
В условиях постоянного роста объемов информации, обрабатываемой как внутри отдельных предприятий, так и в рамках корпоративных и глобальных сетей, именно от эффективности и производительности поисковых систем зависит, превратятся ли в знания многочисленные разрозненные данные, поступающие по различным каналам связи и накапливаемые в разнообразных государственных, ведомственных, частных и прочих электронных архивах.
Объемы обрабатываемой электронной информации нарастают сегодня стремительными темпами - этому способствует активное использование мощных СУБД, быстрое развитие мультимедиа, широкое распространение корпоративных и глобальных сетей. В создавшихся условиях резко возросла потребность в системах поиска и анализа данных. Традиционные системы поиска, которые развивались в тесной взаимосвязи с СУБД, в основном ориентированы на работу со структурированными текстовыми данными и мало приспособлены для обработки мультимедийной информации и данных, поступающих в оперативном режиме. Как показывает статистика, доля структурированных данных в современных архивах составляет не более 20%, остальные же 80% приходятся на долю различных документов, сканированных текстов и другой разрозненной информации. Кроме того, в связи с быстрым развитием мультимедиа изменился характер обрабатываемых документов; наряду с текстовой информацией в них включается графика, видео, звук.
Таким образом, все острее встает проблема организации поиска и анализа для цифровых данных произвольного типа, обработка которых традиционными средствами SQL СУБД оказывается мало эффективной. Обычно в этих системах полнотекстовая индексация строится на базе инвертированных списков, в которых словам или нормализованным словоформам ставятся в соответствие адреса документов. Объем индекса при таком подходе зависит от степени нормализации исходного текста и при работе с неструктурированными данными может достигать 300% от общего объема базы. Этот метод индексации оказывается также мало пригодным при работе с графическими и другими цифровыми данными в связи с их большой насыщенностью и многообразием. Для кардинального решения проблемы индексации и поиска информации необходимы принципиально новые методы.
Один из таких альтернативных подходов - технология, разработанная компанией Excalibur Technologies и объединившая в себе метод адаптивного распознавания образов (APRP - Adaptive Pattern Recognition Processing) и семантические сети. Она позволят работать с цифровой информацией любого типа - текстом, графикой, видео и др. Метод APRP опирается на теорию нейронных сетей и позволяет осуществлять бинарную индексацию, при которой размер индекса даже при обработке неструктурированной информации не превышает 30% от размера исходных данных. Программные средства Excalibur позволяют вести ранжированный индексный поиск и поиск по шаблонам. В качестве шаблонов могут выступать фотографии, наброски, фрагменты текста и др. Применение технологии семантических сетей обеспечивает возможность использования естественного языка запросов и позволяет вести интеллектуальный поиск на основе баз знаний.
Сегодня основными продуктами компании Excalibur являются RetrievalWare, EFS и Visual RetrievalWare. Первые два ориентированы на работу с текстом, а Visual RetrievalWare предназначен для обработки изображений. На рис.1 приведена схема взаимодействия основных компонентов Excalibur, указаны применяемые в них методы поиска, а также поддерживаемые аппаратные платформы и операционные среды.
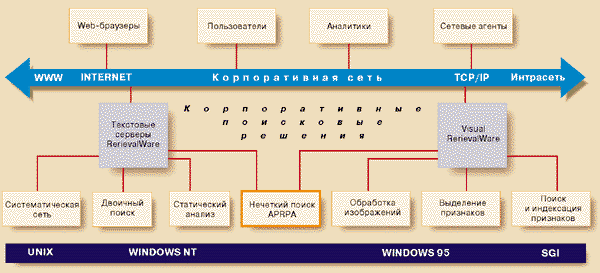
Рисунок 1.
Архитектура RetrievalWare.
