
Сквозное управление производительностью сетевых приложений - необходимый шаг на пути к гарантированному качеству обслуживания.
Даже для того, чтобы просто заставить сетевые приложения работать, часто требуется немало усилий. Но для критически важных приложений необходимо, чтобы они не просто работали, а работали с требуемой производительностью. Для этого надо дополнительно организовать контроль и мониторинг производительности.
На управление производительностью влияют две важные тенденции. Во-первых, повсеместное распространение IP и уменьшающаяся стоимость пропускной способности сетей делают аутсорсинг приложений более целесообразным, чем когда-либо. Во-вторых, многие критически важные приложения имеют распределенную многоуровневую архитектуру, в соответствии с которой части приложения могут выполняться в разных, независимо управляемых сетях.
Организации могут доверить поддержку компонентов своих приложений разного рода провайдерам услуг, таким, как ASP (Application Service Provider), MSP (Managed Service Provider) и т. п. Однако провайдеры обычно не берут на себя обязательств по поддержке критически важных для корпоративных заказчиков приложений без заключения соглашения об уровне сервиса (Service Level Agreement, SLA). Традиционный тип SLA, используемый при подключении к сетям frame relay или Internet, в котором указываются усредненные значения характеристик, например среднее значение времени безотказной работы системы за месяц, в данном случае не подходит. Соглашение об уровне сервиса для каждого конкретного критически важного приложения должно быть детальным и структурированным.
Конечно, приложения должны быть доступны. Однако те характеристики доступности, которые обычно гарантируются провайдерами Internet — например коэффициент готовности не менее 99,7% за целый месяц, — не очень много говорят пользователю о том, как это может сказаться на его работе. Эти 2,16 ч (0,3% от 30 дней) простоя могут прийтись либо на время максимальной загрузки, либо на периоды «авралов» у заказчика. Во многих случаях показатель усредненного за месяц времени безотказной работы является крайне невыразительным.
Одним из наиболее важных требований, предъявляемых приложением к сети, является короткое и предсказуемое время отклика. Некоторые провайдеры Internet включают характеристику «задержка» в свои соглашения SLA, хотя обычно они обставляют ее столь многочисленными условиями, что гарантия практически теряет какую-либо ценность. В типичном случае гарантии касаются только трафика, который не выходит за пределы сети данного провайдера Internet. Кроме того, часто встречающееся в SLA усредненное значение задержки за длительный период времени, такой, как месяц, так же, как и грубая усредненная оценка коэффициента готовности, не дает пользователю возможности адекватно оценить реальную ситуацию.
Пользователи приложений могут воспользоваться другими измеряемыми характеристиками качества обслуживания, лучше отражающими практические потребности, чем коэффициент готовности или задержки. Например, процент незавершенных транзакций может быть важнее средних задержек выполнения. В некоторых случаях важной характеристикой может оказаться доля клиентов, полностью заполнивших экранные формы, а затем отказавшихся от сделки. А вот для участника видеоконференции задержка и ее вариация имеют гораздо большее значение, нежели характеристики, относящиеся к дискретным транзакциям.
Во многих случаях наиболее интересные метрики производительности специфичны для конкретного приложения. Пользователям могут оказаться недостаточны не только обычно гарантируемые характеристики производительности сети, но и общие характеристики производительности прикладного уровня, так как они также не всегда позволяют приемлемо оценить качество работы приложения.
СКВОЗНОЕ УПРАВЛЕНИЕ
В то время как повышенный спрос на детализированные соглашения SLA подразумевает управление, ориентированное на клиента, спрос на сквозное управление «из конца в конец» требует проникновения в сетевые элементы и серверы, у которых могут отсутствовать средства для измерения производительности. Новые многозвенные архитектуры приложений не всегда внедряются со встроенными средствами управления (см. Рисунок 1).
В снижение качества работы приложения могут внести свой вклад серверы приложений, обрабатывающие логику прикладной программы; серверы баз данных, передающие информацию на сервер приложений; устройства балансировки нагрузки, брандмауэры и модули VPN. В идеальном случае все эти устройства должны обладать возможностями управления производительностью. В случае особо важных приложений ситуация еще более осложняется, потому что многие их архитектурные компоненты защищены двойным или тройным резервированием.
