


Что такое катастрофа с точки зрения планирования восстановления после сбоя? Ответ кажется очевидным, но можно столкнуться с серьезными трудностями, пытаясь определить все, что входит в понятие катастрофы. Легко определить понятие «стихийное бедствие» на примере землетрясений, пожаров и наводнений, но сбой может быть вызван и необычными причинами. Мне, жителю Вашингтона, приходилось встречать десятки людей, деловая активность которых в последние два года прерывалась карантинами и эвакуациями из-за угрозы террористических актов, применения биологического оружия и действий криминального характера. Очевидно, подобного рода обстоятельства большинством ИT-администраторов при подготовке к восстановлению после сбоя, по всей вероятности, учитываться не будут.
После разговоров с людьми, которые непосредственно сталкивались с этими ситуациями, я сформулировал для себя следующее определение катастрофы: катастрофа — это любое событие, лишающее пользователей их деловых данных на неприемлемо длительное время (иногда навсегда) и в результате подвергающее риску жизнеспособность организации. Не стану спорить, что мое определение, возможно, слишком широкое — даже такая простая ситуация, как неисправность жесткого диска, может под него подойти. Однако в зависимости от количества и типа затронутых таким образом данных и вероятности восстановления необходимой информации в приемлемое время (если это вообще возможно) некоторые организации вполне могли бы рассматривать выход из строя жесткого диска как катастрофу. Для того чтобы разработать оптимальные решения, обеспечивающие восстановление после сбоя, следует относиться к планированию восстановления как к способу минимизации времени, в течение которого пользователи отделены от нужных данных, независимо от обстоятельств. Рассмотрим пример ситуации глобального сбоя и попробуем установить, какую роль может сыграть служба распределенного хранения файлов Microsoft Dfs в планировании восстановления и минимизации времени, которое придется потратить на подключение пользователей к определенным типам данных.
Готовность к сбою
Представим себе, что нам предстоит разработать план восстановления после сбоя, который мог бы использоваться в случае катастрофы. Наша компания имеет офисы в Нью-Йорке и Лондоне, а инфраструктура, связывающая эти точки, состоит из серверов, настольных систем, маршрутизаторов и концентраторов. Эта инфраструктура является основой для работы нескольких приложений, в том числе приложения общего пользования (email), вертикального бизнес-приложения (LOB), приложения планирования ресурсов предприятия (ERP), приложения для базы данных и файлового хранилища. Предположим, что за последнюю декаду террористы выбрали своей целью оба офиса и что начальник готовит нас к худшему — полной потере одного из офисов на неопределенное время.
Понятно, что план восстановления после сбоя должен быть всесторонним и охватывать много областей, чтобы обеспечить непрерывность работы компании при такой катастрофе. Один из самых важных вопросов, который следует рассмотреть, это вопрос о том, как быстро сделать доступными данные в пострадавшем офисе для персонала в оставшемся офисе. Передача информации персоналу в уцелевшем офисе позволит поддерживать связь с потребителями и продолжать вести бизнес, пока не будет восстановлен пострадавший офис.
Данные, используемые в организациях, обычно состоят из файлов документов, баз данных и хранилищ файлов пользовательских приложений. С помощью Dfs данные первой категории (файлы документов) можно сделать
доступными во время сбоя. Если выполнить небольшое по объему, но тщательное планирование, с минимальными последующими усилиями Windows 2000 сможет хранить данные в нескольких местах и обеспечит поддержку самых последних версий данных.
Краткий обзор Dfs
Dfs — сердцевина Windows 2000, чье название, однако, обманчиво: она не является по-настоящему файловой системой, как NTFS или FAT, а также средством организации хранения данных на магнитном или оптическом носителе. Dfs скорее представляет собой механизм, позволяющий упорядочить представление данных совместного использования и дополнительно механизм хранения реплицированных копий в нескольких местах.
Попросту говоря, Dfs позволяет строить виртуальные структуры из файлов совместного доступа в сети и привязывать эти ресурсы к физическим файловым ресурсам, находящимся, возможно, на многих серверах. Конечные пользователи могут подключаться к этим виртуальным файловым ресурсам так, как будто они подключаются к физическим. Когда пользователи обращаются к этим виртуальным файловым ресурсам, Dfs перенаправляет их к копии данных, расположение которой непосредственно доступно пользователю, или к одной из нескольких реплицированных копий, доступных по сети.
