

Общие характеристики кластеров младшего класса. Кластеры от Microsoft, Novell и Santa Cruz Operation.
Мы созданы Богом,
чтобы облагородить этот мир.
Бисмарк.
Одно из решений заключается в объединении нескольких серверов в одну систему с тем, чтобы серверы дублировали друг друга в случае отказа или поломки одного из них. Но если уж объединять компьютеры, то так, чтобы они не просто дублировали друг друга, но и выполняли другую полезную работу, распределяя нагрузку между собой. Для этого во многих случаях как нельзя лучше подходят кластеры.
Кластерные технологии наконец-то достигли такого уровня развития, когда их использование стало доступно рядовым организациям. Это стало возможным, прежде всего, благодаря тому, что в кластерах младшего класса используются недорогие серверы Intel, стандартные средства коммуникации и распространенные операционные системы.
Исторически кластеры использовались для размещения корпоративных баз данных, в дальнейшем их стали применять для сервиса Web. Однако снижение цен на кластеры привело к тому, что их все активнее применяют для сервисов файлов и печати.
Именно доступность недорогих кластеров для предоставления практически любых сетевых служб подвигла нас более подробно присмотреться к ним. Как показывают опросы сетевых администраторов, немалое их количество имеет лишь смутное представление о кластерных технологиях. Многие до сих пор считают кластеры экзотическими системами, весьма сложными в эксплуатации и требующими колоссальных финансовых затрат.
Кластеры старшего класса, где применяются закрытые и, следовательно, дорогие технологии, в данном обзоре рассматриваться не будут, поскольку по финансовым соображениям они недоступны для большинства предприятий. Выбор был сделан в пользу кластерных технологий самого низкого ценового уровня, и в результате он естественным образом ограничился решениями на базе процессоров Intel. При этом мы рассматривали продукты «из коробки» («out of box»), т. е. не требующие большой подготовительной работы по запуску кластера в эксплуатацию, имеющие хорошо проработанную документацию и поддерживающие стандартные компоненты. Но и это еще не все критерии отбора.
На рынке кластерных решений для Intel (как программно-аппаратных, так и чисто программных) работает несколько десятков компаний, предлагающих самые разные решения. Однако большинство из них имеет слишком узкую специализацию и занимает незначительную долю рынка.
Поэтому мы решили остановиться на кластерных решениях от компаний Microsoft, Novell и Santa Cruz Operation. В подготовке обзора существенную помощь нам оказали сотрудники компании Hadler Networks, специализирующейся на поставках и установке кластеров на базе Windows и NetWare. По кластерам SCO UnixWare подробную информацию нам предоставило (к сожалению, недавно упраздненное) представительство SCO в Москве в лице Игоря Федорова.
Вначале мы планировали рассмотреть также продукты для Linux. Однако ряд обстоятельств не позволил этого сделать. Прежде всего, это связано с недостатком времени, ограничениями на размер статьи и сложностью тестирования кластерных продуктов для Linux. Нам известно как минимум три кластерных решения для Linux, но только TurboCluster Server на базе TurboLinux можно отнести к категории «out of box». Однако это продукт платный, причем для кластера из двух узлов пакет обойдется в 1000 долларов, а для большего количества узлов — в 2000 долларов. К тому же его нельзя заказать в России, что накладывает дополнительные ограничения.
Кластерные решения Beowulf и Mosix широко используются для вычислительных задач на платформе Linux, но имеют неприятные ограничения при использовании в качестве обычного сетевого сервера. По удобству инсталляции и настройке, а также по качеству документации они серьезно уступают решениям Microsoft или Novell.
Тем не менее мы планируем в свое время обратиться к теме кластерных решений на базе Linux, тем более что они быстро набирают популярность и к тому же стоят (если, конечно, считать стоимость только ПО) недорого или вообще доступны бесплатно.
ОБЩИЕ ПОНЯТИЯ
Прежде чем рассматривать конкретные технологии, остановимся на общих понятиях, характеристиках и особенностях кластеров.
Термин «кластер» имеет множество определений. Некоторые производители относят к кластерам системы NUMA, CC-NUMA, NUMA-Q, массово-параллельные системы, а порой и системы с симметричной многопроцессорной обработкой (Symmetric Multiprocessing, SMP). Одни во главу угла ставят отказоустойчивость, другие — масштабируемость, третьи — управляемость.
Мы же будем придерживаться классического определения кластера, данного общепризнанным корифеем в этой области Грегори Пфистером:
«Кластер — это разновидность параллельной или распределенной системы, которая:
- состоит из нескольких связанных между собой компьютеров;
- используется как единый, унифицированный компьютерный ресурс».
Как видно из определения, кластер представляет собой объединение нескольких компьютеров, которые на определенном уровне абстракции управляются и используются как единое целое.
Из определения также логически следует, что на каждом узле кластера (узел кластера — это компьютер, входящий в состав кластера) находится своя собственная копия операционной системы. Между тем такие системы, как SMP и NUMA, имеют одну общую копию ОС, поэтому их никак нельзя считать кластерами. Узлом кластера может быть как однопроцессорный, так и многопроцессорный компьютер, причем в пределах одного кластера компьютеры могут иметь различную конфигурацию (разное количество процессоров, оперативную память, емкость дисков). Узлы кластера соединяются между собой (внутрикластерное или межузловое соединение) с помощью либо обычных сетевых соединений (Ethernet, FDDI, Fibre Channel), либо посредством нестандартных технологий. Внутрикластерные соединения позволяют узлам взаимодействовать между собой независимо от внешней сетевой среды. По внутрикластерным каналам узлы не только обмениваются информацией, но и осуществляют контроль за работоспособностью друг друга.
Основное назначение кластера состоит в обеспечении:
- высокого уровня доступности (High Availability), иначе называемого уровнем готовности;
- высокой степени масштабируемости;
- удобства администрирования по сравнению с разрозненным набором компьютеров или серверов.