Успешное сквозное управление производительностью еще не означает полной победы. Обычно транзакции и другие события, имеющие смысл на уровне приложений, интересны лишь в качестве составной части процесса ведения бизнеса. Например, оформление заказа клиента является частью таких процессов, как учет товаров на складе, отгрузка и проверка расчетных счетов. Конечная цель — не организация технических операций с серверами, дисковыми массивами, маршрутизаторами и другими устройствами, а организация процессов ведения бизнеса таким образом, чтобы они были эффективны и удобны для заказчиков, поставщиков, партнеров и сотрудников.
Традиционно создатели технологий управления производительностью приложений придерживаются трех основополагающих методик. Одна из них, ведущая свое происхождение еще от приложений для мэйнфреймов, заключается в добавлении программистом маркеров или точек остановки в тело программы с тем, чтобы данные о каждом критическом этапе работы приложения, который необходимо отследить, записывались в файл или передавались другому приложению.
Вторая методика включает отбор тех или иных потоков или всего трафика в сети, сопоставление запросов с ответами и формирование заключения о производительности приложения на основе анализа последовательности пакетов.
При третьей методике в непосредственной близости от каждого клиента или внутри сегмента локальной сети, в котором находится группа клиентов, устанавливается что-то вроде «паразитического» агента. Агент отслеживает события на уровне операционной системы, такие, например, как открытие окон или пересылка данных через экранные формы, и проводит измерения параметров, либо заданных заранее, либо выявленных в результате самостоятельно проведенного анализа.
Преимущество метода с программной точкой остановки состоит в том, что разработчики точно знают, какие события требуют аккуратной и всесторонней оценки, и в этом случае не возникает сомнений в корректности проведенного измерения. Более того, измерения могут проводиться на любом уровне детализации. Если приложение не позволяет с помощью стандартных методов получить легко интерпретируемые результаты измерений производительности, то его работа может оцениваться и контролироваться только путем специально проведенной модификации программы для обеспечения потребностей контроля.
К сожалению, только очень немногие клиент-серверные или многоуровневые приложения допускают такого рода модификацию. Неудача может постигнуть даже те предприятия, где готовы выделить для реализации заказных программных решений квалифицированный штат программистов: ничего не получится, если в приложении не были заранее предусмотрены, как минимум, точки вызова процедур обработки прерываний и подходящий интерфейс прикладного программирования (API).
Другим важным недостатком всех подходов к измерению производительности, связанных с модификацией программ, является то обстоятельство, что необходимые для этого высококвалифицированные кадры программистов немногочисленны, дороги, плохо управляемы и обычно выполняют свою работу не так быстро, как ожидается.
Подход с анализом трафика обладает тем большим преимуществом, что не требует вмешательства программистов в исследуемое приложение. Датчики или агенты, устанавливаемые в локальной сети в непосредственной близости от пользователя, являются, возможно, простейшим решением, если в качестве критерия выбрано количество подлежащих модификации компьютеров и соединений.
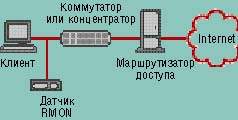 |
| Рисунок 2. Зонд RMON в разделяемой сети или агент RMON, встроенный в коммутатор, может отслеживать трафик в пределах определенной подсети. Однако датчики RMON 2 не могут диагностировать такие распространенные проблемы программных клиентов, как конкуренция |
Наиболее существенный недостаток метода анализа трафика — это ограниченность в выборе оценок производительности приложений. Получаемые при данном подходе общие характеристики не всегда дают возможность определить особенности поведения приложений. К тому же данные средства могут не выявить узкие места производительности на самом клиенте — связь между зондом и пользователем предоставляет для данного метода сбора информации что-то вроде «черного ящика» (см. Рисунок 2). В результате точность работы систем только на базе зондов может оказаться сомнительной, потому что лучшее, на что способно такое ПО управления производительностью, — это сделать предположения о начале и завершении транзакций, а также о структуре пакетных потоков.
