

Главные обязанности администратора Microsoft Exchange Server - проконтролировать доставку почты, обеспечить работоспособность системы и убедить пользователей в абсолютной надежности Exchange Server. Для достижения этих целей необходимо сосредоточить внимание на «трех китах» производительности: аппаратных средствах, проектировании и эксплуатации. Надежные и мощные аппаратные средства - фундамент производительности Exchange Server, но добиться максимальной производительности в течение длительного времени можно, лишь уделив столь же пристальное внимание проектированию системы, построенной на базе этой аппаратуры, и методам управления аппаратными средствами.
Условие первое: аппаратные средства
Платформой для высокопроизводительного Exchange Server может служить сбалансированная аппаратная конфигурация с достаточными функциональными возможностями. Чтобы получить желаемую производительность, необходимо сбалансировать три важнейших компонента сервера: процессор, память и жесткий диск.
Проблема конфигурирования сервера, в сущности, сводится к определению необходимого количества процессоров и их мощности, размера памяти машины и типа дисковой подсистемы. Учитывая скорость современных процессоров и относительно низкую стоимость памяти и дисковых накопителей, даже при ограниченных средствах сейчас можно приобрести полноценный сервер. Минимальный стандартный сервер - оснащенный, например, 700-мегагерцевым процессором, памятью объемом 256 Мбайт и тремя 18-гигабайтными дисками с контроллером RAID пятого уровня - может обслуживать несколько сотен почтовых ящиков Exchange Server. Пояснения к эталонным тестам, используемым поставщиками для определения мощности серверов, приведены во врезке «О чем говорят эталонные тесты». Выбирать конфигурацию высокоуровневых серверов (с высокой степенью готовности или обслуживающих более 1000 почтовых ящиков) сложнее, в основном, из-за того, что желаемого уровня производительности можно достичь, используя разные комбинации аппаратных компонентов.
Характеристики центрального процессора. Большинство машин Exchange Server оснащается лишь одним процессором, однако тесты поставщиков аппаратных средств показывают, что Exchange 2000 хорошо масштабируется для работы с несколькими процессорами. На тестах Compaq увеличение числа процессоров с двух до четырех привело к росту числа почтовых ящиков на 50%; при переходе от четырех к восьми процессорам производительность также увеличилась на 50%. Учитывая издержки, связанные с симметричной обработкой, - это отличный результат, свидетельствующий о том, что программный код Exchange Server успешно работает на нескольких процессорах. Как утверждают в Microsoft, пакет исправлений Exchange 2000 Service Pack 1 (SP1) позволит работать с более чем восемью процессорами, однако в настоящее время восьми-процессорные машины удовлетворяют потребностям самых крупных корпораций, использующих Exchange 2000.
Мощность ЦП постоянно растет. Но особенно сильное влияние на производительность Exchange Server оказывает кэш второго уровня (L2), поэтому я рекомендую использовать машины с кэшем L2 максимально большого размера. Размеры специальной области для кэширования команд зависят от модели процессора. Типичный размер кэша второго уровня процессоров Intel Pentium III составляет 256 Кбайт, тогда как размер кэша процессора Xeon достигает 2 Мбайт. В настоящее время процессоры Xeon - лучшая платформа для Exchange Server, поскольку они оснащены набором микросхем, оптимизированным для серверных приложений.
Администраторы стараются полностью использовать вычислительные возможности машины; для этого необходимо устранить все узкие места. Как правило, в первую очередь нужно решить проблемы оперативной памяти, затем увеличить емкость подсистемы дисковой памяти и повысить пропускную способность сети (100 Мбит/с обычно бывает достаточно для любых систем Exchange Server, за исключением самых крупных). Если после настройки этих компонентов вычислительных ресурсов ЦП будет недостаточно, можно увеличить число процессоров или повысить их тактовую частоту.
