

Если представить вычислительную систему в виде совокупности звеньев, или цепочки, становится очевидно, что быстродействие всей системы определяет компонент, имеющий самую низкую производительность (иначе говоря, слабейшее звено цепи). Это слабое звено называют еще узким местом, критическим фактором, «горлышком бутылки» (bottleneck). Если пользователь чувствует, что система или прикладная программа «притормаживает», значит, одно из звеньев цепочки сдерживает остальные. Чтобы отрегулировать производительность системы, нужно, прежде всего, определить, какой именно компонент оказался не на высоте - центральный процессор, память, дисковая подсистема, сетевой интерфейс, прикладные программы или службы Windows NT. Ведь если начать укреплять участок, не влияющий отрицательно на производительность системы, все усилия окажутся напрасными.
|
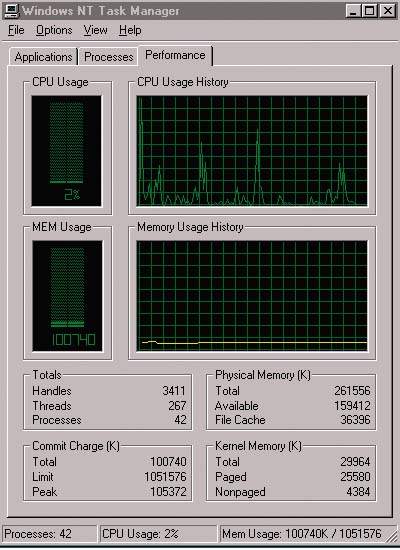
| Экран 1. Task Manager. |
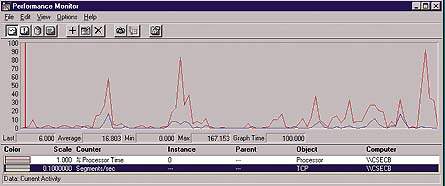
Оптимизировать производительность системы, а также находить ее потенциально слабые звенья можно с помощью как собственных средств NT Server, так и инструментов производства независимых компаний. В инструментарии NT Server следует выделить такие средства, как диспетчер задач Task Manager (см. Экран 1) и диспетчер производительности Performance Mo-nitor (см. Экран 2). Диспетчер Task Manager позволяет быстро выяснить, что происходит в системе. И хотя в этой программе не предусмотрен механизм протоколирования, она обеспечивает представление подробной информации о выполняющихся программах и процессах. Кроме того, Task Manager позволяет управлять процессами, которые могут оказывать неблагоприятное воздействие на систему. Утилита Performance Monitor применяется для получения более детализированной информации о производительности (в виде диаграмм, оповещений и отчетов, которые базируются как на текущем состоянии, так и на результатах протоколирования) с помощью мониторинга системных событий. В комплекте ресурсов Microsoft Windows NT Server 4.0 Resource Kit содержатся также средства диагностики (некоторые средства контроля производительности, имеющиеся в Windows NT, представлены в Таблице 1).