Основное преимущество подхода с использованием клиентских агентов состоит в максимально возможной приближенности к пользователю. Агент, расположенный на машине клиента, легко отличит «время на раздумья» пользователя от задержек при обработке клиентских запросов. Отмечая момент начала и завершения транзакций, агент на клиенте является единственным источником достоверной информации о суммарном времени задержки на прохождение транзакции «туда и обратно» и позволяет сделать заключение об ее успешном завершении.
Наиболее значительный недостаток агентов на клиенте — их тесная связь с приложением. Такие программы нелегко внедрять в массовых количествах. Некоторые сочетания версий ОС, аппаратных средств и прикладного программного обеспечения могут вызывать проблемы установки и совместимости с агентом. Процедуры обновления агентов болезненны и дороги. Агенты, ориентированные на определенные ОС, требуют установки нескольких версий, в то время как их «коллеги» на платформе Java могут привести к необходимости обновления аппаратных средств во избежание неприемлемого снижения производительности. Кроме того, универсальные агенты не могут обеспечить такой же уровень детализации, как и при измерениях средствами заказных программ.
ПРОДУКТЫ УПРАВЛЕНИЯ ПРОИЗВОДИТЕЛЬНОСТЬЮ ПРИЛОЖЕНИЙ
Компания Manage.Com дальше других продвинулась в деле создания системы управления с поддержкой детального измерения и контроля производственных транзакций и процессов из конца в конец. Принципиальными компонентами ее платформы управления производительностью Frontline e.M являются: выделенный сервер Web Frontline e.M Server, который служит в качестве центрального хранилища данных и программ их обработки; e.Agents — апплеты Java, которые могут быть установлены на серверных и клиентских машинах по всему управляемому домену; Web-сайт e.Registry, на котором находятся обновленные сервисные программы и данные о конфигурации агентов; а также manageXML, диалект языка XML (Extensible Markup Language), с помощью которого осуществляется обмен информацией об обновлениях и конфигурации между компонентами системы Frontline e.M.
В декабре 2000 г. компания Manage. Com выпустила набор расширений для разработчиков, известный как Front-line Java Management Edition. Он включает комплект инструментальных средств управления созданием информационного наполнения и расширяемый адаптер приложений Java (Java Application Adapter) для прямого взаимодействия через JNI (Java Native Interface) с приложениями, написанными полностью на Java, с Enterprise Java Beans, а также с приложениями на Си и C++.
Для осуществления контроля и мониторинга транзакций и процессов при минимальном дополнительном программировании в адаптере приложений Java используется технология, которую Manage.Com называет Java Direct Connect. Во многих случаях нет необходимости переписывать исходный код — достаточно лишь установить новые классы объектов. Так как многие Web-ориентированные приложения, относящиеся к классу промежуточного ПО, а именно: серверы приложений, мониторы транзакций, продукты интеграции приложений и системы управления информационными ресурсами, построены на платформе Java, то применение Frontline e.M в значительной степени упрощает управление этими ключевыми компонентами процессов.
Инструменты Java Management Edition предназначены в первую очередь для предприятий и провайдеров услуг, чьи основные приложения разработаны на Java, однако обычная платформа Frontline e.M удовлетворяет большинству ключевых требований к управлению процессами ведения бизнеса на основе Web. Она позволяет измерять параметры клиентов и серверов, а также собирать данные SNMP от устройств и зондов, благодаря чему специалисты имеют возможность получать характеристики транзакции на всем пути ее прохождения
В этом случае формирование отчетов и предупреждений относительно производительности может выполняться не ретроспективно, а в реальном масштабе времени. Web-узел e.Registry в сочетании со службой защищенных соединений e.Connect представляет собой удачное решение проблемы распространения программных обновлений. При определенных условиях Java Direct Connect может обеспечить гибкость написания и внедрения заказного кода без необходимости изменения существующих программ.
Все основные разработчики управляющих платформ уже приняли меры по облегчению процесса модификации приложений таким образом, чтобы их производительность могла быть измерена в ясных и актуальных для заказчика показателях. Компании Hewlett-Packard и Tivoli внесли свой вклад в разработку интерфейса прикладного программирования ARM (Application Response Measurement, подробнее см. «Стандарты измерения производительности») в стандарте Open Group.