Память и кэш. В Exchange 2000 и Ex-change Server 5.5 реализован механизм динамического выделения буфера (Dynamic Buffer Allocation, DBA) для оптимизации размера памяти, предоставляемой приложению операционной системой. DBA отслеживает интенсивность нагрузки на сервер и соответственно изменяет размер виртуальной памяти, используемой механизмом базы данных Exchange Server (Extensible Storage Engine, ESE). DBA - часть процесса Store (общий термин, употребляемый Microsoft вместо In-formation Store, IS), поэтому иногда можно увидеть, как уровень загрузки процессора на сервере, периодически испытывающем интенсивную нагрузку, от процесса Store резко увеличивается или сокращается. Колебания, вызванные Store, отмечаются и на системах Exchange Server, работающих с другими приложениями - особенно базами данных, такими, как Microsoft SQL Server, - когда запросы на ресурсы памяти поступают от многих программ.
На серверах, работающих исключительно с Exchange Server, а потому имеющих стабильную нагрузку, процесс Store, как правило, нагружает процессор до определенного уровня, который остается неизменным. Компьютеры с версией Exchange 2000 не относятся к этой группе, потому что любому серверу Exchange 2000 для поддержки протоколов Internet необходим Microsoft IIS. Не следует беспокоиться из-за больших процентов загрузки от процесса Store - они свидетельствуют лишь о том, что ни одно другое активное приложение не претендует на ресурсы памяти, поэтому DBA запросил дополнительную память для кэширования страниц базы данных. В итоге сокращается интенсивность подкачки страниц и повышается производительность.
Определить размер памяти, используемой ESE, позволяет счетчик Database Cache Size (Information Store) для объекта Database монитора производительности Performance Monitor. На Экране 1 показано типичное значение для небольшого сервера Exchange 2000, работающего с умеренной нагрузкой. Данный сервер распола-гает оперативной памятью объемом 256 Мбайт, но для ESE выделено примерно 114 Мбайт виртуальной памяти. Следует отметить, что объем виртуальной памяти, используемой ESE, будет расти по мере загрузки новых групп хранилищ (storage group, SG) и баз данных. Опытные системные администраторы в связи с этим проявляют максимальную осторожность при выделении места для хранилища.
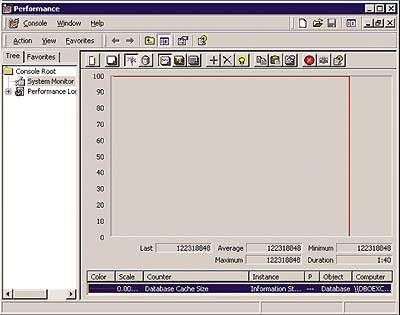
|
| Экран 1. Контроль использования памяти механизмом ESE. |
ESE использует оперативную память для кэширования страниц базы данных. Если на сервере недостаточно физической памяти, ESE записывает в кэш меньше страниц и чаще обращается к диску, извлекая информацию из базы данных. В результате возрастает нагрузка на подсистему ввода/вывода, которая должна выполнять больше операций, чем обычно. Следовательно, необходимо модернизировать эту подсистему, возможно, установив дополнительные диски и перераспределив операции ввода/вывода. Однако, как правило, более экономичным способом будет расширение памяти сервера, и этот вариант всегда следует рассматривать в первую очередь.
Максимальная производительность диска. В сущности, Exchange Server - прикладная программа, работающая с базой данных, и, как любое приложение такого рода, она генерирует множество операций ввода/вывода и создает нагрузку как на диск, так и на контроллер. Поэтому любые мероприятия по повышению производительности должны состоять из трех этапов: необходимо правильно распределить источник ввода/вывода (пересылаемые файлы) по дискам, обеспечить защиту важнейших файлов и выбрать наиболее подходящие аппаратные средства для дисковых операций.
Даже на самой малой системе требуется в первую очередь разделить наборы журналов транзакций и файлы базы данных. Эта мера обеспечивает максимальную вероятность сохранения информации в случае отказа диска. Если разместить журналы на одном накопителе, а базу данных - на другом, то сбой одного устройства не повлияет на работу другого, и базу данных удастся восстановить с помощью резервной копии. Но если база данных и журналы хранятся на одном накопителе, то отказ диска неминуемо приведет к потере данных.