|
| Экран 2. Perfomance Monitor. |
Но прежде чем приступить к процессу оптимизации производительности, нужно как следует в нем разобраться. Небходимо в точности знать, какое используется серверное оборудование, как функционирует NT, какие приложения выполняются на машинах, кто работает с системой, каким нагрузкам она подвержена и как вписывается в общую инфраструктуру сети. Кроме того, требуется определить базовый уровень производительности, что позволит понять, каким образом система использует свои ресурсы, функционируя в обычном режиме при типичных нагрузках (для определения базового уровня производительности можно использовать утилиту Performance Monitor). Не имея базового статистического материала, невозможно зафиксировать изменения эксплуатационных характеристик сервера NT. Чем больше объектов будет подвержено мониторингу базовых характеристик, тем лучше. Пусть это будут, к примеру, характеристики работы памяти, процессоров, операционной системы, файла страничного обмена, логических дисков, физических дисков, сервера, кэш-памяти, сетевого интерфейса. Но в любом случае при выполнении замеров базовых характеристик сервера нужно отслеживать четыре главных ресурса - состояние памяти, процессора, дисков и сетевого интерфейса. При этом не имеет значения, какие функции выполняет данный сервер - является ли он файловым сервером, сервером печати, сервером приложений или контроллером домена. Надо сказать, что все четыре главных ресурса сервера взаимосвязаны, поэтому отыскать слабое звено системы бывает нелегко. Решая одну проблему, можно создать другую. Подбирая нужные параметры, следует вносить изменения по одному и каждый раз сравнивать полученные результаты с базовыми характеристиками; так можно будет определить, пошло ли изменение на пользу. Если вносить несколько изменений сразу и сопоставлять результаты с исходными показателями, нельзя точно сказать, какие из действий повысили производительность системы, а какие нет. Всегда тестируйте новую конфигурацию несколько раз. Важно быть уверенным, что внесенные изменения не ухудшают характеристики сервера. Кроме того, следует всегда тщательно документировать как свои действия, так и результаты.
Память
Замедление работы системы NT Server нередко объясняется нехваткой памяти. Причем иногда кажется, что подлинная причина снижения быстродействия совсем в другом: например, в слишком высоких нагрузках на ЦП или в недостаточной эффективности операций ввода/вывода диска. В первом приближении самый надежный признак проблем в подсистеме памяти - это стабильно высокий показатель отсутствия страниц памяти [hard page faults] (скажем, более пяти ситуаций отсутствия страницы в секунду). Ситуация отсутствия страницы возникает в том случае, когда программа не в состоянии обнаружить затребованные данные в физической памяти и потому вынуждена считывать их с диска. Чтобы определить, испытывает ли система недостаток оперативной памяти, можно воспользоваться утилитой Performance Monitor. Чтобы узнать, каково состояние подсистемы памяти, нужно проанализировать значения следующих счетчиков.
Memory: Pages/sec. Счетчик регистрирует количество запрошенных страниц, которые не представлены непосредственно в ОЗУ и потому считываются с жесткого диска или записываются на диск, чтобы освободить пространство ОЗУ для других страниц. Если данный показатель высок при обычных нагрузках на систему, нужно позаботиться об увеличении размера оперативной памяти. Если же значение счетчика Memory: Pages/sec возрастает, тогда как показатель счетчика Memory: Available Bytes приближается к нижней границе, 4 Мбайт, предусмотренной для системы NT Server, а диски, содержащие файлы pagefile.sys, активно участвуют в обменах (т. е. их показатели %Disk Time, Disk Bytes/sec и Average Disk Queue Length возрастают), можно говорить о перегруженности оперативной памяти. Если же счетчик Memory: Available Bytes не фиксирует сокращения свободной памяти, значит, с подсистемой памяти все в порядке. В этом случае нужно выяснить, какая прикладная программа выполняет большое количество операций чтения и записи на диск (и убедитесь, что соответствующие данные не представлены в кэш-памяти). Для этого нужно с помощью утилиты Perfor-mance Monitor проконтролировать объекты Physical Disk и Cache. На основании значений счетчиков объекта Cache можно судить о том, не малый ли объем кэш-памяти влияет на производительность всей системы.
Memory: Available Bytes. Данный счетчик регистрирует объем доступной программам физической памяти. Как правило, он невелик, поскольку диспетчер Disk Cache Manager системы NT использует почти всю память для кэширования данных, но возвращает ее при поступлении запросов на выделение памяти. Однако если значения счетчика для сервера стабильно ниже порога 4 Мбайт, это свидетельствует о слишком активном страничном обмене.
Memory: Committed Bytes. Счетчик указывает на объем виртуальной памяти, которую система выделяет для хранения данных в физической памяти или в файле подкачки. Если значение Committed Bytes превышает объем физической памяти, вероятно, необходимо увеличить емкость ОЗУ.
