

Средство для гибкого использования таблиц в приложениях
Несколько лет назад, когда мы создавали приложение для одного заказчика, при разработке схемы базы данных перед нами встала традиционная проблема: иерархические структуры данных. 40% наших типов данных были иерархическими (например, структура товаров, заказчики, географические регионы, структура организации продаж, система папок). Из-за иерархических структур данных мы испытывали «табличный синдром»: нам требовалось столько таблиц, что все они не умещались на листе. Нужно было изобрести один шаблон для иерархических таблиц и пользоваться им по всему приложению. Этот шаблон позволил не только уменьшить количество таблиц и тем самым сделать приложение менее сложным, но и повысить его гибкость. Предлагаем читателям применять наш метод для упрощения структуры базы данных в приложениях на базе SQL Server.
|
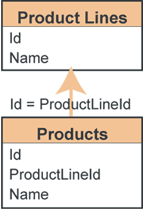
| Рисунок 1. Двухуровневая схема базы данных |
|
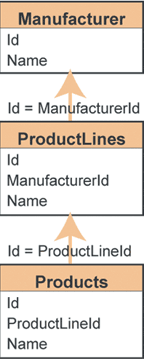
| Рисунок 2. Модифицированная трехуровневая схема базы данных |
Вечно меняющиеся потребности
Задумаемся о хранении товаров и товарных линеек в реляционной базе данных. Обычно здесь используется двухслойная иерархия таблиц наподобие той, что изображена на рис. 1. Предположим, что нас попросили изменить базу данных так, чтобы продавцы могли вносить сведения о товарах конкурентов наряду с информацией о товарах самой компании.
Чтобы выполнить это пожелание, мы изменим схему базы данных так, что она станет похожа на схему, приведенную на рис. 2. Вскоре после внесения этого изменения руководство попросит добавить уровень брэнда Brand между уровнями производителя Manufacturer и линии товаров ProductLines, чтобы можно было следить за тем, как обстоят дела у каждого из брэндов. Что мы в итоге получим? Таблицы расползаются!
Проблема данного метода заключается в том, что он недостаточно гибкий: трудно адаптировать базу данных к изменяющимся потребностям. Преимущество нашего метода состоит в том, что он позволяет группировать сходные типы данных на одном уровне иерархии.
|
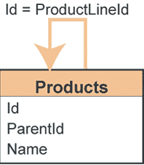
| Рисунок 3. Хранение иерархических данных в таблице со ссылками на саму себя |
Более гибкий метод предполагает хранение иерархических данных в таблице со ссылками на саму себя, как показано на рис. 3. Теперь можно в любое время добавлять новые уровни иерархии. Фактически в такой структуре можно хранить данные любой «глубины». Загвоздка этого метода в том, что выборка записей одного уровня оказывается довольно громоздкой. К примеру, чтобы выбрать все записи уровня товаров Products, нам придется выбрать все записи самого верхнего уровня (производителя Manufacturer), выбрать их потомков (уровень линеек товаров ProductLines) и выбрать потомков предыдущей таблицы (уровень товаров Products). Как определить, относится данная запись к таблице товаров Products или к таблице позиций товаров ProductLines? Трудоемкое дело, не так ли? Однако нам удалось найти более эффективный метод управления огромным количеством таблиц.
Идея получше
|
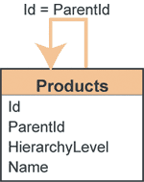
| Рисунок 4. Структура таблицы, которая идентифицирует уровень таблицы в иерархии |
Наша идея комбинирует простоту использования первого метода с гибкостью второго. Мы просто храним уровень узла (т. е. его расстояние от корня) в каждой записи. Такой подход позволяет без труда выбрать все записи одного уровня (товаров Products или товарных линеек ProductLines) и при этом поддерживать гибкость применительно к глубине иерархии. Этот тип структуры показан на рис. 4.
Если имеется иерархия производитель — линейка товаров — товары, то выборка всех товаров, к примеру, производится следующим оператором:
SELECT * FROM Products WHERE HierarchyLevel = 3
Если требуется создать представления (для производителей, товарных линеек и товаров), которые извлекали бы все записи соответствующего уровня, то можно воспроизвести поведение исходной версии с тремя таблицами.
