
- Вы действительно можете набирать текст со скоростью 600 символов в минуту?
- Да! Но такая ерунда получается...
Анекдот
Часто ли вам приходится заполнять формы на веб-страницах? Сейчас практически любое полезное действие в Интернете сопровождается тем, что вам предлагают зарегистрироваться и предоставить некоторые персональные данные. Одни формы ограничиваются логином и паролем, а в другие приходится дополнительно вносить свои ФИО, телефон, адрес, e-mail, дату рождения и т.д.
Проблема «мусорных» данных
Пользователи, напуганные тоннами спама и новостями об утечках баз данных, стараются сообщать о себе как можно меньше сведений. Кое-кто предпочитает вообще не оставлять никакой информации, чтобы его нельзя было идентифицировать в реальном мире. Кроме стремления к приватности есть еще желание сократить время заполнения форм, особенно если предоставляемая информация не дает в краткосрочной перспективе никаких значимых бенефитов.
В то же время регистрационные формы — дешевый и популярный способ получить сведения о посетителях сайта: сегментировать их, изучить с точки зрения возрастного и гендерного состава, географического распределения, чтобы с учетом этого скорректировать маркетинговую направленность. В идеале же можно будет данную информацию анализировать и применять вплоть до интеграции в CRM-системы и системы обратной связи с пользователями с помощью почты или звонков. Таким образом удастся выстроить вокруг своих продуктов или услуг сообщество и эффективно с ним взаимодействовать. Ведь если человек зарегистрировался на вашем сайте, то вероятность того, что он окажется заинтересованным лицом или потенциальным покупателем, очень велика. Тогда возможность наладить с ним двусторонний контакт трудно переоценить.
А чтобы побудить пользователей вводить контактные данные, многие делают важные поля обязательными для заполнения, обычно помечая их звездочкой (*). Это и является основной причиной образования двух видов «мусора» (рис. 1): первого — вводимого для обеспечения приватности; второго — для экономии времени.
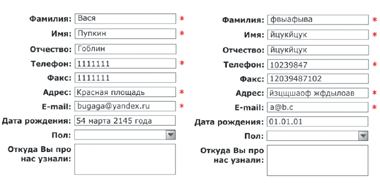
|
| Рис. 1. Типовые «мусорные» данные при заполнении регистрационных форм с обязательными полями. «Мусор», вводимый для соблюдения приватности (слева), и «мусор», вводимый для экономии времени (справа) |
Методы защиты от «мусорных» данных
Собранные «мусорные» сведения не представляют собой никакой ценности для отдела маркетинга, кроме разве что выяснения того, сколько человек заполнили форму. Они также значительно затрудняют маркетинговый анализ, и отдельные техники становятся неприменимыми, что вообще делает сомнительным целесообразность расходов на сбор данных.
Поэтому с «мусором» приходится бороться. И здесь помогут три основных способа.
Выбор значений

|
| Рис. 2. Выбор значений из списка |
Если требуемая информация — элемент относительно небольшого множества, например пол или страна, то выбираемое из списка (или в случае дат из календаря) значение обеспечивает защиту лишь от «мусора» второго вида, и не дает защиты от первого вида, когда преднамеренно сообщается неверная информация (рис. 2).
Проверка информации
При отсылке формы на сервер происходит проверка информации. Если значение какого-либо поля заведомо неверное, то форма возвращается пользователю с просьбой исправить данные. Вариацией данного способа будет проверка адреса e-mail путем отправки на него подтверждения регистрации. Однако в реальности удается осуществить осмысленную проверку только e-mail, дат и некоторых числовых данных. А наиболее ценная информация — контактные данные (ФИО, адреса, телефоны) — так и остается непроверенной. Кроме того, даже при строгой проверке все равно остаются варианты фальсификации и значительно снижается возможность отсечь реальные данные от угаданных при последующей обработке.
Рассмотрение первых двух способов приводит к неожиданному выводу: нужно убрать из регистрационных веб-форм все проверки вводимых данных и выпадающие списки. Если пользователь решил не сообщать о себе информацию, он все равно может вас обмануть. И лишь когда он будет вводить все сам и когда его не будут ругать, вероятность идентифицировать это нежелание будет значительно выше.