Memory: Pool Nonpaged Bytes. Счетчик отражает объем памяти в невыгружаемом пуле, выделяемый для выполнения задач компонентами ОС. Если значение счетчика имеет явную тенденцию к повышению, но соответствующего увеличения нагрузки сервера не наблюдается, это может означать, что выполнение одного из процессов приводит к утечке памяти. Утечка памяти (memory leak) возникает, когда вследствие ошибки программа не высвобождает избыточные ресурсы памяти. Со временем такое непроизводительное расходование памяти может привести к сбою системы, когда ресурсы всей доступной памяти будут исчерпаны (включая физическую память и дисковое пространство, выделенное для размещения файлов подкачки).
Paging File: %Usage. Счетчик показывает, какую долю (в процентах) от максимально возможного размера файла подкачки система использует фактически. Если этот показатель достигает отметки 80%, объем файла подкачки нужно увеличить.
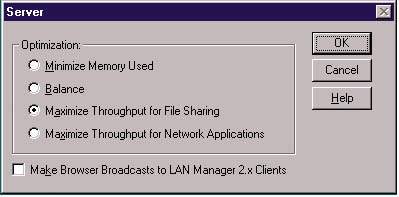
В NT Server предусмотрены средства оптимизации ресурсов памяти системы. Их можно задействовать следующим образом. В панели управления Control Panel нужно перейти к модулю Network, выбрать вкладку Services, а затем элемент Server. При щелчке на элементе меню Properties на экране появится диалоговое окно, в котором предлагается четыре варианта оптимизации (см. Экран 3): Minimize Memory Used (минимизировать использование памяти), Balance (равномерное использование ресурсов), Maximize Throughput for File Sharing (максимально увеличить пропускную способность для совместно используемых файлов) и Maximize Throughput for Network Applications (максимально увеличить пропускную способность для сетевых приложений). Можно изменять значение еще одного параметра - размера подсистемы виртуальной памяти (проще говоря, файла подкачки). Для этого нужно выбрать вкладку Performance диалогового окна System Properties.
|
| Экран 3. Выбор оптимизации работы сервера. |
С точки зрения администратора, в ведении которого находится сервер, обслуживающий множество клиентов, из названных выше вариантов оптимизации ресурсов памяти особого внимания заслуживают два: Maximize Throughput for File Sharing и Maximize Throughput for Network Applications. При выборе варианта Maximize Throughput for File Sharing NT Server выделяет максимальный объем памяти для кэша файловой системы (этот процесс называется dynamic disk buffer allocation). Такая конфигурация особенно эффективна в тех случаях, когда компьютер NT Server используется в качестве файлового сервера. Если вся память выделяется под буферы файловой системы, эффективность дисковых и сетевых операций ввода/вывода, как правило, повышается. С увеличением объема оперативной памяти, обеспечивающей функционирование буферов диска, возрастает вероятность того, что NT Server будет обрабатывать запросы на выполнение операций ввода/вывода не внутри относительно «неповоротливой» файловой системы на физическом диске, а в отличающейся высоким быстродействием кэш-памяти в ОЗУ.
При выборе другого варианта оптимизации - Maximize Throughput for Net-work Applications - NT Server выделяет для кэша файловой системы меньший объем памяти, и прикладным программам достается, соответственно, львиная доля ресурсов ОЗУ. Этот вариант оптимизирует память сервера для выполнения распределенных приложений, предусматривающих кэширование в памяти (Memory caching). Прикладные программы, например Mic-rosoft SQL Server или Exchange Server, можно настроить таким образом, что они будут использовать заданный объем оперативной памяти для дисковых буферов ввода/вывода и кэша БД.