Второй шаг - обеспечить необходимый уровень защиты журналов транзакций. В них хранятся сведения о различиях между текущим состоянием информации в базе данных (страницы в оперативной памяти) и последней сделанной копией (страницы на диске). Нельзя хранить журналы транзакций на незащищенном диске; достаточно надежную защиту без снижения производительности обеспечивают массивы RAID 1 с кэшем с обратной записью на контроллере. Нужно разделить журналы транзакций на серверах Exchange 2000 Enterprise Server, работающих с несколькими группами хранения SG. В идеале следует связать каждый набор журналов с отдельным томом.
Третий шаг - как можно надежнее защитить базы данных хранилища. Можно обеспечить необходимый уровень безопасности, объединив в массивы RAID 5 или RAID 0+1 диски, содержащие почтовые ящики и общедоступные хранилища. Самый распространенный вариант - RAID 5 (Microsoft рекомендовала метод RAID 5 после выпуска Exchange Server 4.0), но последнее время чаще применяется RAID 0+1, благодаря более высокой скорости операций ввода/вывода и возможности обойтись без кэша с обратной записью. Тестирование фирмы Compaq показало, что один накопитель в массиве RAID 0+1 может обслуживать операции ввода/вывода, генерируемые 250 активными пользователями Exchange Server. Таким образом, крупный сервер, обслуживающий 2500 активных пользователей, должен быть оснащен массивом RAID 0+1 с 10 дисками. Для увеличения производительности следует выбирать диски с более высокой скоростью ввода/вывода, а не накопители с большей емкостью.
Установив на сервере запоминающие устройства достаточной емкости, необходимо убедиться, что сервер обеспечивает желаемый уровень производительности. Чтобы получить полную картину, нужно отслеживать каждое устройство, содержащее потенциально «горячий» файл (т. е. файл, генерирующий интенсивный трафик ввода/вывода). Для машин Exchange Server 5.5 это устройства, на которых находятся рабочие файлы служб Message Transfer Agent (MTA) и Internet Mail Service (IMS). Такой же подход рекомендуется и для Exchange 2000, но следует контролировать еще и то устройство, где хранится каталог удаленной почты SMTP. При этом нужно учесть, что хранилище Store может быть разделено на несколько баз данных, каждую из которых необходимо контролировать.
Быстро оценить производительность запоминающих устройств на машине Exchange Server можно с помощью нескольких счетчиков Performance Monitor, измеряющих время отклика диска и длину очередей. Контролировать время отклика можно с помощью одного из следующих счетчиков объекта Physical Disk:
* Avg. disk sec/Read * Avg. disk sec/Write * Avg. disk sec/Transfer
Время выполнения произвольных операций ввода/вывода для каждого устройства не должно превышать 20 мс. Время последовательных операций должно быть меньше 10 мс. При превышении пороговых значений необходимо оптимизировать производительность. Самый простой способ - переместить файлы таким образом, чтобы увеличить нагрузку на те устройства, которые используются менее интенсивно. Существуют и более радикальные способы: перемещение почтовых ящиков, общедоступных папок или коннекторов, обеспечивающих связь с другим сервером, а также установка дополнительных дисков и распределение «горячих» файлов.
Необходимо также следить и за счетчиками производительности Pages Read и Pages Write для объекта Memory: они показывают длительность обращений к диску, вызванных отсутствием нужных страниц в памяти. Сумма этих двух величин не должна превышать 80 мс (т. е. должна примерно соответствовать времени, отведенному на выполнение операции ввода/вывода для одного жесткого диска). Если суммарная величина превышает 80 мс, необходимо расширить физическую память сервера и, возможно, разместить файл подкачки на более быстром диске (хотя последний способ менее эффективен, чем увеличение размера оперативной памяти).