Различные подходы к построению поисковых систем
Основные критерии оценки эффективности поисковых систем - скорость, точность и полнота ответов. Точность определяется тем, какая часть информации, выданной в ответ на запрос, является релевантной, т. е. относящейся к этому запросу. Полнота характеризуется соотношением между всей релевантной информацией, имеющейся в базе, и той ее частью, которая включена в ответ. Кроме этого при оценке поисковых систем учитывается, с какими типами данных может работать та или иная система, в какой форме представляются результаты поиска и какой уровень подготовки пользователей необходим для работы в этой системе.
Традиционные подходы к организации поиска информации можно разделить на три группы: методы индексного (или двоичного) поиска, статистические методы и методы, основанные на базах знаний.
Индексный, или двоичный, поиск применяется главным образом со структурированными базами данных. В таких методах слова интерпретируются как последовательности закодированных символов. Используя формальный синтаксис, или язык запросов, система двоичного поиска выбирает точное соответствие для отдельного слова, цепочки слов или слов, связанных логическими операторами. Применение искусственного языка запросов приводит к необходимости обучения пользователей двоичной логике, которая не является интуитивно понятной и трудна в использовании. Системы двоичного поиска имеют ограничения по точности, влияющие на возможность нахождения всей относящейся к запросу информации. В методах двоичного поиска не учитываются различные формы и значения слов; пользователю непросто угадать точные слова и фразы, которые были использованы авторами в документах. Системы двоичного поиска не могут также ранжировать документы по степени соответствия запросу, поэтому пользователь вынужден читать каждый документ, чтобы определить, насколько он соответствует запросу.
Статистические методы основываются на расчете различных частотных характеристик: частоты вхождения слова в документ, взвешенной частоты вхождения и частоты совместного вхождения нескольких слов. При этом предполагается, что чем чаще встречается то или иное слово запроса в документе, тем в большей степени данный документ соответствует введенному запросу. Основной единицей информации, которой оперируют статистические методы, является отдельное слово, однако связи между словами рассматриваются исключительно с математической, а не с лингвистической точки зрения. В отличие от методов двоичного поиска статистические методы не требуют применения жестко формального языка запросов. Они позволяют проводить ранжирование документов по степени соответствию запросу, что существенно повышает эффективность работы с поисковыми системами. Однако такие методы не всегда позволяют получить желаемые точность и полноту ответов, поскольку важность того или иного термина не напрямую связана с частотой его использования в документе.
Системы, основанные на базе знаний, занимаются поиском информации на основе некоторых внешних знаний. Они используют концептуальные отношения, которые не применяются при статистическом поиске.
Системы, основанные на базах знаний, гораздо удобнее тех, которые базируются на двоичном поиске. Однако сегодня лишь подход, основанный на построении семантических сетей, свободен от ограничений, присущих двоичному поиску; он обладает достаточной гибкостью, доступен для расширения и не слишком громоздок при эксплуатации.
Особенности технологии поиска Excalibur
Концептуальный поиск на основе семантических сетей привносит элементы искусственного интеллекта в информационно-поисковые системы. Именно этот подход использован в системе Excalibur. Однако, как можно заметить, методы поиска, основанные на базах знаний, предназначены для работы в области текстовых данных. Преодолеть это ограничение в поисковых системах Excalibur удалось за счет совместного использования технологии семантических сетей и методики адаптивного распознавания образов APRP.
Метод адаптивного распознавания образов базируется на принципе биологических нейронных сетей - система функционирует как самоорганизующийся организм; анализируя данные, она выделяет и запоминает присущие этим данным двоичные конфигурации-шаблоны. APRP автоматически индексирует выделенные двоичные шаблоны, создавая тем самым структурированную память, оптимизированную в соответствии с внутренним содержанием данных. Наряду с идеологией нейронных сетей в APRP используется также методология нечеткого поиска, которая обеспечивает устойчивость поисковых процедур к ошибкам, содержащимся во вводимых данных или терминах запросов. Подход, основанный на APRP, позволяет достичь высокой скорости поиска информации, добиться расширяемости системы и эффективного использования вычислительных ресурсов.