Но стоит администратору сети, где установлено несколько сетевых прикладных программ, проявить излишнюю «щедрость» и выделить для каждого приложения слишком много памяти, как возникает опасность перегрузки (thrashing). Перегрузка возникает в тех случаях, когда число запросов ко всем активным процессам и к кэш-памяти файловой системы возрастает настолько, что эти запросы блокируют ресурсы памяти системы. В результате запросы к оперативной памяти создают ситуацию отсутствия запрашиваемой страницы. Когда такие ситуации возникают слишком часто, операционная система посвящает почти все свое время не выполнению программ, а записи и удалению данных из виртуальной памяти (свопингу страниц). Чаще всего это приводит к увеличению времени отклика. Если приложение, к которому происходит обращение, не отвечает на запросы, а индикатор диска мигает как ни в чем не бывало, то, скорее всего, система «забуксовала».
Когда производительность системы сдерживается нехваткой памяти, проблему можно решить, увеличив размер файла подкачки или распределив этот файл по нескольким дискам или контроллерам. Одновременно на сервере NT может содержаться до 16 файлов подкачки; при этом в любой момент можно осуществлять чтение и запись данных сразу в несколько файлов. Если объем дискового пространства загрузочного тома ограничен, файл подкачки можно переместить на другой том, что обеспечит выигрыш в производительности. Тем, кто придает первостепенное значение надежности системы, можно порекомендовать такую схему: небольшой файл подкачки размещается на загрузочном томе, а файл более внушительных размеров - на другом томе большей емкости. Есть и другой вариант: файл подкачки размещается на жестком диске (или на нескольких дисках), не содержащем системных файлов NT, либо на специальном томе FAT, который не входит в дисковый массив RAID.
Еще одна рекомендация. Требовательные к ресурсам памяти приложения лучше распределять по нескольким машинам. Внеся соответствующие изменения в системный реестр, можно добиться того, что сервер NT будет работать с кэшем второго уровня емкостью более 256 Кбайт. Для этого нужно запустить редактор regedit.exe, пе-рейти к разделу HKEY_LOСAL_MACHINESYSTEM CurrentControlSetControl Session MenagerMemory Management и дважды щелкнуть на параметре SecondLevelDataCache. Далее следует выбрать десятичную систему исчисления и ввести значение объема кэш-памяти второго уровня (если емкость составляет 512 Кбайт, нужно ввести число 512). Теперь нужно щелкнуть OK, закрыть редактор реестра и перезапустить систему. Кроме того, советую отключить или удалить неиспользуемые службы, драйверы устройств, а также сетевые протоколы.
Процессор
Чтобы проверить, не в процессоре ли кроется причина снижения производительности NT Server, необходимо для начала убедиться в том, что подсистема памяти работает нормально. ЦП становится критическим фактором лишь в тех случаях, когда процессор так загружен, что не может отвечать на запросы. В числе симптомов подобной ситуации - высокий коэффициент загрузки процессора, постоянные очереди и вялый отклик приложений. Как правило, нормальную работу ЦП нарушают ориентированные на интенсивное потребление ресурсов процессора приложения и драйверы, а также чрезмерное количество запросов на прерывание (из-за плохо спроектированных компонентов дисковой или сетевой подсистемы).
Отслеживать коэффициент использования процессора системы помогут следующие счетчики.
Processor: % Processor Time. Отображает время, затрачиваемое процессором на выполнение активных потоков. Если в системе установлено несколько процессоров, нужно обратиться к счетчику System: % Total Processor Time. Если коэффициент загруженности процессора стабильно превышает 80%, возможно, именно этот компонент сдерживает производительность всей системы. Чтобы выявить причину такой загруженности процессора, можно с помощью утилиты Performance Monitor проверить индивидуальные процессы. Однако нужно иметь в виду, что высокий показатель счетчика Processor: % Processor Time не всегда свидетельствует о снижении производительности. Если ЦП обрабатывает запросы от планировщика заданий NT Server, а показатели счетчиков Server Work Queues и Processor Queue Length при этом не возрастают, это значит, что ЦП обслуживает процессы максимально быстро. Говорить о том, что процессор тормозит работу системы, можно лишь в том случае, если значение счетчика System: Processor Queue Length возрастает; показатель Processor: % Processor Time тоже высок, а память системы, сетевой интерфейс и жесткие диски работают нормально. ЦП становится «узким местом» системы лишь тогда, когда он не в состоянии справиться с нагрузкой, предлагаемой NT. ЦП работает на полную мощность, но при этом очередь необработанных запросов, претендующих на его ресурсы, становится все длиннее.
