
становятся «толще», а провайдеры бесплатно предлагают мегабайты дискового пространства для персональных страниц своих клиентов. Причем такой рост характеризуется процессом с положительной обратной связью — с увеличением интересных и полезных ресурсов в Сети становится целесообразнее к ней подключаться. И чем шире становится аудитория Internet, тем больше пользователей и компаний хотят там работать. Многие предпочитают бесплатно читать последние новости в режиме реального времени с экрана, а не покупать газеты. Это стало особенно заметно год назад, после августовского кризиса. На сервере Yandex.Ru (http://www.yandex.ru/polling/6.html) был проведен опрос среди пользователей на тему: «Какому источнику информации вы доверяете?» Выяснилось, что 36% из них доверяют Internet, а 35% — вообще ничему.
Что такое Internet в России?
Традиционно к российскому Internet относят серверы доменов ru (Россия) и su (СССР), а также русскоязычные или российско-ориентированные серверы доменов Украины (ua), Белоруссии (by) и других стран СНГ. По информации Российского научно-исследовательского института развития общественных сетей (РосНИИРОС), управляющего доменом ru, на 23 августа 1999 г. было зарегистрировано 15 869 серверов (http://www.ripn.net/nic/dns/list/). По данным Алексея Тутубалина (http://www.lexa.ru:8101/ru-survey/9906/, «Количественное исследование российского сегмента Internet»), к середине июня 1999 г. в доменах ru и su существовало 29 415 серверов. Можно также получить количественную оценку, обратившись к статистике российских поисковых машин. Так, «Апорт» (http://www.aport.ru/WINP/info.htm) сообщает, что на 18 августа в базе хранятся сведения о 58 721 сервере, 4 477 779 URL и 2 916 268 документах, занимающих 22 410 Мбайт. Документ — это «уникальный» URL. Имеется в виду следующее: в Internet часто одни и те же документы лежат либо на разных серверах, либо на одном, но в различных кодировках. Некоторые поисковые машины умеют определять случаи совпадения документов, и потому индексируют только один URL при наличии нескольких одинаковых. «Рэмблер» (http://www.rambler.ru/new/about.shtml) выражается более расплывчато: «Поисковая система... содержит миллионы документов с более чем 15 000 Web-страниц (имен DNS)». «Яндекс» (http://www.yandex.ru/chisla.html) выдает следующую статистику: «Количество уникальных серверов — 41 122, а уникальных URL — 10 463 493. Объем проиндексированной информации — 94,52 Гбайт». Все данные получены 23 августа сего года на соответствующих Web-страницах.
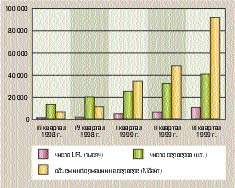 |
| Рис. 1. Многофакторный рост российской части Internet |
Еще одна характеристика стремительного роста Internet связана с быстрым изменением объемов имеющихся в нем текстов. Так, по данным Yandex.Ru, за год они увеличились в 15 раз (с 6 до 94 Гбайт). Причем число серверов выросло в 3,5 раза, а количество страниц — в 12,5 раза. При этом размеры средней Web-страницы увеличились лишь в 1,2 раза, тогда как среднего сервера — почти в 5 раз. Ниже приведены графики роста Internet и изменения средних объемов хранимой информации.
Как разобраться в русском Internet?
Сегодня в Internet можно получить самые разнообразные сведения: расписание авиарейсов и погоду на завтра, рецепт пирога и цены на компьютеры. Но для этого нужно суметь отыскать среди нескольких тысяч серверов и миллионов страниц то, что вам требуется. По содержанию («контенту») Сеть представляет собой кладезь, а по способу организации — свалку. Но, к счастью, положение не столь уж безнадежно — можно воспользоваться каталогами и поисковыми машинами.
Каталог, как правило, имеет иерархическую структуру, и все его ресурсы классифицированы по темам. Обычно с ним связывают поиск по текстам — описаниям включенных в него ресурсов. Собственно классификацию осуществляют либо авторы каталога, и такой процесс протекает качественно, но медленно, либо хозяева ресурсов, но в этом случае нельзя гарантировать соответствие ресурса разделу.
Поисковая машина поступает иначе. Ее сетевой агент («робот», «паук», «червяк») обходит все предписанные серверы и выстраивает индексы, или информацию о том, что и на какой странице было обнаружено. Полнотекстовые поисковые машины индексируют все слова, найденные на Web-странице, исключая иногда некоторые «стоп-слова» (обычно малоинформативные и имеющие незначительную частоту употребления, например союзы и предлоги).
Поисковые машины
Чтобы найти нужную информацию, пользователь должен задать вопрос (послать запрос) поисковой машине. В ответ выдается список адресов (URL). Механизм действия очень прост, но как же правильно сделать запрос?
