
В комплект ABBYY FineReader 5 Pro for Mac (129 долл.) помимо дистрибутивного компакт-диска входят подробное руководство пользователя на английском языке и краткое описание на русском, а также лицензионный договор (на английском и русском языках). Для установки программы необходим компьютер Macintosh на базе процессора PowerPC с операционной системой Mac OS 8.6 или выше (в Mac OS X приложение запускается только в программной среде Classic Environment), QuickTime 4.0 или выше, как минимум 32-Мбайт ОЗУ (рекомендуется 64-Мбайт), 100 Мбайт свободного дискового пространства и дисковод CD-ROM. FineReader работает с более чем 30 моделями TWAIN-совместимых сканеров таких компаний, как Acer, Avigramm, Canon, Epson, Hewlett-Packard, Microtek, Mustek, UMAX и др. (полный список можно найти на Web-узле: www.abbyy.com/support/finereadermac/index.htm).
Мастер установки FineReader предельно прост. Пользователю предлагается выбрать вариант установки: Easy Install или Custom Install. Вариант Easy Install устанавливает конфигурацию программы, которая включает в себя наиболее часто используемые языки распознавания (около 30). Custom Install позволяет выбрать только те компоненты, которые действительно необходимы, в частности установить любые из 117 доступных языков распознавания. Такой подход весьма удобен, поскольку дает возможность сэкономить драгоценное дисковое пространство.
Пользовательский интерфейс FineReader 5 Pro for Mac создавался компанией Sound & Vision, Inc., специализирующейся на разработке ПО для Macintosh. Приятно отметить, что ее специалистам удалось, сохранив привычные черты интерфейса FineReader для Windows, привнести в него «дух Macintosh», в том числе характерные для Mac OS панели управления, значки и диалоговые окна, а также поддержку технологий Apple (таких, как QuickTime, Drag-and-Drop, AppleScript, AppleSpeech). Задачей производителей было сделать так, чтобы работа с системой FineReader была для пользователей Macintosh удобной и привычной, и, на наш взгляд, это им вполне удалось.
Организация работы в FineReader
Основой работы FineReader является так называемый пакет (Batch), содержащий всю информацию о распознаваемом документе.
Пакет представляет собой набор страниц документа. Сначала пользователь импортирует в пакет изображения страниц — со сканера или непосредственно из файлов графических форматов.
Импортированные изображения подвергаются графической обработке. Они могут быть инвертированы (если исходное изображение представляет собой негатив), очищены от «мусора» (мелких дефектов изображения), цветные изображения сведены к черно-белым (если цветность не нужна; это существенно экономит место на диске и ускоряет процесс распознавания).
Следующий шаг — анализ макета (Layout) страниц пакета, т. е. выделение областей, подлежащих распознаванию. На этом этапе FineReader анализирует ориентацию страницы (в случае необходимости она будет повернута) и выделяет «блоки» (Block) — области, которые при дальнейшем анализе будут интерпретироваться как текст, который необходимо распознать, как таблицы или рисунки.
После анализа макета страниц, входящих в пакет, проводится собственно распознавание текста и таблиц. Именно технология распознавания обеспечивает уникальность FineReader, однако это «сердце» всего продукта совершенно незаметно пользователю: он видит лишь бегущее по тексту выделение и типовую строку состояния, указывающую, сколько страниц обработано, а сколько осталось.
Следующий этап — проверка правописания. Отметим, что помимо работы со словами, которых нет в словаре системы, «на суд» пользователя выносятся также те символы, в точности распознавания которых программа не уверена.
Завершающий этап работы программы — сохранение и экспорт результатов распознавания. На самом деле собственно в сохранении результатов нет нужды — вся информация, включая распознанный текст и его форматирование, автоматически сохраняется в пакете вместе с исходными изображениями и сведениями о макете страниц. Пользователь может просто закрыть FineReader, не опасаясь потери данных. Однако полученный текст можно удобно экспортировать во множество различных форматов для последующей работы с ним в других приложениях.
