

Если и можно охарактеризовать сегодняшние сети и приложения одним словом, то это «сложность». Приложения стали крайне непростыми. Они взаимодействуют через целый ряд портов TCP/UDP, работают в многозвенных средах и все чаще перемещаются с распределенных на централизованные серверы. Управлять важными деловыми службами становится все труднее. В такой ситуации поможет лишь глубокое знание происходящих в сети процессов.

Конвергенция трафика данных и голосового трафика на порядок повышает сложность корпоративной сети. Раньше сети передачи голоса, видео и данных были разделены, сегодня же все эти виды трафика передаются по единой сети. С появлением IP-телефонии отделы ИТ пытаются оценить, как IP-телефония, передача графических файлов и управление качеством услуг (Quality of Service, QoS) влияют на работающие в сети деловые приложения. Сетевое оборудование также стало сложнее. ИТ-менеджеры уже ближайшие два года планируют внедрение 10 Gigabit Ethernet, MPLS, виртуальных частных сетей (Virtual Private Network, VPN) и механизмов QoS. Однако, как и прежде, используются Gigabit Ethernet, ретрансляция кадров и АТМ. Неважно, вследствие каких причин возникает необходимость реструктуризации сети: из-за потребности в пропускной способности, неправомерного использования сети или появления новых приложений — без конкретных и детальных характеристик все это гораздо больше напоминает искусство, чем науку.
Специфическая проблема заключается в том, что при обращении в службу технической поддержки большинство пользователей описывают именно затруднения, связанные с выполнением повседневных деловых операций: «Электронная почта медленно работает» или «Приложение CRM слишком долго реагирует». Подобные примеры подтверждают необходимость системного подхода к анализу работы всех приложений для распознавания и устранения проблем, планирования изменений производительности и минимизации времени реакции.
Абсолютно необходима информация о функционировании TCP и UDP, а также о случаях, когда НТТР занимает большую часть пропускной способности по сравнению с DNS или FTP (см. врезку «Идентификация важных индикаторов производительности»). Она дает сетевым администраторам и разработчикам приложений представление о том, как сотрудники используют сеть и насколько сетевые услуги, к примеру поиск DNS, соответствуют ожиданиям.
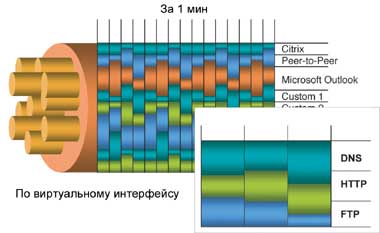
|
| Рисунок 1. Современные решения мониторинга предоставляют не только общий анализ по порту (спереди), но и высокодетализированный — по порту, виртуальной локальной сети и приложению (сзади). |
Решение для управления производительностью сети и приложений должно обладать определенными основными функциями. Очень важно, чтобы оно предназначалось для применения в конвергентных сетях. При обеспечении безопасности полетов ни одна авиакомпания не полагается исключительно на собственные системы слежения, поскольку все используют одно и то же воздушное пространство. Этот принцип должен применяться и в случае голосовых, видео- и информационных приложений в одной и той же сети. Ответственный за ИТ должен иметь возможность анализа и обзора всех приложений, а также сбора соответствующих данных. Прочие требования звучат следующим образом:
- идентификация и нахождение всех приложений, будь то широко распространенные, комплексные, разработанные внутри компании или на базе Web, как, например, SAP, Citrix, IP Multicast, HTTP и одноранговые приложений;
- выявление всех адресов отправителей и получателей из числа пользователей приложений;
- взгляд на приложения в соответствии с классами QoS (с различением по кодовой точке дифференцированных услуг — Differentiated Services Code Point, DSCP);
- выявление приложений по сегменту, к примеру по соединению Gigabit Ethernet, по виртуальному каналу (виртуальной локальной сети) и одновременно в соответствии с QoS;
- взгляд в реальном времени и ретроспективные отчеты при простой навигации в пределах временных срезов;
- мониторинг голосовых приложений и протоколов: протокола передачи в реальном времени (Real Time Protocol, RTP) и протокола инициации сеансов (Session Initiation Protocol, SIP), а также собственных протоколов таких производителей, как Avaya и Cisco;
- предоставление многообразных недорогих инструментальных опций для охвата различных частей сети;
- анализ и сопоставление собранных данных для выявления наиболее часто или, наоборот, редко применяемых приложений, независимо от инструментария и топологии;
- подача сигнала об активном использовании приложений: к примеру, при превышении 50-процентной загрузки пропускной способности сегмента трафиком HTTP или уровня в 3% в случае одноранговых приложений, подобных Kazaa;
- анализ времени реакции приложения до и после внедрения голосовых услуг с целью обеспечения работы деловых приложений и соблюдения соглашений об уровне доступа (Service Level Agreement, SLA) для отделов при миграции на конвергентные услуги.