Hewlett-Packard разработала продукт OpenView VantagePoint Performance Agent с поддержкой ARM API, причем VantagePoint Performance Manager обеспечивает графическое представление архива измерений производительности, в то время как VantagePoint Performance Monitor предоставляет показатели производительности приложений и их компонентов в реальном времени. Программа HP OpenView Response Time Workbench предназначена для адаптации клиентских агентов под специфические приложения, а утилита MeasureWare Client Observer обеспечивает базовую инфраструктуру мониторинга для агента.
Компания Tivoli представила пакет программ управления производительностью приложений, в котором реализованы три возможных типа измерений параметров клиента. Приложения, адаптированные для использования с интерфейсом ARM API, позволяют легко оценить интервалы времени между запрограммированными точками начала и завершения транзакций. Такие действия клиента, как открытие новых окон или изменение ссылок на ресурсы, также могут быть связаны с точками старта и окончания транзакции. Наконец, фиктивный клиент может генерировать искусственные транзакции, которые полезны в качестве эталона для исследования сети и многоуровневых приложений. Предупреждения и информация мониторинга могут быть обработаны различными управляющими консолями Tivoli.
Computer Associates поставляет пакет Application Response Option для Unicenter TNG и NetworkIT. В него встроена поддержка наиболее популярного программного обеспечения: Lotus Notes, SAP R/3, PeopleSoft и Internet Explorer. Система измеряет суммарное время отклика, автоматически создает базовый уровень измерений и может дополнительно оснащаться средствами сбора статистики для специфических приложений.
NetScout Systems давно занимается зондами RMON. Свою деятельность в области управления производительностью компания начала с измерения параметров потоков приложений зондами собственного производства на базе RMON 2. NetScout была создана и опубликована база управляющей информации о времени отклика приложений (Application Response Time, ART) для отслеживания данных о производительности приложений с помощью RMON 2.
Компания представила свое семейство продуктов управления производительностью Ngenius в мае 2000 г., однако после приобретения в июле 2000 г. компании NextPoint Networks, специализирующейся в области управления уровнем обслуживания, она предложила заказчикам пакет программ на основе пользовательского агента — Ngenius Application Service Level Manager.
Concord Communications начала свою деятельность не с завершенной платформы управления, а с продукта для мониторинга и формирования отчетов, собирающего данные от имеющихся у заказчика агентов SNMP и RMON. Несмотря на большой успех в области мониторинга сетей и трафика, Concord увидела перспективу повышения спроса на системы сквозного управления приложениями и сделала два ключевых приобретения. В октябре 1999 г. произошло слияние Concord и Empire Technologies, открывшее компании доступ к ПО управления производительностью серверных приложений. В январе 2000 г. Concord приобрела FirstSense Software и стала обладателем ее высокоразвитой технологии клиентских агентов.
Клиентские программы Concord/ FirstSense экономичны в отношении потребляемых ресурсов. Фактически они запрограммированы на самоуничтожение, если начинают по каким-либо причинам слишком сильно загружать процессор (обычно при превышении отметки 3—5% от полной производительности). В такой же минимальной степени данные агенты используют и ресурсы сети, так как по ней передается только кратковременный поток обобщенной статистической информации, обычно с 15-минутным интервалом. В случае разрыва связи между агентом и контроллером агент будет сохранять все данные, пока это будет позволять емкость его памяти. FirstSense успешно решила проблему распространения клиентских агентов, предоставляя на выбор возможность передачи программ по электронной почте, через Web или путем принудительной доставки на ПК пользователя (push-технологии), обеспечивая также автоматическую установку и регистрацию.
Другим производителем, деятельность которого начиналась с разработки решений управления производительностью приложений на основе сетевых зондов, является CompuWare. Семейство продуктов управления приложениями CompuWare, называемое EcoTEMS, включает систему измерения производительности на базе зондов — EcoSCOPE, и специфическую для приложения серверную часть системы управления — Eco-TOOLS. EcoSCOPE функционирует во многом так же, как NetScout Application Flow Management: зонд используется для централизованного исследования передаваемых пакетов и отнесения каждого из них к специфическому потоку приложения с учетом адресов источника и назначения, номеров портов, ссылок на ресурсы и других характерных атрибутов пакета. Вставляя отметки о времени в пакеты для каждого потока, зонд позволяет выяснить время отклика пользователя без использования клиентского агента.
