В частности, нет большого смысла в попытках мультипрограммирования решета Эратосфена, поскольку в нем натуральный ряд отбирается постепенным отсеиванием составных чисел. Или, например, алгоритм определения некоторого числа из ряда Фибоначчи не удастся сделать многопоточным, так как каждый последующий член ряда равен сумме двух предыдущих, а значит, надо шаг за шагом определять весь ряд. Да и ни к чему «параллелить» алгоритм определения факториала (n!=1·2·3·...·n), поскольку факториал числа 65 вычисляется за считаные миллисекунды, а подсчитать факториал большего числа уже проблематично, ведь разрядность целочисленных переменных в компиляторах имеет свои ограничения (например, переменная типа ulong является беззнаковым целым от 0 до 18446744073709551615).
Тем не менее если включить фантазию и представить себя студентом, который должен решить три перечисленные задачи в одном алгоритме, то возможны любопытные варианты.
Так, талантливый студент XX в. написал бы классический последовательный код, в общих чертах похожий на наше решение, приведенное на «Мир ПК-диске» в листинге 1 (на языке C# ). В этом решении из тела программы в строгой последовательности вызываются основные функции: Number (для нахождения максимального простого числа в определенном диапазоне от 1 до nNum), Fibonacci (для определения члена под номером nFib из ряда Фибоначчи) и Factorial (для вычисления факториала числа nFac), которые проводят соответствующие вычисления для целочисленных аргументов nNum, nFib, nFac. По умолчанию nNum = 200 000, nFib = 500 000 000, nFac = 65, но при желании в исполнительный процесс можно передать другие параметры с помощью строки приглашения (например, вот так: PCW_SingleThreadTest.exe 1000 100 10) — экспериментируйте.
Кстати, в целях наглядности и компактности листинга мы не стали делать так называемую «защиту от идиотов», и поэтому передача в программу символьных переменных (или чисел с плавающей точкой) приведет к предсказуемой ошибке. К тому же не стоит забывать и о пределе значений целочисленных типов.
По пути отметим для пытливых читателей, что функция ToDefineTime является второстепенной в нашем алгоритме и предназначается лишь для наблюдения за «производительностью» кода (с ее помощью засекается время в миллисекундах, затраченное на выполнение ряда поставленных задач).
Итак, после компиляции алгоритма из листинга 1 в системе программирования Microsoft Visual C# 2005 мы получим исполнительный файл PCW_SingleThreadTest.exe (см. листинг и файл на «Мир ПК-диске»). И на двухъядерной платформе (Core 2 Duo E6700, Intel D975XBX, PC2-6400 2×512 Мбайт) эта программа выполняет заложенные вычисления за 1687 мс. Казалось бы, куда быстрее?
Однако гипотетический студент XXI в. может запустить выполнение функций Number, Fibonacci и Factorial параллельно, слегка модифицировав листинг 1. Ведь современный студент знает, что программа на C# может представлять собой набор потоков, каждый из которых выступает объектом класса System.Threading.Thread.
При этом в пространстве имен System.Threading важно выделить два метода, позволяющие запускать независимые фрагменты одного алгоритма в отдельных потоках: когда в вычислительную нить передается аргумент и когда в этом нет необходимости. В нашем случае мы передаем потокам thread1, thread2 и thread3 соответствующие переменные nNum, nFib и nFac, для чего используется делегат типа System.Threading.ParameterizedThreadStart (см. листинг 2 на «Мир ПК-диске»). Если же метод в рамках потока будет иметь тип результата void (т.е. отсутствие типа) с пустым списком параметров, тогда создается делегат типа System.Threading.ThreadStart.
Таким образом, основной кусочек листинга 1 (однопоточная версия) с последовательным вызовом трех функций:
Number(nNum);
Fibonacci(nFib);
Factorial(nFac);
можно трансформировать в соответствующий фрагмент листинга 2 (трехпоточная версия):
Thread thread1 = new Thread(new ParameterizedThreadStart(Number));
thread1.Start(nNum);
Thread thread2 = new Thread(new ParameterizedThreadStart(Fibonacci));
thread2.Start(nFib);
Thread thread3 = new Thread(new ParameterizedThreadStart(Factorial));
thread3.Start(nFac);
thread1.Join();
thread2.Join();
thread3.Join();
Здесь метод Start запускает отдельную нить вычислений и передает в нее соответствующую переменную, а метод Join ожидает реального завершения указанного потока. Кстати, если бы ставилась гипотетическая задача передать результат вычисления функции Number в функцию Fibonacci в качестве аргумента, то перед запуском нити thread2 возникла бы необходимость дождаться завершения выполнения потока thread1 методом thread1.Join(), а уж затем запускать thread2.