Счетчик Current Disk Queue Length для объекта Physical Disk указывает число операций, ожидающих очереди для доступа к конкретному тому. Windows 2000 подсчитывает длину очереди отдельно для операций чтения и записи, но важен суммарный показатель. На практике удобно руководствоваться правилом, согласно которому число запросов в очереди должно быть меньше половины общего количества дисков тома. Например, для тома на массиве RAID с 10 дисками длина очереди не должна превышать четыре запроса. Задача администратора - создать достаточный запас для обслуживания запросов, поступающих в период пиковой нагрузки. Постоянно большая длина очереди означает, что том не справляется с обслуживанием запросов ввода/вывода.
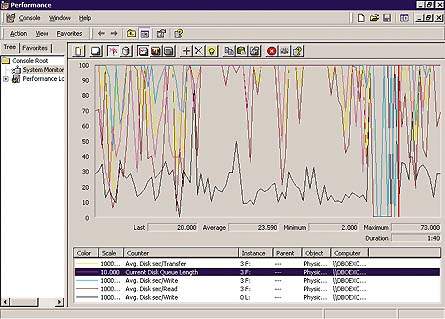
|
| Экран 2. Мониторинг дисков. |
На Экране 2 показаны результаты мониторинга диска F (на котором размещены базы данных Store) и диска L (где хранятся файлы журналов) на сервере Exchange 2000. Показания счетчика Current Disk Queue Length для объекта Physical Disk свидетельствуют, что диск хранилища сильно перегружен: средняя длина очереди 23,59, а максимальная - 79 операций ввода/вывода. Нагрузка резко увеличилась, когда в общедоступном хранилище было создано несколько копий большой общедоступной папки (в одной папке находилось 32 000 элементов). В процессе тиражирования Exchange Server генерировал 230 файлов журналов (1,3 Гбайт данных). Увеличение нагрузки не пройдет незамеченным, так как Exchange Server будет помещать в очередь любые запросы к хранилищу, и время отклика сервера будет больше, чем обычно.
Условие второе: проектирование
Рабочую нагрузку каждого Exchange Server определяют число почтовых ящиков, обслуживаемых сервером, наличие на нем коннектора либо общедоступных папок или его особая роль (например, управление сертификатами). На стадии проектирования выясняется объем данных, размещаемых на сервере, и степень его готовности.
Можно предположить, что с увеличением числа почтовых ящиков требования к размещению данных будут возрастать. Однако одновременно администраторы сталкиваются с «синдромом хомяка»: пользователи начинают накапливать сообщения, чтобы обосновать просьбы о расширении выделенных им почтовых ящиков. Стоимость дисков невелика, поэтому самым простым выходом из положения будет увеличение квот. В организациях, использующих Exchange Server, выделяемые по умолчанию квоты выросли с 25 Мбайт в 1996 г. до 100 Мбайт в 2001 г. Некоторые администраторы назначают квоты менее 100 Мбайт и умудряются удовлетворять все потребности пользователей (что само по себе достижение). Другие администраторы выделяют квоты более 100 Мбайт и вынуждены мириться с дефицитом дискового пространства и увеличением времени резервного копирования.
Дисковую память машины Exchange Server можно расширить, установив и подключив к сети несколько дополнительных накопителей, но это не лучший способ повышения производительности. Каждое экстренное расширение отрицательно сказывается на готовности сервера, и всегда существует опасность непредвиденных затруднений в процессе модернизации. Более удачный подход - заранее планировать максимальный размер дисковой памяти на весь срок эксплуатации сервера и соответствующим образом проектировать инфраструктуру запоминающих устройств. При использовании Exchange 2000 в проекте необходимо учесть взаимодействие между Exchange Server и Active Directory (подробности об их взаимосвязи изложены во врезке «Exchange 2000 и AD»).
