

Кластеры на базе стандартного аппаратного обеспечения и Linux все чаще заменяют традиционные суперкомпьютеры и системы на базе симметричной многопроцессорной обработки. В зависимости от постановки задачи для управления системами предлагается широкий выбор программного обеспечения, как коммерческого, так и с открытыми кодами.
Одна из основных причин, все чаще побуждающая предприятия приобретать кластеры Linux, заключается в привлекательном соотношении «цена/производительность»: в системе применяются недорогие процессоры AMD и Intel, а производительность такого кластера сравнима с производительностью системы SMP на базе RISC. Кроме того, схожесть Linux и UNIX облегчает замену кластеров UNIX на кластеры с открытыми кодами.
При построении кластера Linux особого внимания требует программное обеспечение, решающее задачи управления, безопасности, администрирования и взаимодействия между узлами. В области открытых кодов можно запросто заблудиться в многообразии решений, которые в большинстве своем способны удовлетворить лишь часть предъявляемых к кластеру требований в отношении готовности, масштабируемости и управляемости. Однако предпринимаются и попытки объединения этих подходов.
КЛАСТЕР BEOWULF
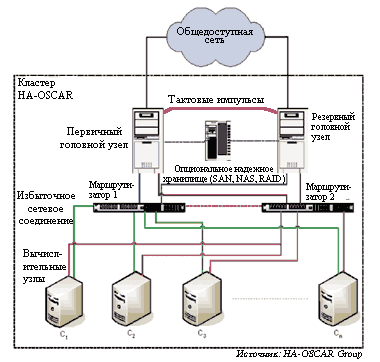
Наиболее старыми и, пожалуй, самыми известными кластерами Linux являются кластеры Beowulf для высокопроизводительных вычислений. Они состоят из множества машин, взаимодействующих между собой посредством высокоскоростной локальной сети и выполняющих параллельные программы, например моделирование погоды или добыча данных (Data Mining). Под термином Beowulf эксперты подразумевают как инструментарий, так и метод, благодаря которому компьютеры взаимодействуют друг с другом с целью обеспечения функционирования в параллельной среде. Сегодня многие предприятия предлагают программное обеспечение для кластеров Beowulf - от отдельных наборов инструментов до полноценных операционных систем наподобие Skyld Beowulf от Penguin Software. Университет Сан-Диего выпускает набор инструментов Rocks для разработки и управления этими кластерами, а Open Cluster Group вместе с High Availability Open Source Cluster Application Resources (HA-OSCAR) - целый ряд компонентов для инсталляции и управления кластерами Beowulf высокой готовности (см. Рисунок 1).
|
| Рисунок 1. Кластеры HA-OSCAR высокой готовности базируются на избыточных компонентах, механизмах распознавания и устранения ошибок, а также на архитектуре Beowulf. |
Концепция высокопроизводительных кластеров предусматривает наличие главного узла для управления остальными, однако над выполнением поставленных задач все узлы работают вместе. Программное обеспечение среди прочего включает в себя службы распределенных межпроцессных взаимодействий (Distributed Interprocess Communication, DIPC) для доступа к процессам в кластере, компоненты для связи карт Ethernet, а также библиотеки интерфейса передачи сообщений (Message Passing Interface, MPI) и параллельной виртуальной машины (Parallel Virtual Machine, PVM). PVM и MPI нужны для разработки приложений, чтобы они могли воспользоваться ресурсами всего кластера. Необходимость адаптации приложений представляет собой большой недостаток кластеров Beowulf, так как ограничивает их распространение научно-исследовательской деятельностью, где пользователи привыкли к созданию индивидуальных и специальных приложений.
Включение PVM и MPI в приложения становится излишним в OpenMosix (на данный момент в версии 2.4), поскольку программное обеспечение передает распределение ресурсов ядру. Дальнейшим развитием GPL проекта Mosix является расширение ядра, благодаря которому процессы могут прозрачно перемещаться с одного узла на другой, если там обработка будет происходить быстрее. Подобный кластер с балансировкой нагрузки идеально подходит для выполнения длительных заданий с интенсивной обработкой, когда не требуется массивная параллельная обработка. Миграция процессов прозрачна не только для приложения, но и для самого процесса, поскольку он «не замечает», что работает на удаленной системе. Для всех остальных процессов на исходном узле упомянутый процесс также работает локально.