Самое легкое — написать в строке запроса одно слово. Но следует иметь в виду, что поисковые машины относятся к словам по-разному. «Апорт» и «Яндекс» понимают слово во всех его грамматических формах и с учетом этого будут его искать. Им известна морфология русского языка, т. е. если в запросе написать и «человек», и «люди», то ответ будет одним и тем же. Эти машины различаются знанием морфологии, что проявляется в их отношении к новым словам. «Апорт» жестко привязан к базовому словарю, поэтому на запрос, включающий слова «будда» и «будде», он выдаст различные результаты, если, разумеется, это слово не внесено в словарь. А «Яндекс», встретив незнакомое слово, действует не только аналогичным образом, но при необходимости автоматически построит гипотезу, опираясь на знание правил русского языка, и ответ на запросы со словами «будда» и «будде» получится одинаковый. Поисковая машина «Рэмблер» вообще не работает с морфологией. Вместо этого она предоставляет возможность «расширить» слово, добавив после него звездочку (*). В результате, например, по запросу «человек*» будут найдены все формы слова «человек», включая «человеколюбие», «человеколюбивый» и «человекообразный».
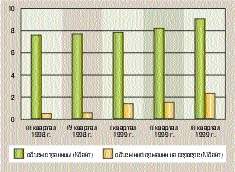 |
| Рис. 2. Характер изменения объемов хранимой информации в ней |
Русский Internet имеет значительные ресурсы, и, запросив одно слово, пользователь вполне может получить в ответ несколько тысяч, а то и десятков тысяч ссылок, если, конечно, не выбрал что-нибудь вроде «археоптерикс». Естественно, при уточнении предмета поиска строится запрос из двух-трех слов. Все поисковые машины имеют язык запроса, который включает логические операторы, а также свои дополнительные возможности. Подробнее с языком запросов для каждой машины можно ознакомиться на ее сервере. Ниже приведены основные операторы, используемые в языках упомянутых машин.
Следует также учитывать, что каждая поисковая машина понимает под пробелом. Так, для «Апорта» и «Рэмблера» пробел в запросе эквивалентен оператору И, для «Яндекса» он работает как специальный оператор Й, т. е. И внутри одного предложения, иначе — &. Кроме того, «Яндекс» использует оператор НЕТ внутри предложения - ~. Помимо того, «Яндекс» по умолчанию предлагает пользователю естественно-языковой запрос, т. е. некоторое «мягкое И». В этом случае включенные в запрос слова будут представлены в ответе наилучшим образом: при наличии документа, в котором все они встречаются, он будет находиться в верху списка найденных. Если такого документа нет, то пользователь получит список из слов, наиболее близких по составу к запросу.
Поиск в Internet требует определенных навыков, но их можно достаточно легко приобрести непосредственно в процессе работы. Ситуация облегчается тем, что бывает достаточно найти лишь один сервер по интересующей вас теме, а дальше нужно двигаться по приведенным ссылкам.
Возможности языков запросов для поисковых машин
| Оператор | «Апорт» | «Рэмблер» | «Яндекс» |
| И | AND, &, + | AND, & | &&, + |
| ИЛИ | OR, I | OR, I | I |
| НЕТ | NOT, - | NOT, ! | ~~, - |
| Группировка | ( ) | ( ) | ( ) |
| Поиск с расстоянием (N, M — число слов и предложений соответственно) | |||
| Словосочетания | « « | Не применяется | « « |
| Расстояние в словах | cN(...), wN(...), [N,...] | $NEAR | .../(N M)... |
| Расстояние в предложениях | nN(...), sN(...), {N,...} | Не применяется | ...&&/(N M)... |
Пользователь, пожелавший вести поиск в Internet, может выбрать из международных поисковых машин и отечественных. Если задача пользователя — найти что-нибудь на просторах нашей страны, то, скорее всего, наиболее успешный результат даст поиск в местных машинах. Но какую из них выбрать? Ниже предложено несколько различных критериев сравнения «искалок».
Выбор поисковой машины
Чтобы правильно выбрать поисковую машину, следует отправляться от нескольких характеристик процесса поиска.
РелевантностьПри поиске в Internet важны: полнота охвата (ничего не потеряно из имеющейся информации) и точность (не найдено лишней), т. е., иначе говоря, релевантность есть степень отношения ответа запросу. Каждая поисковая машина имеет свой алгоритм сортировки результатов поиска. Чем ближе к началу списка стоит нужный вам документ, тем выше релевантность. Проверить ее можно только экспериментально. Для сравнения рекомендуется делать запросы различной длины. Можно также использовать язык запросов, а тем, кому не хочется читать описание, следует обратиться к развернутой странице запроса (расширенный поиск — в «Апорте» и «Яндексе», детальный запрос — в «Рэмблере»).
Охват и глубина поискаПод охватом поиска понимается объем базы поисковой машины, который измеряется общим объемом проиндексированной информации, числом уникальных серверов и количеством документов, а под глубиной — наличие ограничения на количество страниц или глубину вложенности каталогов на одном сервере.
