
Принципы проектирования коммутаторов
Как следует из предыдущего раздела, каждая из рассмотренных схем организации коммутационого поля имеет свои достоинства и недостатки. Обсудим теперь общие принципы проектирования ATM-коммутаторов, не затрагивавшиеся в первой части обзора.
Внутренняя блокировка
Говорят, что коммутационное поле является внутренне блокирующим, если набор из N ячеек, адресованных на N различных выходных портов, способен вызвать конфликты при передаче через это поле. Наличие внутренних блокировок приводит к снижению максимально возможной производительности. Баньноявидные сети относятся к блокирующим, в то время как использование шин с временным мультиплексированием (TDM), скорость обслуживания каждой из которых по крайней мере в N раз превосходит быстродействие порта, не приводит к внутренним блокировкам. Аналогично, коммутаторы с разделяемой памятью, чья производительность операций чтения и записи равна NV ячеек/с, являются внутренне неблокирующими. Таким образом, если N ячеек поступают на различные выходные порты, то конфликт не возникает, когда разделяемые ресурсы функционируют со скоростью, в N раз превышающей скорость порта. Распространив эти рассуждения на баньяновидные сети, можно понять, что быстродействие внутренних соединений должно быть больше квадратного корня из максимальной скорости входящих соединений, умноженной на N. Очевидно, что данный показатель ограничивает масштабируемость и производительность коммутатора.
Методы буферизации
Буферизация необходима практически при любой архитектуре коммутационного поля. Например, если в баньяновидной сети две ячейки, адресованные на один и тот же выходной порт, одновременно достигают последнего каскада коммутатора, то на выходе возникает конфликт, устранить который помогает буферизация.
Рассмотрим четыре наиболее распространенных варианта размещения буферов в ATM-коммутаторе (рис. 6). Каждый из них имеет сильные и слабые стороны, однако сегодня предпочтение отдается организации очередей на выходе коммутатора.
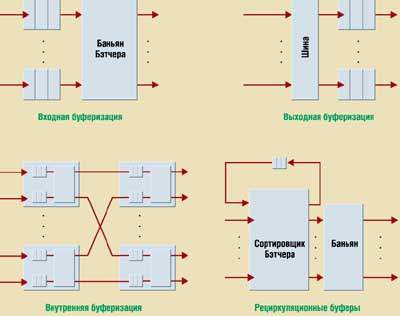 |
| Рис.6. Различные методы буферизации |
Организация очередей на входе. Примером такого варианта размещения может служить организация буферов на входных портах неблокирующей структуры с пространственным разделением, например баньяновидной сети Бэтчера. К его недостаткам можно отнести опасность возникновения блокировки в начале очереди. Если две одновременно поступившие ячейки направляются на один и тот же выходной порт, одна из них попадет во входной буфер и будет препятствовать прохождению следующих за ней ячеек, снижая тем самым пропускную способность коммутатора. Решением проблемы является значительное увеличение производительности коммутационного поля с пространственным разделением или замена дисциплины «пришедший первым обслуживается первым» (FIFO) на другую, скажем «пришедший первым обслуживается в случайном порядке» (FIRO).
Организация очередей на выходе. Этот тип буферизации используется в выходных портах структуры с разделяемой шиной. Он оптимален с точки зрения производительности и задержек, но требует применения дополнительных средств для организации одновременной множественной доставки ячеек на любой выходной порт. Таким образом, либо выходные буферы должны функционировать с достаточно высокой скоростью, либо на каждом выходном порте требуются несколько буферов. Оба решения ограничивают производительность и масштабируемость устройства: в первом случае — из-за необходимости существенно повысить внутреннее быстродействие коммутатора, а во втором — буферов.
Внутренняя организация очереди. Как уже говорилось, структуры с пространственным разделением допускают установку буферов внутри коммутационных элементов. Например, в баньяновидной сети такие элементы могут содержать буферы в своих входных портах. Однако такое решение чревато возникновением блокировки в начале очереди, что приводит к значительному снижению производительности, особенно в случае небольших буферов или крупных сетей. Использование внутренних буферов становится причиной нежелательных случайных задержек при прохождении ячейками структуры коммутатора.