Каждый из описанных шагов — импорт изображений, анализ документа и распознавание, проверка орфографии и сохранение результатов — представлен крупной кнопкой в верхней части экрана, что существенно облегчает работу с программой.
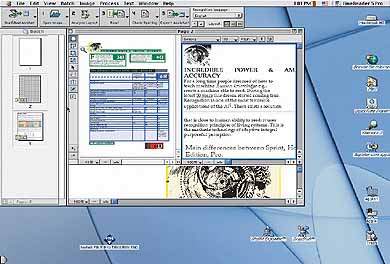
|
| Рабочее окно FineReader for Mac |
Сканирование изображений
«Пусть ваш сканер печатает за вас» — написано на коробке с FineReader. Хорошо. Кладем на стекло сканера лист с текстом и нажимаем кнопку «Сканировать» (Scan).
Совет 1.
Если вы немного удержите нажатой мышь на кнопке, то в выпавшем меню сможете выбрать еще две функции, выполняемые этой кнопкой: сканирование нескольких страниц подряд (Scan Multiple Images) и открытие изображений из файлов (Open Image). Выбранная вами функция окажется теперь «сверху» на самой кнопке. Такое поведение аналогично для всех «больших» кнопок панели управления. Последним пунктом выпадающего меню всегда является вызов диалога Preferences со множеством закладок, группирующих опции удобным образом по функциональности. Вызов пункта меню Preferences у кнопки на панели управления автоматически откроет диалог Preferences на соответствующей закладке, где расположен набор опций для настройки функций данной кнопки. Диалог Preferences также можно вызвать и из стандартного его места расположения в меню Edit.
FineReader взаимодействует со сканером через стандартный драйвер TWAIN (или подключаемые модули Adobe Photoshop — Plug-Ins), что обеспечивает ему совместимость практически со всеми современными сканерами. Поэтому прежде чем начать сканирование, необходимо выбрать источник TWAIN (TWAIN source). Итак, при нажатии на кнопку Scan откроется окно программы сканера, с помощью которой и будет производиться сканирование. Для качественного распознавания необходимо изображение в тонах серого (grayscale) или цветное, с разрешением не менее 300 точек на дюйм. Эти характеристики надо указать программе сканирования.
Еще перед началом сканирования в настройках (Edit?Preferences? Scan/Open Image) можно указать программе инвертировать изображение (Invert image), очищать его от «мусора» (Despeckle image), автоматически определять ориентацию текста на изображении (Detect image orientation, это будет сделано на стадии определения макета), уменьшать разрешение цветного изображения или изображения в оттенках серого (Reduce color and gray image resolution down to 100 dpi; эта опция позволяет сильно уменьшить размер пакета за счет понижения качества файлов изображений, хранимых вместе с ним).
Совет 2.
Будьте внимательны: большинство настроек, связанных с каждым из этапов работы с пакетом (Edit?Preferences...), относятся только к текущему пакету и не распространяются на другие пакеты. Для облегчения переноса настроек из пакета в пакет в FineReader предусмотрена работа с так называемыми шаблонами пакетов (Batch template): вы можете сохранить настройки в специальный файл, а затем загрузить их из него для нового пакета. Эта опция находится на закладке General диалога Preferences.
После завершения сканирования изображение окажется включенным в конец пакета (если не активна опция «запрашивать номер страницы перед добавлением в пакет» — Ask for page number before adding page to the batch на закладке Scan/Open Image диалога Preferences), а его пиктограмма (Thumbnail) отобразится на панели пакета (Batch panel, вертикальная панель слева на экране). Если щелкнуть мышью на этой пиктограмме, можно увидеть все окна FineReader: основное место на экране будет занимать окно изображения и текста (Image and Text Window), в левой части которого расположено изображение нашей страницы, а в правой будет находиться распознанный текст (пока текст не распознан, окно остается пустым). Каждая из этих двух частей главного окна программы снабжена стандартными инструментами управления масштабом, а слева от окна изображения имеется еще и небольшая панель инструментов работы с изображением (Image Tools).
