение, репликацию моментального снимка с немедленной обработкой подписчиков, транзакционную репликацию (включая двунаправленную репликацию), репликацию моментального снимка, транзакционную репликацию с поочередной обработкой подписчиков, и репликацию слиянием. Исходя из требований заказчика, я предложил применить репликацию слиянием SQL Server 2000 по нескольким причинам. Во-первых, слияние дублирующих друг друга записей имеет надежный, встроенный алгоритм разрешения конфликтов, который может быть легко настроен при помощи Enterprise Manager. В простых случаях написание сценариев не требуется. Репликация слиянием обеспечивает внеблочный алгоритм разрешения конфликтов на уровне столбца и высокую транзакционную совместимость операций в ситуациях по типу той, которую описал мой заказчик, когда конфликты случаются редко и в обработку данных включены только два сайта. К тому же репликация слиянием позволяет дублировать текстовые данные. Это имело значение для клиента, так как в его компании использовалось 10 таблиц баз данных, содержащих текстовые столбцы. Репликация слиянием включает в себя непрерывно выполняющиеся агенты Merge Agents, которые обеспечивают передачу данных с допустимой задержкой. Также репликация слиянием легко выполняет присоединение другого сервера к существующей топологической схеме.
Альтернативные подходы могут иметь свои преимущества, но я не рекомендую использовать прямую обработку данных и поочередную корректировку подписок, так как эти варианты не обрабатывают текстовые данные. Не все типы транзакционной репликации могут объединять одновременные изменения в различных полях на различных сайтах. Моментальная репликация и DTS просто не способны работать в ситуации, когда изменения данных происходят на обеих сторонах одновременно. И двухфазная фиксация - это весьма ненадежное решение, так как даже кратковременная потеря соединения между узлами сети во время транзакции обязательно приведет к сбою приложения. Решив, что реализация схемы достаточно надежна, я приготовил базу данных для репликации слиянием.
Подготовка к репликации слиянием
Перед настройкой репликации слиянием нужно сначала внимательно просмотреть основные компоненты приложения и сформировать специальные технические требования для репликации слиянием. Так как в одной небольшой статье невозможно рассказать обо всех деталях планирования и подготовки, для их изучения я рекомендую почитать секцию в SQL Server 2000 Books Online (далее BOL) под названием "Planning for Merge Replication". Здесь приведен ряд приемов, которые я должен был применить для решения проблем моего заказчика.
Репликация слиянием дублирует текстовые поля, только если они были явно обработаны при помощи предложения UPDATE, которое заставило триггер сработать и обновить метаданные, гарантируя, что транзакция передана подписчикам. Операции WRITETEXT и UPDATETEXT не передают изменения другим сайтам. Для решения этой проблемы я модифицировал несколько хранимых процедур, добавив пустое предложение UPDATE после операций WRITETEXT или UPDATETEXT внутри той же транзакции. В BOL есть пример разработки этого типа модификации.
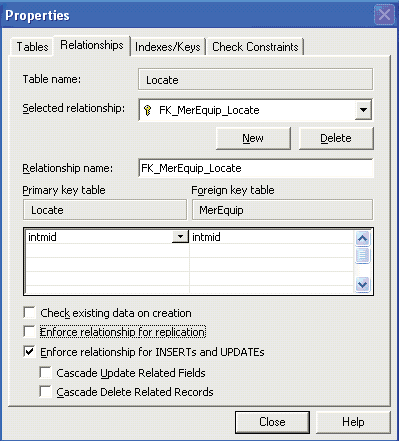
Чтобы избежать повторяющихся конфликтов во время репликации слиянием, я настроил все конструкции внешнего ключа и триггеры пользователя при помощи установки NOT FOR REPLICATION. Чтобы выполнить эту настройку, нужно выбрать таблицу из Enterprise Manager, щелкнуть правой кнопкой мыши и выбрать Design Table. Нажмите Manage Relationships, затем установите в исходное состояние Enforce relationship for replication в таблице Relationships окна Properties, как показано на Рисунке 1, повторите этот шаг для каждого внешнего ключа в "выпадающем" списке. Далее нажмите Close, затем Save. Щелкните Yes, когда появится окно подтверждения. Закройте окно Design Table и повторите эти шаги для всех таблиц, содержащих внешние ключи.