Новые возможности Exchange 2000 и аппаратуры позволяют повысить готовность почтовой системы предприятия. (В частности, о функциях кластеризации Exchange 2000 рассказано в ст. Джерри Кохрана «Построение Exchange 2000 на кластере», Windows 2000 Magazine/RE №1 и №2 за 2001 г. - прим. ред.) Благодаря новым аппаратным решениям, таким, как SAN (Sto-rage Area Network - сеть хранения данных), повышается устойчивость систем к отказам дисков. Возможность создания моментальных снимков состояния системы, первоначально запланированная только для Exchange 2000, но реализованная и в последних версиях продуктов Microsoft, позволяет повысить готовность сервера за счет быстрого восстанавления испорченных баз данных.
Условие третье: эксплуатация
Достоинства лучших аппаратных средств и самого продуманного проекта могут быть сведены на нет ошибками в процедурах обслуживания. Компания настолько сильна, насколько сильно самое слабое ее звено, и слишком часто это звено остается скрытым до тех пор, пока администратор не сталкивается с трудностями в процессе эксплуатации системы.
Постоянный мониторинг обслуживаемых компонентов - ключ к эффективной эксплуатации. Операционная система и Exchange Server записывают информацию в журналы событий. Необходимо проверять информацию вручную или воспользоваться таким продуктом, как AppManager фирмы NetIQ, для поиска событий, указывающих на потенциальные проблемы. Например, если процесс Store обнаруживает, что механизм базы данных не полностью завершил транзакцию, то Exchange Server фиксирует в журнал приложений ошибку с ID1018. В версиях, предшествующих Exchange Server 5.5, ошибка c ID1018 может быть результатом временного рассогласования между дисковым контроллером и операционной системой, но Exchange 2000 и Exchange Server 5.5 повторно выполняют транзакции и устраняют любые недостатки. В Exchange 2000 и Exchange Server 5.5 ошибка c ID1018 может свидетельствовать об аппаратном сбое и повреждении базы данных. Если не проверить аппаратные средства и не восстановить базу данных с помощью резервной копии, то Exchange Server будет генерировать все больше сообщений об ошибках c ID1018 по мере порчи данных, пока база данных не откажет окончательно. Безусловно, в любых сделанных в это время резервных копиях будут содержаться искаженные данные. Небольшие повреждения можно устранить с помощью утилиты Eseutil, но она не поможет восстановить информацию, потерянную в результате отказа аппаратных средств, поэтому сообщение об ошибке c ID1018 - игнорировать нельзя.
Многие другие ежедневно регистрируемые события позволяют оценить состояние системы Exchange Server. Например, в журнале приложений Application Log можно найти информацию о фоновой дефрагментации - операции, которую процесс хранилища Store обычно выполняет автоматически. Exchange Server регистрирует события, отмечающие начало процесса дефрагментации (событие с ID 700), его конец (событие с ID 701) и размер свободного дискового пространства после завершения (событие с ID 1221).
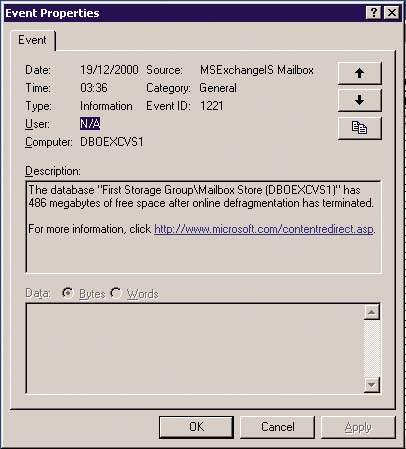
|
| Экран 3. Результаты работы дефрагментатора. |
В сообщении о событии, показанном на Экране 3, говорится, что после дефрагментации почтового хранилища 6,67 Гбайт Exchange 2000 размер свободного пространства составляет 486 Мбайт (примерно 7,2% объема базы данных). На этом пространстве будут записываться новые сообщения и присоединенные файлы по мере их поступления.
