команд, в интерфейсах, соединяющих компоненты ПК, наблюдается ярко выраженный переход на последовательное выполнение инструкций. Но на самом деле все это звенья одной цепи.
PCI Express

|
| Джим Паппас — «крестный отец» USB |
Как метко подметил «крестный отец» USB Джим Паппас1, «чтобы сделать любую шину, нужны кремний и медь. Медь дорога, а кремний со временем «умнеет», поэтому может взять на себя все больше функций». Так, еще в 1992 г., когда ISA стало не хватать пропускной способности, чтобы передавать видеоданные в новую операционную систему Windows, при разработке шины PCI было предложено сделать ее последовательной. В результате удалось бы сэкономить медь, так как по одному каналу передавалась бы вся информация о состоянии битов во всех 32 разрядах. Однако тогда кремний был недостаточно «умен» и не мог справиться с необходимыми скоростями передачи данных (частота шины составила бы 1 ГГц вместо 33 МГц. — Прим. ред.). Шину PCI пришлось сделать параллельной. Но уже при разработке PCI Express сомнений не возникало: она должна быть последовательной. В результате для передачи информации требуется только один канал с частотой 2,5 ГГц, что позволяет передавать информацию со скоростью 250 Мбайт/с в каждом направлении (суммарная пропускная способность 500 Мбайт/c). Для расширения возможностей шины современные наборы микросхем поддерживают многоканальные линии. Так, для графических плат предусмотрены 16-канальные решения (суммарная пропускная способность 8 Гбайт/с). Отличие многоканальных последовательных линий от параллельных многоразрядных заключается в том, что информация по ним может передаваться как параллельно (с последующей сборкой в точке приема), так и в несколько потоков одновременно — если очень упростить ситуацию, то можно два файла перекачивать одновременно по разным линиям одного и того же соединения.
Про последовательные соединения USB и FireWire мы уже писали (см. «Мир ПК», №11/2000, с. 10 и №4/01, с. 10). Сейчас они полностью вытеснили периферию с LPT- и СОМ-портами, исключение составляют только некоторые измерительные системы, для которых переписывание ПО — очень непростое дело (дорого, да и ошибок можно насажать). Конечно, наибольшее развитие получила шина USB. Ее поддержку Intel включает во все свои наборы микросхем, начиная с i430. А незадолго до появления PCI Express мы получили еще и последовательную шину для жестких дисков Serial ATA. Более того, последовательные протоколы освоили не только технологии для персональных компьютеров, но и предназначенные для серверов и систем хранения. Очередь за памятью.
Память FB-DIMM
Так что же с памятью? Напомним, что о планах по внедрению стандарта FB-DIMM мы узнали от компании Intel на весеннем IDF-2005 (см. «Мир ПК», №4/05, с. 54). Теперь удалось прояснить сроки выпуска и назначение этой памяти. Хотя постоянно говорилось, что она появится в 2007 г., ее поддержка была анонсирована в некоторых платформах, которые намечены к запуску в производство в 2006 г. Джим Паппас пояснил, что планируется применять ее в серверах. Стало понятно, что поддержка этой памяти будет реализована в системах заранее, чтобы трепетные корпоративные клиенты могли решить, стоит ли на нее переходить. А сам стандарт как таковой уже готов. Первоначально FB-DIMM разработали Intel и IBM, а затем передали на доработку и утверждение в JEDEC. Так что на этот раз стандарт будет общедоступным и история с Rambus, когда одна компания воспользовалась покровительством Intel и объявила себя чуть ли не изобретателем оперативной памяти, заставив всю ИТ-индустрию платить лицензионные отчисления, не повторится.