Единое решение включает в себя пассивный инструментарий для распознавания приложения с активными агентами и развитыми средствами анализа производительности. Только так обеспечиваются наилучший возможный обзор и анализ происходящего на уровнях со второго по седьмой, и в итоге можно составить и конфигурировать внутренние соглашения об уровне доступа с отделами и филиалами, а также управлять ими. Критериями становятся предоставление данных по сети в соответствии с приоритетом QoS, гарантированная пропускная способность и целевое использование корпоративной сети. Кроме того, указанный подход требует меньшего количества инструментов для управления приложениями на всем предприятии. В результате повышается продуктивность работы сотрудников отдела ИТ, а стоимость текущего ремонта и полная стоимость владения снижаются.
Еще одним положительным результатом является широкий, но контролируемый доступ к отчетам. Так, отдел ИТ поможет партнерам по бизнесу решать возникающие проблемы, будь то взаимодействие финансовых менеджеров при согласовании бюджетных документов или тщательный анализ работы филиальной сети руководителями подразделений компании.
ОТ ПОВСЕДНЕВНОЙ ПРОБЛЕМЫ К ПОЗНАНИЮ
Для принятия решения о предоставлении деловых услуг по сети необходима более или менее детальная информация. Еще раньше следует выяснить, какого рода должно быть это решение: введение новых деловых приложений поднимает вопрос, достаточно ли высока пропускная способность самой корпоративной сети и доступа по глобальной сети к штаб-квартире, в вычислительном центре и в удаленных филиалах. Пример: ответственная за приложения группа в банке регулярно добавляет новые услуги без предварительного сообщения об этом другим подразделениям ИТ. В ответ на это администратор устанавливает зонд перед серверной фермой. В ходе проверок проводится мониторинг всех приложений и немедленно распознаются новые.
Еще одной проблемой является определение того, где находится причина снижения времени реакции: в сети или на сервере приложений. Так, к примеру, в одной крупной организации здравоохранения, где для управления электронными медицинскими данными использовалось требовательное к ресурсам программное обеспечение, время реакции составило более 10 с. Нужно было установить, вызвана такая задержка сервером или приложением. Зонд седьмого уровня со встроенным активным и пассивным анализом времени реакции определил причину задержки в приложении. После этого организация смогла заставить разработчика приложения выпустить заплату для устранения проблемы.
Внедрение IP-телефонии ведет к разработке внутренних SLA между отделом ИТ и производственными подразделениями для обеспечения высококачественного предоставления голосовых приложений и приложений обработки данных. Управление QoS часто применяется для соблюдения SLA, однако этого не всегда достаточно. К примеру, у финансового приложения несмотря на управление QoS были заметные проблемы. После установки зонда удалось выяснить, что почти всем приложениям был присвоен высокий класс QoS, так что появлялись проблемы с качеством. Это лишь некоторые примеры из практики, когда более глубокое изучение на всех семи уровнях модели OSI позволяло сложное сделать простым.
Андреас Штайн — менеджер Netscout Systems по Центральной Европе. С ним можно связаться по адресу: wg@lanline.awi.de.
Идентификация важных индикаторов производительности
Решения по управлению производительностью сети на всех семи уровнях ведут поиск специфической информации для определения и анализа поведения сети и приложений:
- при измерении QoS используется технология второго уровня 802.1р или DSCP в заголовке пакета в соответствии со стандартами RFC 2474 и 247;,
- мониторинг виртуальных локальных сетей происходит в соответствии с 802.1q или с межкоммутаторным канальным протоколом (Inter-Switch Link Protocol, ISL) от Cisco;
- широко известные приложения — HTTP, FTP и т. д. — идентифицируются на основе стандартного номера порта;
- сложные приложения, например SAP, часто задействуют несколько портов; решение мониторинга может объединять эти данные, сопоставляя порты и IP-адреса сервера для определения общего использования;
- одноранговые приложения (Kazaa, Morpheus и прочие решения совместного использования файлов) часто задействуют другие порты помимо порта HTTP 80; для распознавания одноранговых приложений и сравнения схем трафика данных решения мониторинга могут следить за любыми сеансами TCP, если те не относятся к определенному порту приложения или широко известному приложению.
? AWi Verlag