Информационно-поисковая аналитическая система PCBIRS (см. «Мир ПК», № 12/97, c. 54) предназначена для работы с информационными массивами большого объема, состоящими из многих текстовых документов произвольных форматов или структурированных БД. Она обеспечивает быстрый контекстный поиск информации при едином стереотипе анализа и последующей обработки, базирующихся на технологии автоматической лексической индексации текстов.
Данная статья посвящена особенностям создания баз данных, ввода и полнотекстовой индексации информации в PCBIRS 3.2.
БД в PCBIRS
Для образования с помощью PCBIRS новой БД достаточно указать ее имя, место расположения на диске и текст комментария, определяющий тематическую направленность. По умолчанию возникает неструктурированная БД, готовая для ввода и поиска текстов. При этом каждый вводимый документ сопровождается автоматической индексацией всех образующих его слов.
В тех случаях, когда предполагается хранить в БД документы с внутренней структурой, ее необходимо предварительно описать. Она задается списком возможных имен фрагментов, причем сама фрагментация может либо вообще отсутствовать, либо быть частичной или детальной. Так, если БД содержит информацию о товарах, то детальная структура документа может состоять из таких фрагментов, как дата, товар, цена, место и т. п., каждый из которых будет включать лишь значения соответствующих данных. Если предполагается хранить в БД библиографические описания, то документы, скорее всего, будут состоять из следующих фрагментов: источник, название, авторы, содержание и т. п., включающих лишь некоторые тексты.
В общем случае каждый фрагмент документа может содержать отдельные данные, произвольные тексты, таблицы, графику, ссылки, параметры внешних функций и кнопки в качестве дополнительных органов управления.
Понятие «фрагмент» в PCBIRS аналогично понятию «поле» в реляционных БД, но они не совпадают. В самом деле, если система работает с информацией из реляционной БД, то каждое поле — это фрагмент, а запись воспринимается как отдельный документ. Однако в PCBIRS фрагмент не включает такие атрибуты, как размер и предопределенный тип данных. При фрагментации текст документа разбивается по смыслу на несколько частей. При описании же фрагмента указывается лишь его имя и набор символов-разделителей для слов, а размер текста в нем может быть любым.
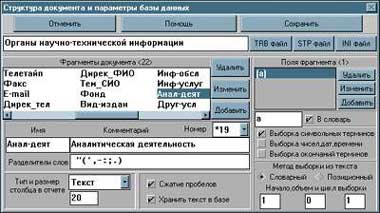
В PCBIRS поля определяют правила интерпретации лексических единиц в тексте фрагмента и выборки, которая может быть позиционной или словарной. Они никак не связаны со способом хранения информации, типами данных, и назначаются, как правило, динамически в процессе решения задач поиска и анализа. Для одного и того же фрагмента может быть назначено несколько полей с разными именами. В качестве поля могут выступать, например, любые слова фрагмента (назначение по умолчанию), числа, содержащиеся в тексте (числа, даты и время распознаются автоматически по способу написания), или наборы символов, начиная с некоторой позиции. Можно задать поля, представляющие собой инверсные слова фрагмента, т. е. слова, записанные в обратном порядке и используемые для обеспечения быстрого поиска по окончаниям сложных слов, и т. п.
Поля в основном определяют тип индексации или правила формирования поискового словаря, а используются для уточнения области поиска в предложениях запроса. Иное их применение связано с формированием так называемых виртуальных списков данных, выбираемых из множества найденных документов при анализе информации.
Структура БД в PCBIRS слабо связана со способом хранения информации. При необходимости ее можно дополнить новыми фрагментами и полями, имена которых будут изменяться без физической реорганизации базы. Ее структура, которая отражает взгляд пользователя на тот или иной информационный массив, зависит от возникающих задач, что позволяет гибко работать с очень крупными информационными массивами, поскольку на одних и тех же источниках информации можно построить множество БД.
В процессе создания или эксплуатации БД могут быть добавлены стоп-словарь, коллекции графических изображений, классификатор текстов, правила контроля вводимой информации, формы представления документов, графические планы для отображения данных из текстов документов, дополнительные функции обработки, методы защиты информации и т. д.