Иными словами, кластеры позволяют значительно повысить отказоустойчивость сетевых служб и увеличить их производительность с сохранением простоты администрирования и использования. Кластеры должны быть нечувствительны к одиночным отказам компонентов (как аппаратных, так и программных); в общем случае, при отказе какого-либо узла сетевые сервисы или приложения автоматически переносятся (запускаются) на другие узлы. При восстановлении работоспособности отказавшего узла приложения могут быть перенесены на него обратно.
Прежде чем говорить о характеристиках кластеров, мы кратко остановимся на возможных конфигурациях кластеров.
Кластерных конфигураций существует огромное количество, уже упоминавшийся Пфистер насчитал около 60 только аппаратных конфигураций, притом порой самых немыслимых. Иногда то, что называют кластером, представляет собой объединение нескольких кластеров, да еще вместе с дополнительными устройствами. Тем не менее, каким бы экзотическим ни был кластер, его всегда можно квалифицировать в соответствии с двумя критериями.
Первый характеризует оперативную память узлов кластера. Здесь возможны два варианта: либо все узлы кластера имеют независимую оперативную память, либо у них существует общая разделяемая память (возможно, вдобавок к независимой памяти), доступная всем узлам кластера. За очень редким исключением, разделяемая модель оперативной памяти в кластерах не используется. Во всяком случае это утверждение справедливо для всех кластеров младшего класса.
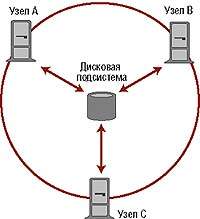 |
| Рисунок 1. Кластер с разделяемой дисковой подсистемой. |
Второй критерий характеризует степень доступности устройств ввода/вывода и, прежде всего, дисков. Понятие кластеров с разделяемыми дисками (shared disk) подразумевает, что любой узел имеет прозрачный доступ к любой файловой системе общего дискового пространства (см. Рисунок 1). Разумеется, помимо разделяемой дисковой подсистемы на узлах кластера могут иметься локальные диски, но в этом случае они используются, главным образом, для загрузки ОС на узле. Такой кластер должен иметь специальную подсистему, называемую «распределенный менеджер блокировок» (Distributed Lock Manager, DLM), для устранения конфликтов при одновременной записи в файлы с разных узлов кластера.
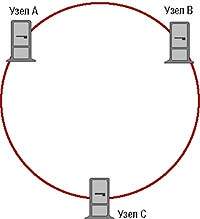 |
| Рисунок 2. Кластер без разделения ресурсов. |
Кластеры без разделения ресурсов (shared nothing), как и следует из названия, не имеют общих устройств ввода/вывода (см. Рисунок 2). Правда, здесь есть одна тонкость: речь идет об отсутствии общих дисков на логическом, а не на физическом уровне. Это означает, что на самом деле дисковая подсистема может быть подключена сразу ко всем узлам. Если на дисковой подсистеме имеется несколько файловых систем (или логических/физических дисков), то в любой конкретный момент времени доступ к определенной файловой системе предоставляется только одному узлу. К другой файловой системе доступ может иметь (т. е. владеть ресурсом) совсем другой узел (см. Рисунок 3).
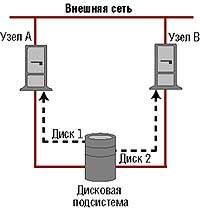 |
| Рисунок 3. Кластер без разделения ресурсов, но с общей дисковой подсистемой. Пунктирной линией показан доступ к дискам. |
Такая схема применяется для того, чтобы в случае отказа одного узла ресурс мог быть передан другому узлу. Например, если узел A владеет диском 1, а узел B — диском 2, то при отказе узла A узел B получит прямой доступ (права владения ресурсом) как к диску 2, так и к диску 1. За счет этого, собственно говоря, и достигается высокий уровень доступности в кластерах без разделения ресурсов с общей дисковой системой. Дисковые подсистемы обычно подключают через разделяемый интерфейс SCSI либо с помощью Fibre Channel.
В некоторых кластерных конфигурациях без разделения ресурсов с общей дисковой подсистемой узел может получать доступ к не принадлежащему ему ресурсу косвенным путем, через владельца ресурса.
Тем не менее широкое применение, особенно для вычислительных задач и сервиса Web, получили кластеры, у которых общие ресурсы вообще отсутствуют, даже подключенные на физическом уровне. Обычно в качестве хранилища информации они задействуют внешние серверы (файловые, СУБД и т. д.).
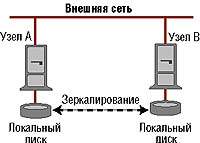 |
| Рисунок 4. Кластер с зеркальным копированием локальных дисков. |
В соответствии с еще одной схемой локальные диски узлов кластера зеркалируются (дублируются) (см. Рисунок 4). Очевидно, что такой подход годится только для задач, решение которых не возлагает значительной нагрузки на дисковые подсистемы.
Наиболее просто на аппаратном уровне и уровне ОС реализовать схему с разделяемыми дисками, поскольку для этого достаточно установить многоканальную дисковую подсистему (это позволяют сделать многие массивы RAID) и подключить ее к узлам кластера, чтобы получить доступ к любой файловой системе. Однако написание DLM представляет собой исключительно сложную задачу, поэтому такие решения достаточно дороги. Большинство современных кластеров (и не только для процессоров Intel) задействует схему без разделения ресурсов с общей дисковой подсистемой. Ее организовать гораздо проще, хотя она и требует определенных усилий по модернизации ОС и/или программного обеспечения.
Следует иметь в виду, что возможны случаи, когда в кластере одновременно применяются на первый взгляд взаимоисключающие схемы. Например, в решении Microsoft Cluster Service используется схема без разделения ресурсов с общей дисковой подсистемой. Однако оно позволяет параллельно использовать и схему с разделяемыми дисками за счет размещения на общей дисковой подсистеме файловых систем без назначения им типа «кластерный диск». Другими словами, все узлы могут обращаться к такой файловой системе напрямую. Однако за доступ к ней Cluster Service не отвечает, поэтому пользователю придется приобрести или написать соответствующий DLM. При этом использующие схему с разделяемыми дисками программы вообще не должны задействовать сервисы Cluster Service, вернее, они обязаны опираться при доступе к файлам только на DLM.