Применение рециркуляционных буферов. Этот подход позволяет ячейкам повторно проходить по сети с пространственным разделением, когда несколько ячеек одновременно адресуются на один и тот же выходной порт, причем блокируемые ячейки направляются на входные порты сети через рециркуляционные буферы. Хотя данный вариант обладает серьезным потенциалом для достижения оптимальной производительности и уменьшения задержек при организации выходных очередей, при его практической реализации нужно учитывать следующее.
Во-первых, емкость коммутационного поля должна быть достаточной для размещения рециркулируемых ячеек. Во-вторых, необходимость сохранить исходную последовательность ячеек, проходящих через коммутатор, значительно усложняет управление коммутацией.
Разделение буферов
Число и размер буферов имеют важное значение при разработке коммутатора.
В устройствах с общей памятью централизованный буфер зачастую имеет преимущество перед средствами статистического разделения. Принимая интенсивный поток ячеек на некоторый выходной порт, коммутатор выделяет для них максимально возможную часть буферного пространства, что приводит к экономии последнего, поскольку ячейки поступают на различные порты случайным образом.
Для коммутационного поля с TDM-шиной и N выходными буферами большая группа ячеек, одновременно поступивших на какой-либо выход, естественно, не может быть принята другим выходным буфером. Тем не менее каждый выходной буфер способен статистически мультиплексировать трафик с N входов.
В структурах с N 2 выходными буферами, имеющих полносвязную топологию, статистическое мультиплексирование между выходными портами или на любом выходном порте невозможно. В этом случае размер буферного пространства растет экспоненциально.
Хорошо известны пять схем разделения буферной памяти. Первая, схема полного разделения (Complete Partitioning, CP), предполагает фиксированное разделение суммарной емкости буферного пространства (которое может объединять физически разные буферы) между ячейками, направляемыми на разные выходы. Ее антиподом является упоминавшаяся ранее полнодоступная схема (Complete Sharing, CS): поступающая ячейка буферизуется при наличии свободного места в общей памяти, независимо от того, на какой выход она адресуется. Полнодоступная схема с индивидуальными ограничениями на длины выходных очередей, называемыми потолками (Sharing with Maximum Queue lengths, SMQ), является развитием предыдущей. В данном случае при наличии общей полнодоступной буферной памяти вводятся фиксированные максимальные значения количества буферизуемых ячеек, направляемых на разные выходы, т.е. число ячеек каждого типа не может превышать заданного значения (потолка). Неполнодоступная схема (Sharing with a Minimum Allocation, SMA) представляет собой симбиоз CP и CS, поскольку предполагает наличие как общей буферной памяти (CS), так и ее выделенных частей для ячеек каждого типа (CP). Последний вариант — неполнодоступная схема с индивидуальными потолками (Sharing with Maximum Queue and Minimum Allocation, SMQMA) — отличается от предыдущей введением индивидуальных ограничений в общей части буферной памяти.
Масштабируемость коммутационного поля
ATM-коммутаторы смогут заменить обычные большие коммутационные системы, когда их производительность станет не ниже 1 Тбит/с. Однако преодоление терабитной «планки» — непростая задача, и ее решение наталкивается на многочисленные трудности технологического характера. В коммутаторах с разделяемой памятью и общей средой «узким местом» является время обращения к запоминающему устройству, а зависимость между числом портов и их скоростью оказывается критической. При полносвязной топологии можно получить высокие скорости портов, зато не удается избавиться от ограничений на количество буферов. Пространственное разделение, хотя и не накладывает ограничений на время обращения к запоминающему устройству и число буферов, также не свободно от недостатков. Во-первых, размер баньяновидной сети Бэтчера физически лимитируется допустимой плотностью монтажа и параметрами ввода/вывода используемых интегральных схем. Сложность организации связей между платами накладывает дополнительные ограничения на их количество. Во-вторых, в каждом каскаде требуется обеспечить синхронизацию полного набора из N ячеек. Наконец, рост геометрических размеров коммутатора снижает его надежность и затрудняет проведение сервисных и ремонтных работ.
Таким образом, большие коммутационные структуры могут работать лишь со взаимосвязанными простыми модулями ограниченной производительности, использующими любой из рассмотренных выше методов коммутации.
