С момента появления серийных ЭВМ наблюдалась стойкая тенденция к повышению их производительности и увеличению объемов памяти. Изменения архитектуры в основном заключались в устранении узких мест и оптимизации обработки данных путем распараллеливания и кэширования, что можно рассматривать как линейный рост. А вот в области разработки программных средств для вычислительных машин происходило не только усложнение алгоритмов, но и предпринимались попытки сократить объем работы программиста за счет систематизации и повторного использования готовых модулей, библиотек и целых программ. После перехода от программирования в машинных кодах к ассемблеру и макроассемблеру стало проще повторно использовать тексты. Однако по-настоящему облегчило процесс разработки ПО создание языков высокого уровня, которые позволили полностью сосредоточиться на алгоритме решения задачи и не отвлекаться на организацию процесса обработки данных и взаимодействия с аппаратной частью. Создание модулей операционных систем и программ, работающих с аппаратурой, выделилось в отдельный класс — системное программирование.
С ростом мощности компьютеров и совершенствованием средств разработки повышался и уровень сложности решаемых задач. Теперь программа должна была уже не просто выполнять вычисления, но и обеспечивать ввод-вывод, сохранение и организацию данных. А для некоторых задач требовались уже целые комплексы программ, и особое внимание стало уделяться организации процесса обработки информации. Если сначала количество объектов или типов объектов, которыми оперировала программа, исчислялось лишь единицами и десятками, то теперь приходится работать с описаниями сотен, а то и тысяч объектов. При этом программист неэффективно расходовал свое время, поскольку был вынужден поддерживать гигантскую структуру данных. Справиться с проблемой помогло внедрение объектно-ориентированного программирования (ООП). Встроенная в язык высокого уровня поддержка управления и обработки иерархического описания объектов позволила свести необходимую работу к формализации характеристик объектов.
Требования к программам повысились также и вследствие того, что реализовать их непременно нужно было в рамках какой-либо операционной среды с определенным набором программных интерфейсов (API). Если же необходимая функция отсутствовала или была реализована иначе, чем в предыдущей версии продукта, то требовалось писать дополнительные тексты. Ситуация усугубилась с появлением глобальных сетей и требованием к возможности переноса ПО на различные аппаратные платформы и ОС, что не позволяет использовать сжатые способы представления данных и эффективные методы обработки. Пришло время интерпретирующих и скриптовых языков.
Кто-то спросит: «В чем же здесь проблема? Перед нами стоят масштабные задачи, мы знаем пути их решения, развиваем технологии и идем вперед по дороге прогресса...» Но давайте взглянем на оборотную сторону этой медали, а точнее, на процесс обработки данных внутри современной программы, работающей в сетевой ОС. Допустим, мы щелкаем мышью на пиктограмме, а задача программы — отобразить соответствующие данные. Проследим процессы, происходящие при этом в компьютере:
- обработка драйвером мыши;
- обработка сообщения в ОС;
- определение программы, отвечающей за обработку события;
- выявление элемента управления, отвечающего за обработку события;
- обработка сообщения элементом управления (перерисовка);
- вызов пользовательской процедуры;
- интерпретация пользовательской процедуры;
- вызов библиотеки чтения файла нужного формата;
- вызов системной библиотеки чтения файла;
- проверка прав доступа;
- запрос на чтение файла (при использовании сетевого диска добавится еще пять-шесть уровней обработки);
- интерпретация формата файла;
- вызов элемента управления для отображения;
- обработка элементом управления (перерисовка);
- вызов библиотеки графических примитивов;
- вызов драйвера видеоплаты.
Получился весьма длинный список. Реализация всех этих функций на древней машине в однозадачной операционной системе программой, написанной на ассемблере или Форте, структурно выглядела бы точно так же. Проблема заключается в том, что все большая часть такой структуры реализуется все менее оптимально. Аналогичное происходит и в области организации данных. То, что раньше требовало 500 байт и обрабатывалось полусотней инструкций, сейчас может занимать 20 Кбайт и обслуживаться несколькими тысячами инструкций!