ПРОГРАММЫ ДЛЯ КЛАСТЕРОВ
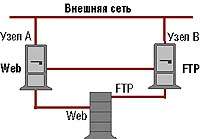 |
| Рисунок 5. Пример использования кластера. |
Выполняемые кластером программы условно делятся на три категории: обычные, рассчитанные на работу в кластере (cluster-aware) и истинно кластерные. Ниже мы рассмотрим каждую из них подробнее, применительно к схеме без разделения ресурсов с общей дисковой системой, так как она является наиболее популярной на рынке недорогих кластеров.
Кстати говоря, большинство не сведущих в кластерных технологиях людей в первую очередь интересует вопрос о возможности использования в кластерах обычных программ. На данный вопрос можно ответить утвердительно, хотя это справедливо не для всех приложений. Но об исключениях чуть позже.
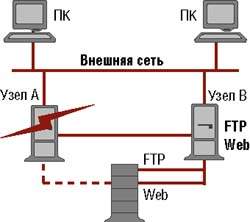 |
| Рисунок 6. Отказ одного узла кластера. |
Да, действительно, на любом узле можно запустить обычную программу. Например, на узле A можно запустить сервис Web, а на узле B — сервис ftp. При этом сервис Web использует файловую систему Web, а сервис ftp — файловую систему ftp (см. Рисунок 5). Допустим, произошел отказ узла A (см. Рисунок 6). В этом случае файловая система Web перейдет в распоряжение узла B, вместе с тем, на этом же узле будет запущен сервис Web. Данная процедура носит название миграции (failover) процесса и его ресурса. Процедура передачи прав на ресурс и условия миграции приложения задаются администратором по своему усмотрению. В частности, администратор может вообще отменить миграцию или, в случае нескольких узлов, оговорить приоритет миграции по узлам. При восстановлении работоспособности узла A сервис Web вновь перейдет (failback) в его владение. Опять же, администратор может определить условие, чтобы обратная миграция не производилась.
Кроме того, одну и ту же программу можно запускать на разных узлах кластера. Однако каждая копия программы должна использовать свой собственный ресурс (файловую систему), поскольку файловая система закрепляется за конкретным узлом. Таким образом, на узле A можно запустить сервер Web, обслуживающий домен asme.com, а на узле B — сервер Web, обслуживающий домен anybody.com. При отказе узла A сервис Web домена asme.com и используемая им файловая система отойдут к узлу B.
Кластеры подходят и для обычных сервисов файлов и печати. В частности, узел A может обслуживать файловую систему DATA, а узел B — PROGRAMS. Тогда даже при отказе одного узла файловые системы будут доступны через другие узлы благодаря миграции ресурсов.
Подводя некоторый итог, можно утверждать, что масштабирование и увеличение производительности кластера для обычных приложений и служб достигаются путем их распределения между узлами.
Следует помнить, что не все приложения и службы поддерживают миграцию, хотя их и значительное меньшинство. Например, если в кластере Microsoft NT некий узел является главным контроллером домена, то при отказе узла полномочия главного контроллера не могут автоматически переноситься на другой узел.
Помимо обычных программ для кластеров существуют так называемые истинно кластерные приложения. Такие программы как бы разносятся по узлам кластера, а между частями программы, функционирующими на разных узлах, организуется взаимодействие. Истинно кластерные программы позволяют распараллелить нагрузку на кластер. В первом приближении можно считать, что любой узел кластера может обслуживать любой запрос клиента, за счет чего достигается динамическое выравнивание нагрузки на узлы кластера.
Написание истинно кластерных приложений представляет собой очень сложную и трудоемкую задачу, более того, программы, написанные в расчете на параллелизм SMP, не будут полноценно работать на кластерах, и наоборот. Однако истинно кластерные программы позволяют добиться максимальной отдачи от кластера. Подходов к написанию истинно кластерных программ существует множество, но большинство коммерческих истинно кластерных приложений построено по принципу «последовательная программа, параллельная подсистема» (Serial Program, Parallel Subsystem, SPPS). Под последовательной программой подразумевается обычная программа, рассчитанная на выполнение на одном сервере (в том числе SMP).
Согласно модели SPPS, разработчики пишут обычную программу, а за обеспечение параллелизма и взаимодействие между узлами кластера отвечает специальная подсистема (Parallel System). В соответствии с принципом SPPS построены практически все кластерные СУБД, в том числе Oracle OPS и Informix XPS. Высокая доступность достигается благодаря тому, что выход из строя любого узла никак не влияет на работоспособность кластера, хотя тот и может испытывать некоторую перегрузку.
Промежуточную позицию занимают приложения, рассчитанные на работу в кластере (cluster-aware). В отличие от истинно кластерных программ, в них явный параллелизм не используется; фактически программа является обычной, но она может задействовать некоторые возможности кластера, в первую очередь, с точки зрения миграции ресурсов.
Дело в том, что немало пользовательских программ не позволяет одновременно запускать несколько своих копий на одном компьютере. В частности, на одной машине невозможно запустить несколько копий обычной (не кластерной) СУБД, даже если они обращаются к разным файлам (это связано с тем, что одна копия может обслуживать множество файлов). Каковы последствия этого факта для кластера? Представим случай, когда СУБД обслуживает несколько баз данных, причем они получают большое количество запросов со стороны клиентов. В такой ситуации СУБД имеет смысл распределить по разным узлам кластера с тем, чтобы каждый узел обслуживал свой набор БД. Такой подход замечательно работает в нормально функционирующем кластере, но что если один узел выйдет из строя? Миграция файловых систем (а, следовательно, и БД) пройдет безболезненно, но отвечающую за эту базу данных копию СУБД запустить не удастся, поскольку она будет второй копией СУБД на узле. Автоматически же назначать БД имеющейся копии СУБД при миграции во многих случаях не представляется возможным.
Рассчитанные на работу в кластере приложения устраняют данную проблему. В нашем случае на работающем узле не будет запускаться вторая копия СУБД, просто имеющаяся СУБД на лету подхватит мигрированную БД.