Существуют различные схемы организации связей между коммутационными модулями. Наиболее популярным на сегодняшний день является многокаскадное соединение.
В качестве примера на рис. 7 представлена трехкаскадная сеть Клоза Clos (N,n,m), применяемая в коммутаторах FETEX-150 компании Fujitsu и АТОМ фирмы NEC. Первый каскад содержит N/n
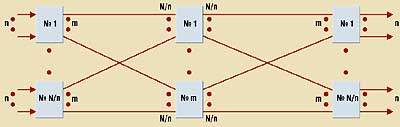 |
| Рис.7. Сеть Clos (N,nm) |
Сеть Клоза является строго неблокирующей, если в ней всегда существует доступный путь между любыми свободными входным и выходным портами — независимо от наличия других соединений в сети. Поскольку в сетях ATM ширина полосы частот, используемой соединением, может изменяться во времени, то определение условий отсутствия блокировки является нетривиальной задачей.
Производительность сети Клоза увеличится, если внутренние соединения будут иметь большую скорость, чем порты. В этом случае необходимо уделить внимание выбору размеров буферов последнего каскада, где возникает больше всего очередей.
Использование принципа выходной буферизации для сетей Клоза позволяет оптимизировать производительность, например, за счет удачного выбора параметра m. Обычно он задается исходя из того, что при достаточно больших значениях m вероятность одновременного поступления более m ячеек на один и тот же модуль последнего каскада не превосходит заданной.
Совершенно иной подход заключается в нахождении оптимального способа разделения большого коммутационного поля NxN на небольшие модули. При этом множество N входов распадается на К подмножеств с мультиплексированием К выходов, каждое из которых управляется N2/K коммутационными модулями. В таком случае небольшие коммутационные модули могут быть реализованы в виде сортирующих сетей Бэтчера, расширенных сетей или параллельных баньяновидных плоскостей.
Многоадресная передача
Многие услуги, такие как передача видео и аудио, требуют доставки входящей ячейки на несколько заданных выходных портов либо трансляции ее на все выходы. Многоадресная передача реализуется путем добавления к коммутационному полю отдельной сети, предназначенной для копирования ячеек, создания специального взаимосвязанного коммутационного модуля или использования других вариантов коммутационных схем.
Методы, основанные на общей среде, полносвязной топологии и выходной буферизации. В данном случае многоадресная передача поддерживается автоматически, так как поступающие ячейки транслируются в общую среду, а затем отбираются адресными фильтрами на выходных буферах. Адресные фильтры могут разбирать ячейки не только по адресам выходных портов, но и по групповым адресам.
Метод разделяемой памяти. Этот вариант многоадресной передачи требует применения дополнительных ресурсов. Ячейка, передаваемая по групповому адресу, может быть продублирована до буферизации или считана из памяти несколько раз. Дублирование требует дополнительной памяти, а повторное считывание — сохранения ячейки до тех пор, пока она не попадет на каждый из выходных портов, соответствующих групповому адресу.
Метод пространственного разделения. В матричных коммутаторах многоадресная передача реализуется без особого труда, однако она оказывает значительное влияние на работу устройства. Матричные системы с входной буферизацией могут передавать поступившую ячейку на несколько выходных портов, но это повышает вероятность блокировки в начале очереди на входных буферах. Единственный выход из подобной ситуации — более изощренное управление буферами.
В буферизованных баньяновидных сетях реализация многоадресной передачи возможна в том случае, если каждый коммутационный элемент способен переслать входящую ячейку на оба выхода во время буферизации другой входящей ячейки. Реализация данной схемы, получившей название широковещательной баньяновидной сети (BBN, Broadcast Banyan Network), сопряжена с рядом сложностей. Во-первых, любой коммутационный элемент имеет четыре возможных состояния, а, следовательно, ячейка должна нести два бита управляющей информации при прохождении каждого элемента баньяновидной сети. Во-вторых, две продублированные ячейки, сгенерированные коммутационным элементом, идентичны, поэтому будут направлены на один и тот же выходной порт. Эту проблему можно обойти двумя способами. Первый — снабжать групповые ячейки вместо адреса выходного порта групповым адресом, используемым для принятия решения о маршрутизации отдельным коммутационным элементом. Его недостатком является потребность в большем объеме памяти на коммутационных элементах. Второй — использовать для маршрутизации и дублирования ячеек полный набор выходных адресов, поступающих с каждой многоадресной ячейкой. Недостатки этого метода также очевидны.