Естественно, я не призываю вернуться к программированию на ассемблере или отказаться от защищенных мультизадачных сетевых ОС. Обратимся к одному из средств отладки, предназначенному для оптимизации программ, — профилировщику. Этот инструмент позволяет выяснить, какие блоки программы выполнялись в ходе обработки данных и сколько раз. Так, например, на профилирование процесса отправки IP-пакета в Windows (вызов библиотеки winsock.dll) потребовалось около 7000 инструкций! Представим тот же процесс в DOS:
- заполнение десятка полей в пакете — 100 операций;
- копирование данных — 10 операций;
- пересылка в буфер — 10 операций;
- работа с драйвером — 50 операций;
- работа с сетевой платой — 50 операций.
Комментарии излишни. Общий принцип оптимизации скорости выполнения процесса гласит: наиболее тщательно должны оптимизироваться часто используемые процедуры. В этом плане традиционные способы построения ОС выглядят вполне логично — чаще всего выполняются примитивные операции, относящиеся к уровню драйверов. Сами драйверы, разрабатываемые, как правило, на языке низкого уровня, максимально используют возможности аппаратуры. Затем по частоте исполнения следуют различные базовые подпрограммы, входящие в ядро ОС: работа с динамической памятью, обслуживание очередей, буферов, файлов. Библиотеки такого уровня обычно выполняются на компилируемых языках высокого уровня типа Си.
Взяв на себя организацию хранения данных и реализацию типовых операций, компилятор вынужден вставлять в исполняемый код добавления, обеспечивающие выполнение этих функций. Фактически это дополнительный код, не работающий непосредственно на выполнение основной задачи, что вызывает накладные расходы процессорного времени. При использовании языка Си эти накладные расходы малы.
Следующими по частоте выполнения являются подпрограммы, отвечающие за организацию интерфейсов и межпроцессные коммуникации. Они также создаются на компилируемом языке. Но поскольку для работы здесь необходимо вызывать подпрограммы более низкого уровня, накладные расходы возрастают. Предположим, что компилирующий язык затрачивает на 100 команд реализации алгоритма четыре команды по организации поддержки структур языка (иными словами, имеется 4% накладных расходов), при двухуровневой организации кода примерно 8%. Последнее уже приближается к границе разумного (считается, что в мультизадачной ОС накладные расходы на управление процессами не должны превышать 10% процессорного времени).
Однако скорость и качество разработки, получаемые за счет структуризации и автоматизации, покрывают эти недостатки. Даже шестиуровневая иерархия дает (1+0,04)6=1,265, т. е. 26,5%, а ведь такой метод подсчета работает только для управляющих структур (компилятор, написанный на компиляторе). Вычислительные задачи решаются с теми же 4% накладных расходов.
При использовании языков интерпретирующего типа ситуация кардинально меняется. На сегодняшний день существуют две их модификации: классические интерпретаторы, включающие в исполняемый модуль оригинальный текст программы, исполняющую и интерпретирующую подсистемы, а также полукомпилирующие, создающие промежуточный код (р-код). На выполнение команд этого кода тратится значительно меньше времени, чем на интерпретацию. Недостатком такой программы является теоретическая невозможность изменять себя в ходе выполнения.
Точно измерить уровень накладных расходов для интерпретаторов — задача сложная. Попробуем оценить его, учитывая, что для интерпретации надо сравнивать каждое слово программы со списками ключевых слов (операторов и операций) и имен переменных. Конструкция if then else компилируется в пять инструкций (сравнение, два перехода и два вызова подпрограмм). Для интерпретации того же оператора потребуется не менее 20 инструкций (т. е. 400% накладных расходов!). А еще требуется вычислить условное выражение... Исходя из этих соображений, можно определить накладные расходы для интерпретатора с p-кодом в 200%, а для «чистого» интерпретатора — в 400%.
Приведенная оценка, основанная на анализе реализации, хорошо согласуется с экспериментальными данными, описанными в статье «Эмпирическое сравнение семи языков программирования»*. Конечно, есть примеры, на которых интерпретаторы показывают неплохие результаты, но решение практических задач требует логической и вычислительной обработки, а в этих областях они безнадежно проигрывают. Если иметь в виду, что наиболее популярные средства разработки, такие как Java, Visual Basic и VBA (Visual Basic for Applications — основа офисных технологий Microsoft), относятся к полукомпилирующим интерпретаторам, а Perl, VBScript и Java-script — к классическим, то становится понятно, что виноваты в ужасающе низкой производительности современных программных средств отнюдь не операционные системы.