Ряд других особенностей технологии Excalibur связан с использованием семантических сетей, позволивших кардинально изменить работу с текстовыми базами данных и предоставивших возможность осуществления автоматического поиска информации с применением запросов на естественном языке. Семантические сети объединяют синтаксис, морфологию и семантику языка, они используют полные словари, тезаурусы и другие семантические ресурсы, предоставляя в распоряжение пользователей встроенную базу знаний для ведения интеллектуального поиска информации. Например, английский вариант сети охватывает около 0,4 млн смысловых значений слов и свыше 1,6 млн связей между словами.
В процессе поиска информации пользователь может сформулировать свой запрос непосредственно на родном ему языке, например английском. Этот запрос автоматически дополняется набором связанных между собой терминов и понятий. Алгоритмы морфологического разбора, применяемые в Excalibur, позволяют различать разнообразные формы слов, заданных в запросе, даже с учетом возможных орфографических ошибок. Для обеспечения более точного поиска проводится анализ, направленный на выявление идиоматических выражений, встретившихся в запросе. Словосочетания типа "недвижимое имущество" воспринимаются как единые понятия, а не наборы отдельных слов. Кроме того, распознаются разные значения слов. Пользователь имеет возможность указать, в каком из множества значений употреблено слово в конкретном запросе. Базовая семантическая сеть Excalibur поддерживает многоуровневые структуры словарей, которые объединяют специализированные термины по юридическим, медицинским, финансовым, техническим и другим дисциплинам. Конечный пользователь может также добавить свои определения и понятия, не нарушая целостности основной базы знаний.
Важным преимуществом Excalibur является возможность представления результатов поиска в виде списка документов, отсортированных по степени соответствия запросу. Это значительно повышает эффективность работы с данными и позволяет сразу получить наиболее важную информацию, не просматривая подряд все выделенные документы. Однако точность ранжированного поиска существенно зависит от критериев, которые используются для оценки релевантности документов. Обычно для оценки степени соответствия применяется непосредственный статистический анализ. Иногда база данных разбивается на отдельные сегменты, или порции, и оценка релевантности проводится отдельно по каждому сегменту. Это повышает скорость поиска, но может привести к снижению точности, так как документ, наиболее важный в некотором сегменте, может не оказаться таковым в рамках всей базы. При оценке степени соответствия документа кроме статистических методов поиска используется ряд дополнительных критериев, основанных на значении слов и их синтаксической роли. В общей сложности можно выделить семь основных критериев, которые учитываются при ранжировании документов: частота вхождения понятия в документ; близость понятий документа к запросу; частота вхождения понятия в остальную часть базы данных; близость понятия к другим понятиям и терминам документа; важность понятия, основанная на его синтаксической роли; важность понятия, основанная на его спецификации; позиция понятия в списке наиболее важных понятий документа.
Программные продукты Excalibur, соединяющие в себе APRP-технологию, семантические сети и естественный язык запросов, принадлежат к поисковым системам нового поколения. При работе с различными источниками данных они позволяют не просто извлекать разрозненные сведения, а получать актуальную, доступную, точную, полную и своевременную информацию.
Средства анализа и поиска текстовой информации RetrievalWare
Excalibur RetrievalWare занимает центральное место в семействе программных продуктов Excalibur. Интеграция методики адаптивного распознавания образов и технологии семантических сетей позволяет системе RetrievalWare обеспечить высокую производительность на всех этапах обработки текстовой информации, начиная от сбора и индексации данных и кончая их поиском и распространением.