Из вышесказанного ясно, что многоадресная передача значительно увеличивает сложность коммутационного поля с пространственным разделением, поэтому появились предложения разделить функции дублирования ячеек и маршрутизации между двумя сетями. Дублирующая сеть, которая должна предшествовать сети маршрутизации, распознает многоадресные ячейки и создает необходимое количество дубликатов. Затем сеть маршрутизации просто выполняет двухточечную маршрутизацию — в том числе всех копий данной ячейки (что является недостатком этого метода). Если же дублирующая сеть будет следовать за сетью маршрутизации, продублированные ячейки станут доставляться на выходные порты, и в этом случае снова возникнут все проблемы широковещательной сети.
Для организации самой дублирующей сети обычно применяются баньяновидные структуры. Многоадресная ячейка маршрутизируется или дублируется на каждом этапе коммутации, но в целях эффективного использования ресурсов процесс дублирования выполняется с максимально допустимой задержкой. Все дубликаты ячейки несут одну и ту же адресную информацию, поэтому дублирующая сеть маршрутизирует ячейки произвольным образом. После прохождения ячейками дублирующей сети трансляционные таблицы изменят групповой адрес на соответствующие выходные адреса.
Отказоустойчивость
Поскольку надежность является существенным аспектом функционирования коммутационных систем, необходимо обеспечить избыточность их критически важных компонентов. Поле маршрутизации и структура буферов, являющиеся важнейшими элементами коммутационной системы, могут быть продублированными или избыточными, что влияет на организацию механизмов обнаружения отказов и восстановления работоспособности.
Простейший способ повышения надежности сводится к разбиению всей совокупности коммутируемых ячеек на непересекающиеся подмножества, распределяемые между параллельными плоскостями поля маршрутизации. Этот метод весьма эффективен, так как он обеспечивает наименьшую избыточность, а каждая плоскость несет лишь малую долю общего трафика. Другой вариант — тождественное дублирование всего множества ячеек —- обеспечивает большую отказоустойчивость при меньшей производительности. Компромиссным решением может быть использование частично перекрывающихся подмножеств.
Распараллеливание плоскостей поля маршрутизации и структуры буферов поднимает степень отказоустойчивости, однако гораздо важнее повысить избыточность в пределах отдельных плоскостей. Баньяновидные сети склонны к отказам, поскольку содержат единственный путь в каждой паре «вход—выход»; сети с множественными путями отличаются большей отказоустойчивостью. Для повышения избыточности следует включать в состав баньяновидных сетей дополнительные коммутационные элементы и каскады, избыточные и альтернативные соединения либо увеличивать число входных и выходных портов. Платой за это становится усложнение как схем буферизации и маршрутизации, так и средств управления.
Для организации эффективного контроля за отказоустойчивостью коммутационной системы применяются разнообразные тестирующие механизмы. Маршрутизация специальных ячеек через тестовые элементы и отслеживание их появления на выходах, а также добавление служебной информации в заголовок ячейки позволяют обнаружить потери ячеек, ошибочные пути или неоправданные задержки. При выявлении отказа трафик перераспределяется до устранения причины сбоя, причем функция перераспределения может выполняться как концентраторами, так и самим коммутационным полем.
Использование приоритетов в управлении буферами
Коммутационное поле должно по-разному обрабатывать трафик АТМ различных классов в соответствии с уровнями качества сервиса (QoS). Классы трафика различаются главным образом допустимыми величинами задержек и приоритетами принадлежащих им ячеек. Поскольку организация выходных очередей предпочтительнее других методов буферизации, структура коммутатора может иметь разделяемые буферы на каждом выходном порте, по одному для каждого класса трафика. В целях сохранения порядка следования ячеек во всех парах VPC/VCC буферы используют дисциплину обслуживания FIFO, однако для самой очереди ее применять не обязательно.