Следует заметить, что метод Thread.Join является перегруженным, и факультативная переменная типа Int32 задавала бы время ожидания в миллисекундах. Так, метод thread3.Join(5000) ждал бы завершения потока в течение 5 с, после чего можно было бы форсировать завершение вычислительной нити thread3 методом thread3.Abort(), не дожидаясь вывода результатов.
Но не будем в рамках статьи стараться поведать обо всех возможностях мультипрограммирования. Тем более что в языке C# отдельный поток может находиться в одном из следующих состояний (определяемом свойством Thread.ThreadState): незапущенный (Unstarted), исполнение (Running), ожидание (WaitSleepJoin), приостановленный (Suspended), прерванный (Aborted), завершенный (Stopped), — каждое из которых характеризуется своими методами, и детальную информацию о них (и не только) следует искать в удобной системе помощи Microsoft Visual Studio 2005.


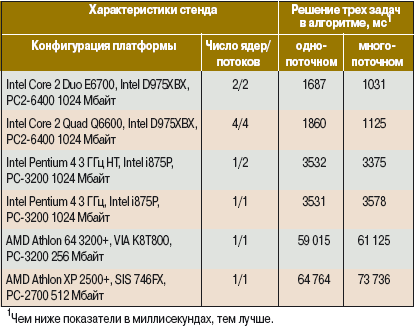
Мы же вернемся к компиляции листинга 2, в результате которой получается файл PCW_MultiThreadTest.exe (см. листинг и файл на «Мир ПК-диске»). И если запустить эту программу на двухъядерной платформе (Core 2 Duo E6700, Intel D975XBX, PC2-6400 2×512 Мбайт), то становится очевидным выигрыш от многопоточной реализации нашего алгоритма — 1031 мс вместо 1687.
Взглянув на экран, где выводятся результаты программы, можно догадаться, что быстрее всего со своей задачей справляется функция Fibonacci, а самым ресурсоемким фрагментом алгоритма является решето Эратосфена. Причем за время работы решета (thread1) без видимых сложностей успевают запуститься и увенчаться успехом потоки 2 и 3.
Таким образом, потратив дополнительное время на небольшую модернизацию классического последовательного алгоритма, можно значительно увеличить эффективность его исполнения. И не стоит думать, что наши выводы далеки от практики. Например, в алгоритме работы востребованного архиватора (либо другой вариант — антивируса) можно организовать отдельные вычислительные потоки для каждого файла из выбранной для архивации (проверки на вирусы) папки. Если же пользователь пожелает сжать один большой файл, то можно разбить его на части и затем все их подвергнуть архивации в параллельных потоках. Разумеется, при разном количестве отдельных нитей будет меняться степень сжатия упомянутого файла, но в большинстве случаев можно будет достичь и высокой скорости выполнения задачи, и нужного уменьшения первоначального объема.
Однако в процессе эффективной реализации технологий мультипрограммирования огорчают два момента. Во-первых, разработка сложного программного обеспечения подразумевает высокотехнологичные решения вопросов согласования работы вычислительных нитей и корректной передачи данных из одного потока в другой (например, с помощью методов класса System.Threading.Monitor). А во-вторых, распараллеленный код программного приложения скорее всего приведет к падению производительности на устаревших компьютерах с одноядерными процессорами.
Давайте изучим таблицу результатов запуска нашего алгоритма на разных платформах — налицо регресс продуктивности многопоточной версии в отдельных конфигурациях трехлетней давности. А значит, в тексте идеальной программы потребуется еще и обращение к классам WMI (Windows Management Instrumentation — инструментарий управления ОС Windows) в пространстве имен System.Management, чтобы определить количество логических процессоров в системе и на основании их числа применить тот или иной способ решения поставленных задач.