Такая функциональность обеспечивается работой службы File Replication Service (FRS). FRS встроена в Window 2000 и не требует никакой настройки (Dfs — единственный из рассматриваемых компонентов, который следует настраивать). Разберем пример конфигурации Dfs, пригодной для целей восстановления после сбоя.
Планирование репликации
Предположим, что у нас имеется по нескольку серверов в обоих офисах — в Лондоне и в Нью-Йорке — и решено реплицировать файлы данных совместного использования (например, документы, таблицы, презентации Microsoft PowerPoint, маркетинговые материалы) из одного офиса в другой. Эти данные разбросаны по нескольким серверам на каждом сайте, и требуется создать резервную копию данных лондонского офиса на одном сервере в Нью-Йорке и наоборот.
Для начала следует оценить необходимое количество дискового пространства. Если имеется примерно 50 Гбайт документов и файлов в каждом офисе, следует обеспечить наличие еще 50 Гбайт свободного дискового пространства в каждом офисе, для того чтобы хранить реплицированные данные.
Затем следует оценить пропускную способность, необходимую для поддержки репликации между узлами. Например, если связь между офисами осуществляется по каналу T1, это означает, что имеется полоса пропускания в 1,5 Мбит/с для передачи данных из одного узла в другой. Необходимо определить, какая часть этой полосы пропускания используется в процессе обычной связи между узлами, — скорее всего, эту информацию смогут предоставить провайдеры WAN. Если данная информация в готовом виде недоступна, можно задействовать инструмент извлечения данных по протоколу SNMP, такой как Multi Router Traffic Grapher (MRTG), чтобы проследить за использованием полосы пропускания. Какой бы способ ни был выбран, следует вычесть используемое количество полосы пропускания из общего доступного количества. В нашем примере будем считать, что половина полосы пропускания между нью-йоркским и лондонским офисами уже используется, в результате чего остается свободной часть полосы в 750 Мбит/с.
Наконец, следует выяснить, как много пользовательских данных в каждом офисе меняется в течение дня. Dfs реплицирует изменения на файловом уровне, поэтому каждый раз, когда кто-нибудь вносит изменения в подлежащую репликации презентацию PowerPoint размером 20 Мбайт, Dfs будет пересылать целиком файл 20 Мбайт через WAN, и это будет частью процесса репликации. Очевидно, репликация данных подобным образом может сильно нагрузить сеть.
Существует несколько методов, позволяющих определить, сколько данных меняется в течение дня в организации, — я, например, использую функцию расширенного поиска в Windows, чтобы установить местоположение всех файлов, которые были изменены за последний день. Необходимо запустить этот поиск в папках, которые требуется реплицировать, затем узнать суммарный объем всех найденных файлов. Некоторые файлы будут меняться несколько раз в день, поэтому, возможно, придется увеличить полученную цифру, используя для некоторых из этих файлов множитель, учитывающий число репликаций.
После того как мы узнаем, сколько данных (в байтах) меняется пользователями в течение дня, нужно умножить это количество на 8, чтобы выразить полученное число в битах. Предположим, например, что наша вымышленная организация на протяжении одного дня модифицирует 200 Мбайт данных. Если умножить 200 Мбайт на 8, то получится, что необходимо реплицировать 1,6 млрд. бит данных. Разделим это число на общее количество доступной полосы пропускания и найдем число секунд, которое займет трафик репликации Dfs в сети на данный день (в нашем примере это 2133 секунды в день). Учитывая, что день состоит из 86 400 секунд, по-видимому, можно считать, что при вычисленном времени Dfs-репликации вполне целесообразно отправлять данные по каналу T1, даже если несколько узлов обновляются в одно и то же время (модель репликации FRS имеет несколько основных реплик и может обрабатывать несколько узлов одновременно).
Можно повысить качество расчетов, используя интервал менее 24 часов для определения количества данных, меняющихся за день, и количества секунд, составляющих этот промежуток времени. Еще нужно помнить, что мы не берем в расчет передачу служебных данных — заголовков пакетов, которые могут существенно увеличивать общее количество передаваемых данных, обычно 56 байт на пакет. Поскольку трафик репликации Dfs между двумя городами будет наиболее заметен в часы максимальной деловой активности, можно считать, что рабочий день, охватывающий нью-йоркский и лондонский офисы, длится 13 часов (обычный 8-часовой день плюс 5-часовая разница). Теперь, когда есть свободное дисковое пространство и полоса пропускания, предназначенные для репликации, следует перейти к планированию и реализации плана.