CompuWare также предлагает интересные инструменты для разработки и тестирования программ измерения производительности приложений. Application Expert и Application Vantage, унаследованные в результате приобретения компании Optimal Net-works в июле 2000 г., обладают уникальными возможностями обнаружения и визуализации узких мест сетевых приложений. В декабре 1999 г. Compu-Ware приобрела также CACI Products и включила в свое семейство решений продукты моделирования трафика и планирования загрузки ресурсов, разработанные этой компанией. Теперь данные продукты называются Eco-PROFILER, EcoPREDICTOR и COMNET III.
BMC Software занимается проблемами управления производительностью приложений еще с тех времен, когда миром правили мэйнфреймы. До недавнего времени большая часть усилий компании по управлению производительностью клиент-серверных программ ограничивалась разработкой для определенных приложений и операционных систем модулей для контроля за показателями производительности сервера. Продукты семейства решений BMC PATROL поддерживают многие версии UNIX, Windows 2000 и NT, NetWare, Oracle, Ingres, Informix, Sybase, Lotus Domino, Microsoft Exchange, SAP, Baan, а также такое связующее ПО, как Tuxedo и IBM MQ. Модули PATROL не только отслеживают отдельные характеристики серверных процессов, но также могут генерировать искусственные транзакции для сквозной оценки производительности.
PATROL для Service Level Management работает в сочетании с модулями приложений, обеспечивая поддержку разработки и реализации соглашений SLA. Организации, где уже используются компоненты PATROL или имеются серьезные проблемы с производительностью приложений, включая унаследованные системы, большие базы данных и хранилища информации, будут удовлетворены широким спектром новых продуктов BMC, подкрепленных профессиональным сервисным обслуживанием и возможностью обучения персонала заказчика.
Другой поставщик решений, чья деятельность начиналась с управления серверами, — это Dirig Software. Компания Dirig называет свою технологию агентов Proctor и предлагает две ее версии — RelyENT для корпоративных пользователей и xSPress для ASP и других провайдеров. Основным различием между двумя версиями является то, что xSPress поддерживает множественные независимые представления данных об измерениях производительности, поэтому провайдеры могут представлять индивидуальные отчеты каждому своему клиенту.
Агент Proctor реализован в виде процесса-демона в обычных версиях ОС UNIX и в виде службы в Windows NT. Взаимодействие с ним возможно по протоколам SNMP, HTTP или FTP. Размещенные в различных точках сети субагенты передают информацию о системных ресурсах, наблюдают за процессами и файлами журналов регистрации событий, выполняя в случае необходимости корректирующие действия. Специализированные версии Application Manager доступны для серверов Web Apache и Microsoft IIS; СУБД Oracle, Progress и SQL Server; Microsoft Exchange, а также Citrix MetaFrame и Microsoft Terminal Server Edition.
Продукты поставляются с комплектом программ для разработчика, чтобы сетевые администраторы имели возможность конфигурировать все функции управления производительностью приложений в случае использования заказных программ. Продукты Dirig не относятся к числу законченных решений, обеспечивающих сквозное управление производительностью, поэтому Dirig тесно сотрудничает с компаниями Aprisma и HP OpenView, которые включают его продукты в свои системы.
ПОДХОДЫ НА ОСНОВЕ АГЕНТОВ
Основу подхода к управлению производительностью приложений подразделения NetworkCare компании Lucent Technologies составляют клиентские агенты. В результате ряда приобретений Lucent унаследовала клиента VitalAgent, первоначально выпущенного в виде отдельного продукта и предназначенного для решения сложной задачи — оценки производительности каждого элемента распределенного приложения со стороны клиента. Lucent разработала дополнения к VitalAgent: VitalNet, предоставляющее информацию о производительности сети и сервера; VitalAnalysis — приложение консоли, которое агрегирует и обрабатывает данные о производительности, формирует отчеты и отслеживает выполнение SLA; программу BTMS, осуществляющую мониторинг производительности реальных транзакций; Automon — средство создания и измерения параметров прохождения искусственных транзакций; а также VitalHelp — инструмент обнаружения и устранения проблем, который позволяет выявить ошибки до того, как они станут очевидны пользователям. Полный набор всех этих компонентов называется VitalSuite.