Processor: % Privileged Time. Этот счетчик показывает, сколько времени ЦП затрачивает на обслуживание операционной системы.
Processor: % User Time. Время, затрачиваемое процессором на выполнение кода приложений и подсистем (например, текстового процессора или электронных таблиц). Нормальным следует считать значения 75% и ниже.
Processor: Interrupts/sec. Число прерываний от прикладных программ и аппаратных устройств, обрабатываемое процессором (за одну секунду). Этот показатель зависит от интенсивности обменов с диском, от числа операций, выполняемых за одну секунду, и от числа сетевых пакетов, передаваемых за одну секунду. Чем выше быстродействие процессора, тем большее число прерываний он способен обработать. Для большинства современных ЦП этот показатель составляет порядка 1500 прерываний в секунду.
Process: % Processor Time. Счетчик показывает, какая часть процессорного времени в процентах приходится на выполнение того или иного процесса. С его помощью можно определить, какой из процессов занимает подавляющую часть рабочих циклов процессора.
System: Processor Queue Length. Показатель отражает число задач, ожидающих обработки. Если система выполняет несколько задач, то иногда показания счетчика превышают нулевой порог. Если же значение счетчика регулярно достигает цифры 2 или превосходит этот показатель, процессор, несомненно, не справляется с нагрузкой: слишком много процессов ожидают обработки. Чтобы выяснить причину «затора», нужно запустить утилиту Performance Monitor и исследовать объект «процесс», а также провести более подробный анализ отдельных процессов, обращающихся с запросами к процессору.
Один из способов избавиться от неприятностей, связанных с низкой производительностью процессора, сводится к установке в машине центрального процессора с более высокими характеристиками. Если речь идет о системе, с которой одновременно могут работать несколько пользователей и на которой выполняются многопотоковые прикладные программы, увеличения мощности процессорной подсистемы можно добиться за счет установки дополнительного процессора. Когда обрабатывается многопотоковый процесс, для повышения производительности можно добавить еще один процессор, а если процесс однопотоковый, для повышения быстродействия нужно заменить процессор на более производительный. Но если в сети установлена операционная система с однопроцессорным ядром NT, то, возможно, придется модернизировать ядро до многопроцессорной версии. Для этого нужно переустановить NT или воспользоваться утилитой uptomp.exe из комплекта ресурсов Resource Kit.
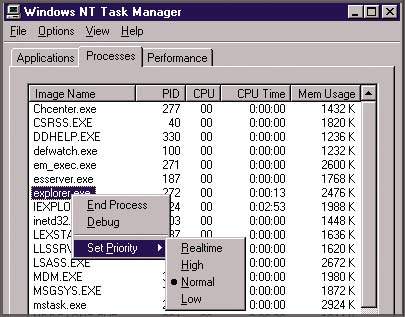
Еще один способ оптимизации характеристик ЦП состоит в том, чтобы с помощью диспетчера Task Manager выявить процессы, «потребляющие» основную часть рабочих циклов процессора, и назначить им соответствующие приоритеты. Изначально процесс имеет базовый (заданный администратором) приоритет, но порождаемые подпроцессы могут иметь другую очередность (диапазон колебаний - на два уровня выше или ниже базового приоритета). Если нагрузки на процессор достаточно велики, ускорить выполнение того или иного процесса можно за счет повышения его приоритета. Для этого нужно, нажав комбинацию клавиш Ctrl+Alt+Del, запустить диспетчер Task Manager и перейти к вкладке Processes. Теперь следует щелкнуть правой клавишей мыши на интересующем процессе, выбрать пункт Set Priority и установить для приоритета процесса одно из значений - High, Normal или Low, как показано на Экране 4. Новые приоритеты вступают в силу немедленно, но нужно иметь в виду, что это решение временное. После перезагрузки системы или перезапуска данного приложения все установленные значения приоритетов будут потеряны. Чтобы обеспечить заданный уровень приоритетов при всех последующих запусках прикладной программы, нужно воспользоваться командой Start, которая вводится из командной строки или включается в пакетный файл. Познакомиться с ключами команды Start можно, введя из командной строки
start /?