|
| Рис. 3. Если значение поля не выбирается из списка, пользователю должна быть дана подсказка о том, какие данные от него ожидаются. В рассматриваемом примере нужно включить «30.07.1980» в кандидаты на «мусор», поскольку есть большой соблазн указать именно эту дату, скопировав ее в поле через буфер обмена |
Если же вводимые данные не проверяются, около каждого поля должна быть краткая и четкая инструкция относительно того, что и в какой форме ожидается (рис. 3). В ином случае появляется риск получить некорректные сведения, поскольку пользователь не всегда понимает, что от него требуется.
«Мусорный» фильтр
«Мусорный» фильтр работает следующим образом. Получив данные, он проверяет, может ли указанная информация в принципе быть правильной. Если да, то она попадает в базу, а если это «мусор», то фильтр тяжело вздыхает и удаляет его, а форма также попадает в базу, но вместо текста в ней будут содержаться пустые строки или специальное значение, имеющее смысл «нет данных» (обычно программисты в таких случаях используют NULL). Причем пользователю даже не сообщается о том, что его данные проигнорированы. Он остается в счастливом неведении, но зато не испортил базу. Уже за одно это можно позволить ему сделать то, ради чего, собственно, он заполнял форму. Если, конечно, такое в принципе возможно — например, когда ему по указанному адресу должны что-то прислать, то просто «не заметить» адрес будет неправильно.
Судя по всему, для регистрационных форм в Интернете «мусорные» фильтры будут наиболее приемлемым решением, если, конечно, вы собираетесь каким-либо образом использовать собранную информацию. Только они повышают вероятность того, что те немногие данные, которые удалось собрать, окажутся сколько-нибудь полезны. И потому расскажем о них более подробно.
Семантическая интерпретация данных
Лучшим способом понять, являются ли данные «мусором», будет попытка каким-либо образом их интерпретировать. Например, в случае с телефоном имеет смысл выделить код города, узнать, существует ли он, проверить, удовлетворяет ли количество цифр системе нумерации, принятой в регионе, определяемом этим кодом города, и т.д. То же самое желательно проделать с ФИО и адресами. Несмотря на кажущуюся простоту задачи, подобные алгоритмы и справочники разрабатываются годами и требуют постоянного обновления и настройки под сведения. Так что если вы всерьез озабочены качеством своих данных, то лучше поищите готовые решения на открытом рынке и подключите их — либо установив на сервер и проинтегрировав с формами ввода, либо по модели SOA№ — перенаправляя информацию на сервер поставщика решения по очистке данных.
При этом должны быть учтены два очевидных и очень важных аспекта, связанных с природой набора на клавиатуре:
- практически все люди делают ошибки и опечатки;
- набирать "абракадабру" значительно быстрее, чем осмысленный текст.
Сравнение на похожесть
При проверке данных опечатки заставляют отказываться от сравнения на абсолютное равенство, используя вместо него сравнение на похожесть. Похожесть — комплексное понятие, включающее в себя подсчет количества совпадающих и несовпадающих букв, фонетическую и семантическую близость и т.п. В качестве примера фонетической близости можно привести слово «исчо», не содержащее ни одной правильной буквы, но в то же время звучащее так же, как «еще», а семантическую близость можно представить именем «Вова», интерпретируемым как «Владимир», или словом «столица», интерпретируемым как «495» или «Москва».
Транслитерация
Масла в огонь добавляет транслитерация — napisanie russkih slov latinskimi bukvami. Поскольку различных схем транслитерации очень много, обратная транслитерация, т.е. преобразование латинских букв в русские, неоднозначна. Так, латинская «y» при транслитерации может превращаться в «и», «й», «ы» и даже «у», и значит, при обратной транслитерации практически всегда будут внесены искажения на уровне букв, что можно исправить только при сравнении на похожесть.