Необходимость в памяти нового типа возникла в связи со стремительным сокращением количества модулей, которые можно посадить на один контроллер северного моста. При увеличении тактовой частоты памяти эта цифра пропорционально снижалась: для небуферизованных 100-МГц SDRAM она составляла восемь модулей на канал, для регистровой 200-МГц DDR — четыре модуля, для 400-МГц DDR2 — всего два модуля, а в регистровой 800-МГц DDR3 максимум равен минимуму — один модуль, «меньше просто не было смысла». Конечные пользователи находятся в лучшем положении, так как им не требуется очень большое ОЗУ, к тому же в стандартных ПК обычно устанавливают небуферизованные модули. А вот при использовании 800-МГц FB-DIMM в серверах число модулей на контроллер возрастет опять до восьми. Потенциально на системной плате, поддерживающей шести каналов памяти, можно будет установить 48 (!) модулей памяти общим объемом 192 Гбайт. Мне, честно говоря, сложно представить такую плату, утыканную, модулями, как ежик иголками, но подобный сервер будет иметь большее преимущество перед кластерами, позволяющими получить любой объем памяти, соединив нужное количество ПК. Он будет обладать единым полем памяти, что принципиально важно для определенного класса задач, в которых данные нельзя разделить между независимыми компьютерами, так как каждый процессор может затребовать информацию из любой области памяти.
Немного перефразируя Ленина, скажу, что ошибаются все, кто работает, поэтому и большие компании наступают на грабли. И потом об этом все помнят очень долго, потому что именно огромные корпорации, продвигающие вперед индустрию ИТ, способны завести ее в тупиковое ответвление научно-технического прогресса. Посему, опять вспомнив о Rambus, замечу, что цена модулей FB-DIMM не должна сильно отличаться от стоимости регистровой DDR2. Они имеют одинаковый формфактор, но электрически не совместимы: ключ будет разным, чтобы в разъемы для одних модулей нельзя было установить другие. И более того, в FB-DIMM использованы микросхемы обычной DDR2. В чем же разница? Память нового типа имеет не регистр, а буфер (точнее, «полный буфер», теперь с этим словом надо обращаться аккуратнее), где хранятся не только данные об адресации памяти и контрольной линии, но и использованные данные. Так что по себестоимости они не будут сильно отличаться от регистровой памяти.
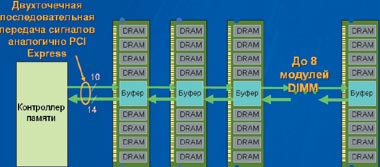
|
| Организация ОЗУ на базе модулей FB-DIMM |
Благодаря новому типу буферизации модули FB-DIMM можно подключать цепочкой друг за другом, так как на каждом буфере установлены два порта: один — для соединения с контроллером (или предыдущим модулем), второй — для подключения к следующему DIMM. Буферная микросхема, получив сигнал, разбирается, то ли он пришел ей, то ли его надо передать дальше по цепочке. В принципе можно было бы подключать по цепочке и больше восьми модулей, но при добавлении каждого из них накапливается задержка в передаче сигнала, и к тому же свои ограничения накладывают электрические характеристики такой цепочки. Кстати, по словам Паппаса, задержка в цепочке даже из восьми модулей будет главным образом определяться не тем, насколько модуль далек от контроллера, а временем на считывание или запись информации в конкретные ячейки данного модуля. Так что и для памяти последовательные соединения демонстрируют свое преимущество перед параллельным подключением. Может быть, в будущем дело дойдет и до последовательного подключения ячеек памяти в модуле?
Для FB-DIMM используются 10 нисходящих линий (от контроллера к модулям) и 14 восходящих (в обратном направлении). Такое распределение обусловлено тем, что для считывания требуется вдвое большее число линий, чем для записи, но для последней часть пропускной способности также используется для передачи адресов, с которых будет производиться копирование.
Если на современную системную плату для сервера поставить память FB-DIMM (конечно, умозрительно, так как придется еще и заменять набор микросхем), то поддерживаемый объем ОЗУ увеличится в 4 раза (так как поддерживается до восьми модулей FB-DIMM на каждый контроллер, а модулей DDR2 — только два). Следовательно, и число контактов, необходимых для разводки разъемов и поддерживающих одинаковое количество памяти, уменьшится примерно с 240 до 70. Пропускная способность системной памяти увеличится на 33%: 6,7 Гбит/с для FB-DIMM против 5 Гбит/с для 667-МГц DDR2 (здесь, впрочем, у DDR2 есть еще перспективы роста тактовой частоты). Также следует отметить возможность определения ошибок и повторной передачи ошибочных пакетов (передача данных последовательная, в пакетах, кодирование избыточное, так что легко обнаружить и выбросить сбойный пакет, запросив его заново). Кроме того, предусмотрены механизмы обхода «дорожки бит» и исключения из работы сбойных участков буфера.