|
| Экран 4. Установка приоритета процесса. |
Дисковая подсистема
Перед тем как приступить к исследованию работы жестких дисков, нужно определить, не испытывает ли система недостатка в ресурсах памяти. Дело в том, что, когда система активно выполняет операции страничного обмена, вызванные несоразмерно малой емкостью ОЗУ, эти манипуляции легко принять за свидетельство того, что диск попросту не справляется с нагрузкой. Чтобы отличить дисковые операции, обусловленные передачей страниц на диск диспетчером Virtual Memory Manager, от операций, связанных с выполнением прикладных программ, лучше разместить соответствующие файлы подкачки на отдельных дисках.
Прежде чем браться за исследование жестких дисков с помощью утилиты Performance Monitor, нужно четко усвоить различие между двумя счетчиками, используемыми в этой программе. Счетчики LogicalDisk отражают характеристики элементов высокого уровня (например, набора томов или набора томов с чередованием). С помощью данных счетчиков можно определить, какой раздел вызывает активность диска, и даже выяснить, какое приложение или служба генерирует те или иные запросы. Счетчики PhysicalDisk отражают сведения о конкретных дисках вне зависимости от того, как эти диски используются. Иначе говоря, счетчики LogicalDisk отображают параметры операций обмена логических разделов диска, тогда как счетчики PhysicalDisk представляют ситуацию по всему жесткому диску.
По умолчанию NT не активизирует счетчики дисков, используемые утилитой Performance Monitor, так что администратор должен делать это вручную. В результате активизации производительность дисковой подсистемы снизится на 2-5%. Для активизации дисковых счетчиков Performance Monitor на локальном компьютере нужно ввести в командной строке:
diskperf -y
При исследовании дискового массива RAID нужно использовать ключ -ye. После этого компьютер следует перезагрузить.
Анализ производительности и емкости дисковой подсистемы осуществляется с помощью счетчиков дисковой подсистемы из утилиты Perfor-mance Monitor. Ниже перечислены счетчики, которые могут использоваться в обоих случаях - и для Logi-calDisk и для PhysicalDisk.
% Disk Time. Счетчик отображает, какую часть времени диск расходует на обслуживание запросов на чтение и запись. Если его значения стабильно сохраняются на уровне вблизи отметки 100%, система работает с диском весьма интенсивно. Если же идет постоянный активный обмен данными и при этом создаются большие очереди, возможно, что дисковая подсистема не справляется с нагрузкой. В типичных условиях эксплуатации значение этого счетчика не должно превышать 50.
Avg. Disk Queue Length. Показатель этого счетчика отражает среднее число ожидающих обработки запросов к диску на ввод и вывод данных. Если он стабильно выше 2, значит, в диске образовался «затор».
Avg. Disk Bytes/Transfer. Отражает пропускную способность (т. е. среднее число байтов, пересылаемых на диск или с диска в ходе операций записи или чтения). Чем выше этот показатель, тем эффективнее работает система.
Disk Bytes/sec. Скорость, с которой система пересылает байты на диск или с диска в ходе операций записи или чтения. Чем выше средний показатель, тем эффективнее функционирует система.
Current Disk Queue Length. Количество запросов к диску, ожидающих обработки. В ходе интенсивного обмена с диском очереди запросов встречаются сплошь и рядом; однако, если из запросов постоянно формируются «пробки», это значит, что диск не справляется со своими задачами.