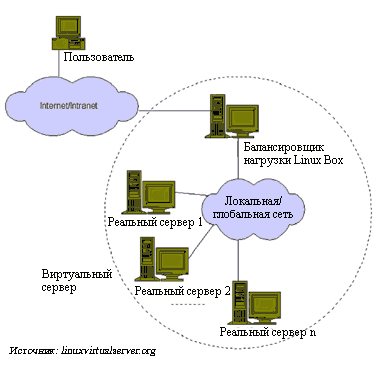
Как только заплата для ядра Linux инсталлирована, узлы начинают взаимодействовать друг с другом, кластер адаптируется к рабочей нагрузке и оптимизирует распределение ресурсов. Кластер ведет себя как симметричная многопроцессорная система и способен масштабироваться до более чем 1000 узлов (которые, в свою очередь, также могут быть узлами SMP). Скорость взаимодействия узлов определяется локальной сетью. Виртуальный сервер Linux также служит для балансировки нагрузки, хотя и иным образом. Поступающие из Web сервисные запросы распределяются по ряду стандартных серверов. Серверные узлы обычно вместе не работают. Архитектура кластера прозрачна для конечного пользователя, поэтому он взаимодействует с кластером так, как будто тот представляет собой единственный виртуальный сервер. Реальные серверы соединяются друг с другом по высокоскоростной локальной сети или распределенной глобальной сети. Внешний интерфейс сервера является балансировщиком нагрузки и, как таковой, размещает запросы на разных серверах (см. Рисунок 2), а также представляет параллельные службы кластера как виртуальную службу с одним-единственным IP-адресом. Благодаря добавлению узлов масштабируемость системы достигается прозрачно. Схожий подход использует Piranha: сервисные запросы из кластера Piranha поступают на адрес виртуального сервера, который состоит из протокола, плавающего IP-адреса и номера порта. Компьютер, в зависимости от его роли в кластере, может быть маршрутизатором или реальным сервером.
|
| Рисунок 2. При балансировке нагрузки по правилам виртуального сервера Linux входящие сервисные запросы распределяются между несколькими стандартными серверами. |
ФАЙЛОВЫЕ СИСТЕМЫ
Для обеспечения совместного использования устройств хранения в сети хранения (Storage Area Network, SAN) кластеру требуется файловая система с поддержкой кластера для параллельного согласованного доступа всех узлов к данным на любом носителе в SAN. Одним из наиболее известных пакетов для так называемых кластеров хранения, или кластеров разделения данных, является глобальная файловая система (Global File System, GFS) от Sistina, которая теперь принадлежит компании RedHat. Однако устройство хранения должно быть физически подключено к SAN, так что использование GFS ограничивается небольшими кластерами. Работы над версией с открытыми кодами ведутся в рамках проекта OpenGFS.
СЕТЕВЫЕ УСТРОЙСТВА ХРАНЕНИЯ В КЛАСТЕРЕ
Lustre, продукт компании Cluster File Systems, напротив, предлагает файловую систему для сетевых устройств хранения данных (Network Attached Storage, NAS) для крупных кластеров (помимо этого, имеются и несколько версий GPL). Lustre обходит «узкое» место в виде ограниченной производительности одного сервера CFS, без необходимости физического подключения каждого накопителя к каждому узлу. На всех узлах работает клиентский экземпляр файловой системы, причем клиент получает метаданные своих файлов от выделенного сервера и обращается к нескольким узлам хранения по прямому соединению.
При построении кластера Linux высокая степень готовности приложений часто становится главным требованием. Широкий спектр коммерческих предложений и решений с открытыми кодами существует для так называемых отказоустойчивых кластеров (failover cluster).
В связи с разработками в области кластеров Linux речь неизменно заходит о едином системном образе (Single System Image, SSI). Под этим понятием скрывается концепция отображения всех систем кластера как одной системы. Идея сама по себе не нова, и различные типы кластеров в определенном смысле являются разновидностями SSI. Кластер хранения данных представляется с помощью распределенной файловой системы как SSI прежде всего тогда, когда корневая файловая система используется всеми узлами. Единственный IP-адрес LVS также представляет внешнему миру SSI.
Scyld предлагает для кластеров Beowulf разновидность SSI, когда все процессы инициализируются управляющим узлом и потом распределяются по остальным. С управляющего узла за этими процессами можно следить так, как будто они работают на одной машине. Для пользователя кластер также предстает одной системой. С этой концепцией схожа концепция Mosix, различие лишь в том, что управляющих узлов может быть несколько (в случае Mosix они называются домашними). Процесс формируется на домашнем узле и может прозрачным образом мигрировать на другие, причем он и дальше будет «видеть» окружение своего домашнего узла.
И сообщество открытых кодов, и поставщики Linux работают над оснащением своего кластерного программного обеспечения дополнительными технологиями. Самая масштабная и одновременно самая претенциозная попытка предпринимается сейчас в рамках проекта Open SSI Cluster: цель заключается в объединении всех лучших технологий кластеризации Linux и UNIX, чтобы, по словам разработчиков, создать «идеальный кластер».