Буферное управление реализует алгоритмы отбрасывания ячеек при их поступлении в уже заполненные буферы и перераспределения на выходе из буферов. Эти операции входят в состав функций администрирования трафика и выполняются модулем управления коммутатором. Внутри коммутационного поля очереди должны проверяться на предмет перегрузок для своевременного запуска необходимых процедур контроля за ними.
Общие сведения. Бит приоритета потери ячейки (Cell Loss Priority, CLP) в ее заголовке используется для указания на возможность отказа от ячейки. Когда буферы заполнены, находящиеся в очереди ячейки с CLP=1 отбрасываются раньше, чем ячейки с CLP=0. Этот бит устанавливается пользователем (для маркировки потока данных со сравнительно низким приоритетом) либо подсистемой UPC, когда объем трафика клиента превышает величину, оговоренную в контракте на обслуживание.
Различные приоритеты по задержкам передачи можно ассоциировать с разными соединениями виртуального канала. Поскольку сведения о приоритете не содержатся в заголовке ячейки ATM, обычно его связывают с каждой парой идентификаторов VPI/VCI в кодовой таблице коммутатора. Данные о приоритете допускается помещать во внутренний тэг маршрутизации, которым каждая ячейка снабжается при передаче внутри коммутатора. Ячейки, передаваемые по одному соединению VCC, должны иметь одинаковый приоритет по задержке, хотя могут обладать различными приоритетами потери ячеек.
Распределение ячеек. Функция распределения ячеек устанавливает порядок их передачи из буферов. Поскольку каждому классу QoS обычно соответствует свое значение задержки, высший приоритет должен предоставляться классу с более строгими требованиями к параметрам передачи. Стандартный подход на основе статических приоритетов, когда ячейки с низким уровнем QoS могут быть переданы лишь при отсутствии трафика, имеющего более высокий приоритет, в ряде ситуаций оказывается неэффективным. В случае его использования обработка группы ячеек с высоким приоритетом может вызвать слишком большие задержки передачи ячеек, приоритет которых ниже.
Метод расписания, при котором любая ячейка имеет установленное время отправления из очереди (deadline), основанное на требованиях QoS, считается наилучшим. Ячейки, пропустившие установленное время отправления, могут получить отказ — в зависимости от параметров трафика и особенностей реализации коммутатора. Если услуга предоставляется ячейке с наиболее близким предельным временем отправления, то число отбрасываемых ячеек удается минимизировать. В соответствии с другой схемой время делится на циклы и решение принимается в начале каждого цикла, а не перед поступлением ячейки в буфер.
Отказ от ячеек. Поскольку ячейки одного и того же соединения VPC/VCC должны обслуживаться последовательно, ячейки с разными приоритетами потерь могут смешиваться в буфере. В связи с этим необходимо определить стратегию помещения в заполненный буфер ячеек с CLP=0 и CLP=1.
В схеме выталкивания (push-out) ячейки с CLP=1 не допускаются в заполненный буфер и принимаются лишь ячейки с CLP=0 (если отказ от ячеек с CLP=1 позволяет освободить часть буферного пространства); такой способ позволяет добиться оптимальной производительности. В методе частичного разделения буферизуются ячейки и с CLP=0, и с CLP=1, но при условии, что число ячеек в очереди ниже определенного порогового значения. При превышении этого значения в буфер поступают только ячейки с CLP=0 — пока в нем имеется свободное пространство. Данный вариант менее эффективен, поскольку ячейки с CLP=1 порой оказываются заблокированными несмотря на незанятость части буферного пространства, однако он обеспечивает хорошую производительность и значительно проще в реализации, чем схема выталкивания. Существуют и более сложные алгоритмы отказа от ячеек, основанные на применении гистерезисного управления с двумя пороговыми значениями.
Индикация перегрузок. Буферное управление позволяет поддерживать обновление статистики очередей и информировать модуль управления коммутатором о возникновении перегрузок внутри коммутационного поля. Статистика очередей должна быть достаточной для эффективного контроля за работой коммутатора, определения фаз нарастания и снижения перегрузок, а также их характера (пульсирующего или сглаженного во времени). Необходимо проверять несколько полей внутреннего тэга маршрутизации, включая отметки времени и служебную информацию.
