
Тем, кто пользуется сетью хранения уже несколько лет, приходится бороться со старением компонентов, перегруженными соединениями и помехами вследствие интеграции устройств разных стандартов. Сети SAN становятся все сложнее и запутаннее. Оценки данных от отдельных компонентов часто недостаточно,тем более что физический уровень практически игнорируется.Как и в случае с локальными сетями,в подобной ситуации можно прибегнуть к инструментам для мониторинга и анализа.

Aнализ сетей хранения (Storage Area Network, SAN) в принципе идентичен с анализом локальной сети. Однако до сих пор он имел небольшое практическое значение, главным образом, потому, что SAN, как показывает опыт, работают надежно и стабильно: после запуска в эксплуатацию ошибок обычно не наблюдается, а если все-таки они проявляются, то быстро и легко локализуются и устраняются заменой компонентов. Проблемы, которые не могут быть устранены подобным образом, должны изучаться в лабораториях. Именно поэтому до сих пор вопросами анализа SAN занимался лишь узкий круг специалистов: инженеры службы поддержки производителей оборудования и крупных системных интеграторов.
Сегодня сложившаяся ситуация в корне изменилась, поскольку SAN все в большей степени становятся ненадежными. Причина происходящего кроется в следующих явлениях:
- старение конструктивных элементов;
- износ/загрязнение кабелей и штекеров;
- новые и развивающиеся стандарты;
- смешение и интеграция разных технологий;
- дополнительные устройства и компоненты;
- увеличение нагрузки;
- растущая сложность;
- виртуализация.
Все это способствует тому, что «чистые» среды SAN скоро исчезнут, а количество проблем, связанных с ними, возрастет. Поэтому производителям и пользователям гораздо больше времени придется тратить на мониторинг и/или анализ проблемных ситуаций (поиск и локализацию неисправностей).
ПРИНЦИП РАБОТЫ SAN
Сеть хранения состоит из серверов, коммутаторов и систем хранения данных. Как правило, между собой они соединяются волоконно-оптическими кабелями. Вообще говоря, стандарты на соединение посредством медных проводов существуют, но на практике такое встречается крайне редко.
Протокол Fibre Channel (FC) работает как механизм для передачи данных от одного порта FC на сервере к другому порту FC на системе хранения данных. Над уровнем Fibre Channel расположен уровень интерфейса малых компьютерных систем (Small Computer Systems Interface, SCSI), на котором организуются соединения между инициаторами SCSI (серверами) и целями SCSI/номерами LUN (системами хранения). На этом уровне серверы и системы хранения взаимодействуют по правилам SCSI. Нижележащий уровень Fibre Channel служит исключительно в качестве транспортного средства.
ФИЗИЧЕСКИЕ ИСТОЧНИКИ ПОМЕХ
Список возможных источников помех довольно велик. Большая часть проблем возникает на физическом уровне (см. Рисунок 1). К их числу относятся чересчур длинные, слишком изогнутые или механически поврежденные кабели, а также загрязненные штекерные соединения. Кроме того, оптические компоненты подвержены старению.
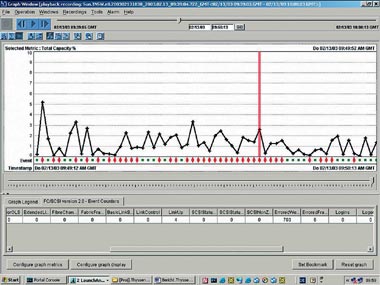
|
| Рисунок 1. Как видно из результатов измерений, физические ошибки привели к потере 90% производительности (источник: DDS). |
В отличие от полного отказа соединения, который можно мгновенно распознать и локализовать, названные причины ошибок приводят к другим последствиям. Как правило, пользователю о них ничего неизвестно, поскольку протокол Fibre Channel пытается их устранить самостоятельно и не предоставляет вышестоящему уровню SCSI никакой информации. То, что не может быть исправлено на уровне FC, регулируется на уровне SCSI. В принципе, передача данных в процессе устранения ошибок продолжается, однако производительность заметно падает.