Индексация информации
Пополнение базы сопровождается автоматической индексацией текстов фрагментов. При этом автоматически формируются заново или дополняются словарь поисковых терминов и так называемый инвертированный список. Пользователь управляет индексацией на уровне полей. PCBIRS создает по умолчанию обычный словарный индекс, а также позволяет гибко варьировать правила выборки и интерпретации лексических единиц текста фрагмента, которые не всегда являются словами естественного языка, например, записи чисел, дат и времени, математические и химические формулы, марки материалов, иерархические коды и т. п.
Система поддерживает два вида индекса для символьных последовательностей — прямой и инверсный, а также индексы для чисел с плавающей запятой и для числовых интервалов. Пара последних позволяет реализовать контекстный поиск по запросам, включающим числа и числовые интервалы независимо от способа их представления в текстах документов. Если числа имеют размерность (метры, килограммы и т. п.), то возможен корректный поиск с ее автоматическим переводом.
Инвертированный список и словарь можно назвать накладными расходами всех систем контекстного поиска, причем если последний довольно быстро насыщается (для массивов объемом 100 Мбайт и более он часто составляет 1-3% исходного размера), то инвертированный список растет линейно при изменении размеров информационных массивов, так как он зависит от количества индексируемых терминов источника. Его можно существенно сократить, исключив из индекса так называемые «стоп-слова», к которым относятся предлоги, союзы, местоимения и т. д., т. е. термины, используемые наиболее часто и наименее информативные с точки зрения поиска. PCBIRS позволяет работать с несколькими «стоп-словарями», самостоятельно формируемыми пользователем с учетом его интересов. Их обычно выбирают непосредственно из текстов и частотных словарей, просматривая документы, а также в процессе анализа автоматически сформированного словаря всей базы.
Реальная борьба за уменьшение объема инвертированного списка при неуклонном падении цены на память внешних запоминающих устройств имеет смысл тогда, когда индексируются гигабайтные массивы или готовятся электронные издания на компакт-дисках. В случае жестких дисков можно использовать подбазы и производить распределенное хранение индекса на разных устройствах, а для компакт-дисков с ограниченным объемом нужно учитывать, что размеры инвертированного списка иногда достигают 30% объема исходного массива, поэтому работа со «стоп-словарем» может оказаться весьма актуальной.
PCBIRS поддерживает корректируемую и упакованную формы хранения индекса. Объем первой в среднем на 40% больше, а скорость доступа на 10—15% ниже. Однако ее целесообразно использовать в тех БД, где производится частая корректировка текстов документов или они вводятся небольшими порциями. В этом случае модифицируется лишь та часть индекса, которая связана с исправлениями в конкретных документах. Автоматическая модификация индекса возможна и в режиме пакетной корректировки документов, однако для больших баз она может занимать значительное время, поэтому предусмотрен механизм отложенной индексации, включающийся после окончания всех корректировок в БД.
Упакованный индекс используется при работе с нередактируемыми документами, загружаемыми в пакетном режиме, например с HTML-страницами из Internet, при подготовке электронных изданий и т. п. Изменение типа индекса в процессе эксплуатации БД требует переиндексации всего информационного массива.
Другим очень важным параметром систем контекстного поиска является время индексации. При диалоговой подготовке или корректировке отдельных документов пользователь его практически не ощущает, но при пакетном вводе больших информационных массивов может потребоваться значительное время. Средняя скорость индексации текстов на русском языке достигает примерно 10 Мбайт/мин для ПК с процессором Pentium-133. На самом деле она в большей степени зависит от количества индексируемых терминов и колеблется от 10 до 15 тыс. слов в секунду, что определяется частотными характеристиками конкретной БД или особенностями национального языка обрабатываемых текстов. С увеличением тактовой частоты процессора она растет линейно, однако при индексации информации с удаленных источников или компакт-дисков ее скорость в значительной мере определяется временем доступа к документам.
В конечном итоге характеристики индексации зависят от выбранной технологии эксплуатации БД, в которую информация может быть введена в диалоговом режиме (непосредственно с клавиатуры) и пакетном (из внешних источников). При последнем в БД сохраняются либо документы, либо только ссылки на источники.