Размер базы данных можно сократить, перестроив ее в автономном режиме с помощью Eseutil, но эту операцию следует выполнять лишь в тех случаях, когда планируется освободить много места (более 30% базы данных), и администратор испытывает дефицит дискового пространства или желает сократить время резервного копирования. Поскольку автономная перестройка занимает длительное время (по крайней мере 1 ч на каждые 4 Гбайт данных), лучше купить дополнительные диски или более быстрые устройства резервного копирования, чем применять Eseutil.
В журнале приложений также содержатся сведения об ошибках агента MTA, подробности сообщений о репликации и данные о попытках доступа к чужому почтовому ящику с помощью учетной записи Windows 2000 или Windows NT, не связанной с этим почтовым ящиком. Некоторые антивирусные программы инициируют события последнего типа, когда обращаются к почтовым ящикам, чтобы проверить файлы, присоединенные к входящим сообщениям.
Exchange Server регистрирует события, связанные с операциями резервного копирования. Опытные системные администраторы чрезвычайно осторожно относятся к резервному копированию и всегда проверяют, успешно ли выполняется процесс. Согласно закону Мерфи, в самый неподходящий момент резервные ленты оказываются нечитаемыми, а на любой читаемой ленте, использованной в критической ситуации, содержатся испорченные данные.
Резервное копирование - самая важная задача администратора Exchange Server. Любая система может выйти из строя в результате поломки аппаратуры, но ни один руководитель не потерпит длительного отключения системы или потери данных из-за ошибок либо небрежности при составлении процедур резервного копирования.
Никто не застрахован от полной остановки системы, вызванной отказом аппаратуры. Поэтому задача администратора - свести к минимуму отрицательные последствия любой неисправности, после которой приходится восстанавливать данные. Чтобы это осуществить, необходимо соблюдать следующие требования.
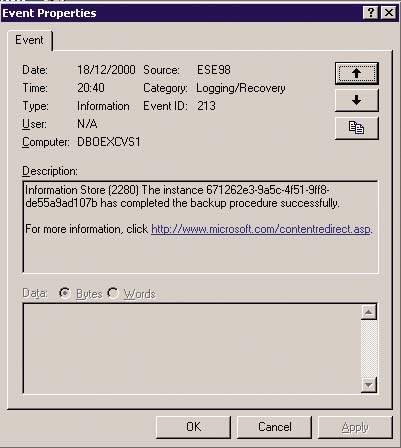
|
| Экран 4. Запись в журнале событий об успешном завершении резервного копирования. |
- Ежедневно делайте резервные копии, проверяя результат. На Экра-не 4 показано событие с ID 213, которое Exchange Server записывает в журнал приложений при успешном завершении операции резервного копирования.
- Освойте процедуру восстановления отказавшей базы данных Exchange Server. Обратите внимание: в Ex-change 2000 эта задача одновременно сложнее и проще, чем в Exchange Server 5.5. С одной стороны, Ex-change 2000 Enterprise поддерживает несколько баз данных, и, возможно, администратору придется восстанавливать не одну базу данных. С другой стороны, Exchange 2000 Store может продолжать работу во время восстановления баз данных, поэтому доступа к службе лишаются только те пользователи, чьи почтовые ящики находятся в отказавшей базе.
- Изучите признаки приближающегося отказа и контролируйте состояние системы, чтобы распознавать проблемы на ранних стадиях.
- Отработайте план восстановления после отказа. Убедитесь, что все сотрудники, которым требуется восстанавливать данные, знают, где находятся резервные носители, как восстановить Exchange Server и операционную систему (на случай катастрофического отказа аппаратных средств) и когда следует обратиться за помощью. Обращение в службу Microsoft Product Support Services (PSS) не поможет, если перед этим в процессе восстановления были сделаны непоправимые ошибки. Если вы не знаете, что делать, то лучше сразу же обратиться за консультациями.
Заниматься копированием данных изо дня в день утомительно. Но в случае отказа диска или контроллера значение хорошей копии трудно переоценить.