Если присмотреться внимательнее, то на изображении страницы можно увидеть небольшую пунктирную рамку с лупой. Та часть изображения, которая попадает в эту рамку, отображается в окне крупного плана (Zoom Window). Щелчок мыши на определенной части изображения (в окне изображения) переместит центр увеличиваемой области в указанное место.
Выбрав из выпадающего меню на кнопке «Сканировать» пункт «Сканировать несколько страниц», вы можете добавить в пакет несколько страниц сразу, не выходя из программы сканирования вашего сканера, а выбрав пункт «Открыть изображение» — добавить в пакет изображение из файла. FineReader поддерживает следующие форматы файлов изображений: PICT, PCX/DCX, JPEG, PNG, TIFF (различных способов сжатия, включая многостраничные TIFF-файлы).
Совет 3.
Пользователи Macintosh, возможно, захотят использовать для сканирования изображений привычный Adobe Photoshop. Два совета: старайтесь избегать этого, так как даже модуль сканирования FineReader делает первые шаги в процессе распознавания. Но если вы все же решили (или вынуждены) сканировать изображения с помощью Photoshop, сохраняйте полученные файлы в формате PICT либо TIFF без LZW-сжатия.
Анализ макета страниц
Второй шаг работы с документом, представленный кнопкой на панели инструментов, — анализ макета страниц (Analyze layout). Прежде чем FineReader приступит к собственно распознаванию текста, он должен «знать», какие именно области подлежат распознаванию, как расположены строки.
Определение ориентации текста при установке соответствующей опции производится автоматически (хотя можно сделать это и вручную путем поворота исходного изображения: Image?Rotate), а выделение областей распознавания (блоков) решает еще две задачи. Во-первых, отдельными блоками выделяются таблицы и рисунки, которые не подлежат распознаванию. Во-вторых, четкое выделение блоков позволяет максимально корректно сохранить макет исходной страницы при передаче распознанного документа во внешние приложения (такие, как MS Word или Adobe Acrobat), поскольку взаимное расположение блоков (их границы составляются только из прямых линий) легче анализировать, нежели не вполне четкие границы самого текста или рисунков.
Итак, нажимаем на кнопку Analyze layout. Различные части нашего изображения, содержащие текст или рисунки, оказались обведены рамками разных цветов и обозначены цифрами и пиктограммами в углу каждой рамки. Цвет и пиктограмма служат для обозначения типа блока. Цветовое кодирование можно при желании изменить, но в любом случае текстовый блок будет обозначен пиктограммой с буквой «А», блок рисунка — стандартной пиктограммой изображения (на ней изображены разноцветные геометрические фигуры), а табличный блок — пиктограммой таблицы.
Обычно автоматический анализ макета страницы работает достаточно корректно, однако в ряде случаев приходится поправлять FineReader. Чаще всего это бывает необходимо, если нужно распознать лишь часть текста, расположенного на странице, или включить в конечный документ не все рисунки. Также иногда приходится редактировать макет табличных блоков — некоторые таблицы оказываются слишком сложными по своей структуре.
Третьей причиной, заставляющей пользователя редактировать макет, являются рисунки оригинала, содержащие текст, например графики с подписями осей. В таких случаях FineReader отдает предпочтение тексту и выделяет подписи как текстовый блок, оставляя сам график без внимания или же выделяя как рисунок какую-либо его часть. Естественным выходом из такой ситуации является выделение всего графика как рисунка, без распознавания текста подписей.
Более специфическим случаем ручного редактирования макета являются формулы — математические или сложные химические. Поскольку внутренний формат текста в FineReader очень близок к RTF, он не «умеет» корректно работать с текстом, расположенным не «в строчку» (исключение составляют надстрочные символы и буквицы, с которыми FineReader справляется легко). При работе с документами, содержащими такие формулы, приходится и их выделять как рисунки.