Чтобы этот метод работал, придется постоянно обновлять столбец уровня иерархии HierarchyLevel. При вставке каждой новой записи надо задавать для нее значение HierarchyLevel, базируясь на ее родителе. Однако мы придерживаемся другого подхода. В нашем случае таблица товаров Products наполнялась с помощью довольно сложной пакетной процедуры импорта, поэтому нам не хотелось портить ее обновлениями. Кроме того, таблица была небольшой, так что мы обновляли столбец HierarchyLevel по завершении импорта. Делалось это следующим образом.
Предположим, что мы создали таблицу Products с использованием приведенного ниже оператора (для простоты опустим ограничения целостности):
CREATE TABLE Products( Id int identity(1,1), ParentId int, HierarchyLevel tinyint, Name nvarchar(50) )
Поскольку мы не можем предположить, какой будет глубина иерархии, обновление HierarchyLevel должно выполняться рекурсивно. SQL Server 2000 не очень хорошо справляется с рекурсиями, поэтому реализуем обновление HierarchyLevel в виде итерации, как показано в коде листинга 1. SQL Server 2005 поддерживает рекурсивные запросы; мы приведем примеры с применением рекурсии.
В коде листинга 1 сначала для всех записей значение HierarchyLevel устанавливается равным null, затем задается значение 1 для столбца HierarchyLevel для всех строк самого верхнего уровня (тех, у которых нет родителя). После этого код устанавливает значение 2 для уровня иерархии непосредственных потомков записей самого верхнего уровня и т. д. И опять значения столбца HierarchyLevel помогают отслеживать, что происходит: для строк, чей уровень уже задан, сведения об уровне стали доступными. Мы всегда можем отфильтровать записи с низшим известным уровнем путем выборки тех записей, чей уровень иерархии равен значению, хранящемуся в переменной @CurrentHierarchyLevel. Затем код увеличивает переменную @CurrentHierarchyLevel и обновляет следующее множество строк. Итерации заканчиваются, когда больше нет записей, которые надо обновлять.
Данный шаблон можно применять к каждой из иерархических таблиц. Это даст два основных преимущества.
- Программисту легко запомнить порядок использования таблиц.
- Можно реализовать обновление столбца HierarchyLevel один раз в виде хранимой процедуры.
Код в листинге 2 показывает хранимую процедуру для обновления столбца HierarchyLevel, который работает с любой таблицей. В качестве параметров хранимой процедуры задаются имя таблицы и идентификатор столбца. Можно задать дополнительные параметры, чтобы получить имена других полей.
Применение рекурсивных запросов SQL Server 2005
SQL Server 2005 поддерживает рекурсивные запросы с помощью общих табличных выражений (Common Table Expressions, CTE). В коде листинга 3 использован запрос CTE для обращения к иерархической таблице. В коде листинга 4 выражения CTE применяются для обновления исходной таблицы.
В листингах 1 и 4 использованы разные методы для выполнения одного и того же действия: обновления записей иерархической таблицы. Мы вскоре сравним их более наглядно, но сначала посмотрим на листинг 3 и разберем, как надо структурировать рекурсивный запрос SQL Server 2005. Оператор SELECT в конце сценария обманчиво прост из-за того, что использует CTE. Первая часть CTE описывает «якорь»: первоначальное множество записей, с которого начинается рекурсия. Эта часть исполняется только один раз. Вторая, рекурсивная часть CTE ссылается непосредственно на CTE, выполняя соединение таблицы заказчиков Customers table с HCustomersCTE. У нас уже имеются записи в результирующем наборе CTE за один круг рекурсии. В следующем круге мы добавляем их потомков. За кулисами SQL Server действует точно так же, как в листинге 1: он продолжает итерации с CTE до тех пор, пока происходит добавление новых записей.
Теперь рассмотрим листинг 4. Здесь мы реализуем те же действия по обновлению, что и в листинге 1, но на этот раз применяем рекурсивный запрос. Отметим соответствующие части в обоих сценариях: определение якоря и шаги итерации/рекурсии. Все они являются простыми операторами SELECT. Однако оператор UPDATE сложнее, чем SELECT из листинга 3. В сущности, CTE представляет собой рекурсивный оператор SELECT, который предоставляет значения столбца HierarchyLevel для каждой записи таблицы Customers, а затем соединяет CTE с исходной таблицей Customers. Обновление происходит вне рекурсивной части кода.