RetrievalWare построена на основе гибкой - модульной - архитектуры, которая обеспечивает масштабируемость в распределенной среде клиент-сервер, поддерживает работу с обширными базами данных и большим количеством пользователей. Excalibur RetrievalWare представляет собой инструментальную систему, включающую в себя широкий набор текстовых серверов и развитые средства разработки приложений (SDK). В состав SDK входят высокоуровневые интерфейсы API, предназначенные для создания пользовательских интерфейсов GUI на основе таких средств, как Visual Basic; средства вызова удаленных процедур, обеспечивающие проектирование систем, которые поддерживают работу с большим числом удаленных пользователей; прикладные интерфейсы низкого уровня, позволяющие адаптировать поисковые возможности RetrievalWare к требованиям конкретных потребителей.
Текстовые серверы Excalibur RetrievalWare обеспечивают высокопроизводительный полнотекстовый поиск для больших информационных систем. В них входит расширяемый набор модулей индексации, поиска и отображения данных, которые допускают гибкую конфигурацию, могут работать на процессорах различных типов и поддерживают протоколы TCP/IP. Excalibur RetrievalWare включает в себя несколько серверов, предназначенных для текстового поиска.
Применение технологий Excalibur позволяет повысить эффективность работы как с неструктурированной цифровой информацией, так и с традиционными базами данных. Компания Excalibur сотрудничает с разработчиками СУБД Oracle, Informix, Sybase, CA и др. Наиболее тесные связи установлены с компанией Informix, для которой Excalibur создает встроенные модули Data Blade, предназначенные для работы как с текстами, так и с изображениями. Сегодня пользователь или системный интегратор, использующий имидж-сервер в качестве Data Blade, может создавать приложения на базе обоих продуктов. В принципе, как утверждают разработчики Excalibur, они могут проиндексировать любую базу данных и обеспечить тем самым неструктурированный доступ к структурированным данным. Например, Pacific Bell At Hand заключила соглашение с Excalibur и объединила RetrievalWare с реляционными базами данных Oracle и Java-интерфейсом, что позволило компании не только проиндексировать информацию, но и улучшить качество обслуживания пользователей.
Система ведения электронных архивов Electronic Filing Software
Сегодня, несмотря на широкое распространение автоматизированных систем документооборота и делопроизводства, огромное количество оперативной и справочной информации по-прежнему остается на бумажных носителях, что стимулирует развитие новых информационных технологий построения электронных архивов, обеспечивающих хранение больших объемов документов в электронном виде и доступ к ним.
Система Electronic Filing Software (EFS) предназначена для автоматизации различных видов деятельности, связанных с ведением электронных архивов; она предоставляет средства для сбора, хранения документов и организации поиска информации. EFS может работать на различных платформах с разнообразными типами документов, поступающих из многочисленных источников, в частности распределенных по локальным и глобальным сетям.
В этой системе бумажные документы вводятся с помощью сканера, а электронные могут считываться с оптических дисков, магнитной ленты или быть получены с помощью модема. EFS поддерживает большинство известных форматов текстовых и графических файлов, а также имеет встроенные средства оптического распознавания текста (OCR). Необходимо отметить, что, благодаря использованию технологии ARPR, EFS (в отличие от других подобных систем, где ошибки сканирования являются основным препятствием к успешной работе с архивами) менее чувствительна к погрешностям распознавания текста, поэтому позволяет осуществлять поиск без дополнительной корректировки и уточнения введенного текста. При работе с документами это позволяет экономить от 1 до 10 дол. на страницу текста, что является важным преимуществом, особенно ощутимым для организаций, осуществляющих электронное дублирование большого количества бумажных документов.
После того как документ введен в EFS, проводится автоматическое индексирование полного содержимого этого документа по технологии ARPR. Кроме того, по выбору пользователя документ может быть каталогизирован в базе данных с помощью набора определяемых пользователем полей или сохранен в электронном архиве Excalibur. Технология адаптивного распознавания образов, применяемая в EFS, дает возможность индексировать все содержимое текста, однако индекс не превышает одной трети от размера исходного документа, что позволяет достичь максимальной производительности при минимуме затрат на хранение информации.