Наконец, совсем отдельно стоят случаи «плохого оригинала»: FineReader испытывает естественные трудности при выделении макета на некачественных изображениях, содержащих много посторонних элементов. В частности (хотя это более относится к распознаванию как таковому), «не любит» FineReader комментарии, написанные от руки на полях оригинала, поскольку ухитряется углядеть там знакомые символы, выделяет их как текстовый блок и распознает, что нарушает общую структуру основного текста. Многие подобные ошибки могут быть исправлены именно на этапе работы с макетом — по крайней мере, делать это здесь значительно проще, чем потом редактировать готовый текст.
Изменить размеры или форму существующих блоков можно, просто «потянув» мышью за их границы. Изменить тип блока позволяет всплывающее меню, которое появляется после щелчка мышью на пиктограмме в углу блока, обозначающей его тип.
Для более сложного редактирования макета используются инструменты, расположенные на панели инструментов работы с изображением (Image Tools) слева от окна изображения. Они позволяют нарисовать новые блоки заданного типа, добавить или удалить часть блока (удалить блок целиком можно с помощью кнопки на клавиатуре, выделив предварительно нужный блок мышью).
Отдельно следует упомянуть инструменты работы с табличными блоками: если FineReader некорректно определил макет таблицы, можно вручную задать на изображении вертикальные и горизонтальные разделители (separators) таблицы, т. е. «нарисовать» структуру таблицы. Это позволяют делать два инструмента: «Добавить вертикальный разделитель» и «Добавить горизонтальный разделитель». Удалить разделитель можно также с клавиатуры, выделив его мышью и нажав .
Таким образом, при автоматическом анализе макета страниц оригинальные изображения достаточно корректно разбиваются на блоки. Те же неточности, которые программа все-таки допускает, можно легко и довольно быстро отредактировать с помощью предоставленных инструментов.
Распознавание текста
После того как макет создан и отредактирован, приступим к распознаванию (кнопка Read). Первое, на что следует обратить внимание — язык распознавания. FineReader поддерживает 117 (!) языков.
Язык, на котором будет проводиться распознавание, выбирается из выпадающего списка справа на основной панели инструментов. Если исходный документ многоязычен, можно указать несколько языков для распознавания одновременно (Multiple languages...), однако следует помнить, что увеличение числа включенных языков замедляет процесс распознавания.
Помимо языка оригинала, модуль распознавания учитывает и так называемый тип печати (Print type), который по умолчанию определяется автоматически, но при необходимости может быть установлен вручную (Process?Print Type). Есть два специфических типа печати: «матричный принтер» (Dot matrix printer) и «пишущая машинка» (Typewriter). Символы, напечатанные на матричном принтере, состоят из отдельных точек (иногда хорошо различимых даже на глаз), а символы пишущей машинки, как правило, моноширинные — имеют одинаковую ширину. Именно эти две особенности должен учитывать FineReader при распознавании. На обычных типографских шрифтах тип печати должен быть установлен в Auto.
Проверка правописания и сохранение результатов работы
Модуль распознавания анализирует не только отдельные символы, но и целые слова, используя при этом встроенный словарь. Кроме того, этот модуль особым образом помечает «неуверенно распознанные символы» (Uncertain characters).
Работа со словами, неизвестными системе, и с неуверенно распознанными символами осуществляется в модуле проверки правописания. Он вызывается кнопкой «Проверить правописание» (Check spelling).
Весь распознанный текст виден в окне текста главного окна программы. Оно представляет собой несложный текстовый редактор, позволяющий, однако, свободно изменять и гарнитуру шрифта, и его начертание. Кроме того, в этом окне цветом будут отмечены неуверенно распознанные символы.
