
Распределенное тиражирование может оказаться наилучшим способом резервного копирования находящихся в разных местах файлов и повышения эффективности работы сети.
Однако времена изменились
Теперь же данные имеют множество форм и проникают за географические и организационные границы. Пользователям требуется доступ к изображениям, аудио- и видеофайлам, страницам Web вдобавок к простым алфавитно-цифровым данным из реляционных систем управления базами данных (Relational Database Management System, RDBMS).
С превращением распределенных сетей, Intranet и неисчислимого множества сервисов рабочих групп в стандартные компоненты предприятия администраторы сетей сталкиваются с трудноразрешимыми вопросами. Как организовать доступ к данным? Как обеспечить адекватное функционирование сети? Какая пропускная способность необходима для поддержки больших объемов данных? Как осуществить интеграцию данных?
Здесь-то и приходят на помощь тиражирование данных и распределенная кластеризация — две стратегии обеспечения требуемых характеристик доступа к данным в масштабах корпоративной сети. (Краткий перечень основных преимуществ распределенного тиражирования данных приводится во врезке «Почему именно распределенное тиражирование данных?».)
СТРАТЕГИИ ТИРАЖИРОВАНИЯ
Тиражирование данных не является чем-то новым. Идея создания дублирующего образа множества данных и использования его в качестве резервной копии известна уже несколько десятков лет. Тиражирование данных служит для повышения доступности хранилищ данных вот уже многие годы, вне зависимости от способа — автономно в резервной конфигурации или оперативно в массиве RAID. Вместе с тем распределенное тиражирование данных ставит ряд новых вопросов.
В общих чертах распределенное тиражирование данных подразумевает копирование всех или части источников данных в другое место. Источником данных могут быть цифровые данные любого типа, однако наиболее часто тиражируемым объектом остаются базы данных. Тиражирование может осуществляться с помощью традиционных технологий копирования на жесткий диск или магнитную ленту, но все большую популярность в качестве носителя информации начинает приобретать сеть.
Как и любая технология, тиражирование данных имеет свои достоинства и недостатки. Чтобы оценить, какое влияние она будет оказывать на вычислительную среду, администраторы сетей должны хорошо разбираться в различных стратегиях и их разновидностях.
Основных стратегий тиражирования данных три: разбиение (partitioning), дублирование (duplication) и объединение (federation) (см. Таблицу 1). Выбор подходящей стратегии зависит от потребностей вашей организации и требований приложений. Стратегию тиражирования данных иногда называют политикой «конвейеризации данных», потому что она определяет различные этапы размещения данных в процессе их консолидации или распределения в рамках организации.
Стратегия разбиения предполагает разделение базы данных на серию дискретных баз данных, находящихся в различных местах. Обычно раздел создается в соответствии с первичным ключом, таким, как номер заказчика, номер детали или любой другой уникальный идентификатор. Запросы на данные осуществляются по первичному ключу. Центральный сервер перенаправляет их на сервер, где хранятся запрошенные данные.
Главное преимущество такого подхода состоит в том, что он позволяет равномерно распределить нагрузку и сохранить работоспособность оставшейся части системы при отказе какого-либо из ее компонентов. Однако в этом и его слабость. Физическое разбиение данных производится в соответствии с одним определенным ключом. А что если в соответствии с запросом данные потребуется собрать из нескольких источников? Переходя от раздела к разделу, запрос будет увеличивать не только нагрузку на сеть, но и, с точки зрения пользователя, время отклика. Заранее предугадать, какие данные будут запрашивать пользователи, очень трудно, и поэтому, прежде чем выбрать первичный ключ, вам необходимо подумать над тем, к каким данным они будут обращаться чаще всего.
Другая проблема подхода с разбиением данных состоит в возможности потери одного раздела. В конце концов, какой смысл в отчете о дебиторской задолженности, если вы в состоянии получить только данные о заказчиках в алфавитном порядке от А до М, потому что разделы от Н до Я недоступны?
ОДИН В ДВУХ ЛИЦАХ
Стратегия дублирования предусматривает тиражирование данных с одной машины на другую. Помимо выравнивания нагрузки и избыточности дублирование обеспечивает динамическое резервирование и восстановление в случае сбоев как сети, так и сервера.
Дублирование имеет несколько разновидностей: в реальном времени, почти в реальном времени и отложенное (см. Таблицу 2). Дублирование в реальном времени часто используется в системах поддержки транзакций, например при вводе заказов, когда все копии данных должны синхронизироваться немедленно. Оно считается «атомарной» операцией, т. е. информация должна быть модифицирована либо на обеих машинах, либо ни на одной из них.