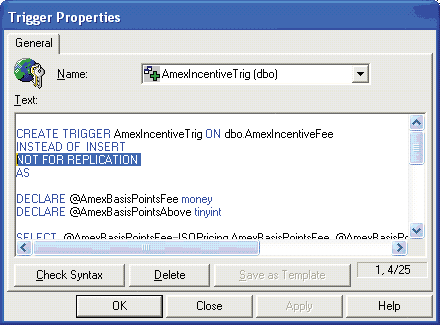
Чтобы изменить установку NOT FOR REPLICATION для имеющегося триггера, следует выбрать таблицу в Enterprise Manager. Щелкните правой кнопкой мыши, выберите All Tasks, затем выберите вкладку Manage Triggers. Из контекстного меню выберите определенный пользователем триггер. Как показано на Рисунке 2, наберите NOT FOR REPLICATION в строке, предшествующей AS в текстовом окне. Нажмите Apply, затем повторите эти шаги для других триггеров в той же таблице. В заключение нажмите OK. Затем поменяйте вариант NOT FOR REPLICATION для всех таблиц, имеющих триггеры.
Поля All IDENTITY должны иметь установку NOT FOR REPLICATION (этот вариант настраивается автоматически при установке репликации слиянием). Значения IDENTITY нужно разделить в соответствии с местонахождением. При настройке репликации слиянием для гарантии того, что значения идентификации задаются в пределах значений, предусмотренных для диапазона узла, SQL Server автоматически создает ограничивающее условие CHECK в каждой таблице, содержащей поле IDENTITY. При работе над решением клиента я тщательно планировал амплитуду значений столбца для каждой затронутой таблицы. Я рекомендую установить большой диапазон значений для узла, так чтобы невозможно было достичь предела. Из-за некоторых проблем с его функциональностью не стоит полагаться на диапазон автоматической идентификации, обрабатывая строку при помощи SQL Server. Разъяснить эти затруднения с идентификацией строки поможет статья Microsoft "BUG: Identity Range Not Adjusted on Publisher When Merge Agent Runs Continuously" на http://support.microsoft.com/?id=304706.
Я решил использовать алгоритм разрешения конфликта по умолчанию. Это самый простой вариант в подобном случае, с двумя серверами и редкими конфликтами. Выбор варианта по умолчанию был подходящим. Исполнение механизмов разрешения конфликтов в системе, зависящих от времени и даты, потребует модификаций в табличной структуре многих таблиц. В основном SQL Server позволяет выбрать из нескольких предписанных типов механизмов разрешения конфликтов в системе. Либо можно написать свой механизм разрешения конфликтов. В большинстве случаев, я уверен, читатели будут удовлетворены несколькими типами предписанного механизма разрешения конфликтов в системе.
Репликация слиянием специально добавляет уникальное поле-идентификатор для каждой тиражируемой таблицы. Общий размер строки для каждой тиражируемой таблицы (таблицы с дублированием), включая ту, которую я добавил, не должен превышать 6000 байт. Несколько таблиц имели больший размер строки, и изменение их структуры я обсудил с заказчиком.
SQL Server требует, чтобы все таблицы, соединенные взаимосвязями внешнего ключа, были опубликованы вместе в одной публикации. Перед настройкой репликации слиянием я разработал диаграмму базы данных для базы ClientDB в Enterprise Manager и распознал все такие случаи, так что я мог полностью видеть все взаимосвязи. Затем, чтобы облегчить настройку, я приготовил крупноформатную таблицу со списком запланированных публикаций и статей.
Разработка репликации слиянием
На Рисунке 3 показана схема репликации слиянием для моего заказчика. Я выбрал SQLServer1 на Site 1 как издателя и дистрибутора. А SQLServer2 на Site2 я определил как подписчика. ClientDB - это база данных, которая должна быть тиражирована. Агенты по снимкам и слиянию выполняют репликацию слиянием. Агент снимков подготавливает файлы-копии снимков, которые содержат схему и данные опубликованных таблиц, сохраняет файлы в папке моментальной копии, а затем вносит задания по синхронизации в базу публикаций. Агент снимка также создает специальные хранимые процедуры, триггеры и системные таблицы. Агент слияния объединяет изменения данных в виде приращений, которые происходят у издателя или подписчика после разработки начального моментального снимка, и это позволяет улаживать конфликты согласно установленным правилам.