Это только один из примеров программы, где учитывается кластерная конфигурация. Другим примером могут служить приложения с развитыми средствами обнаружения сбоев в ПО. Об этом будет сказано ниже при рассмотрении отказоустойчивости кластера.
Интересным представляется вопрос о том, как инсталлировать приложения в кластере: на каждом узле кластера или только на одном. Принципиальное значение для ответа на него имеет то, насколько конкретное приложение зависит от параметров и настроек операционной системы, другого ПО и даже аппаратной части узла. Например, приложения, вносящие записи в реестр Windows, должны в обязательном порядке устанавливаться на всех узлах кластера Microsoft Cluster Service, но инициализация (запуск) программы должна осуществляться только на необходимых.
Процедура обновления ПО на узлах кластера является весьма своеобразной. Допустим, на узле A выполняется сервис Web, а другие узлы выступают в качестве резерва на случай отказа узла A. Для проведения модернизации администратор останавливает сервис Web на узле A вручную, при этом сервис автоматически запускается (мигрирует) на другой узел. Тем временем администратор осуществляет обновление сервиса Web на узле А. После остановки этого сервиса на другом узле сервис вновь запускается на узле A. Далее сервис Web можно обновлять последовательно на других узлах (поскольку он уже выполняется на узле A). Таким образом, сохраняется непрерывность работы сетевых сервисов.
НАЗНАЧЕНИЕ КЛАСТЕРА
Как уже было сказано выше, основными характеристиками кластера являются высокий уровень доступности, масштабируемость и представление кластера как единого целого с точки зрения внешней среды.
Уровень доступности характеризует готовность системы к функционированию в течение длительного времени без остановки и измеряется в процентном отношении времени нахождения системы в работоспособном состоянии к общему времени. Иногда он характеризуется временем простоя системы за год. В Таблице приведено соответствие между этими величинами.
Высоким уровнем доступности считается обычно уровень 99,9% и выше, хотя такая градация носит достаточно условный характер. С уровнем доступности тесно связано понятие отказоустойчивости. Обычно под отказоустойчивой понимают систему с уровнем готовности 99,999% и выше. Используемый иногда термин «истинная отказоустойчивость» подразумевает практически безостановочную работу системы (99,9999% и выше).
Важно понимать, что заявляемый производителями уровень доступности относится лишь к аппаратной части кластера и операционной системе и обычно не учитывает надежность ПО, особенно сторонних разработчиков. Более того, чтобы обеспечить высокий уровень производительности, каналы подключения к дисковым массивам, сетевой среде и между узлами должны быть отказоустойчивыми и дублированными. Вдобавок дублировать следует также сами дисковые массивы, маршрутизаторы и коммутаторы сети, источники бесперебойного питания и т. д. Особенно важное значение имеет использование в качестве дисковых подсистем массивов RAID, причем для повышения отказоустойчивости и производительности специалисты советуют применять RAID-10. Разумеется, чем больше компьютеров в кластере, тем теоретически выше уровень доступности.
Кластеры из обычных компьютеров относят к категории систем высокого уровня доступности, но никак не к отказоустойчивым системам. Ничего, кроме улыбки, не может вызвать самомнение Microsoft, которая своему кластеру из двух узлов Cluster Service выставила уровень доступности 100%. На уровень доступности влияет не только отказ и простои системы или отдельных сервисов в кластере, но и время миграции программ. Обычно в кластерах, наподобие Microsoft Cluster Service, время миграции колеблется от 1 до 3 мин. Кроме того, обновление ПО, особенно системного, также может обернуться простоями.
Иная проблема возникает, когда сбой происходит в отдельном приложении на узле, но сам узел остается в работоспособном состоянии. В зависимости от настроек кластера приложение либо мигрирует на другой узел, либо тот же узел пытается его перезапустить.
Но как определить, что приложение зависло? К сожалению, сделать это бывает порой не так-то просто. Система может обнаружить некорректные операции приложения на уровне ядра, но не на прикладном уровне. Именно для этих целей некоторые рассчитанные на работу в кластере программы снабжены специальными детекторами сбоев. Но если программа написана некорректно, то даже миграция на другой узел ей вряд ли поможет: она будет поочередно зависать на каждом узле.
Обращаясь к теме масштабирования кластеров, следует отметить, что грамотное размещение на узлах кластера даже обычных (не кластерных) приложений позволяет не только существенно повысить запас прочности, но и увеличить общую производительность по сравнению с одним сервером. Правда, здесь есть своя специфика. Увеличение производительности по сравнению с одним сервером в кластере происходит не пропорционально. Точнее говоря, в случае истинно кластерных приложений оно практически линейно, но для обычных приложений такая тенденция соблюдается далеко не всегда. Максимальной отдачи от кластера для обычных приложений можно достичь только в том случае, если эти приложения распределены по узлам так, что они получают равномерную нагрузку.
Количество узлов в кластере зависит от конкретной реализации, оно колеблется от двух до нескольких десятков, и, как уже было сказано, каждый узел может быть многопроцессорным. Добавление нового узла в кластер обычно проходит безболезненно и не требует перегрузки других узлов. Таким образом, при нехватке вычислительных ресурсов кластер можно на ходу увеличить «в размерах».
Весьма важной особенностью кластера является так называемый единый образ системы (Single System Image, SSI), благодаря которому пользователи могут видеть серверы в кластере как единое целое. Для пользователя кластер — это большой сервер, на котором работает множество приложений, хотя в действительности они функционируют на различных узлах.
Единый образ системы исключительно важен и для администратора, так как позволяет управлять кластером как одной системой. Разумеется, с помощью соответствующих утилит администратор может управлять и отдельными узлами. В разных кластерных технологиях образ SSI реализован по-разному, более того, он опирается на разные программные слои: в наиболее продвинутых системах единый образ формируется на уровне ядра (kernel level), в то время как в дешевых продуктах он сформирован на уровне приложений (application level).
Если единый образ системы формируется на уровне ядра, то обычные команды и утилиты ОС, даже выполняемые на консоли какого-то узла, оперируют ресурсами всего кластера. Если же образ SSI сформирован на уровне приложений, то управлять кластером как единой системой можно только с помощью специальных утилит. Действие же обычных утилит, выполняемых на консоли, будет распространяться только на конкретный узел.