Как проверить эти характеристики? Некоторые машины дают на своей Web-странице статистику «робота». Но можно проверить и самостоятельно, задав несколько поисковых запросов, состоящих из одного слова, дабы исключить влияние языка запросов, включая различие в понимании пробела. При этом необходимо обратить внимание на статистику результатов, выдаваемую машиной. Обычно в начале списка указано количество всех найденных документов. Причем рекомендуется, чтобы слова были взяты из разных областей, но отличались по частоте употребления («весам»): редкие, «средние» и «тяжелые». А затем следует проанализировать ответы. «Тяжелые» слова, в частности, тестируют полнотекстовую индексацию документа для данной поисковой машины.
Глубину хождения «робота» проверить сложнее. Для этого нужно взять какие-либо Web-страницы, например с разветвленной структурой архивов, и проверить, проиндексированы ли те документы, на которые можно попасть, допустим, только за шесть переходов по ссылкам.
Скорость обхода и актуальность ссылокСкорость обхода Сети показывает, насколько быстро происходит индексация последнего добавленного ресурса и обновляется информация в базе данных. Важным показателем качества поисковой машины (ее работы) является не только «захват» новых территорий, но и отслеживание состояния уже захваченных, так как серверы исчезают и появляются, да и их страницы обновляются. Ссылки, которые выдает поисковая машина в списке ответа, должны существовать, а их содержание — соответствовать запросу.
Для того чтобы это проверить, информацию нужно получить экспериментальным путем. Так, для определения скорости обхода создайте где-нибудь страницу с текстом. Затем добавьте ее туда, где ведете поиск, и посмотрите, как быстро она будет найдена. Или измените уже существующую страницу. Чтобы определить актуальность ссылок, проверьте документы, приведенные по крайней мере на первой странице списка, найденного по нескольким запросам. Сообщение Not Found свидетельствует о том, что документ больше не существует.
Наряду с релевантностью имеются и другие важные пользовательские характеристики.
Скорость поискаЕсли поисковая машина отвечает медленно, то работать с ней неэффективно. Стоит иметь в виду, что воспринимаемая пользователем скорость зависит не только от характеристик поисковой машины, но и от каналов связи.
Это также проверяется экспериментально. Для этого надо производить поиск с помощью запросов разной длины и «тяжести» слов, а также в разное время суток, поскольку загрузка серверов неравномерна и ее пик обычно наступает около трех-четырех часов дня.
Поисковые возможности (работа с языками документов и запросов)Важен еще один пункт, по которому сравниваются машины: что именно и как они вносят в индекс. Полнотекстовая поисковая машина индексирует все слова текста, видимого пользователю. Учет морфологии в языке запросов позволяет находить искомые слова во всех склонениях или спряжениях. Кроме того, в языке HTML существуют теги, которые также могут обрабатываться поисковой машиной (заголовки, ссылки, подписи к картинкам и т. п.).
Язык запросов, использующий стандартные логические операторы И, ИЛИ и НЕ, присущ практически всем машинам. Причем некоторые из них умеют искать словосочетания или слова, отстоящие на заданном расстоянии, что зачастую бывает важно для получения разумного результата. Дополнительной возможностью является поиск в таких зонах документа, как заголовки, ссылки, ключевые слова (META KEYWORDS) и т. д.
Кроме того, язык запросов допускает специальную форму естественно-языкового запроса, при которой не требуется знание операторов. Чтобы проверить это, используют информацию, публикуемую на сервере поисковой машины (в help-файле). Тем не менее проверку такой возможности рекомендуем проводить с помощью реальных запросов, поскольку нередко желаемое выдается за действительное.
Дополнительные возможностиПользователям поисковой машины предоставляются дополнительные возможности, облегчающие их работу, а именно: специализированные страницы, поиск похожих документов, ограничение области поиска, наличие списка найденных серверов, поиск по датам и серверам, удобный интерфейс машины и возможность его персонализации.
Чтобы проверить наличие подобных удобств, можно ознакомиться с информацией, опубликованной на сервере поисковой машины, но лучше всего поэкспериментировать самим, используя эти возможности.
Естественно, предложенные методы исследования потребуют некоторого времени. Кроме того, поисковые машины, как и сам Internet, не стоят на месте. Но «искалка» — одно из средств, помогающих вам работать, и поэтому ее выбору стоит уделить некоторое внимание, по крайней мере не меньшее, чем организации своего рабочего места.
На Yandex.Ru был проведен опрос пользователей. Они должны были ответить на вопрос: «Зачем нужен Internet и чего в нем не хватает?» (http://www.yandex.ru/polling/9.html). Оказалось, что 23,76% используют его как справочник, 15,45 — в качестве инструмента исследования, 12,32 — как источник новостей и 14,15 — как развлечение. Вызывает оптимизм, что 10% пользователей находят нужную информацию всегда, а 73% — довольно часто; к недостаткам же респонденты отнесли то, что в Internet часто отсутствуют необходимые сведения, нет удобного поиска и... хорошей системной организации.
Желаю успеха в поиске!