В октябре 2000 г. Lucent представила версию VitalSuite SP, специально разработанную для нужд провайдеров. В ней поддерживаются не только независимые представления данных для заказчиков (и соответствующие отчеты), но и агрегированные представления для провайдера; ее усовершенствованный вариант способен поддерживать миллионы пользователей. Если возможности VitalSuite SP соответствуют заявлениям Lucent, то данный продукт может стать тем средством сквозного управления качеством обслуживания, в котором так нуждаются провайдеры услуг.
Pegasus компании NetIQ, объединившейся в мае 2000 г. с Mission Critical Software, которая ранее в свою очередь приобрела первого разработчика Pegasus — компанию Ganymede Software, является еще одним ориентированным на клиента менеджером сквозного управления производительностью приложений. В точках установки Pegasus может отслеживать реальное время отклика транзакции или генерировать искусственные транзакции. NetIQ также поставляет инструменты измерения производительности для разработчиков приложений и проектировщиков сетей.
Поддерживает ли предприятие критически важные приложения своими силами или передает их сопровождение провайдеру услуг, в любом случае должно быть заключено контролируемое соглашение SLA. Поэтому провайдеры услуг по сопровождению приложений (и подобные им организации), а также корпоративные специалисты по информационным технологиям скоро будут вынуждены создавать инфраструктуру, способную проверить выполнение таких соглашений.
Некоторые пункты ориентированных на приложения соглашений SLA сегодня не могут контролироваться с помощью готовых продуктов. В таком случае единственно возможным выходом будет внедрение средств управления, где предусматривается возможность программных разработок, включая индивидуальную настройку агентов. Ясно также, что хорошей замены прямому измерению параметров не существует, как минимум, для некоторых клиентов и что измерения параметров выполнения искусственных и реальных транзакций играют одинаково важную роль. Кроме того, средства управления, которые просто отслеживают бизнес-процессы и подают сигналы тревоги, менее предпочтительны, чем средства, которые могут, например, перезапустить «зависший» процесс или перенаправить излишек вычислительной нагрузки на альтернативный сервер. Большинство упомянутых в данной статье провайдеров сходится в поддержке этих принципов.
Промышленность еще не достигла той точки развития, когда внедрение комплексных бизнес-процессов могло бы проводиться последовательно, с заключением приемлемых соглашений SLA и с использованием компонентов plug-and-play. К сожалению, условия разработки заказного ПО таковы, что только очень устойчивые в финансовом отношении предприятия или провайдеры могут позволить себе пойти на риск возможного провала дорогостоящих проектов разработки ПО. С другой стороны, трудно представить, что без комплексной инфраструктуры контроля провайдер услуг добьется крупного успеха в деле сопровождения приложений. В конечном счете развитие коммерции на основе Web зависит от успешной эволюции средств управления производительностью приложений.
Стив Штайнке — главный редактор Network Magazine. С ним можно связаться по адресу: ssteinke@cmp.com.
Стандарты измерения производительности
Компании Hewlett-Packard и Tivoli первыми внесли свой вклад в то, что сейчас называется интерфейсом программирования измерения отклика приложений (Application Response Measurement, ARM API) — набор библиотек, с помощью которых разработчики могут включить измерения времени отклика в свои приложения. Хотя многие известные поставщики являются членами Open Group и даже приняли участие в создании ARM API, только мизерная доля приложений была разработана с использованием такой формы встроенных средств измерения.
Альтернативой Open Group API является интерфейс прикладного программирования AIC (Application Instrumentation and Control API), получивший поддержку Computer Associates, Tivoli, IBM, BMC Software и прочих разработчиков. В стандарте ARM API предусмотрены функции мониторинга, но отсутствуют возможности контроля, что ограничивает полезность этого стандарта для организации автоматизированных или обусловленных откликов на нарушения уровня обслуживания. Кроме того, AIC API поддерживает дополнительно подключаемые компоненты безопасности. Computer Associates создала пакет ПО разработчика программ AIC, который можно загрузить, обратившись по адресу: http://www.cai.com/solutions/enterprise/ app_db/aic_sdk_download.htm.