Проект репликации Dfs
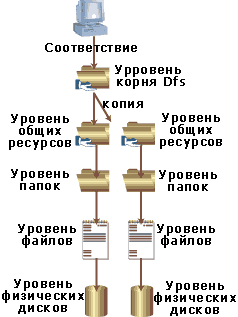
|
| Рисунок 1. Копия общего ресурса на уровне корня Dfs |
В стандартной установке Windows 2000 без Dfs операционная система обычно хранит пользовательские файлы в папках на сервере, и эти папки являются папками общего доступа для конечных пользователей. Для того чтобы работать с файлами в папках общего доступа, конечные пользователи подключаются к этим сетевым ресурсам или непосредственно, или с помощью назначения букв для сетевых дисков. Подключение к сетевым ресурсам упрощает поиск данных в сети для конечных пользователей и состоит из четырех функциональных уровней, начиная с уровня пользователя и его ресурса, затем идет уровень папки, уровень файла и, наконец, уровень физического диска. В зависимости от того, как планируется проектировать инфраструктуру Dfs, возможно, понадобится один или два дополнительных уровня — обязательный уровень корня Dfs (рис. 1) и необязательный уровень связей Dfs (рис. 2).
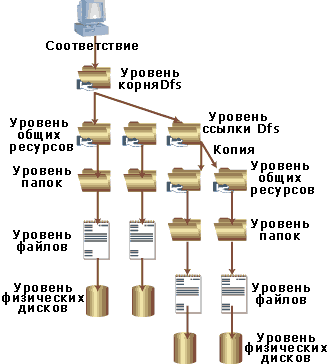
|
| Рисунок 2. Копия общего ресурса на уровне ссылки Dfs |
Корневой уровень Dfs подобен корню жесткого диска — у каждого диска должен быть корень, и структура Dfs не исключение. Когда создается структура Dfs, следует выделить один или несколько ресурсов сети, которые будут выступать в роли корня Dfs. Чтобы иметь некоторый запас, можно создать корневые ресурсы на нескольких серверах в рамках одной структуры Dfs. Рассмотрим процесс реализации корневой структуры Dfs, используя тестовую лабораторию в домене Active Directory (AD) netarchitect.local, с репликацией данных между двумя серверами: ARCHITECT10 и DMZSERVER.
Конфигурация корня Dfs
В Windows 2000 процесс создания корня Dfs начинается с запуска оснастки Microsoft Management Console (MMC) Distributed File System через Start, Programs, Administrative Tools. Следует щелкнуть правой кнопкой по Distributed File System в правой панели оснастки, затем выбрать New Dfs Root, чтобы запустить мастер конфигурации. Для начала нужно решить, какой корень Dfs требуется создать: доменный или одиночный. Поскольку мы определяем корень Dfs для поддержки репликации между узлами, нам необходим доменный корень Dfs.
Затем следует решить, в каком домене AD нужно разместить создаваемый корень Dfs. Требуется выбрать домен, который больше подходит для конкретной ситуации, как показано на рис. 3. Доменное имя, выбираемое нами на данном шаге, — это то имя, которое конечные пользователи будут применять для подключения к корневой структуре Dfs. Например, когда пользователи захотят подключиться к корню Dfs в нашем случае, они будут обращаться к etarchitect.localDfs root name, а не подключаться непосредственно к какому-либо серверу.
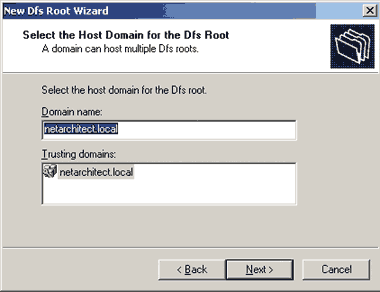
|
| Экран 1. Выбор домена для корня Dfs |
После выбора домена следует определить главный сервер для корня Dfs, затем выбрать общий ресурс, который будет использоваться в дальнейшем. Если ресурс не был создан в самом начале, можно сделать это позже. Ресурс должен быть привязан к папке на диске NTFS, поскольку FRS использует систему протоколирования NTFS 5.0 (NTFS 5) для отслеживания момента изменения файла. Для нашего примера я создал ресурс с именем netarchitect-dfsroot на сервере ARCHITECT10. Можно задействовать любое имя, но использование описательных имен для ресурсов упрощает работу с папками, ресурсами и репликами, когда их много.