Знание - залог успеха
Не понимая технологии, невозможно создать хороший проект и правильно управлять серверами, а первые аппаратные неполадки могут привести к потере данных и длительным простоям. Существует огромное количество материалов по Exchange Server 5.5, быстро растет и объем информации по Exchange 2000. На таких конференциях, как Microsoft TechEd и Microsoft Exchange Conference (MEC), можно познакомиться с опытом других специалистов и прогнозами на будущее.
Несомненно одно - технология будет продолжать развиваться. Постоянно пополняя багаж знаний, администраторы научатся эффективно использовать новые аппаратные и программные технологии. Результатом станет стабильная - и все более высокая - производительность системы Exchan-ge Server.
Тони Редмонд - редактор Windows 2000 Magazine, старший технический редактор выпусков Exchange Administrator. Связаться с ним можно по адресу: exchguru@win2000mag.com.
Пьер Бижу - старший архитектор группы Applied Microsoft Technologies Group компании Compaq (Софиа-Антиполис, Франция). С ним можно связаться по адресу: bijaoui@compaq.com.
О чем говорят эталонные тесты
Крупнейшие поставщики аппаратных средств публикуют руководства, из которых можно получить информацию о базовых возможностях настройки производительности продуктов. В руководствах приводятся полученные в ходе тестирования сведения о числе почтовых ящиков, соответствующих определенной рабочей нагрузке для машины той или иной конфигурации. Messaging API (MAPI) Messaging Benchmark (MMB) и MMB2 - два варианта тестов, обычно используемые поставщиками для эталонных испытаний.
MMB - более старый набор пользовательских операций (например, создание и рассылка сообщений, обработка календаря деловых встреч), который дает неточные результаты. Например, согласно опубликованным результатам MMB, некоторые машины обслуживают десятки тысяч почтовых ящиков. В 2000 г. специалисты Microsoft разработали эталонный тест MMB2 для более точного измерения рабочей нагрузки в производственной среде. Как правило, результаты MMB2 в семь раз ниже показателей MMB. Например, результат MMB - 14 000 почтовых ящиков - соответствует значительно более реальной величине - 2000 почтовых ящиков MMB2.
Нельзя упускать из виду, что приводится число имитируемых пользователей; результаты практических испытаний могут быть иными - достаточно вспомнить пользователей, которые безмятежно обмениваются сообщениями с большими присоединенными файлами. В эталонных тестах, как правило, не учитываются сетевые издержки, репликации и другие затраты системных ресурсов в рабочей среде. Тем не менее при правильном понимании ограничений, присущих эталонным тестам, результаты, полученные для машин различной конфигурации, послужат отправной точкой при проектировании сервера.
Exchange 2000 и AD
Рассказ о производительности Microsoft Exchange 2000 Server будет неполным без упоминания об Active Directory (AD). AD используется в качестве корпоративного хранилища информации о конфигурации Exchange 2000, глобального адресного списка (Global Address List, GAL) и основного информационного ресурса для принятия решений о маршрутизации. В непосредственном сетевом окружении каждого сервера Exchange 2000 должен находиться сервер глобального каталога Global Catalog (GC), чтобы запросы из Exchange как можно быстрее поступали в AD.
Искать в GC каждый адрес, необходимый Exchange 2000, неэффективно, поэтому на сервере имеется кэш, в котором хранится недавно использованная информация из каталога. Exchange 2000 всегда в первую очередь обращается в кэш и продолжает поиск в GC лишь в том случае, если не удается найти нужных данных в кэше. Кэш может содержать тысячи записей, но тем не менее быстрый доступ к GC - необходимое условие для достижения высокой производительности.
В малых системах один сервер может исполнять Exchange 2000 и одновременно выполнять роль GC. Если Windows 2000 развернута лишь в рамках одного домена, то все контроллеры домена являются GC. Размещать GC в небольших сетях будет, по-видимому, несложно, но администраторам предприятий и распределенных сред придется потрудиться.