Клавиатура
Теперь про расположение клавиш. Когда человеку нужно очень быстро набрать какое-то количество текста, то он, как правило, беспорядочно барабанит пальцами по клавишам. Поскольку они расположены не в алфавитном порядке и не в порядке частоты их соседнего расположения в русском языке, набираемое на клавиатуре случайным образом отличается от набираемого специально (даже с опечатками) наличием недопустимых сочетаний букв, характерными шаблонами повторов и их вариаций и проч.
Семантика «мусора»
Когда «честный» алгоритм проверки значений получает строку «вер» в качестве имени, то он вполне легитимно интерпретирует ее как «Вера». Но если мы знаем, что этот «вер» получился обратной транслитерацией из «wer», то скорее всего он был набран на клавиатуре произвольно, поскольку клавиши W, E и R расположены рядом, и поэтому больше похож на «мусор», чем на «Веру». Значит, даже в случае «честной» проверки необходима идентификация полученной информации.
Человечный и бесчеловечный «мусор»
Как ни странно, идентификация «мусора» в текстовых данных практически не рассматривается в профильной литературе по обеспечению качества информации, хотя тема, безусловно, важная и достойная внимания. Начнем разговор с рассмотрения «мусора» первого вида — «Микки Маусов» и «Вась Пупкиных», т.е. заведомо искаженной информации. Однако сначала стоит обратить внимание на «мусор» еще одного вида: осмысленный текст, набранный на клавиатуре другой раскладки, например «цццю» вместо www. Такая проблема решается просто путем трансформации каждого символа из одной раскладки в другую.
Человечный «мусор». Как показывает практика, если есть преднамеренное искажение информации хотя бы в одном поле, вероятность того, что то же самое происходит и во всех остальных, очень высока и даже может считаться правилом. Исключение составляет, пожалуй, только номер телефона, зачастую оказывающийся искаженным при сохранении остальных полей «похожими на правду».
Кажется очевидным, что видов такого «мусора» бесконечно много, но это ошибочное впечатление. Практика показывает, что фантазии пользователей хватает лишь на ограниченное количество искажений, и поэтому вполне достаточно создать их словарь, поиск по которому должен вестись с учетом возможных опечаток и транслитераций. К фаворитам человечного «мусора» относятся строки «нет», «не знаю», «не скажу» и несколько сотен вымышленных, но в то же время хорошо известных персонажей — «Вася Пупкин», «Микки Маус», «Гоблин» и т.д. Конечно, иногда будет проскакивать что-то новенькое, но после составления объемного справочника таких случаев будет пренебрежимо мало.
Бесчеловечный «мусор». Это «мусор» второго вида, например «фывафыва» и прочее, т.е. «мусорные» данные, полученные случайными нажатиями на клавиатуру. При идентификации подобного «мусора» наблюдалось следующее:
- нажатия на самом деле не совсем случайные;
- множество случайно составленных последовательностей из русских (или английских) букв значительно превышает множество всех осмысленных слов.
Нажатия «не совсем случайные» бывают по нескольким причинам.
Во-первых, клавиши расположены на клавиатуре стандартно, а руки каждого человека вполне определенных размеров.
Во-вторых, цель случайных нажатий состоит в том, чтобы сэкономить время, а совершенно случайные нажатия выполнять не проще, чем набирать осмысленный текст. Поэтому то, что набирается случайными нажатиями, набирается по определенной системе, что позволяет определить текст, набранный таким способом.
А вот имена, фамилии, отчества, адреса и прочая осмысленная информация обладают своими свойствами. Эти слова произносимы вслух, и здесь существуют грамматические ограничения: например, после гласной не может стоять мягкий знак. Это также позволяет для каждого вида данных обнаружить систему в допустимых значениях.
Таким образом, подход состоит в том, чтобы найти общее и различия между значениями двух классов — «мусора» и осмысленного. Потом по этим признакам любую строку можно с некоторой долей вероятности отнести к какому-либо классу.
Казалось бы, проще всего проанализировать характерные особенности осмысленного текста. Нужно взять базу данных по всем возможным экземплярам осмысленного текста определенного типа (например, по адресам) и искать, что в них общее и что различное. Для этого используется достаточно широкий спектр средств математической статистики и инструментов data mining, а также прямые переборы множества вариантов, что требует неимоверной вычислительной емкости. Применение такого некрасивого средства, как перебор, вызвано необходимостью учета опечаток.