Обеспечение быстрого и эффективного поиска информации - основная цель всех систем ведения электронных архивов. EFS позволяет осуществлять поиск несколькими независимыми способами:
- контекстный поиск по полному содержимому документов;
- контекстный поиск по названиям документов и меткам файлов;
- контекстный поиск с введенными пользователем синонимами по всему тексту документа;
- непосредственный доступ к файлам;
- поиск по SQL-запросам;
- ключевой поиск по тексту, именам и меткам;
- двоичный поиск по всему тексту.
Наличие графического пользовательского интерфейса, который создает удобную среду, привычную для всех кто знаком с офисной работой, дает возможность свести к минимуму затраты на переподготовку специалистов и обучение их приемам работы с электронными архивами. Режим нечеткого поиска уменьшает последствия погрешностей распознавания текста, ошибок ввода данных, а также сводит к минимуму влияние орфографических ошибок, допущенных в самом запросе.
EFS поддерживает технологию клиент-север для всех популярных аппаратных платформ, операционных систем, сетей и баз данных. Она может быть установлена на рабочих станциях и серверах UNIX производства компаний Sun, IBM, Digital и Hewlett-Packard. Обеспечивается также поддержка клиентов Windows и Macintosh для всех аппаратных платформ. EFS поддерживает связь с внешними базами данных, в том числе Oracle, Informix, Digital Rdb, Sybase, Ingres (Ultrix/SQL). В состав EFS входит WebFile, обеспечивающий доступ для чтения архивов EFS через Web-браузер. Для того чтобы начать поиск по архивам EFS, пользователю достаточно иметь поддерживаемый EFS Web-браузер и соединение с локальной сетью или с Internet.
Средства анализа и поиска мультимедийной информации
Подсистема Visual RetrievalWare предоставляет инструментальные средства для создания программного обеспечения, предназначенного для обработки произвольной мультимедийной цифровой информации. В состав Visual RetrievalWare SDK входит несколько графических интерфейсов разработки приложений различных уровней. Для UNIX-версий Visual RetrievalWare SDK поставляются статические библиотеки, а версия для Windows 95 и Windows NT, кроме того, включает в себя библиотеки импорта и динамически загружаемые библиотеки DLL. На основе Visual RetrievalWare SDK могут быть разработаны как самостоятельные приложения, так и отдельные модули, входящие в состав более крупных систем, для которых обработка изображений - лишь одна из многих решаемых задач. Visual RetrievalWare поддерживает режим многопроцессорной обработки.
Visual RetrievalWare SDK предоставляет средства для выполнения различных традиционных операций с изображениями, таких как загрузка, сохранение, копирование, отсечение, поворот, масштабирование и др., а также специальные компоненты для организации индексации и поиска цифровой информации. Все это позволяет проводить сравнение цифровых данных и осуществлять ранжированный поиск изображений по шаблону-образцу. Допускается обработка произвольных изображений - двоичных, полутоновых и цветных. Visual RetrievalWare поддерживает работу с различными графическими форматами - TIFF, GIF, JPEG, BMP и др. Изображения могут быть введены с помощью сканеров, получены по видеоканалам (VCR и др.), загружены из сети или созданы с помощью каких-либо графических редакторов.
Основу технологии Visual RetrievalWare, как и всего семейства программных продуктов Excalibur, составляет метод адаптивного распознавания образов. Каждому изображению, обрабатываемому в Visual RetrievalWare, ставится в соответствие некоторый двоичный вектор признаков, называемый дескриптором. Дескриптор формируется в результате анализа и сжатия изображения. Анализ осуществляется для выявления отличительных признаков, а сжатие позволяет уменьшить размер дескриптора по сравнению с размером исходных данных. Дескрипторы хранятся в базе, связанной с базой основных изображений. Именно дескрипторы используются для индексации, сравнения и поиска цифровой информации; на их основе автоматически устанавливаются гиперссылки в базе изображений. В процессе поиска информации по технологии Visual RetrievalWare дескриптор шаблона сравнивается с дескрипторами данных, хранящихся в базе. В итоге выдается список изображений, ранжированный по степени сходства с образцом. При этом пользователь может задавать различные весовые коэффициенты для конкретных параметров (композиции, цвета, контрастности).