Если есть подозрение, что производительность всей системы сдерживается неэффективной работой диска, проблему можно решить несколькими способами. Например, можно установить более производительный контроллер диска, укомплектовать массив RAID дополнительными накопителями (размещение данных на нескольких физических дисках приводит к повышению производительности, особенно при выполнении операций считывания) или нарастить память (чтобы увеличить емкость кэша для файлов). Наряду с этим можно прибегнуть к дефрагментации дисков, перейти на другую архитектуру шины ввода/вывода, разместить тома на отдельных каналах шины ввода/вывода (особенно если условия эксплуатации системы предусматривают интенсивный обмен данными с дисковой памятью) или установить новый диск с малым временем поиска (время, необходимое для перемещения головок чтения/записи дискового накопителя с одной дорожки на другую). При работе с файловой системой FAT не забывайте, что для томов размером свыше 400 Мбайт более всего подходит система NTFS.
Кроме того, администратор может выделить для выполнения приложений большее число дисков. Способ организации данных зависит от требований безопасности. Для ускорения операций чтения и записи, а также для увеличения емкости накопителей используйте тома с чередованием. В такой конфигурации коэффициент загрузки дисков в расчете на диск сокращается, а общая пропускная способность увеличивается за счет распределения нагрузки по всем томам.
Можно попробовать привести размеры используемых в системе кластеров в соответствие с размерами блоков ввода/вывода прикладной программы; это будет способствовать повышению эффективности процесса переноса данных. Однако нужно иметь в виду, что увеличение размеров кластера не всегда ведет к повышению производительности дисковой подсистемы. Если в разделе тома содержится множество мелких файлов, возможно, правильнее будет использовать кластеры меньших размеров. Существует два способа изменить размер кластера. Во-первых, с помощью командной строки. В этом случае нужно ввести с клавиатуры следующий текст:
format : /FS: NTFS /A:
А во-вторых, можно использовать утилиту Disk Administrator. В окне этой программы в меню Tools нужно выбрать пункт Format и изменить размеры кластера. В системе NTFS допускается использование кластеров следующих размеров: 512 байт, 1024 байт, 2048 байт, 4096 байт, 8192 байт, 16 Кбайт, 32 Кбайт или 64 Кбайт. В системе FAT, соответственно, - 8192 байт, 16 Кбайт, 32 Кбайт, 64 Кбайт, 128 Кбайт или 256 Кбайт.
Сетевой интерфейс
После исследования памяти системы, характеристик процессора и диска можно приступать к анализу сетевой подсистемы. Клиенты и другие системы должны иметь возможность быстро подключаться к сетевой подсистеме ввода/вывода NT Server так, чтобы время отклика на запросы пользователей не превышало допустимых пределов. Чтобы определить, какие компоненты сетевой архитектуры провоцируют снижение производительности системы и как устранить эти сдерживающие факторы, администратор должен иметь четкое представление о том, каков характер нагрузок, генерируемых клиентскими системами, какие компоненты являются ключевыми в применяемой сетевой архитектуре, какие сетевые протоколы используются (скажем, Ethernet или Net-BEUI) и каковы физические характеристики сети. Программа Performance Monitor аккумулирует данные по каждому физическому сетевому адаптеру. Для выявления нагрузки на адаптеры используются следующие счетчики.
Network Interface: Output Queue Length. Счетчик фиксирует длину очереди исходящих пакетов адаптера. Приемлемыми считаются значения 1 и 2. Но если этот показатель часто достигает уровня 3, 4 или более высоких отметок, это значит, что сетевой адаптер ввода/вывода не справляется с запросами сервера на передачу данных в сеть.
Network Interface: Bytes Total/sec. Показатель отражает весь объем сетевого трафика (число отправленных и полученных байтов), проходящего через сетевой адаптер в течение одной секунды; в него включаются и непроизводительные затраты, связанные с использованием как сетевых протоколов (к примеру, TCP/IP и NetBEUI), так и физического типа сети (например, Ethernet). Если, скажем, в сети 10BaseT этот показатель составляет около 1 Мбайт/с, а очередь исходящих пакетов, ожидающих обработки в адаптере, продолжает расти, скорее всего, причина низкого быстродействия кроется в сетевом интерфейсе.