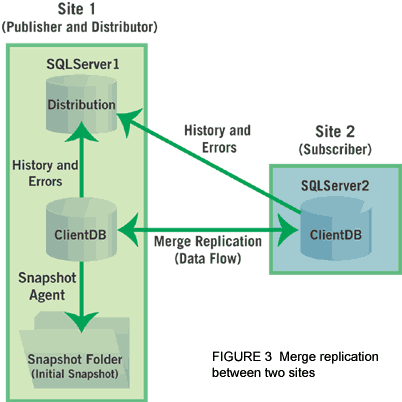
В репликации слиянием роль дистрибьютора ограничена, так что достаточно локально привести в исполнение дистрибьютора (на том же сервере, что и издатель), что я и сделал. Распространение базы от дистрибьютора сохраняет лишь архив и смешанные данные (т.е. ошибки) с обоих серверов, касающиеся репликации слиянием.
Настройка дистрибуции и публикации
Перед настройкой репликации слиянием удостоверьтесь, что на всех серверах достаточно дискового пространства. В дополнение к пространству для базы данных (ClientDB в этом случае) потребуется место для сохранения элементов, таких как база данных Distribution, файлы копии моментальных снимков и резервные файлы. Затем удостоверьтесь, что SQL Server в обоих местах работает под доменной учетной записью. Учетная запись должна иметь доступ к обоим серверам и к совместно используемому файловому ресурсу, который сохраняет файлы моментального снимка.
Легче всего установить дистрибьютора и настраивать издателя, используя Enterprise Manager. Оба сервера (издатель и подписчик) должны быть зарегистрированы в Enterprise Manager. В левом окне Enterprise Manager щелкните Databases для сервера, который надо настраивать как дистрибьютора (SQLServer1 в этом случае). На панели инструментов щелкните Tools, выберите Replication, затем выберите Рисунок Publishing, Subscribers , Distribution. Если репликация еще не настроена, появляется Replication Wizard. Нажмите Next, после чего появляется окно Select Distributor. Если репликация уже настроена, появится окно Publisher and Distributor Properties. Выберите Make SQLServer1 its own Distributor для создания собственного дистрибьютора, затем щелкните Next.
Если есть подозрение, что SQL Server Agent не выполняется, выберите Yes, Рисунок SQL Server Agent to start automatically, затем нажмите Next. Если SQL Server Agent работает, пропустите этот шаг настройки. В диалоговом окне Specify Snapshot Folder подтвердите выбор по умолчанию (или выберите свой вариант) для папки моментального снимка и щелкните Next. Если появляется сообщение и нужно подтвердить выбор папки, сделайте это.
Затем в окне Customize the Configuration (для настройки конфигурации) выберите Yes, let me для настройки свойств базы данных распределения, затем щелкните Next. Укажите место для данных и системного журнала для базы данных распределения. Затем нажмите Next. Если есть возможность, используйте разные накопители для данных и системных журналов. Я рекомендую для базы данных распределения сохранить имя по умолчанию.
В окне Enable Publishers выберите только требуемый сервер (SQLServer1). Закройте окно сообщения, если оно появляется. Если появится окно Publisher Properties, оставьте установку по умолчанию (использовать имеющееся соединение) и очистите вариант, требующий пароль для соединения издателя с дистрибьютором. Нажмите OK для выхода из окна и вернитесь в окно Enable Publishers. Если сообщение появляется, щелкните Yes для подтверждения, затем нажмите Next.
В окне Enable Publication Databases выберите Merge для базы данных (ClientDB в этом случае), затем щелкните Next. В окне Enable Subscribers выберите базу данных (SQLServer2 в этом случае), щелкните Next, затем нажмите Finish. Закройте окно, которое описывает функциональность Replication Monitor.
Подготовка исходной синхронизации данных (моментального снимка)
После настройки свойств внешнего ключа и триггера для решения моего заказчика я приготовился к разработке моментального снимка. Репликация слиянием требует получения начального снимка для всех тиражированных таблиц. Во время выполнения исходного снимка SQL Server добавляет триггеры объединения к каждой опубликованной таблице, добавляет поле уникального идентификатора к каждой таблице, которая его не имеет. SQL Server к тому же создает новый индекс по полю уникального идентификатора и другие системные таблицы.