Очевидно, что единый образ системы на уровне ядра предполагает, что поддержка кластеров должна быть глубоко интегрирована в ОС, а это требует определенных усилий от разработчиков ОС.
Особый интерес представляет доступ клиентов к кластеру в момент отказа узла.
Кластеру назначается один или несколько общих виртуальных IP-адресов (практически все кластеры поддерживают исключительно IP и не рассчитаны на IPX, AppleTalk, NetBEUI и т. д.). Эти виртуальные IP-адреса используются для доступа к кластеру как единому целому. Кроме того, каждому узлу назначается свой индивидуальный IP- адрес.
Помимо общих виртуальных IP-адресов каждому сетевому ресурсу кластера (это может быть система для файлового сервиса или приложение с соответствующим ему дисковым пространством) назначается свой виртуальный IP-адрес. В нормально работающем кластере такие виртуальные IP-адреса принадлежат узлам, на которых выполняется приложение или сетевая служба, т. е. при обращении к виртуальному IP-адресу откликается определенный узел. При отказе того или иного узла кластерные ресурсы вместе с соответствующими виртуальными IP-адресами переходят к другим узлам.
Что же происходит при отказе узла или отдельной сетевой службы, с точки зрения клиента? Все зависит от того, какими протоколами и приложениями пользуется клиент в данный момент. Если они относятся к категории сервисов, не отслеживающих состояние соединения, то клиент попросту не заметит ничего, вернее, он может столкнуться с некоторой задержкой в выполнении запросов, вследствие того, что на миграцию служб требуется определенное время.
Если же сервисы отслеживают состояние соединения, то их работа зависит от конкретной реализации. В общем случае от клиента может потребоваться заново установить соединение. Именно это обстоятельство позволяет утверждать, что кластеры не могут быть отказоустойчивыми системами. Однако в ряде случаев повторного открытия соединений может и не потребоваться, как это происходит при доступе клиентов к файловым системам на кластерах Microsoft и Novell, поскольку клиентское ПО само автоматически переустановит соединение.
РЕШЕНИЯ ОТ NOVELL
Компания Novell предлагает несколько решений по обеспечению высокого уровня доступности. В свое время популярностью пользовалась система SFT III (System Fault Tolerance, level 3) на базе NetWare 3 и 4. Согласно модели SFT III, два сервера одинаковой конфигурации без общей дисковой подсистемы имеют специальное высокоскоростное соединение друг с другом. Кроме того, на каждом сервере устанавливаются обычные сетевые адаптеры для выхода во внешнюю сетевую среду, т. е. для обслуживания клиентов сети. В конфигурации SFT III один сервер является ведущим (активным), а другой — ведомым (пассивным). Все запросы клиентов обрабатывает только ведущий сервер, а ведомый находится в оперативном резерве, т. е. его диски имеют полную динамическую зеркальную копию содержимого дисков ведущего сервера в каждый момент времени. Вдобавок, на ведомом сервере выполняются те же пользовательские процессы, что и на ведущем, а межузловое соединение позволяет синхронизировать состояние серверов. При отказе ведущего сервера обслуживание запросов клиентов автоматически переносится на ведомый, при этом клиенты не ощущают каких-либо сбоев.
Следует иметь в виду, что SFT III не является кластером по определению, и это вовсе не из-за того, что серверы работают в режиме горячего резервирования. Другие конфигурации горячего и даже холодного резервирования полностью соответствуют классическому определению кластера. Конфигурация SFT III не соответствует определению кластера потому, что она требует применения идентичных компьютеров в качестве узлов. Кроме того, в SFT III неэкономно расходуются вычислительные ресурсы: ведомый сервер никакой полезной работы, кроме дублирования ведущего, не выполняет. Тем не менее надо отметить, что SFT III имеет гораздо более высокий уровень доступности, чем обычные кластеры из двух узлов. Фактически, по уровню доступности SFT III приближается к отказоустойчивым решениям, поскольку ей требуется минимальное время для переключения между серверами: никакой миграции и перезапуска процессов не происходит.
Продукты StandbyServer for NetWare и StandbyServer Many-to-One for NetWare, разработанные Novell в сотрудничестве с компанией Vinca, работают в соответствии с принципом холодного резервирования, т. е. на диски одного из серверов зеркально копируются данные с других серверов. При сбое основного сервера ведомый сервер необходимо перезапустить, чтобы он заменил ведущий. Процедуру перезапуска ведомого сервера можно автоматизировать с помощью различных внешних средств, однако она отнимает достаточно много времени. Тем не менее такой подход привлекателен тем, что он стоит гораздо дешевле других. StandbyServer с некоторой натяжкой можно отнести к кластерным решениям, поскольку для его реализации идентичных серверов не требуется.
Хотя SFT III и StandbyServer и повышают отказоустойчивость серверов NetWare, они не решают проблему масштабирования. Для тех, кому нужно полноценное кластерное решение, компания Novell выпустила NetWare Cluster Services (кодовое название Orion) на базе NetWare 5.
NetWare Cluster Services (NCS) принадлежит к категории кластеров без разделения ресурсов с общей дисковой подсистемой и может включать от 2 до 32 узлов; в качестве таковых могут выступать как одно, так и многопроцессорные серверы Intel. Узлы кластера имеют независимые от внешней сети соединения, но это условие не является обязательным: межузловое взаимодействие может осуществляться и по внешней (общедоступной) сети. Очевидно, что последний вариант не гарантирует высокую доступность, однако он может активизироваться при отказе внутрикластерной связи. NetWare Cluster Services устанавливаются поверх NetWare 5.