После окончания проверки правописания следует решить, в каком формате сохранить полученные результаты (кнопка «Сохранить» — Save):
- RTF (для MS Word 98 и старше и AppleWorks 5.0 и старше);
- PDF;
- SimpleText;
- HTML (Internet Explorer, Netscape Navigator);
- Текст (кодировки Unicode, ANSI, MAC);
- MS Excel;
- CSV;
- DBF.
Как видно из этого списка, FineReader позволяет передавать результаты распознавания практически во все широко используемые приложения: MS Word, MS Excel, AppleWorks, SimpleText, Adobe Acrobat, а также использовать автоматический ввод для публикации в Web и для заполнения баз данных. Такая универсальность оказывается подчас незаменимой.
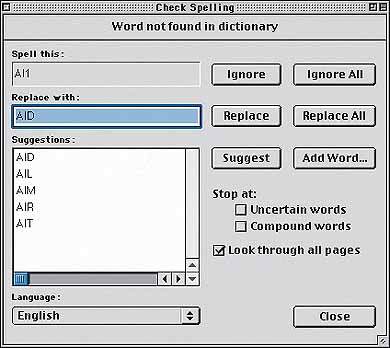
|
| Диалоговое окно проверки правописания |
И еще. . .
Мы описали лишь основные возможности FineReader для Macintosh. Но нужно сказать и о некоторых других его особенностях:
- все описанные шаги обработки документа — сканирование/открытие изображений, анализ макета и распознавание, проверка правописания, сохранение результатов — доступны в режиме «помощника» с помощью Scan&Read Assistant, вызвать который можно, нажав на первую кнопку на основной панели инструментов;
- внешний вид программы можно настраивать (см. Edit?Preferences, закладка Display);
- для ряда страниц с одинаковым макетом можно использовать так называемые шаблоны блоков (Block templates);
- FineReader for Mac использует в своей работе ряд технологий, тесно связанных с Mac OS: в первую очередь следует упомянуть поддержку AppleScript, что позволяет программировать работу с FineReader, а также возможность автоматического чтения распознанного текста через AppleSpeech (правда, пока поддержаны только английский и испанский языки);
- мощная гипертекстовая справочная система позволит разобраться даже в самых сложных аспектах работы с программой.
ОБ АВТОРАХ
Владимир Мохов — аспирант МГУ, e-mail: vlm@actuar.math.msu.su, Вера Васильева — редактор рубрики «Мультимедиа», e-mail: vasilieva@pcworld.ru
Авторы выражают благодарность компании ABBYY и персонально ее сотрудникам Яне Смотряевой и Александру Рылову за помощь в подготовке этой статьи.
Технология распознавания
Сложность машинного распознавания текста заключается в том, что его невозможно построить по жесткому алгоритму, — в частности потому, что вариантов написания одной и той же буквы существует бесконечное множество. Следовательно, чтобы корректно прочитать символы, компьютер должен их «осмыслить». Иными словами, для решения такой неформализованной, нетривиальной задачи, как распознавание текста, требуется моделирование рассуждений человека в подобной ситуации, что принято обозначать термином «искусственный интеллект».
Технология распознавания, используемая FineReader, базируется на принципах целостности, целенаправленности и адаптивности. Они были впервые сформулированы и применены на практике в конце 80-х годов XX в. Александром Шамисом (ныне сотрудником компании ABBYY) в системе распознавания «Графит».
Исходя из принципа целостности, распознаваемое изображение рассматривается как единый объект, состоящий из частей, связанных между собой пространственными отношениями. Сами части получают интерпретацию только в составе гипотезы об объекте в целом.
Согласно принципу целенаправленности, распознавание строится как процесс выдвижения и целенаправленной проверки гипотез об объекте.
Принцип адаптивности подразумевает способность системы к самообучению.