Средства буферного управления предоставляют модулю управления коммутатором данные о его функционировании, перегрузках и отброшенных ячейках, а кроме того, сведения, необходимые для учета ресурсов. При обнаружении перегрузки этот модуль способен заставить средства буферного управления скорректировать стратегию распределения или отбрасывания ячеек. Если используется индикатор перегрузки в прямом направлении (EFCI), будет изменено поле типа нагрузки (payload type field) в заголовке ячейки ATM. Для лучшего управления перегрузками могут применяться точные оценки статистических параметров трафика и состояния буферов. Хорошо известными коммутаторами, обеспечивающими управление перегрузками при помощи индикатора EFCI, являются представители семейства ForeRunner компании FORE Systems.
Как показывает анализ алгоритмов буферизации ячеек, буферное управление является сложным процессом, прежде всего — в связи с постоянным изменением требований к уровню QoS и слабой предсказуемостью возникновения перегрузок. Эффективная реализация средств управления, как и ряда других ключевых компонентов ATM-коммутаторов, представляет собой крайне сложную задачу. Авторы статьи намеревались лишь ввести заинтересованного читателя в круг проблем, связанных с коммутацией в сетях ATM. Ссылки на многочисленные Internet-ресурсы по этой теме доступны по адресу http://www.pfu.edu.ru/~ef/telelinks/atm_bisdn.htm. Некоторые данные по отдельным моделям ATM-коммутаторов можно найти в журнале «Сети» (1998, № 3, с. 36).
ОБ АВТОРАХ
Владимир Ефимушкин — канд. физ.-мат. наук, зам. заведующего кафедрой,
Татьяна Ледовских — сотрудник кафедры «Системы телекоммуникаций» Российского университета дружбы народов. С ними можно связаться по тел. (095) 955-0715, электронной почте ef@sci.pfu.edu.ru, tledovskikh@sci.pfu.edu.ru и факсу (095) 952-2823.
Список сокращений
AAL (ATM Adaptation Layer) — уровень адаптации ATM.AF (Address Filter) — адресный фильтр.
BBN (Broadcast Banyan Network) — широковещательная баньяновидная сеть.
B-ISDN (Broadband Integrated Service Digital Network) — широкополосная цифровая сеть с интеграцией услуг.
CAC (Connection Admission Control) — управление установлением соединения.
CLP (Cell Loss Priority) — приоритет потери ячейки.
EFCI (Explicit Forward Congestion Indication) — индикатор перегрузки в прямом направлении.
FIFO (First-In-First-Out) — дисциплина буферизации «пришедший первым обслуживается первым».
FIRO (First-In-Random-Out) — дисциплина буферизации «пришедший первым обслуживается в случайном порядке».
HEC (Header Error Control) — управление ошибками заголовка.
ILMI (Interim Local Management Interface) — промежуточный интерфейс локального администрирования.
IM (Input Module) — входной модуль.
MIN (Multistage Interconnection Network) — многокаскадная сеть.
NPC (Network Parameter Control) — управление параметрами сети.
OAM (Operations, Administration, and Maintenance) — эксплуатация и техническое обслуживание.
OM (Output Module) — выходной модуль.
QoS (Quality of Service) — качество сервиса.
SCPS (Synchronous Composite Packet Switching) — синхронная коммутация составных пакетов.
SM (Switch Management module) — модуль управления коммутатором.
SMDS (Switched Multi-Megabit Data Service) — коммутируемая мультимегабитная служба передачи данных.
SMA (Sharing with a Minimum Allocation) — неполнодоступная схема буферизации.
SMQ (Sharing with Maximum Queue lengths) — полнодоступная схема буферизации с индивидуальными потолками.
SMQMA (Sharing with Maximum Queue and Minimum Allocation) — неполнодоступная схема буферизации с индивидуальными потолками.
UNI (User-Network Interface) — интерфейс «пользователь-сеть».
UPC (Usage Parameters Control) — управление параметрами использования.
VCI (Virtual Channel Identifier) — идентификатор виртуального канала.
VPI (Virtual Path Identifier) — идентификатор виртуального пути.
VCC (Virtual Channel Connection) — соединение виртуальных каналов.
VPC (Virtual Path Connection) — соединение виртуальных путей.