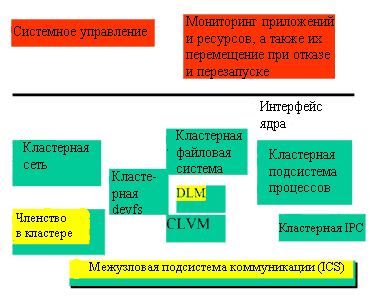
В кластере SSI имеется единственная разделяемая корневая операционная система, а каждый узел обладает собственным ядром ОС, который свои действия согласует с остальными. Отдельные ядра служат для обеспечения готовности и производительности, в то время как разделяемый корень облегчает управление и, по возможности, не должен содержать специфичных для узла файлов. Разделяемым корнем можно управлять с помощью параллельной физической файловой системы, такой, как GFS, или с какого-либо одного узла, и совместно использовать посредством кластерной файловой системы (Cluster File System, CFS). Это означает, что принадлежность к узлу (членство) должна быть очень узкой - все узлы обязаны знать и уважать эту принадлежность. Ядра предоставляют единую машину с высокой степенью готовности на уровне системных запросов благодаря наличию коммуникационных маршрутов между ними. Они образуют единое пространство имен для объектов ядра и обеспечивают единый распределенный доступ ко всем объектам: к процессам, файлам, очередям сообщений и устройствам (см. Рисунок 3).
|
| Рисунок 3. Компоненты кластеров SSI делятся на три категории: компоненты вне ядра для системного управления и обеспечения высокой готовности, инфраструктура ядра и расширения для имеющейся подсистемы ядра. |
ОБЪЕДИНЕНИЕ ТЕХНОЛОГИЙ
Кластерные компоненты SSI можно разделить на три категории: расширения для системного управления и обеспечения готовности за пределами ядра, модули инфраструктуры ядра для поддержки дополнительных функций и расширение имеющейся подсистемы ядра для представления объектов ядра в виде SSI.
Ряд компонентов на уровне системных вызовов позволяет реализовать любые типы кластеров. Компоненты частично являются собственными разработками, частично - заимствуются из других проектов сообщества. К ним относятся кластерная служба членства (Cluster Member Service, CLMS) для контроля за статусом каждого узла. Код ведет свое происхождение от Nonstop Clusters (NSC) - этот продукт Compaq и Caldera был предоставлен в распоряжение проекта кластерной инфраструктуры, - и обеспечивает для каждого узла одинаковый вид статуса всех остальных. Как и остальные подсистемы ядра, CLMS взаимодействует с подсистемой межузловой коммуникации (Internode Communication Subsystem, ICS), обеспечивающей маршрут для коммуникации между ядрами.
Еще один компонент - общекластерная файловая система, которая строится на базе таких различных подходов, как GFS, OpenGFS, Lustre или Ext3, FS (журнальная файловая система от IBM) или XFS (журнальная файловая система от SGI). Подсистема кластерных процессов делает все процессы каждого узла видимыми и доступными для остальных. Подсистема устройств обеспечивает доступ всех узлов к каждому устройству, в то время как распределенный менеджер блокировки заботится о различных формах когерентности кэша. Сетевая подсистема передает IP-адрес во внешний мир и управляет соединениями ТСР между узлами. Большая часть технологий заимствована из проекта LVS.
Open Clustering Framework не ставит таких высоких требований. Задача рабочей группы в рамках Free Standards Group заключается в определении программных интерфейсов приложений (Application Programming Interface, API) для обеспечения взаимодействия различных продуктов и проектов. Исходной точкой является схожесть функциональности служб кластерного членства, коммуникации или блокировки. Интероперабельная инфраструктура взаимодействия должна облегчить интеграцию разделенных хранилищ, менеджеров кластерных томов и файловых систем.
ПЕРСПЕКТИВЫ
Ни один из проектов пока не закрыт, работы продолжаются и в конечном счете должны способствовать поддержке нескольких кластерных подходов в одном решении. Безусловно, эту тенденцию стоит приветствовать, но с каждым днем пользователю все сложнее сделать свой выбор, а конца совершенствованию так и не видно.
Сюзанна Франке - независимый журналист из Мюнхена. С ней можно связаться по адресу: jos@lanline.awi.de.
Проект Linux BIOS
Для того чтобы Linux могла работать в рамках кластера, нужны различные расширения ядра и перекомпоновка дистрибутивов. К примеру, RedHat и SuSe сокращают свое предложение Linux до ядра, библиотек и компилятора.
Наиболее радикальные изменения предлагает LinuxBIOS. Этот проект GPL преследует цель замены имеющегося BIOS или встроенного программного обеспечения на компьютерах и рабочих станциях на ядро Linux и проведения перед запуском самого ядра инициализации аппаратного обеспечения, определения емкости памяти, самотестирования и проч. Базовая система ввода/вывода может быть построена на основе и без того обычно сильно сокращенного набора аппаратного обеспечения узла: преимущество заключается не только в очень небольшом времени перезагрузки, но и в повышении добавленной стоимости кластерных систем.
BIOS облегчает удаленное управление и конфигурацию серверов в кластере. Кроме того, она позволяет получить множество диагнозов запуска через последовательный порт системы и управлять процессом загрузки с последовательного терминала. Дополнительно программное обеспечение кластеров Linux предлагает режим замещения на случай отключения во время обновления BIOS. Вторая версия BIOS поддерживает минимум шесть процессоров и свыше 50 системных плат.
? AWi Verlag