Распознавание символов в FineReader 5 строится следующим образом. Для выдвижения гипотез о том, что может представлять собой изображение, применяются так называемые признаковые классификаторы. Они используют ряд признаков, на основе которых программа вычисляет степень близости распознаваемого изображения и известных ей классов изображений, и выдает список подходящих классов (т. е. гипотезу о принадлежности объекта к тому или иному классу). Кроме того, признаковые классификаторы задействуются также и для повышения точности распознавания изображений с дефектами.
Полученный набор классов последовательно проверяется структурным классификатором, целенаправленно анализирующим каждый символ, исходя из знаний о его структуре. Что значит «целенаправленно»? Когда FineReader полагает, что на странице изображена буква «М», он специально проверяет те признаки, которые должны быть именно у буквы «М», а не у какой-либо другой, сравнивая предлагаемый символ со структурным эталоном.
Структурный эталон описывает символ как комбинацию структурных элементов (отрезок, дуга, кольцо и точка), находящихся в определенных отношениях между собой, задаваемых как нечеткие логические высказывания. Процесс распознавания делится на этапы выделения структурных элементов в изображении и сопоставления их с эталонами. Причем важно, что структурные элементы выделяются не априорно, а непосредственно в процессе сопоставления эталона с распознаваемым изображением на основе гипотезы о содержимом всей картинки. Эта гипотеза позволяет FineReader использовать знания об устройстве знака: типах элементов, их относительном положении, допустимых значениях длин, углов и проч. Благодаря такому подходу программа выделяет структурные элементы даже на разорванных и искаженных изображениях.
Если в окончательный список попало более одной гипотезы, они попарно сравниваются с помощью дифференциальных классификаторов. Так, если при распознавании символа структурный классификатор не может однозначно выбрать одну из двух букв с похожим написанием, между этими конкурирующими гипотезами делается дифференциальный выбор. Скажем, есть две гипотезы: распознаваемый символ представляет собой строчную букву «мягкий знак» или «твердый знак». Чтобы сделать выбор между этими двумя гипотезами, FineReader целенаправленно проанализирует левый верхний угол изображения, где помещается единственная отличительная деталь. Причем тщательно исследовать эту единственную деталь программа станет, только когда у нее останутся лишь две гипотезы.
С завершением работы дифференциального классификатора собственно распознавание заканчивается и начинается проверка итогового списка гипотез.
Окончательная верификация результата распознавания осуществляется системой контекста: при наличии некоторого количества распознанных букв из слова программа может «догадаться», что это за слово, используя словарь.
От версии к версии FineReader совершенствуется, используются новые алгоритмы, появляются новые функциональные возможности. Однако, по словам разработчиков, базовые принципы целостности, целенаправленности и адаптивности останутся неизменными. Ведь именно они позволяют компьютеру приблизиться к логике мышления человека и в дальнейшем, возможно, могут быть применены при решении гораздо более сложных задач, чем распознавание текстов.
Языки распознавания FineReader 5 for Mac
FineReader 5 for Mac способен распознать тексты на 117 языках, что с избытком удовлетворяет потребности любого полиглота. Так как словари занимают место на жестком диске, мы рекомендуем устанавливать поддержку только тех языков, которые действительно необходимы.