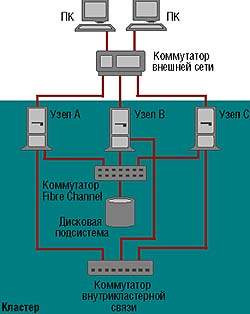 |
| Рисунок 7. Типичная схема использования кластера младшего класса. |
Общая дисковая подсистема (их может быть несколько в составе кластера) подключается ко всем узлам кластера. Само собой разумеется, что дисковая подсистема должна базироваться на аппаратном массиве RAID. В случае двух узлов можно применять разделяемый SCSI, а при большем количестве узлов — сети устройств хранения (Storage Area Network, SAN) на основе Fibre Channel. Каждый узел кластера должен иметь локальный диск, на котором размещается том SYS для загрузки ОС. На Рисунке 7 представлена типичная схема использования NCS. При необходимости обеспечить высокий уровень доступности потребуется установить несколько коммутаторов Fibre Channel и несколько дисковых массивов. Для организации внутрикластерной сети чаще всего применяют Fast Ethernet, хотя не возбраняется использовать и другие сетевые технологии.
В кластере NCS на каждом узле должно иметься как минимум 64 Мбайт памяти (рекомендуется не менее 128 Мбайт). NCS рассчитан на работу в сетях IP. Конечно, отдельные узлы могут иметь IPX- или AppleTalk-адреса, но такие адреса не могут мигрировать на другие узлы, т. е. высокая доступность соединений по этим протоколам не обеспечивается.
Для корректной работы кластера на общем дисковом массиве создается небольшой специальный кластерный раздел (cluster partition) размером не менее 10 Мбайт. В этом разделе никакие тома не создаются, он предназначен исключительно для контроля за функционированием кластера. Представим себе ситуацию, когда в кластере из двух узлов какая бы то ни была связь по сети между узлами отсутствует, однако узлы нормально работают и имеют доступ к общей дисковой подсистеме. Без принятия специальных мер каждый узел будет считать, что второй узел не работает, и захватит в свое владение все дисковые ресурсы. Как следствие, это приведет к конфликтам при доступе к файлам. Специальный кластерный раздел призван, помимо прочего, устранять подобные конфликты, поскольку на нем регистрируются работающие узлы и службы кластера.
Кроме специального кластерного раздела на общей дисковой подсистеме создаются кластерные тома, каждый из которых закрепляется за определенным узлом-владельцем ресурса. Дополнительно каждому кластерному тому назначается свой виртуальный IP-адрес. Единственное ограничение на кластерные тома состоит в том, что они должны иметь тип NSS (Novell Storage Services).
Все узлы кластера должны находиться в одном дереве NDS и в одной подсети IP.
Управлять кластером можно из ConsoleOne или NetWare Administrator. Единый образ системы SSI в NCS реализуется на пользовательском уровне, поэтому выполняемые на консоли команды относятся к конкретному узлу (за исключением ConsoleOne).
Через ConsoleOne осуществляются все настройки служб и ресурсов кластера, в частности задаются настройки процедур миграции (failover) и ремиграции (failback), программы загрузки и выгрузки ресурсов. В комплект поставки изначально входят шаблоны для настройки файлового сервиса, службы печати NDPS, СУБД Oracle 8i, программы электронного документооборота GroupWise, Web-сервера Netscape Enterprise Server, системы управления настольными компьютерами Z.E.N.Works for Desktops и межсетевого экрана BorderManager.
Среди недостатков NetWare Cluster Services можно выделить то, что он ориентирован исключительно на протокол IP, в то время как большинство существующих сетей NetWare до сих пор использует IPX/SPX. Таким образом, переход на NCS потребует модернизации и настройки всех клиентских мест, работающих по IPX/SPX.
Огорчение вызывает и то, что для NetWare Cluster Services не существует истинно кластерных приложений, и, судя по настроению ведущих разработчиков кластерного ПО, никто не стремится восполнить данный пробел.
Тем не менее NCS хорош тем, что он позволяет заменить множество разрозненных серверов NetWare одним кластером, притом с обеспечением высокого уровня доступности. Как и другие кластерные технологии, NCS может работать в режиме холодного резервирования (т. е. в конфигурации активный/пассивный), благодаря чему в ряде случаев можно отказаться от покупки продуктов категории Standby.
MICROSOFT CLUSTER SERVICE
Microsoft впервые выпустила свой кластерный продукт еще для Windows NT Server. Тогда он назывался Microsoft Cluster Server (MSCS, кодовое название Microsoft Wolfpack, Phase 1). Мы не будем останавливаться на нем, поскольку новая версия, уже под названием Microsoft Cluster Service, имеет значительно лучшие характеристики (в терминологии Microsoft это Phase 2).
Microsoft Cluster Service входит в состав Windows 2000 Advanced Server и Windows 2000 Datacenter Server (к сожалению, Windows 2000 Datacenter Service еще не выпущен). Cluster Service в составе Windows 2000 Advanced Server поддерживает кластер из двух узлов, а для Windows 2000 Datacenter Server — до четырех. Cluster Service устанавливается поверх Windows 2000.
Microsoft Cluster Service является кластером без разделения ресурсов с общей дисковой подсистемой и по своим характеристикам и архитектуре очень похож на NetWare Cluster Services, хотя и поддерживает значительно меньше узлов. В качестве узлов могут выступать серверы самой различной конфигурации, причем Windows 2000 Advanced Server поддерживает до 8 Гбайт оперативной памяти на узле, а Windows 2000 Datacenter — до 64 Гбайт.
Внутрикластерные соединения организуются с помощью обычных сетевых адаптеров, хотя для этого можно использовать и соединения ServerNet компании Tandem (теперь Compaq). В принципе, для взаимодействия узлов может использоваться и внешняя (по отношению к кластеру) сеть, но техническую поддержку такой конфигурации Microsoft не обеспечивает.
Общая дисковая подсистема подключается ко всем узлам кластера либо через разделяемый интерфейс SCSI (для двух узлов), либо с помощью Fibre Channel. В качестве дисковой подсистемы настоятельно рекомендуется использовать отказоустойчивые спецификации RAID.
Помимо общей дисковой подсистемы каждый узел кластера должен иметь локальный диск, откуда осуществляется загрузка операционной системы и инициализация кластерной конфигурации.
Cluster Service рассчитан на работу в сетях IP, хотя в нем и задаются настройки NetBIOS.