Например, вот этим кусочком кода можно определить число ЦП (i):
WqlObjectQuery queryCPU = new WqlObjectQuery(“Select * from Win32_Processor“);
ManagementObjectSearcher findCPU = new ManagementObjectSearcher(queryCPU);
foreach (ManagementObject mo in findCPU.Get())
{
++i;
}
И все эти тонкости современного программирования позволяют нам полагать, что многопоточность становится востребованной, если это не просто модная конструкция программного кода, а хорошо продуманный алгоритм, обеспечивающий эффективное исполнение задач как на одноядерных платформах, так и на многоядерных компьютерах.
Полный вариант статьи см. на «Мир ПК-диске».
Позвольте напомнить
Решето Эратосфена — метод, разработанный Эратосфеном и позволяющий отсеивать составные числа из натурального ряда. Сущность его заключается в следующем.
Зачеркивается единица. Число 2 — простое. Зачеркиваются все натуральные числа, делящиеся на 2. Число 3 — первое незачеркнутое число — будет простым. Далее зачеркиваем все натуральные числа, которые делятся на 3. Число 5 — следующее незачеркнутое число — будет простым. И так можно продолжать до бесконечности.
Числа Фибоначчи — это элементы числовой последовательности 1, 1, 2, 3, 5, 8, 13... , в которой каждый последующий член равен сумме двух предыдущих, а сама эта последовательность называется рядом Фибоначчи. Таким образом, число Фибоначчи можно вычислить по формуле Fibonacci(n) = Fibonacci(n-2) + Fibonacci(n-1). Например, 7-е число из ряда Фибоначчи соответствует Fibonacci(7) = Fibonacci(5) + Fibonacci(6) = 5 + 8 = 13.
Факториал — это произведение натуральных чисел от единицы до какого-либо данного натурального числа n (т. е. 1·2·3·...·n), обозначается «n!». Например, 7! = 1·2·3·4·5·6·7 = 5040.
Далеко ходить не надо
Внимательные читатели могли заметить, что компьютерный диск журнала «Мир ПК» в последнее время претерпел значительные изменения. Причем модернизация нашего электронного приложения коснулась не только внешнего вида, но и алгоритма поисковой оболочки, который разрабатывался компанией «Стокона» (http://www.stocona.ru/).
Теперь отображение диска очень быстро появляется на экране, и пользователь может сразу приступать к работе. Однако по индикаторам работы жесткого диска можно догадаться, что программная оболочка не перешла целиком и полностью в режим ожидания ввода команд читателя, а продолжает выполнять какую-то работу в параллельном режиме. Неужели многопоточность оказалась рядом с нами?
И вот что по этому вопросу разъяснил нам один из разработчиков системы Богдан Гаркушин:
— Проблема, с которой столкнулись разработчики компании «Стокона», — это обеспечение быстрой загрузки содержания журнала и быстрого поиска информации. Поскольку процесс подготовки поиска является более длительным, то его целесообразнее выделять в отдельный поток и запускать параллельно с загрузкой содержания журнала. И это позволяет значительно сократить время ожидания основной информации.
Таким образом, основной поток загружает статьи журнала и сразу предоставляет их пользователю для чтения. Тем временем вспомогательная нить выполняет подготовку данных для поиска: загружает словарные базы, тематические словари, а также кэширует нужные файлы. И только по окончании работы вспомогательного потока в основной нити появляется возможность выполнения всех поисковых функций.
Кстати, для пользователя сигналом о полной загрузке всех служб служит остановка вращения логотипа компании «Стокона» в правом верхнем углу интерфейса, а не состояние индикаторов жесткого диска .
Обычно предварительная загрузка данных занимает около минуты. Поэтому если выполнять ее в основном потоке, то время отображения оболочки при запуске значительно увеличится. А ведь для отображения информации и навигации по файлам «Мир ПК-диска» достаточно загрузки программы Acrobat Reader, и эта операция сама по себе должна выполняться очень быстро. И только когда пользователь начинает спокойно читать журнал, оболочка инициирует довольно трудоемкую операцию загрузки вспомогательных данных в оперативную память. Так что не каждый читатель заметит нужную работу, выполняемую вторым потоком.
Результаты выполнения компиляций