Заключительный шаг в конфигурации корня Dfs — присвоение ему имени (рис. 4). Подобно имени домена, пользователи будут задействовать это имя корня Dfs, чтобы подключиться к структуре Dfs. Именно поэтому я предпочитаю использовать имя, описывающее функцию ресурса (например, ReplicatedFiles — реплицируемые файлы, SyncFiles — синхронизируемые файлы).
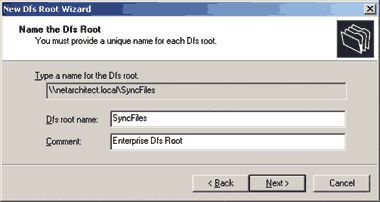
|
| Экран 2. Задание имени для корня Dfs |
По завершении этого шага следует протестировать новый корень Dfs с какой-нибудь рабочей станции, подключаясь к UNC-имени domainnameDfsrootname, которое было определено в процессе создания корня Dfs (например, etarchitect.localSyncFiles). Рабочая станция извлечет данные о Dfs из AD, а затем найдет лежащие ниже корня общие ресурсы.
Добавление избыточности в Dfs
На данном этапе у нас есть структура корня Dfs, но корень не продублирован. Поэтому следующий шаг — создание реплики корня Dfs нажатием правой кнопки мыши Distributed File System в левой панели оснастки Distributed File System. Необходимо выбрать в контекстном меню пункт New Root Replica, чтобы запустить мастер Dfs Root Wizard. Сначала следует выбрать компьютер, который планируется назначить главным компьютером для копии корня Dfs, в нашем примере это DMZSERVER. Затем нужно выбрать общий ресурс, который был определен перед запуском мастера; в нашем примере это netarchitect-dfsroot.
После того как указан общий ресурс для корня Dfs на втором сервере, следует выполнить настройку репликации между обоими ресурсами. По умолчанию Dfs не настраивает репликацию данных автоматически, поэтому ее придется включить. Нужно щелкнуть правой кнопкой по созданному корню Dfs, затем выбрать Replication Policy из контекстного меню, чтобы открыть диалоговое окно Replication Policy, показанное на рис. 5. Следует щелкнуть Enable, чтобы включить репликацию для каждого ресурса, а затем определить, какой ресурс будет главным во время первой репликации. Выберите Set Master для этого ресурса. После выполнения перечисленных шагов Windows 2000 будет реплицировать данные между этими ресурсами и содержать их синхронизированными. Как только произойдет первоначальная репликация, разница между первичным ресурсом и другими ресурсами исчезнет.
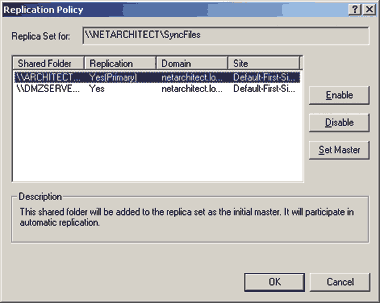
|
| Экран 3. Формирование политики репликации |
Окончание настройки репликации Dfs для конкретной среды зависит от того, как предполагается реализовать Dfs. В данный момент уже можно переносить каталоги, подкаталоги и файлы в корень Dfs, а Windows 2000 будет автоматически синхронизировать данные между всеми ресурсами корня Dfs. Точнее говоря, можно целиком задействовать древовидную структуру каталогов, чтобы все критически важные файлы данных располагались где-нибудь внутри структуры Dfs. Тогда можно быть уверенным, что в случае глобального сбоя (катастрофы) эта информация будет реплицирована и доступна из других офисов организации.
Можно пойти еще дальше и создать ссылки Dfs внутри структуры Dfs. Ссылки Dfs появляются перед конечными пользователями как папки в рамках структуры Dfs, но реально они представляют собой новые ресурсы, определенные внутри структуры Dfs (отдельно от ресурсов, которые использовались для определения корня Dfs; см. рис. 2). Ссылки Dfs особенно полезны, когда имеются различные типы данных, которые уже существуют на нескольких серверах, и требуется консолидировать эту информацию в единую структуру каталогов с простой навигацией. Для того чтобы создать ссылку Dfs, нужно щелкнуть правой кнопкой по вновь определенному корню Dfs в левой панели оснастки Distributed File System, затем выбрать New Dfs Link для запуска мастера конфигурации. Как и при конфигурации корня Dfs, мастер попросит выбрать серверы и ресурсы, которые будут участвовать в связи, и установить репликацию между ресурсами.