Учет опечаток
Любая опечатка может превратить слово в «мусор». Например, если вы вместо букв «б» или «т» попадете в «ь» и окажется, что он стоит после гласной буквы, то полученное слово будет гарантированно определено как «мусор», поскольку в осмысленном тексте такого сочетания не может быть никогда. Хотя в действительности слово «хорошее», просто с опечаткой. А люди довольно часто ошибаются.
Поэтому правильным подходом будет выявление таких «мусорных» и «хороших» подстрок, которые остаются без изменений, даже если в них есть опечатки. И эти ошибки в наборе должны ранжироваться согласно вероятности их встречаемости. Например, люди, печатающие слепым десятипальцевым методом, зачастую ошибаются из-за того, что вместо одной руки срабатывает другая, нажимая клавишу, которая симметрична нужной относительно центра клавиатуры. Остальные, как правило, просто промахиваются, нажимая соседние клавиши. Есть еще несколько типовых профилей опечаток, но это уже тема для отдельной статьи.
Создание словарей таких подстрок — дело не очень сложное, но трудоемкое, кропотливое и занимающее много времени вследствие необходимости калибровки на статистически значимых массивах «мусорных» и «немусорных» образцов. Результаты таких работ целесообразнее приобрести у поставщиков решений по обеспечению качества данных.
Стоит отметить, что количество «мусорных» (с точностью до опечаток) подстрок для русских данных в несколько раз больше, нежели для транслитерированных. Основная причина этого — наличие множества различных схем транслитерации, благодаря чему бессмысленных комбинаций становится меньше. Разумеется, это значительно снижает вероятность обнаружения «мусора» таким методом, и потому, если возможно, требуйте заполнения форм русскими буквами.
Анализ клавиатурных последовательностей
Теперь перейдем к анализу «мусора». Здесь все еще проще — даже опечаток нет, поскольку весь «мусор» и есть одна большая опечатка. Но сложность заключается в том, что создать справочник случайных клавиатурных нажатий не удастся. Даже если вы большой компанией будете в течение месяца долбить по клавиатуре, то скорее всего не соберете и малой доли встречающихся в реальной жизни случаев, хотя созданная вами начальная база для анализа будет очень ценной.
Более правильным будет такой подход, при котором создается математическая модель процесса случайного набора на клавиатуре. Предлагаю два основных подхода. Первый построен на предположении о том, что целью случайного набора является экономия энергии за счет движений, более свойственных кисти руки. Он связан с построением физической модели процесса. При втором подходе выявляются шаблоны в последовательностях расстояний между клавишами, соответствующими буквам. Целесообразно объединить оба подхода и добавить к ним измерения времени между соседними нажатиями.
* * *
Чтобы аналитическая составляющая маркетинга, CRM и других базовых механизмов предприятия приносила пользу, ей необходимы «чистые» стандартизованные данные. Собранные же с помощью ручного ввода таковыми не являются. Одна из главных задач, решение которой поможет оперировать более объективной информацией и принимать более правильные решения, — задача идентификации «мусора», рассмотренная в данной статье. Она лежит на стыке маркетинга, программирования, математического моделирования и психологии, и именно из-за такого коктейля из разнородных знаний ее зачастую оставляют «на потом». К счастью, многие компоненты, необходимые для решения этой задачи, уже есть. Они перешли из области науки в область отлаженной технологии и потому могут быть развернуты в рамках адекватных временных и бюджетных затрат. Это значительный прорыв технологии в сторону маркетинга и бизнеса, поскольку всем очевидно: плохие данные — плохой бизнес.
О конкретных программных решениях для фильтрации «мусорных» данных читайте в следующем номере журнала.
Об авторе
Дмитрий Журавлев — директор Humanfactorlabs, e-mail: dmitryzh@hflabs.ru.
№ Service-Oriented Architecture — сервисно-ориентированная архитектура, или методология построения информационных систем.