Распределенное обновление информации в реальном времени реализуется главным образом с помощью программного алгоритма двухступенчатого выполнения. Цель применения этого алгоритма состоит в устранении связанной с выполнением операции неопределенности за счет введения этапа подтверждения в дополнение к процессу обновления. Однако реализация такого алгоритма ведет к удвоению времени отклика для любой конкретной транзакции и к увеличению сетевого трафика.
Как можно предположить, гарантирование атомарности распределенной транзакции имеет важнейшее значение. Однако из-за того, что двухступенчатое выполнение не всегда гарантирует результат, дублирование в реальном времени используется редко. Из-за увеличения накладных расходов и вероятности незавершения обновления многие организации остерегаются применять этот подход.
Дублирование почти в реальном времени пользуется большей популярностью. В этом случае дубликат создается на основании главной копии с некоторой небольшой задержкой (от одной минуты до получаса). Для большинства приложений обновления почти в реальном времени вполне достаточно.
Одна из проблем с этой стратегией состоит в том, что ее применение возможно, как правило, только в случае, если все охватываемые ею базы данных поставлены одним и тем же разработчиком. С учетом децентрализованной природы большинства организаций это не всегда возможно или желательно. Разработчики придерживаются разных подходов к тиражированию почти в реальном времени. Некоторые рассылают копии на все машины сразу, другие пересылают запросы через промежуточные машины. Первый подход позволяет ускорить процесс обновления, тогда как второй — сократить потребление сетевых ресурсов. К сожалению, разработчики не предоставляют выбора между двумя этими подходами.
Если у вас реализована система тиражирования почти в реальном времени, то вы должны помнить, что данные могут не отражать реального состояния в данный конкретный момент. Поэтому такой подход неприемлем для систем, где данные используются для мгновенного принятия решений (например, при интерактивном бронировании билетов).
Третий вариант, отложенное дублирование, полезен для тех организаций, где имеются базы данных от разных разработчиков. В этом случае целевой базе данных посылается через сеть сообщение о необходимости выполнить обновление — своего рода аналог электронной почты между прикладными программами.
Примером схемы с отправкой сообщений в очередь для реализации отложенного дублирования может служить MQSeries компании IBM. Такой подход гарантирует доставку сообщения, но не время доставки. Подобные сервисы часто используются на фондовых биржах для передачи брокерам информации о торгах.
Объединение представляет собой третий подход к тиражированию данных. В этом случае несколько серверов действует как один. Данные могут разбиваться или дублироваться в зависимости от необходимости.
Главное преимущество объединения в том, что оно позволяет поддерживать самые разнообразные аппаратные и программные системы — по крайней мере, теоретически. Данная конфигурация наиболее трудна в реализации, потому что разработчики баз данных и серверов Web не стремятся совместными усилиями обеспечить взаимодействие своих систем. Так, объединение вполне можно было бы реализовать на базе распределенной архитектуры реляционной базы данных (Distributed Relational Database Architecture, DRDA) компании IBM, но она пользуется слабой поддержкой со стороны других разработчиков СУБД. Сегодня распределенные гетерогенные объединения СУБД остаются скорее мечтой, чем реальностью.
КЛАСТЕРЫ ПРЕОДОЛЕВАЮТ РАССТОЯНИЯ
Последним словом в тиражировании данных (для всех видов данных) являются распределенные кластеры.
Кластеризация используется давно. Традиционно кластер представляет собой группу находящихся в одном месте взаимосвязанных компьютеров, действующих как одна система. Эти машины могут быть объединены в архитектуры симметричной многопроцессорной обработки (Symmetric Multiprocessing, SMP) или массовых параллельных процессоров (Massively Parallel Processors, MPP).
Несмотря на то что применение таких технологий, как Fibre Channel, позволяет увеличить расстояние между системами, кластер по-прежнему рассматривается преимущественно как локальный объект. Однако все течет, все изменяется. В наши дни группы связанных сетью компьютеров могут функционировать как один хост, даже если физически они находятся в разных местах.
Последствия этого трудно переоценить. Достаточно вспомнить, что Electronic Frontier Foundation и distri- buted.net удалось взломать 56-разрядный ключ шифрования DES менее чем за сутки с помощью созданного ими кластера из более 100K компьютеров Internet. В соответствии с подходом по принципу «грубой силы и неведения» каждому компьютеру был дан для проверки определенный диапазон ключей. В конце концов, один из компьютеров «наткнулся» на правильный ключ.
Конечно, с помощью вашей сети вы можете сделать кое-что более полезное, чем взлом программных ключей шифрования. Кстати, как вы справляетесь с поступающими запросами? Как известно, эта задача разбивается на четыре подзадачи: управление трафиком, процессорная архитектура, хранение и извлечение, администрирование.
Если некоторые части вашей сети объединены в кластер, то управление трафиком (т. е. распределение нагрузки) выходит на первый план.