Нельзя сказать, что все совершенно безоблачно. Ожидается, что при небольших потоках данных задержка FB-DIMM будет превосходить аналогичный показатель у DDR2 (и тут призрак RDRAM!). Да и энергопотребление будет выше, чем у существующих модулей памяти, поэтому для FB-DIMM необходим радиатор (а эту проблему, думаю, можно будет решить за счет перехода на более «мелкие» техпроцессы). Видимо, в следующем году мы познакомимся с интересным конкурентом памяти DDR3, и как знать, может, только одна из них выживет к 2007 г.
Так почему же процессоры обрабатывают информацию параллельно, а интерфейсы последовательно? А потому, что так быстрее! И все, нет панацеи, нет универсального решения, даже критериев больше нет, за исключением, конечно, приемлемой цены. Ядро обрабатывает информацию быстрее, чем получает? Подведем к нему две цепочки данных. А если оно не справляется с их обработкой, сделаем два ядра. А вот передавать информацию оказывается быстрее последовательно, не теряя время на распараллеливание пакетов отправителем и их сборку получателем. Значит, так и сделаем. Быстрого вам компьютера и интересной работы!
В статье использована информация по разработкам компаний Intel, Samsung и организации JEDEC.
Вездесущая PCI Express
Интересно, что PCI Express скорее всего окажется основой для других последовательных соединений SATA и Ethernet (для всех вычислительных систем), а также для SAS, Fiber Channel iSCSI и InfiniBand (для серверов и систем хранения данных). В принципе и сама PCI Express может быть использована не только для внутрисистемных соединений, но для подключения внешних устройств. В группе PCI SIG есть отдельная подгруппа, занимающаяся такими решениями, но пока производители не рады этому предложению, поскольку им надо окупить собственные затраты на InfiniBand и Fiber Channel. Зато в качестве разъема для карты расширения PCI Express потенциально выгоднее. Так, по данным Intel, в 3 раза повышается производительность плат InfiniBand по сравнению с аналогами на базе шины PCI-X (этот разъем — дальнейшее развитие PCI, он широко используется в серверах). И хотя у PCI-X есть еще резервы для развития (например, планируется перейти на 266-МГц шину), даже просто установка ее разъема на плату с набором микросхем Intel обходится производителям системных плат дороже, чем установка PCI Express. Это происходит из-за того, что поддержка PCI Express уже встроена в набор микросхем и остается развести только сам разъем. В результате площадь, которую занимают соединения для двух таких разъемов х8, на 53% меньше, чем занимаемая двумя PCI-X и мост между северным мостом набора микросхем и разъемами.
Справедливости ради отметим, что пока не видно плат расширения PCI Express для домашних компьютеров. Но здесь причина тривиальна: все, что может понадобиться пользователю, уже встроено на плату, и широко используются только PCI Express х16 или х8 для видеоплат.
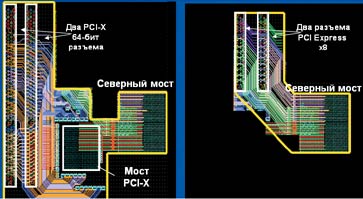
|
| Видно, что на два разъема PCI Express х8 (справа) уйдет меньше меди для соединений, чем на два 64-разрядных PCI-X |
1Ныне Паппас — директор по технологическим инициативам подразделения Digital Enterprise Group (т.е. подразделения «Цифровое предприятие») компании Intel. Он так или иначе участвовал во всех масштабных проектах Intel — от участия в разработке шины PCI до внедрения PCI Express и, конечно, в создании универсальной последовательной шины USB, которая считается его главным детищем.