| Аварский Агульский Адыгейский Аймара Албанский Английский Африкаанс Ацтекский Баскский Белорусский Блэкфут Болгарский Бретонский Буготу Венгерский Волоф Гавайский Галисийский Ганда Греческий Гуарани Гэлао Гэльский (Шотландия) Дакота Даргинский Датский Дун Идо Ингушский Индонезийский Интерлингва Ирландский Исландский Испанский Итальянский Кабардинский Карачаево-балкарский Каталонский Кечуа Конго Корсиканский | Кпелле Кроу Кумыкский Крымско-татарский Лакский Латинский Латышский Лезгинский Литовский Луба Майя Македонский Малинке Маори Могавк Молдавский Мордовский Мяо Минангкабау Немецкий Немецкий (Люксембург) Немецкий (новая орфография) Нивхский Нидерландский Нидерландский (Бельгия) Ногайский Норвежский (Букмол) Норвежский (Нюнорск) Ньянджа Оджибве Осетинский Папьяменто Польский Португальский Португальский (Бразилия) | Ретороманский Руанда Румынский Рунди Русский Саамский Самоа Сапотек Свази Себуанский Селькупский Сербский (кириллица) Словацкий Словенский Сомали Суахили Табасаранский Тагальский Таити Ток-писин Тонга Турецкий Украинский Фиджи Финский Французский Фризский Фриульский Хани Хауса Хорватский Цзинпо Цыганский Чаморро Чеченский Чешский Шведский Эвенкийский Эвенский Эскимосский (кириллица) Эстонский |
Как мы тестировали
FineReader для Windows всегда отличался чрезвычайно высокой точностью распознавания, причем версию 5 многократно отмечали как достаточно существенное продвижение вперед в области качества распознавания. При разработке продукта для Mac OS была использована та же технология распознавания, что и для платформы PC. Для тестирования были подобраны наиболее сложные документы и по качеству печати, и по используемым символам, и по макету:
- две старые страницы машинописного текста на русском языке (с частично выцветшими буквами);
- страница текста на русском языке, напечатанная на 24-игольчатом матричном принтере с «севшим» картриджем;
- бланк личной карточки (типовая межотраслевая форма №Т-2) с таблицами, оформленными рамками различной толщины, и шрифтом с эффектами (подчеркиванием, смещением выше и ниже уровня строки);
- страница из книги очень низкого качества печати, изобилующая сложными математическими формулами;
- страница из глянцевого журнала на английском языке со сложным макетом (заголовок, напечатанный отличным от основного текста шрифтом, набор в несколько колонок, цветной рисунок с надписями);
- страница из книги на французском языке.
Тестирование выполнялось на iMac с операционной системой Mac OS 9.
Машинопись FineReader распознал успешно, выцветшие буквы не стали для него помехой. Чтение текста с матричного принтера, вызывавшего у нас сильные сомнения (уж очень бледной была печать), тоже не явилось для программы сложной задачей — она не допустила ни одной ошибки.
Как известно, младшим версиям FineReader для Windows (вплоть до четвертой) иногда были «не по зубам» сложные таблицы. Но FineReader 5 for Mac справился с личной карточкой «одной левой». Мы обнаружили только два незначительных недостатка. Во-первых, вокруг нескольких ячеек таблицы не «прорисовалась» рамка, но пара щелчков мыши — и обрамление было скорректировано. Во-вторых, горизонтальный текст, выровненный в оригинале по правому краю, после распознавания почему-то вытянулся в узкий вертикальный столбец, проходящий через все правое поле страницы. Однако после пересылки распознанного документа в MS Word 2001 текст расположился правильно и никакого редактирования не потребовалось.
А вот распознать математические формулы оказалось FineReader не под силу: вместо них программа выводила бессмысленный набор символов (причем не удавалось получить даже знак дроби, не говоря уже о более сложных — радикалах, интегралах и проч.). Однако следует уточнить, что подобное происходило, только если формулы распознавались как текстовый блок. Будучи же отмеченными как рисунки, формулы легко читались. Конечно, редактировать средствами Word или другого текстового процессора их нельзя. Не стоит, впрочем, забывать, что FineReader и не предназначен для распознавания формул.
Наконец, английский и французский языки, равно как и сложный макет, не вызвали у FineReader ни малейших затруднений. Инструмент проверки орфографии автоматически переключался на тот язык, на котором был напечатан текст. Особенно понравилось умение нового FineReader правильно располагать надписи на рисунках — в ранних версиях для Windows они нередко «съезжали» под картинку, и на исправление макета приходилось тратить значительное время.
Таким образом, FineReader 5 for Mac практически во всех тестах показал отличные результаты. Количество неверно распознанных символов было достаточно мало, чтобы правка не заняла много времени, и подсчитывать в процентах, какую точно долю они составляют, просто не имело смысла.