Сейчас основная задача разработчиков заключается в создании уже не столько отдельных программ, сколько распределенных гетерогенных комплексов, позволяющих использовать результаты работы одного приложения во многих других, находящихся на удаленных компьютерах, управляемых разными ОС. Подобное «сшивание» систем должно быть очень гибким, поэтому для его реализации используются языки интерпретирующего типа, т. е. в структуре управления появляются пирамиды из интерпретаторов, где уже двухэтажная конструкция обеспечивает 400—800% накладных расходов!
Возвращаясь к примеру с щелканьем по пиктограмме, можно сказать, что если раньше на интерпретаторе выполнялась лишь логическая часть, то теперь информация для отображения берется не из файла, а динамически генерируется еще одним интерпретатором. Те, кто имеет отношение к разработке Web-приложений, уже догадались, что этот камень кинули в их огород. Действительно, все поисковые системы, порталы и крупные информационные ресурсы предоставляют информацию в виде Web-страниц, генерируемых по запросу пользователя на лету из баз данных, текстовых файлов и результатов выполнения скриптов. Цепочка их обработки представлена на рисунке.
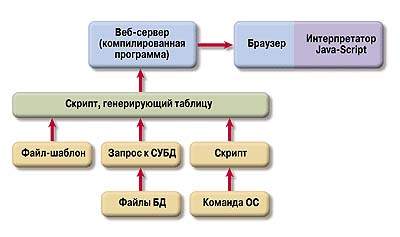
Если популярная ранее организация Web-страниц с помощью фреймов позволяла избежать скрипта, выполняемого Web-сервером (попутно увеличивая возможность кэширования), то сейчас нагрузка на сервер возрастает в два—четыре раза, а общие накладные расходы по всей цепочке составляют 600—1000% (при наличии на странице активных элементов, выборок из СУБД или результатов выполнения команд).
Какой же выход можно найти из этой ситуации? Первое, что приходит в голову, — избавиться от интерпретаторов. Однако это настолько ухудшит модернизируемость систем, что всерьез такое предложение даже не рассматривается. Затем появляется желание оптимизировать цепочку обработки, т. е. отполировать до блеска программы и по возможности избавиться от ненужных ступеней в иерархии управления. Главные препятствия на таком пути — стоимость и время разработки. К сожалению, коммерческая направленность программных продуктов подобного рода становится врагом их технологичности — жесткие временны/е рамки заставляют создателей полагаться на первые подвернувшиеся среды разработки и использовать экстенсивные решения.
Есть ли другие варианты? Возможно. Стоит обратить внимание на то, что основная часть накладных расходов приходится на уровень приложения, причем ситуация становится критичной, когда в приложении имеется многоуровневая схема управления — скрипт выполняется на интерпретаторе, написанном на интерпретаторе, и т. д. Последовательная же обработка, т. е. сначала одним интерпретатором, а затем другим, такого роста потерь не вызывает. Предлагаемый вариант может показаться парадоксальным — если нельзя отказаться от интерпретаторов, то надо «сплющить» всю пирамиду управления до одного уровня.
Откуда возникла необходимость в построении пирамиды? Очередное средство разработки или набор библиотек позволяют программисту перейти на новый уровень абстракции, где решение основной задачи не заслоняется реализацией типовых подзадач. Для различных средств разработки это могут быть функции коммуникации с внешними устройствами, файлового ввода-вывода и внутренней организацией данных в системе. Поэтому в состав инструмента включаются конструкции, поддерживающие выполнение таких типовых подзадач.
При нынешнем уровне требований к разработке приложений круг рутинных типовых задач значительно расширяется. Теперь к нему относится не только представление объектов, но и организация архитектуры системы, потоков обработки данных внутри нее, описания форматов, протоколов и интерфейсов. Важность этого направления работ и его высокий удельный вес в процессе разработки ПО подчеркивают факт существования CASE-систем, применяемых для ускорения проектирования и создания макетов.