Группа Distributed Management Task Force (DMTF) разработала объектно-ориентированную модель CIM (Common Information Model), предназначенную для отображения взаимосвязей компьютеров, сетей, операционных систем, приложений, принтеров и прочих устройств. Кроме того, DMTF предлагает методы, с помощью которых управляющие приложения могут обмениваться информацией по стандарту CIM через HTTP, используя язык XML. Практически каждый заметный производитель, деятельность технико-политических подразделений которого каким-либо образом касается подобных вопросов, входит в DMTF и поддерживает эти стандарты. Группа включает Microsoft, Novell, Sun Microsystems, IBM, HP, Cisco Systems, Nortel Networks, Lucent Technologies, 3Com, Avaya, Computer Associates, Tivoli, CompuWare, Manage.Com, BMC Software, Compaq Computer и Dell Computer. Весьма вероятно, что доминирующие механизмы уровня обслуживания будущего будут совместимы с моделью DMTF.
Java выглядит привлекательно для целей управления, так как программные коды не требуется преобразовывать для выполнения на различных платформах. Набор библиотек классов JMX (Java Management Extensions) поддерживает разработку функций управления в приложениях и агентах, написанных на Java.
Рассматриваемые продукты
BMC Software
PATROL
http://www.bmc.com/patrol/
Computer Associates
Application Response Option
http://www.ca.com/products/ tng_application_response.htm
CompuWare
EcoSYSTEMs
http://www.compuware.com/products/ecosystems/
Concord Communications
http://www.concord.com
Dirig Software
RelyENT, xSPress
http://www.dirig.com
Hewlett-Packard
OpenView VantagePoint
http://www.managementsoftware.hp.com
Lucent Technologies
VitalSuite
http://www.lucent.com/networkcare/
Manage.Сom
Frontline e.M
http://www.manage.com
NetIQ
Pegasus
http://www.netiq.com/products/network_performance/
NetScout Systems
ngenius
http://www.netscout.com
Tivoli
Application Performance Management
http://www.tivoli.com
Ресурсы Internet
Интересную колонку Тома Нолле можно найти в выпуске Business Communications Review за август 2000 г. К сожалению, на момент написания данной статьи она не была доступна ни на Web-узле BCR, ни в архиве по адресу: http://www.computer-select.com, поэтому вам придется найти бумажную копию. В ней приведено исследование корреляции между измерениями качества обслуживания (Quality of Service, QoS) сети и канала передачи данных, с одной стороны, и приложениями, использующими эти службы, с другой, а также рассмотрены некоторые меры по управлению производительностью приложений, от которых пользователи могут получить реальную пользу.
Lucent Technologies опубликовала ценное руководство по измерению параметров транзакций под названием «Business Transaction Management». Загляните на Web-страницу http://www.lucentnetworkcare.com/knowledge/ whitepapers/buz_trans_mngt.asp/.
Мне довелось видеть очень полезное руководство Lucent VitalSoft под названием «Managing Service Provider Environments», но я не смог его найти на Web-узле Lucent. Возможно, оно будет там размещено к моменту публикации этого материала.
Вы можете загрузить различные руководства по управлению производительностью с Web-узла Concord Communications, включая «An Architecture that Delivers True End User Views of Application Performance», в котором рассмотрены многие подробности FirstSense Enterprise. Загляните на страницу http://www.firstsense.com/resctr/white/white.htm.
Если вы согласитесь заполнить анкету компании Manage.Com на странице http://www.manage.com/eMgmt/jmwhitepaper.html, то сможете загрузить хорошее руководство Джона МакКоннела под названием «Smoo-thing eBusiness Speed Bumps», в котором обсуждаются достоинства и недостатки передачи разработки и сопровождения приложений провайдерам услуг, а также то, чем семейство продуктов Manage.Com способно в этом помочь.