Диалоговый ввод информации
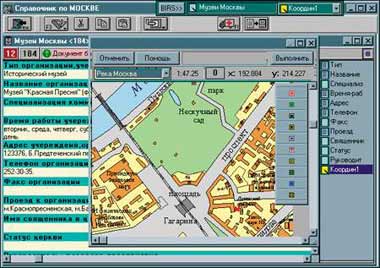
Новый документ может быть введен в БД непосредственно в режиме редактирования. В область фрагментов можно вставлять различные изображения, в частности ссылки на графические файлы или коллекции графики, таблицы, кнопки. Последние обычно используются в тексте документа для организации динамических гипертекстовых ссылок, причем с ними могут быть связаны не только тексты запросов, но и вызовы специфических функций. Таким образом, документ БД может представлять собой панель управления. Если к БД подключены графические планы (карты, схемы и чертежи), то в режиме редактирования документ будет привязан к точке или области на плане.
Система PCBIRS позволяет разрабатывать различные технологии ввода документов. Например, аннотирование файлов, используемое для регистрации в БД документов, подготовленных с помощью Windows-приложений. Это дает возможность находить документы по содержанию и просматривать их средствами тех программ, в которых они были подготовлены. Таким образом, не нужно запоминать имена и расположение файлов на дисках, и кроме того, можно анализировать содержимое документов средствами PCBIRS, используя автоматическую классификацию текстов, выделение и анализ данных. Документы регистрируются в режиме просмотра оригинала соответствующим Windows-приложением. Пользователю достаточно выделить актуальные для последующего поиска и анализа фрагменты текста и указать тип этого фрагмента в окне-поплавке PCBIRS. Выбранная информация автоматически копируется в БД.
Отдельные фрагменты регистрационной карты (дата и время регистрации, имя приложения, имя файла источника и т. д.) формируются автоматически, что обеспечит возможность просмотра оригиналов найденных документов.
Технология аннотирования файлов полезна для тех, кто получает и пересылает по электронной почте корреспонденцию большого объема и интенсивно работает в Internet. По существу, она позволяет не только хранить адреса и тексты, полученные в Сети, но и сопровождать их комментариями, а также формировать собственный индекс для ускорения в дальнейшем поиска нужной информации.
Пакетный ввод информации
Новые документы могут быть добавлены в сформированную БД непосредственно из текстовых файлов и других баз в режиме немедленной или отложенной индексации. В качестве источников информации могут выступать различные файлы (во входном формате PCBIRS, с линейно размеченными текстами, в формате HTML, произвольные тексты в ANSI- или ASCII-кодировке, в формате ISO-2709 и в виде указателей на позиционно размеченные тексты), а также БД PCBIRS и базы данных в формате DBASE IV (dbf и dbt-файлы).
Наконец, пользователь может написать собственные функции для чтения источников информации и подключить их к PCBIRS в виде DLL-библиотеки, поскольку они являются параметрами системы. Это не только увеличивает количество обрабатываемых форматов от версии к версии, но и помогает продвинутым пользователям разрабатывать собственные методы хранения информации, особенно когда предъявляются повышенные требования к ее защите и/или сжатию.
После выбора источников PCBIRS позволяет просмотреть и откорректировать схему ввода информации, поскольку структуры документов источника и БД не всегда совпадают. Система помогает гибко отобразить первую на вторую, применяя соответствующие назначения, объединяя фрагменты, вставляя константы и переменные. Если необходимо, пакетная загрузка сопровождается контролем информации и фильтрацией документов.
В завершение статьи следует отметить, что здесь не рассмотрен ряд поисковых и аналитических возможностей PCBIRS 3.2 (ассоциативный поиск, анализ понятий, взаимодействие типа клиент—сервер с другими Windows-приложениями и т. п.). Для знакомства с ними можно обратиться к демоверсии по адресу http://www.chat.ru/~birs.
ОБ АВТОРЕ
Бугаев Виталий Юрьевич — канд. физ.-мат. наук, руководитель лаборатории ВНИИ физико-технических и радиотехнических измерений. Контактный телефон: (095) 535-08-52, e-mail:bgv@ftri.extech.msk.su