Подсказки и приемы
Если таблица включает описываемые несколькими полями отношения «родители-потомки», можно слегка модифицировать хранимую процедуру листинга 2, чтобы адаптировать ее к ситуации, если только все имеющиеся таблицы пользуются одинаковым числом полей для описания этого отношения. Если же в таблицах используется разное число полей для описания отношения «родители-потомки», то придется применять процедуру обновления к таблицам по очереди.
Лучше всего иметь в иерархической таблице поле идентификатора. По сути, мы использовали поле идентификатора во всех наших таблицах, на которые могли ссылаться другие таблицы. Это значительно упрощает написание запроса. Кроме того, если когда-нибудь надо будет передать эти таблицы в OLAP и они станут измерениями, службы аналитики SQL Server легко превратят этот тип иерархии в отношение «родители-потомки».
Данный шаблон иерархической таблицы можно применять для решения таких вопросов, как несбалансированные табличные иерархии, двусмысленные уровни и необходимость хранить различные атрибуты на разных уровнях иерархии. Из трех описанных ранее структур таблиц только наш шаблон иерархии позволяет справиться с несбалансированными иерархиями, потому что в этом случае невозможно создать отдельные таблицы для хранения конкретных уровней.
Несбалансированные иерархии. Предположим, у нас имеется таблица Positions, описывающая структуру организации. Иерархия таблицы Positions включает генерального директора, директоров, управляющих и секретарей. Как показано на рис. 5, иерархия Positions является несбалансированной, поскольку секретари отчитываются разным уровням. Либо надо поместить секретарей на один уровень, и тогда придется «перескакивать» уровни, либо, как показано на рис. 6, придется размещать секретарей на разных уровнях, что меняет иерархию.
В данном примере уровень секретарей Secretaries фактически лежит вне нашей иерархии. Никогда не понадобится ни назначать секретарям, например, показатели продаж, ни включать их в расчеты при вычислении величин продаж. Поскольку секретари не являются частью иерархии организации в таблице Positions, секретарей необходимо представить отдельным атрибутом, иначе уровни иерархии будут нереализуемыми.
Двусмысленные уровни. Что происходит, когда приходится создавать новый уровень иерархии между двумя существующими уровнями? Скажем, уровень брэнда Brand обычно располагается между линейками товаров ProductLines и товарами Products, однако в некоторых случаях он должен размещаться поверх линеек товаров Product Lines. В этом случае, как в примере с таблицей Positions, уровень Brand находится вне иерархии, так что его следует хранить в виде отдельного атрибута.
Различные атрибуты на разных уровнях. Возможно, вам придется хранить различные атрибуты на разных уровнях иерархии. К примеру, у заказчика может быть атрибут налогового идентификатора Tax Identifier на уровне компании, однако на уровне магазина этот атрибут не нужен. Хранение различных атрибутов на разных уровнях легко осуществить, если имеются две разные таблицы. Но если используется только одна таблица, приходится хранить объединение всех атрибутов, поэтому появится атрибут, который на уровне магазина всегда будет пустым. В конце концов, это вопрос проектирования: зачастую важно именно сходство (выраженное количеством совпадающих столбцов), так что имеет смысл объединить разные таблицы в одну. Если это не так, то лучше решиться и создать разные таблицы. Здесь приходится жертвовать либо памятью ради гибкости, либо наоборот.
Гибкий подход
Итак, мы продемонстрировали преимущества своего иерархического шаблона, которые сделали его весьма и весьма удобным средством работы с базами данных. Разумеется, у этого подхода имеется и оборотная сторона — необходимость хранить объединение атрибутов каждого уровня иерархии. Читателям придется самим решать, когда создавать такой тип структуры, а когда нет. Когда начинаешь использовать этот прием, очень скоро становится очевидно, что он оттачивает навыки проектирования, поскольку заставляет переосмыслить структуру таблиц.
Балинт Наги - Ведущий консультант Microsoft Services в Венгрии. Имеет сертификат Windows 2000 MCSE и звания SQL Server и Solution Architecture MCP. balintn@microsoft.com
Ласло Пуштай - Старший консультант Microsoft Services в Венгрии. Имеет сертификаты Windows 2000 MCSD и MCSE. laszlop@microsoft.com