Для того чтобы логические диски (по существу, файловые системы), находящиеся на общей дисковой подсистеме, были кластерными, им присваивают специальные метки, виртуальные IP-адреса и уникальные имена. Кроме того, на общей дисковой подсистеме необходимо создать так называемый кворумный диск (quorum disk) размером не менее 50 Мбайт (рекомендуется 500 Мбайт), аналог кластерного раздела в NetWare Cluster Services. Кворумный диск позволяет разрешить конфликты, когда узлы потеряли соединение друг с другом и каждый из них пытается стать владельцем ресурсов.
Узлы кластера должны входить в один домен Windows, причем их рекомендуется делать контроллерами домена. Единый образ системы SSI в Microsoft Cluster Service реализуется на пользовательском уровне, поэтому обычные, выполняемые на консоли, утилиты относятся к конкретному узлу. Как единым целым кластером можно управлять из программы Cluster Administrator. Она позволяет задавать настройки служб и ресурсов кластера, в том числе режимы миграции (failover) и ремиграции (failback).
В составе Microsoft Cluster Service имеются развитые средства обновления ПО на узлах (rolling upgrade). Это особенно важно, поскольку подавляющее большинство приложений осуществляет записи в реестр Windows.
Для Windows 2000 имеется около двух десятков рассчитанных на работу в кластере продуктов, большинство из них являются средствами резервного копирования. Microsoft SQL Server 7.0 также относится к данной категории продуктов, так что кластер Microsoft можно использовать для решения достаточно серьезных задач.
Некоторые компании объявили о намерении создать для Windows 2000 истинно кластерные приложения, но нам пока неизвестно о появлении их на рынке.
Главным недостатком Cluster Service является его невысокая масштабируемость, не идущая ни в какое сравнение с решениями от Novell и SCO. Определенные нарекания вызывает и отсутствие динамического распределения нагрузки. Впрочем, у большинства кластеров младшего класса такая возможность также отсутствует.
MICROSOFT NETWORK LOAD BALANCING
Рассмотренное выше кластерное решение Microsoft Cluster Service не очень подходит для реализации мощных серверов Web; сама Microsoft позиционирует его как кластер для СУБД и файлового сервиса. Впрочем, это справедливо в отношении любого другого кластера без разделения ресурсов с общей дисковой подсистемой.
Как показывает статистика, на реальных серверах Web наблюдается большой перекос по числу обращений к разным страницам сервера. Наибольшая нагрузка обычно приходится на главную (домашнюю) страницу компании. Поэтому всевозможные ухищрения по размещению страниц и сервисов Web на разных узлах кластера далеко не всегда решают проблему.
Кардинальным способом увеличения производительности сервера Web остается распараллеливание нагрузки между разными серверами с одинаковым набором страниц. Это обычно достигается за счет применения программно-аппаратных диспетчеров либо посредством распределения нагрузки с помощью DNS. Но такие решения сами обладают неприятными, а порой и неприемлемыми ограничениями.
Свой вклад в увеличение производительности сервисов Internet решила внести и Microsoft. С этой целью она выпустила продукт Network Load Balancing (NLB), входящий в состав Windows 2000 Advanced Server и Windows 2000 Datacenter Server (для Windows NT Server 4.0 имелся аналогичный продукт Windows NT Load Balancing Service (WLBS)).
Кластер NLB предназначен для обслуживания таких служб, как Web, Terminal Services, виртуальных частных сетей и потокового мультимедиа. Он может включать до 32 узлов, каждый из которых может представлять собой многопроцессорный сервер.
Network Load Balancing является кластером без разделения ресурсов, без общей дисковой подсистемы; на каждом узле выполняется своя копия прикладной программы, причем эти копии независимы и не знают о существовании друг друга.
Поэтому встает вопрос, как же он оперирует общими данными? Если кластер только считывает информацию с дисков, то он может использовать полностью разделяемую дисковую подсистему. В таком случае NLB превращается в кластер с разделенными дисками, но при этом DLM не требуется, поскольку информация не записывается на дисковую подсистему со стороны клиентов. Однако подобная схема не подходит для большинства серверов Internet, особенно предназначенных для электронной коммерции.
Если же данные не только считываются, но и записываются, то такой подход не годится. Для кластера NLB с небольшим количеством узлов можно установить средства тиражирования данных для зеркального копирования (дублирования) содержимого локальных дисков между узлами. Для этих целей Microsoft рекомендует использовать Microsoft Content Replication Server.
Но кардинальным решением проблемы является привлечение внешних средств хранения и обработки данных. В качестве такого средства можно использовать кластер Microsoft Cluster Service, т. е. полное решение по обеспечению высокопроизводительного сервиса Internet будет состоять из двух кластеров: Network Load Balancing и Microsoft Cluster Service (см. Рисунок 8). Кластер NLB обрабатывает запросы со стороны клиентов к Web и другим службам Internet, а Cluster Service обеспечивает корректный доступ к информации на уровне файловых операций. Кроме того, на кластере Microsoft Cluster Service можно установить рассчитанную на работу в кластере СУБД Microsoft SQL Server 7.0. СУБД будет осуществлять корректное и согласованное обращение к базам данных со стороны узлов кластера NLB.
Для распараллеливания запросов на каждом узле NLB устанавливается программное обеспечение Network Load Balancing, оно размещает драйвер NLB между стеком TCP/IP и драйверами сетевых адаптеров. Никаких внешних по отношению к кластеру программных или программно-аппаратных диспетчеров для распределения запросов между узлами в Network Load Balancing не требуется.
Функционирование NLB базируется на ряде любопытных, а порой и просто уникальных алгоритмов, о которых можно говорить очень долго. Однако мы этого делать не будем, поскольку решения, наподобие NLB, еще долгое время будут оставаться невостребованными абсолютным большинством российских компаний. Легче пересчитать, притом для этого хватит пальцев одной руки, кому в России может понадобиться кластер NLB. Во всяком случае нам не известно ни об одном случае инсталляции данного продукта (включая Windows NT Load Balancing) в нашей стране.