НЕСОВМЕСТИМЫЕ КОМПОНЕНТЫ
Некорректное поведение некоторых активных компонентов также может стать возможным источником ошибок на уровнях Fibre Channel и SCSI. Функционирование компонентов определяется инсталлированным и стандартизированным микрокодом. Стандарты для Fibre Channel и SCSI продолжают разрабатываться, и это приводит к тому, что сеть хранения состоит из компонентов разных стандартов, из-за чего они оказываются несовместимы друг с другом. При этом могут применяться устройства с разными версиями микрокода.
К тому же велика вероятность, что с переходом от однородной системы к неоднородной в одной среде окажутся компоненты, которые не тестировались на совместную работу.
Если эти несоответствия значительны, то ошибку легко распознать и локализовать. Если же ошибка проявляется лишь в особенных рабочих или нагрузочных ситуациях, к примеру, в форме спорадически возникающих отключений системы, сбоев и/или падений производительности, она поначалу далеко неочевидна и уж точно не локализуема.
Наряду с программным обеспечением к помехам может привести некорректная конфигурация какого-либо компонента. В особенности это затрагивает уровень SCSI, а на нем, в свою очередь, серверы с их относительно сложным подключением к SAN.
ПЕРЕГРУЗКА
Следующая группа причин связана с перегрузкой SAN. Хотя SAN и в состоянии работать с определенной скоростью 1 или 2 Гбит/с, подключенные компоненты вовсе не обязательно поддерживают такую скорость. Подобные проблемы проявляются особенно в области резервного копирования данных, поскольку именно здесь, по естественным причинам, нагрузка наиболее высока. Но и в обычном режиме приложения, в частности базы данных, обмениваются большими объемами информации.
И, наконец, может случиться так, что влияющая на передачу данных причина ошибки кроется за пределами SAN, а обслуживающий техник пытается отыскать ее внутри системы.
РАСПОЗНАВАНИЕ ОШИБОК
В случае некоторых из описанных проблем ошибку можно устранить посредством замены компонента, обновления программного обеспечения или внесения изменений в конфигурацию. В противном случае следует провести анализ SAN. Необходимую для этого информацию получают от серверов, коммутаторов и массовых накопителей, входящих в SAN, поскольку через них проходит, как минимум, часть общего трафика данных. Однако серверы и массовые накопители или совсем не предоставляют техникам этих данных, или предоставляют в очень небольшом объеме. Коммутаторы позволяют осуществлять доступ либо через порты мониторинга, либо через их систему управления. Тем самым техник продвигается значительно дальше, причем глубоких знаний о Fibre Channel ему не требуется. Однако для всеобъемлющего анализа необходима информация, которой коммутатор не располагает, — сведения о физическом уровне и об уровнях SCSI. Информация о физическом уровне недоступна для коммутатора, поскольку он распознает лишь часть трафика данных на этом уровне. Информацию же об уровне SCSI он не получает потому, что уровень SCSI для него прозрачен.
Для того чтобы определить и оценить трафик данных в SAN, технику нужны такие измерительные приборы, которые подключаются к каналу Fibre Channel и получают информацию непосредственно с линии.
ИЗМЕРИТЕЛЬНЫЕ ПРИБОРЫ
Простейшим прибором для анализа SAN является тестер линии. Он проверяет трафик данных на ошибки и показывает их. С его помощью просто и эффективно можно установить факт наличия ошибок физического уровня в канале Fibre Channel.
На следующей стадии применяются зонды для мониторинга, они аналогичны зондам для удаленного мониторинга (Remote Monitoring, RMON) в локальных сетях. В процессе работы проводится наблюдение за трафиком данных, откуда извлекается статистическая информация и затем передается на компьютер, где сохраняется и анализируется. Массив статистической информации может быть обширным. В него входят все данные, начиная от информации об ошибках физического уровня и о замеченных событиях на уровне Fibre Channel, заканчивая распознаванием ошибок и выяснением зависимости времени ответа на уровне SCSI. Поскольку такая система обеспечивает возможность сохранения данных, она подходит также для долгосрочных оценок и длительного мониторинга: ошибки, проявляющиеся спорадически и через значительные промежутки времени, могут быть зафиксированы и позднее проанализированы (см. Рисунок 2).