Репликация слиянием добавляет поле уникального идентификатора со свойством ROWGUIDCOL и значением по умолчанию newid () к каждой опубликованной таблице и создает индекс по полю. Для больших таблиц процесс может быть длительным. Быстрее добавить новые поля к уже изданным большим таблицам, а затем выполнить начальный снимок для публикации с затронутыми таблицами (подробнее об этом рассказано в статье Microsoft "HOW TO: Manually Synchronize Replication Subscriptions by Using Backup or Restore" at http://support.microsoft.com/kb/320499/en-us).
В моем случае данные в базе данных ClientDB были непропорционально размещены между почти 200 таблицами, которые нужно было тиражировать. Большая часть (85 процентов) пространства базы данных была сконцентрирована в таблице BatchTrans, в которой было более 53 миллионов записей. Следующая самая большая таблица содержала около 5 миллионов строк.
В Таблице 1 показано, как данные распределены между таблицами в ClientDB. Для моего заказчика я написал пакет DTS, с помощью которого подготовил структурные изменения в семи самых больших таблицах ClientDB (каждая с числом строк более миллиона). Я запустил этот пакет только один раз. Даже если новые начальные снимки потребуются позже, выполнение модуля DTS необходимо, так как таблицы уже имеют необходимые столбцы с уникальным именем.
Настройка публикаций и создание начального моментального снимка
После настройки сервера-дистрибьютора и издателя пришло время создать начальный моментальный снимок. Чтобы повысить производительность агента снимков при работе с большими публикациями (или публикациями, имеющими большие таблицы), я рекомендую создать новый профиль для этого агента и использовать его вместо профиля по умолчанию. На рисунке 4 показан процесс создания нового профиля агента снимков.
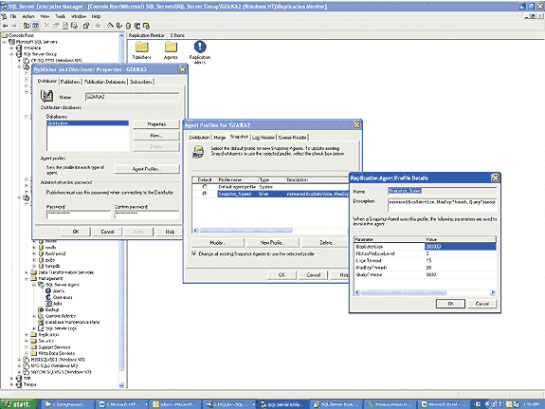
В Enterprise Manger выберите Replication на сервере издателя (дистрибутора), затем щелкните правой кнопкой мыши и выберите Рисунок Publishing, Subscribers, Distribution. На таблице Distributor нажмите Agent Profiles, выберите таблицу Snapshot. В окне Replication Agent Profile Details введите значения, которые показаны в Таблице 2 (настройте эти значения для имеющихся условий, как я сделал здесь; я проверил эти изменения в среде разработки заказчика и выбрал комбинацию, которая дала мне оптимальное время). Когда значения нужным образом изменены, нажмите OK. Затем в окне Agent Profiles выберите профиль Snapshot_Speed и сделайте его профилем по умолчанию, выбирая Change all existing Snapshot Agents для указания варианта выбранного профиля. Нажмите OK два раза, чтобы закончить настройку.
С этого места я был готов настраивать публикации. Я решил создать 12 публикаций: 4 различные публикации, в которых собраны группы родственных таблиц и 8 других, в которых собраны несвязанные таблицы, основанные на бизнес-функциях, частоте изменений, размере и других факторах. Используя несколько публикаций, можно настраивать каждый агент слияния для самостоятельного выполнения, по его собственному плану, используя различные подпроцессы, ускоряющие процесс дублирования. Если нужно уравновесить число агентов, работающих при помощи доступных средств, прочтите врезку "Шаги по настройке публикаций", где представлен процесс для настройки каждой созданной публикации.
После создания моментальных снимков для всех публикаций я сделал резервную копию базы данных ClientDB на сервере-издателе, затем копировал резервные файлы на сервер-подписчик и восстановил там базу данных.