В Visual RetrievalWare SDK имеются встроенные средства для выделения признаков и составления дескрипторов изображений. Размер дескриптора обычно бывает фиксированным, он не превышает 1% от объема исходного изображения. Использование дескрипторов позволяет сократить индекс и повысить скорость поиска цифровой информации. Однако слишком сильное сжатие ухудшает точность сравнения, поэтому в Visual RetrievalWare SDK предусмотрена возможность варьирования размера дескриптора для достижения наилучшего баланса между скоростью и точностью сравнения.
Алгоритмы, используемые в Visual RetrievalWare, имеют высокую производительность и позволяют обрабатывать большие объемы цифровой информации - это главное их преимущество перед традиционными методами сравнения изображений, основанными на корреляционном анализе. Проведение корреляционного анализа требует выполнения сложных математических вычислений, которые занимают значительно больше расчетного времени, чем побитовые операции, выполняемые при сравнении дескрипторов. Однако корреляционные методы являются более точными, поэтому для достижения наилучших результатов возможно совместное использование двух подходов. В этом случае поиск осуществляется в два этапа: сначала путем сравнения дескрипторов выделяется ограниченное подмножество изображений, схожих с заданным шаблоном, а затем внутри этого подмножества применяется корреляционный анализ для выявления более точного соответствия.
Программные средства Visual RetrievalWare будут интересны всем организациям и специалистам, много работающим с изображениями, - военным, криминалистам, службам безопасности, разведке, таможне, а также представителям более мирных профессий, в том числе искусствоведам, дизайнерам, научным работникам и картографам. Недавно Visual RetrievalWare был интегрирован в поисковую систему Internet Yahoo! для реализации интеллектуального поиска изображений. Теперь обратившись по адресу http://www.yahoo.com, можно не только найти текстовый фрагмент или ссылку на документ, но и использовать изображение в качестве поискового образа.
* * *
Программные продукты Excalibur представляют собой средства интеллектуального поиска информации и позволяют повысить эффективность работы специалистов из разных прикладных областей. Поисковые системы Excalibur обеспечивают единую среду для работы с самыми разнообразными документами - электронными архивами, неструктурированными данными, информацией, оперативно поступающей по различным каналам связи, структурированными данным, хранящимися в различных базах данных и др. Повышая скорость и точность поиска нужной информации, технологии Excalibur позволяют высвободить дополнительное время для анализа и осмысления, что влияет на скорость и качество принятия решений. Новые решения предоставляют эффективные средства работы с огромными информационными ресурсами, такими как корпоративные сети и Internet, позволяя более полно использовать огромную мощь и потенциал современных информационных систем.
Возможности программных продуктов Excalibur по достоинству оценены многими компаниями. Например Всемирный банк включил Excalibur RetrievalWare в свою корпоративную сеть в качестве стандартного средства доступа к данным, различным по типу и местоположению. Известные компании, издательства и информационные агенства (например, Chicago Tribune, Internet Financial Network, Global Financial Information, Control Data Corp., Sequent, Sierra On-Line, The Los Angeles Times и командование ВМФ США) также активно используют решения от Excalibur. Все большее распространение получают программные продукты Excalibur и в России, их применяют Конституционный суд, ГУИР ФАПСИ, агенство занятости АНКОР, страховые компании и ряд других.
Получить более подробную информацию о поисковых средствах компании Excalibur Technologies, а также просмотреть примеры выполнения поиска можно на Web-сервере компании по адресу http://www.excalib.com.
Елена Карташева - Институт математического моделирования РАН, Москва; тел. (095) 972-3855.