Network Load Balancing предназначен, прежде всего, для повышения производительности серверов Internet, но в России главной причиной низкой производительности Internet является не недостаток вычислительных ресурсов серверов, а малая пропускная способность каналов связи. Что же касается повышения отказоустойчивости, то оптимальным вариантом представляется использование серверов Internet на основе обычных кластеров без разделения ресурсов с общей дисковой подсистемой, таких, как Microsoft Cluster Service, Novell Cluster Services, SCO UnixWare Reliant HA и SCO UnixWare NonStop Clusters. Да и по цене такие решения будут значительно дешевле.
КЛАСТЕРЫ ОТ SANTA CRUZ OPERATION
Компания Santa Cruz Operation предлагает два кластерных решения для разных сегментов рынка.
С точки зрения архитектуры продукт UnixWare 7 Reliant HA является полным аналогом Microsoft Cluster Service и Novell Cluster Services (см. Рисунок 7), поэтому мы не будем его подробно описывать. UnixWare 7 Reliant HA предназначен, в первую очередь, для повышения отказоустойчивости сетевых служб. Этот кластер без разделенных ресурсов с общей дисковой подсистемой может включать до четырех узлов.
Единый образ системы SSI в данном кластере формируется на уровне приложений, а управлять кластером как единым целым можно с помощью графической утилиты Configuration Manager.
Гораздо большие возможности предоставляет продукт UnixWare 7 NonStop Clusters, который SCO разработала в тесном сотрудничестве с Compaq (компания Compaq поставляет данный продукт под маркой Compaq ProLiant Clusters for SCO UnixWare 7.1) и который базируется на аппаратном обеспечении от Compaq. Надо сказать, что после покупки компаний Digital и Tandem, законодателей мод в области кластерных технологий, Compaq стала владельцем самого богатого набора кластерных решений. Расположения Compaq добиваются многие разработчики кластерных систем, в том числе Microsoft и Novell.
Среди основных особенностей продукта UnixWare 7 NonStop Clusters можно выделить то, что в нем:
- единый образ системы SSI сформирован на уровне ядра;
- реализована единая и доступная всему кластеру файловая система, включающая единый список устройств, каналов (pipe), семафоров, файлов подкачки и т. д.;
- применяется динамическое распределение нагрузки;
- помимо отказов узлов и отдельных приложений отслеживаются отказы устройств; при наступлении такого события использующие данное устройство процессы могут мигрировать (failover) на другие узлы.
Ни одна кластерная технология младшего класса не может предложить ничего подобного.
Для внутрикластерного соединения узлов в UnixWare 7 NonStop Clusters применяется проверенная годами технология ServerNet компании Tandem (купленной Compaq). Хотя производительность ServerNet не впечатляет, она дает меньшие издержки при передаче пакетов.
В стандартной конфигурации кластер UnixWare 7 NonStop Clusters поддерживает от двух до шести узлов, но это ограничение накладывается коммутаторами ServerNet; на тестах SCO продемонстрировала, что кластер нормально работает и со 100 узлами.
UnixWare 7 NonStop Clusters поддерживает два варианта размещения дисковых подсистем: с зеркалированием локальных дисков (Cross-Node Mirrored, CNM) и с внешней дисковой подсистемой (External Storage Fibre Channel, ESFC).
Обычно зеркалирование дисков применяют для кластера из двух узлов (см. Рисунок 4), хотя это и не обязательно, т. е. зеркалировать можно и большее количество узлов. Сама операция копирования осуществляется по сети ServerNet с прямым соединением между узлами (в случае двух узлов), без использования коммутаторов ServerNet.
В случае ESFC кластер без разделения ресурсов имеет общие дисковые подсистемы, причем сеть строится так же, как и в Tandem Himalaya (см. Рисунок 9). Согласно этому принципу каждый дисковый массив подключается к двум, и только к двум узлам кластера через коммутаторы Fibre Channel. Узлы соединяются между собой сетью ServerNet с использованием коммутаторов. Для повышения отказоустойчивости каждый компонент дублируется.
Несмотря на такую замысловатую архитектуру, все ресурсы кластера прозрачно видны с любого узла; даже если ресурсом владеет другой узел, остальным он виден через его владельца. Таким образом, все обычные команды, утилиты и ПО, выполняемые на узле, могут обращаться к любым файлам и устройствам кластера.
В UnixWare 7 NonStop Clusters поддерживается динамическое распределение приложений по узлам, при котором процесс, запускаемый на кластере, выполняется на наименее загруженном узле кластера. Разумеется, администратор может также вручную (статически) указать узел, на котором будет выполняться конкретное приложение.
Реализованный в UnixWare 7 NonStop Clusters кластерный подход не может не впечатлять, однако и у него есть свои минусы. Главное ограничение состоит в жесткой ориентации на аппаратное обеспечение Compaq. В качестве узлов кластера могут выступать исключительно серверы ProLiant, в качестве дисковых подсистем требуется использовать дисковые массивы от Compaq, для межузловой связи можно применять только сети ServerNet. Последнее требование является наиболее неприятным, так как ServerNet значительно уступает по производительности современным сетевым технологиям, представляет собой закрытое решение, да и стоит недешево. Справедливости ради, надо отметить, что в настоящее время SCO рассматривает возможность отказа от ServerNet в пользу стандартных сетевых технологий.
ЗАКЛЮЧЕНИЕ
Кластеры из разряда экзотики постепенно переходят в категорию рядовых серверных систем. Особенно отрадным фактом является появление серьезных кластерных решений нижнего ценового уровня. Стоимость кластера всего на 15—30% больше суммарной стоимости отдельных компонентов, при этом он обеспечивает высокий уровень доступности, немыслимый в случае применения отдельных серверов. Кластеры прекрасно подходят не только для корпоративных СУБД или больших серверов Web, но и для тривиального сервиса файлов и печати.
Константин Пьянзин — обозреватель LAN. С ним можно связаться по адресу: koka@lanmag.ru.
| Уровень доступности | Время простоя в год |
| 99% | около 4 дней |
| 99,9% | около 9 ч. |
| 99,99% | около 1 ч. |
| 99,999% | около 5 мин. |
| 99,9999% | 30 с |