|
| Рисунок 2. Анализ с использованием системы мониторинга качества услуг SAN от Finisar выявил спорадические сбои одного диска в системе хранения данных. |
Для детального анализа трафика данных можно использовать протокольные анализаторы. Эти устройства позволяют записывать трафик данных в определенной форме и позже просматривать его кадр за кадром в декодированном виде. Если учесть, что по каналу Fibre Channel в течение 7 с проходит 1 Гбайт данных, то нетрудно понять, что протокольный анализ на уровне Fibre Channel можно сравнить с поиском иголки в стоге сена. Поэтому гораздо проще, когда протокольный анализатор расшифровывает записанные данные и оценивает их при помощи экспертной системы. Так в коммуникации обнаруживаются задержки и прочие события. Имеющиеся на рынке протокольные анализаторы способны работать не только с каналами Fibre Channel, но и с другими технологиями передачи данных, в том числе с Ethernet и Infiniband.
При анализе SAN могут оказаться полезными тестер частоты появления ошибок, а также генераторы и манипуляторы данных.
При анализе канала Fibre Channel в качестве средств для подключения могут с успехом использоваться разветвители. Они разделяют поток данных, не влияя на работу сети, и интегрируются в канал Fibre Channel на постоянной основе. Для анализа канала техник подключает протокольный анализатор к разветвителю, причем соединение SAN не прерывается.
ПОИСК И ЛОКАЛИЗАЦИЯ НЕИСПРАВНОСТЕЙ
Анализ SAN при решении задач по поиску и локализации неисправностей нужен всегда. Техник должен как можно быстрее распознать проблемную ситуацию, определить ее причины и, исходя из этого, дать указания к устранению ошибок или выполнить эту работу самостоятельно. Не все помехи могут быть устранены путем замены компонента или обновления программного обеспечения. Проблему представляют помехи, затрагивающие производительность или время реакции, а также сбои системы, проявляющиеся только в особых ситуациях. За недостатком знаний причину часто ищут в SAN, когда она не имеет к ней никакого отношения. В таком случае крайне необходимо посоветоваться с ответственным и компетентным системным администратором.
ПРОФИЛАКТИКА
Сети хранения данных очень важны для предприятия, поэтому отказы SAN влекут за собой фатальные последствия. Анализ SAN — хорошая профилактическая мера для предотвращения помех. Он поможет избежать лихорадочного диагностирования возникших проблем.
Во время профилактического анализа администратор проверяет работоспособность SAN, чтобы вскрыть невидимые ошибки и получить общую картину нагрузки на SAN. Кроме того, моделирование специальных ситуаций, неотложные меры, балансировка и перевод нагрузки могут оказаться целесообразными для оценки резервов производительности. Превентивные проверки должны быть обязательной мерой после внесения изменений в SAN и/или регулярной процедурой для получения долгосрочной картины происходящих процессов.
ПЕРСПЕКТИВА
В будущем анализ SAN станет еще более важным, когда предприятия начнут совместно использовать технологии хранения SAN и сетевые устройства хранения данных (Network Attached Storage, NAS) и расширять их при помощи технологии на базе iSCSI. Переход от сетей 1 и 2 Гбит/с к сетям 4 и 10 Гбит/с, по сути, уже начался. При этом повысится значение сопряжения более быстрых распределенных сетей хранения данных посредством городских и глобальных сетей.
Intel и другие лаборатории разработчиков подготавливают в лице Infiniband еще один стандарт для сетей хранения данных. Это предъявляет дополнительные требования к измерительным устройствам для сетей хранения. Пока лишь немногие производители могут предложить необходимое для этого оборудование.
Бернд Канес — коммерческий директор компании DDS по разработке систем данных и диагностики. С ним можно связаться по адресу: http://www.dds.de.
?A Wi Verlag