Решением проблемы может стать и средство разработки нового типа, которое условно назовем системно-ориентированным языком программирования (СОЯП). От обычных инструментов он отличается наличием средств описания архитектуры программного комплекса и его составных частей. Подобно тому как в среде визуальной разработки типа Delphi из кубиков-компонентов строится интерфейс приложения, СОЯП призван обеспечить построение требуемой информационной системы из набора стандартных блоков.
Такой язык должен включать интегрированную среду разработки (ИСР), подобную используемой в CASE-системах. На этапе разработки приложения с ее помощью генерируется описание объектов, процессов и задач для конкретной предметной области. Реализация функций приложения, направленных на решение конкретной задачи (бизнес-функций), выносится в библиотеки, разрабатываемые на стандартном компиляторе, а объединение бизнес-функций в сервисы, пригодные для решения стратегической проблемы, производится интерпретатором, оперирующим исключительно описанием предметной области, которое сгенерировано в ИСР.
При сопровождении системы часто возникает необходимость изменения архитектуры. Обычно это требует не только разработки нового приложения, но еще и создания нескольких конвертеров данных и скриптов для управления процессом передачи данных между отдельными элементами системы. Именно здесь появляются «многоэтажные» управляющие конструкции, где помимо рассмотренных выше «управленческих» накладных расходов присутствуют еще и дополнительные издержки на преобразование форматов. При изменении архитектуры системы, созданной с помощью системно-ориентированного инструментария, необходимо разработать новую бизнес-функцию в соответствии с имеющимися спецификациями и ввести ее в структуру системы.
Стоит проанализировать накладные расходы в системе, построенной по предлагаемой методике. Во-первых, для разработки библиотек, реализующих функциональность, по-прежнему используется компилятор с его 4%-ными издержками. Во-вторых, организация передачи данных между различными функциями реализуется на интерпретаторе, причем не на полукомпилирующем, а на классическом, иначе будет затруднена модернизация системы на лету. Это дает еще 400%. И наконец, процесс передачи данных между библиотеками. Он не несет особой смысловой нагрузки и, вообще говоря, необязателен — это просто дань структуризации системы, и потому его реализация может быть безболезненно скрыта от разработчика внутрь языка.
Полученная архитектура имеет два уровня. Теперь основным становится вопрос: с какими издержками реализуется передача данных? На ассемблере переход в подпрограмму транслируется в несколько инструкций, на Си++ в те же несколько инструкций укладывается вызов сложной рекурсивной функции. В объектно-ориентированном языке код того же объема отвечает за вызов метода объекта. Поскольку описание архитектуры системы не имеет принципиальных отличий от описания класса в ООП, можно надеяться на то, что реализация процесса передачи данных уложится в 10—20 инструкций с издержками на уровне компилятора. Следовательно, общие накладные расходы можно оценить как (1+4,00)x(1+0,04)+0,04=5,24. Примерно 424% для структурированной системы любой сложности, причем основная масса издержек сосредоточена на наиболее редко используемом участке!
Стоит добавить, что наличие эффективного средства разработки программных систем позволяет бороться не только с накладными расходами. В статье Никлауса Вирта «Долой «жирные» программы»** показано, что грамотная методика разработки, прививаемая использованием качественного инструментария, способствует сокращению размера программ, повышению скорости их выполнения, уменьшению количества ошибок, а также упрощению и ускорению процесса отладки. Поскольку фирмы-разработчики кровно заинтересованы как минимум в двух последних свойствах, можно надеяться, что такой инструментарий в виде СОЯП рано или поздно будет создан, а его применение приведет к повышению качества программных продуктов.
ОБ АВТОРЕ
Александр Шлепнев - инженер-программист ВЦ МГИЭТ, e-mail: shleps@narod.ru
* www.osp.ru/os/2000/12/045.htm
** www.osp.ru/os/1996/06/27.htm
| Инструмент | Типовая операция | Покрываемый уровень абстракции |
| Драйвер | Обмен с аппаратурой | Аппаратная независимость |
| Операционная система | Ввод-вывод в файл | Организация долговременного хранения данных |
| ЯВУ | Вычисление выражения Вызов процедур | Организация хранения данных в оперативной памяти |
| Объектно-ориентированные ЯВУ | Создание-удаление объекта Изменения свойства | Представление объектов |
| Специализированные ЯВУ | Зависит от области применения | Типовые задачи предметной области |
| *ЯВУ — языки высокого уровня. | ||