Советы и предостережения в работе с Dfs
Не стоит слишком сильно восхищаться Dfs, поскольку она имеет ряд ограничений — это не окончательное решение для всех межсайтовых задач по репликации данных, а только полезный инструмент для начинающих. Прежде всего нужно узнать, какие типы файлов можно реплицировать с помощью Dfs. Например, Dfs хорошо работает с файлами, которые пользователи открывают, редактируют, а затем закрывают до тех пор, пока им вновь не понадобится доступ к этим файлам. Dfs узнает, что файл был изменен, и реплицирует новую версию файла по сети. Кроме того, Dfs реплицирует файл целиком, а не только изменения. Поэтому нужно помнить: если был изменен большой файл, Windows 2000 будет копировать целиком новый файл в каждую реплику в сети.
Помимо перемещения файлов данных из одной реплики в другую, Windows 2000 также реплицирует разрешения, которые были определены в структуре Dfs. Если добавить или удалить разрешение на папку или файл в одном месте, Dfs реплицирует эти изменения по всей сети.
Единственный элемент, не подлежащий репликации Dfs, — это блокировки файлов, индикаторы, с помощью которых Windows 2000 определяет, работает ли с файлом кто-нибудь еще. Этот вопрос важен и, вероятнее всего, он повлияет на способ формирования структуры Dfs. Поскольку Dfs не реплицирует блокировки файлов, два пользователя могут работать с одним и тем же файлом одновременно, каждый со своей копией. Если такая ситуация имеет место и оба пользователя сохраняют свои изменения в сети примерно в одно и то же время, срабатывает правило «побеждает записавший последним» (last-writer-wins). Например, изменения, сделанные одним пользователем, могут быть записаны на диск и синхронизированы, а затем почти сразу же переписаны изменениями, сохраненными другим пользователем. Чтобы избежать подобной ситуации, я обычно советую пользователям всегда рассматривать синхронизированные реплики только как резервные копии, т. е. ресурсы, к которым пользователи не должны иметь прямого доступа.
Один из способов синхронизации реплик в качестве резервных копий состоит в том, чтобы выделить ресурсы в соответствии с принадлежностью документов к конкретным сайтам, а затем создать резервную копию ресурса на другом сайте. Например, хранилище документов по продажам из нью-йоркского офиса может быть в ресурсе NYSALESDOCS. Чтобы реплицировать эти данные в Лондон, я мог бы создать папку, назвав ее NYSALESDOCS-BACKUP и определить ее как реплику Dfs.
Наверное, читатели уже догадались, что если существует только один главный ресурс Dfs с именем SALESDOCS во всей организации, то Dfs будет тратить много времени, отправляя пользователей на конкретный ресурс, расположенный на конкретном сервере, поскольку Dfs использует сайты AD, чтобы определить, является ли ресурс ближайшим.
Поскольку репликация Dfs запускается при изменении файла, Dfs плохо работает с файлами баз данных, которые всегда открыты, — раз с файлами баз данных никогда не выполняются операции закрытия, эти данные никогда не синхронизируются. В результате Dfs не сможет реплицировать базы данных Microsoft SQL Server и Microsoft Exchange Server. Важно помнить о том, что репликация Dfs подобна созданию зеркального образа диска (т. е. система реплицирует те данные, которые имеет). В результате, если рабочую станцию пользователя поражает вирус, который повреждает все файлы типа .doc, а пользователи модифицируют эти файлы, Dfs будет реплицировать поврежденные файлы до тех пор, пока они находятся в структуре Dfs. Этот пример показывает, почему традиционное резервное копирование все еще необходимо. И наконец, по умолчанию Dfs не реплицирует определенные типы файлов: .bak, .tmp и любые файлы, имена которых начинаются с тильды (~).
Дуглас Тумбс — редактор Windows & .NET Magazine. Имеет сертификаты MCSE, Compaq ASE и Novell CNA. С ним можно связаться по электронной почте по адресу: doug@netarchitect.com.