Управление трафиком позволяет динамически обрабатывать поступающий сетевой трафик — т. е. все возрастающий поток объектов Web, сообщений электронной почты и запросов на передачу файлов к www.вашеместо.com. Согласно теории массового обслуживания, как только загруженность сервера превосходит 50%, время обслуживания (и, следовательно, время отклика) растет экспоненциально. Решить эту проблему можно посредством установки двух или более серверов для обработки поступающих запросов. Но как определить, куда какой запрос следует направлять?
Здесь имеется два подхода: открытый и нестандартный. Открытый подход опирается на Berkeley Internet Name Daemon (BIND), разработанный и развиваемый Internet Software Consortium (ISC, http://www.isc.org). С помощью сервера DNS поступающие сообщения циклически направляются на разные серверы Web. Конечно, этот метод имеет свои недостатки. Если сервер выйдет из строя, то пользователи будут привязаны к нему, пока не истечет тайм-аут.
Другой открытый подход базируется на обратном сервере-посреднике протокола разрешения адреса (Address Resolution Protocol, ARP) (см. Рисунок). В этом случае все поступающие запросы направляются на одну машину, а она уже выбирает, какой сервер использовать. Такая конфигурация имеет несколько преимуществ. Во-первых, не возлагая повышенной нагрузки на сервер DNS, сервер-посредник может выбрать, какая система является оптимальной на момент запроса. Во-вторых, серверы могут предоставлять обратному посреднику ARP информацию о своем состоянии. В-третьих, обратный посредник ARP может быть размещен перед другими серверами и выступать в качестве «обратного брандмауэра», когда вопросы защиты имеют важное значение.
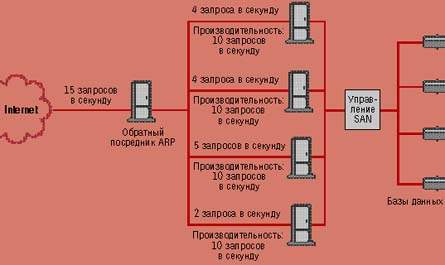 |
| Наоборот. Обратный посредник ARP может использоваться для реализации распределения нагрузки. Какой сервер должен выполнять полученный запрос, можно определить разными способами. Обратите внимание, что SAN используется для обеспечения высокоскоростного доступа ко всем страницам сервера Web. |
Открытые реализации сервера обратного посредника ARP предоставляются Apache Project (http://www.apache.org). Коммерческие реализации предлагаются Netscape, Sun и Squid и другими.
Windows NT Load Balancing Server (MLBS) компании Microsoft использует для управления трафиком нестандартный подход. Он также обеспечивает автоматический перевод операций на другой сервер при отказе. С Windows NT 4.0 Enterprise Edition он поставляется бесплатно.
НАРАЩИВАНИЕ МОЩНОСТИ
Управление поступающим трафиком представляет собой всего лишь один из аспектов распределенной кластерной конфигурации. Что если сервер получает запрос, выполнение которого требует значительных вычислительных ресурсов? Например, запрос к складу данных может быть эффективно выполнен только при использовании нескольких процессоров. То же заключение справедливо и в случае системы выполнения транзакций, когда множество запросов направляется к одному источнику данных.
В этом случае вы вполне можете воспользоваться традиционными кластерами SMP или MPP. Такие компании, как Compaq (благодаря приобретению Tandem и Digital), IBM, Hewlett-Packard и Sun, имеют богатый опыт разработки специализированного аппаратного и программного обеспечения, используемого в этих машинах. При недостатке средств вы можете воспользоваться такой недорогой альтернативой, как Cluster Server компании Microsoft (MSCS).
MSCS является встроенным компонентом Windows NT 4.0 Enterprise Server. Он позволяет связать два процессора в соответствии со стратегией «ничего общего», обычно используемой в более крупных кластерах.
Принцип «ничего общего» означает, что каждый процессор имеет свое собственное пространство на диске, которое он использует единолично, пока не случится сбой. Главное преимущество такого подхода состоит в том, что процессоры не имеют общих каналов ввода/вывода, так как в разделяемых средах такие каналы могут быстро превратиться в узкое место. Помимо повышения доступности подобная конфигурация упрощает масштабируемость, так как она не требует применения дисковых подсистем с экзотической архитектурой.
Конечно, Microsoft — не единственный производитель, предлагающий поддержку конфигураций по типу «ничего общего». Те, кто использует NDS компании Novell, могут воспользоваться ее High Availability Server (NHAS). Systems Fault Tolerance (SFT) давно выпускается Novell, но теперь компания предлагает несколько серверов тиражирования, еще более повышающих доступность.
Хорошим примером может служить Netware StandbyServer Many-to-One, когда один сервер выступает в качестве резервного для нескольких первичных серверов. Это весьма эффективное решение, так как вероятность сбоя одновременно двух или более серверов обычно очень мала. Novell имеет также бета-версию кластерного программного обеспечения для NetWare 5.0.