Создание нового профиля агента слияния и настройка подписки
Для увеличения производительности агента слияния и минимизации эффекта, когда SQL Server обрабатывает записи потомка и родителя, я решил создать новый профиль для агента слияния (о возможных проблемах рассказано в статье компании Microsoft "PRB: Non-Convergence When SQL Server Processes Child and Parent Generations in Separate Generation Batches" at http://support.microsoft.com/default.aspx?scid=kb;en-us;308266). Для создания нового профиля агента слияния начните с Enterprise Manager и выберите узел Replication на сервере-дистрибьюторе. Затем щелкните правой кнопкой мыши и выберите ConРисунок Publishing, затем Subscribers, затем Distribution. На закладке Distributor щелкните Agent Profiles, и на таблице Merge нажмите New Profile.
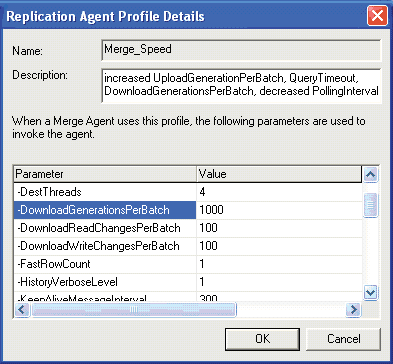
Как показано на Рисунке 5, введите значения в окне Replication Agent Profile Details, которые показаны в Таблице 3, затем нажмите OK и подтвердите изменения, если появляется сообщение. В окне Agent Profiles выберите профиль Merge_Speed и сделайте его профилем по умолчанию, выбирая Change all existing Snapshot Agents to use the selected profile для всех существующих агентов моментального снимка, для исполнения выбранного профиля. Нажмите OK два раза для завершения настройки.
Затем я настроил подписчиков на электронные публикации. Зайдите в Enterprise Manager, выберите узел Replication сервера-пользователя, выберите Publications, щелкните правой кнопкой мыши на публикации и выберите Push New Subscription. Щелкните Next, и в секции Enabled Subscribers окна Choose Subscribers выберите сервер-пользователя (SQLServer2 в данном случае) и щелкните Next. В окне Set Merge Agent Schedule выберите Continuously (важно отметить, что это не вариант по умолчанию) и нажмите Next.
Когда появится окно Initialize Subscription, для задания начальных условий подписки выберите No, the Subscriber already has the schema and data (снова это не вариант по умолчанию) и щелкните Next. Не нужно выбирать этот вариант, так как копия базы данных на целевом сервере уже восстановлена. На экране Set Subscription Priority для установления приоритета подписчика выберите Use the Publisher as a proxy, затем нажмите Next. После этого в окне Start Required Services примите все установки и нажмите Next. Щелкните Finish, чтобы закрыть окно мастера, затем нажмите Close. В правой панели Enterprise Manager вы увидите новую строку с заново настроенными данными подписки. Повторите эти шаги для всех публикаций.
Проверьте репликацию слиянием перед началом работы
Перед использованием репликации слиянием в промышленных условиях я рекомендую проверить ее выполнение на подобном оборудовании с ожидаемой загрузкой данных. Я допускаю, что в некоторых случаях репликация слиянием может не удовлетворять требованиям бизнеса. Особенно это справедливо в случае массивных загрузок данных. В этой ситуации можно подумать о транзакционной репликации или другом сценарии передачи данных. Мне известен один случай, когда репликация слиянием замедлила загрузку данных на одном из серверов вдвое.
Для баз данных малого и среднего размера, которые имеют равномерное распределение и не очень большой рабочий объем (как я описал ранее), репликация слиянием будет работать хорошо. Данные пользователя, журнал регистрации, файлы TempDB и Distribution должны быть размещены на разных накопителях. За дополнительным объяснением обратитесь к статье компании Microsoft "SQL Server 2000 Merge Replication Performance Tuning and Optimization" at http://www.microsoft.com/technet/prodtechnol/sql/2000/maintain/mergperf.mspx.
Это исполнение репликации слиянием удовлетворило требования моего заказчика. Данное решение поддерживает одновременный ввод данных на разные серверы (включая модификацию текстовых полей) и не требует специального дробления данных. Оно позволяет избежать многих конфликтов на уровне строки за счет объединения изменений в различных полях в одну запись. Кроме того, это решение облегчает работу при увеличении числа пользователей. Оно не требует глубоких знаний в области написания сценариев и может поддерживаться даже не слишком опытным администратором баз данных, желающим изучить новую технологию. Репликация слиянием является удачным выбором для разрешения ситуаций, похожих на ту, которая была описана выше.