Network Interface: Bytes Sent/sec. Отражает число байтов, проходящих через данную сетевую интерфейсную плату за одну секунду.
Server: Bytes Total/sec. Показывает число байтов, отправленных и полученных сервером за одну секунду по сети через все его сетевые интерфейсные платы.
Server: Logon/sec. Число предпринимаемых за одну секунду попыток регистрации, включая локальную проверку прав доступа, а также аутентификацию учетных записей служб и пользователей по сети. Если активизировать такие счетчики на контроллерах доменов (DC), можно получить полезную информацию об объеме данных, проходящих проверку на достоверность в процессе регистрации.
Server: Logon Total. Общее число попыток регистрации, предпринятых за время, прошедшее с момента последнего запуска компьютера, включая локальную проверку прав доступа, а также аутентификацию учетных записей служб и пользователей сети.
Если анализ показал, что слабым звеном в системе является сетевой интерфейс, можно действовать по-разному. Так, можно попробовать связать сетевой адаптер только с теми протоколами, которые используются в данное время; установить на сетевых адаптерах новейшие версии драйверов; заменить сами адаптеры на более современные; наконец, установить дополнительные адаптеры и разбить сеть на сегменты (что позволит изолировать трафик, поступающий на интересующие сегменты). Дабы убедиться, что причины низкой производительности кроются в сетевом компоненте, следует проверить общую пропускную способность сети и заменить недостаточно эффективные компоненты физического уровня (коммутаторы, концентраторы). Можно поискать решение и в другом направлении - распределить вычислительную нагрузку по большему числу серверов.
В сети TCP/IP администратор может попытаться повысить производительность за счет увеличения размеров окна TCP. Размер окна приема (данных по протоколу) TCP/IP отражает объем полученных данных (в байтах), которые в каждый момент могут помещаться в буфер, созданный системой для какого-либо соединения. В NT размер окна фиксированный; по умолчанию для сетей Ethernet он составляет 8760 байт, однако в системном реестре можно задать и другой размер окна. Сделать это можно, или задав другое значение раздела HKEY_LOCAL_MACHINESYSTEM CurrentcontrolSetServicesTcpip ParametersTcpWindowSize и изменив эту установку для всей системы, или воспользовавшись вызовом Windows Sockets setsockopt(), для изменения конкретного сокета. Оптимальный размер окна зависит от архитектуры сети. В сетях TCP максимальная пропускная способность выражается числом, получаемым при делении размера окна на величину задержки, связанной с подтверждением приема, или на величину сетевой задержки.
И последнее замечание по сетевым адаптерам. Не следует использовать их в режиме Autosense (автоматического распознавания режима работы сети 10/100 Мбит/c). Настраивайте сетевые интерфейсные платы на точное значение быстродействия - на то, которое нужно получить. Изменять этот параметр следует с помощью программы конфигурации, поставляемой с сетевым адаптером.
Знай свою среду
Для анализа факторов производительности требуется способность логически мыслить. Но, кроме того, нужны статистические данные, получаемые опытным путем, и немалое терпение. Корректируя производительность корпоративных систем, администраторы вполне могут полагаться на главные средства контроля и оптимизации, поставляемые с NT.
Ключ к успеху - ясное представление о своем сетевом хозяйстве и понимание того, как функционируют прикладные программы и как служащие пользуются ресурсами сети. Для успешного решения проблем, связанных со снижением производительности системы, а также составления планов с учетом требований, которые будут предъявляться к системе в дальнейшем, я рекомендую опираться на информацию, предоставляемую описанными выше инструментами, и на знание используемых в организации прикладных программ и вычислительной среды.
Крис Бенсон - независимый автор, пишущий на темы построения крупных сетей предприятий и глобальных сетей, а также о работе систем хранения. Имеет сертификаты MCSE и CNE. С ним можно связаться по адресу: cbanson@itref.com