Последовательность действий при настройке публикаций
Для настройки каждой публикации начните с Enterprise Manager на сервере-издателе (в этом случае SQLServer1) и выполните следующие шаги:
- Выберите Replication, Publications. Щелкните правой кнопкой мыши и выберите New Publication.
- Появляется мастер Create Publication. Нажмите Next.
- В окне Choose Publication Database выберите базу данных (ClientDB в этом случае), затем нажмите Next
- Если появляется окно Use Publication Template, выберите No, I will define the articles and properties, затем нажмите Next. В окне Select Publication Type выберите Merge publication, нажмите Next
- В окне Specify Subscriber Types выберите только Servers running SQL Server 2000, нажмите Next.
- В окне Specify Articles убедитесь, что в столбце Show на левой панели выбран только вариант Tables и проверьте, выбран ли вариант Show unpublished objects.
- На правой панели выберите таблицы, которые нужно дублировать.
- Если таблица содержит поле IDENTITY, как показано на Рисунке А, нажмите (...) рядом с полем и укажите закладку Identity Range. Затем выберите Automatically assign and maintain a unique identity range for each subscription.
- Введите достаточно большие значения в текстовые окна Range Size at Publisher и Range Size at Subscriber. Например, на основе предполагаемого увеличения количества данных таблицы, содержащей около 1,500,000 миллионов строк я ввел здесь 10,000,000.
- В текстовом окне Assign a new range when the percentage of values is used напечатайте 99, затем нажмите OK.
- После того как выбраны все статьи и модифицированы все свойства, нажмите Next.
- Если появляется окно Article Issues, убедитесь в том, что получен только один результат, uniqueidentifier columns will be added to tables. Если результат связан с полем IDENTITY одной или большего количества таблиц, вернитесь в предыдущее окно и внесите изменения в свойства статьи, как было описано выше. Если в таблице только один результат, просмотрите описание в окне Article Issues, затем нажмите Next.
- В окне Select Publication Name and Description напечатайте название публикации. После этого изменить присвоенное название публикации уже будет нельзя. Введите понятное описание публикации, затем нажмите Next
- В окне Customize the Properties of the Publication, выберите Yes, I will define data filters, нажмите Next
- В окне Filter Data (ничего не выбирая) щелкните Next. Здесь можно ввести критерий для фильтрации строк.
- В окне Allow Anonymous Subscriptions выберите No, allow only named subscriptions, затем нажмите Next.
- В окне Set Snapshot Agent Schedule примите варианты по умолчанию. Убедитесь в том, что выбран вариант Create the first snapshot immediately, затем нажмите Next. Или можно назначить выполнение агента снимков в более удобное позднее время.
- В окне Completing the Create Publication, нажмите Finish и закройте те сообщения, которые появляются.
- В правой панели Enterprise Manager следите за развитием Replication Monitor, Agents и Snapshot Agents в процессе генерации моментального снимка.
- Повторите шаги 1-20 для всех публикаций.
Таблица 1. Распределение данных в базе ClientDB
| Число строк | Число таблиц в ClientDB |
| > 1,000,000 | 7 |
| 100,000-1,000,000 | 7 |
| 10,000-99,999 | 32 |
| 1000-9999 | 22 |
| < 1000 | 130 |
Таблица 2. Измененные значения для экрана деталей профиля агента репликации
| Параметр | Измененное значение |
| Имя | Snapshot_Speed |
| Описание | Повышенные BcpBatchSize, MaxBcpThreads, QueryTimeout |
| BcpBatchSize | 200,000 (от 100,000) |
| MaxBcpThreads | 20 (от 1) |
| QueryTimeout | 5000 (от 300) |
Таблица 3. Значения параметров профиля агента репликации
| Параметр | Предлагаемое значение |
| Имя | Merge_Speed (или другое понятное имя) |
| Описание | Повышенные UploadGenerationPerBatch, QueryTimeout, DownloadGenerationsPerBatch, уменьшенные PollingInterval |
| UploadGenerationPerBatch | 1000 (от 100) |
| DownloadGenerationsPerBatch | 1000 (от 100) |
| QueryTimeout | 3000 (от 300) |
| PollingInterval | 10 (от 60) |