Администраторам сетей следует помнить, что Microsoft и Novell являются относительными новичками в области кластеризации. Для действительно высококритичных приложений лучше воспользоваться более зрелыми продуктами от Sun, IBM и других. Несмотря на более высокую начальную стоимость, отдача от них будет больше за счет меньших административных расходов и лучшей масштабируемости.
Например, технология SunCluster компании Sun Microsystems позволяет объединить до 256 процессоров на расстоянии до 10 км. В качестве средства соединения она поддерживает множество сетевых сред, в том числе 1000BaseT, FDDI и Fibre Channel. Поддержка многочисленных приложений сторонних разработчиков, таких, как TME от Tivoli, Oracle и SAP, означает, что корпоративные приложения могут находиться на кластере многие годы.
Что касается программного обеспечения, вы должны помнить, что многие приложения не способны использовать преимущества кластерной архитектуры без дополнительного программирования. Например, Oracle и IBM пришлось специально разрабатывать версии своего программного обеспечения баз данных для кластеров MPP.
ДОСТУП К ДАННЫМ
Конечно, хорошо иметь работающие со скоростью молнии процессоры, но это не ликвидирует основное узкое место распределенных кластеров — доступ к данным.
Решить данную проблему можно несколькими способами. Один из подходов состоит в применении программного обеспечения управления трафиком. Эти системы обычно поддерживают и перенаправление, и тиражирование. Не вдаваясь в детали, при поступлении запрос перенаправляется на сервер, где находится соответствующая информация. Например, в случае Central Dispatch от Resonate информационное наполнение может быть распределено между различными серверами. При таком подходе разные серверы могут быть выделены для разных типов данных, таких, как мультимедийная информация, тексты и т. д. Это позволяет оптимизировать работу сервера в соответствии с выполняемыми им операциями.
Кластерные дисковые подсистемы реализуют еще одну полезную стратегию, особенно когда доступность играет важную роль. Наиболее распространенные конфигурации базируются на технологии RAID с Fibre Channel в качестве межсоединения. Эта зрелая, прошедшая испытание временем технология имеет множество достоинств. Однако из-за того, что все компоненты RAID производятся, как правило, одним поставщиком, такие конфигурации не стандартизованы и достаточно дороги.
Сети устройств хранения (Storage Area Network, SAN) становятся привлекательной альтернативой конфигурациям RAID. Преимущество SAN над RAID состоит в их гибкости. Устройства SAN могут отстоять друг от друга на большие расстояния и позволяют интегрировать различные носители информации. Более того, пропускная способность может выделяться в соответствии со скоростью устройства хранения. Это повышает эффективность использования пропускной способности и, как следствие, общую производительность. Главным недостатком SAN является отсутствие стандартов: эти сети базируются отнюдь не на TCP/IP. Для реализации функциональности SAN каждый производитель применяет свой протокол.
На вершине иерархии дисковых кластеров находятся системы управления иерархическим хранением информации (Hierarchical Storage Management, HSM). Обычно они используются в средах с мэйнфреймами, где необходимо хранить терабайты данных. Система HSM — это, образно говоря, взращенная на стероидах SAN. Помимо преимуществ SAN система HSM автоматизирует загрузку дисков, лент, картриджей и компакт-дисков с помощью роботов. Она также содержит сложное программное обеспечение для управления и администрирования.
БОЛЬШИЕ ОБЕЩАНИЯ
Высокоскоростные сетевые технологии предлагают новые возможности для создания и функционирования центров обработки данных. В первые годы существования тиражирования и кластеризации компьютеры должны были располагаться поблизости друг от друга, чтобы они могли использовать при взаимодействии высокоскоростные каналы. Это ограничение уходит в прошлое. Сегодня элементы одной и той же группы тиражирования или кластеризации могут располагаться там, где их нахождение наиболее целесообразно.
Распределенное тиражирование выполняет обещание повышения производительности, доступности и почти неограниченной масштабируемости. Распределенная кластеризация позволяет равномерно распределить сетевой трафик, увеличить время бесперебойной работы и предоставить вычислительные циклы там, где они будут использоваться наиболее эффективно. С помощью этих двух технологий вы можете создать вычислительную среду, отвечающую самым высоким мировым стандартам.
Джерри Голик — консультант по сетям. С ним можно связаться по адресу: jgolick@ibm.net.
Почему именно распределенное тиражирование данных?
Организация может обратиться к тиражированию данных в силу самых разных причин. Одна из них — необходимость повышения производительности системы. Размещение данных как можно ближе к пользователям не только уменьшает время отклика и высвобождает пропускную способность, но и сокращает трафик через глобальные сети. Кроме того, распределение данных между несколькими системами повышает скорость выполнения запросов.
Другое преимущество продуманной среды тиражирования данных состоит в более высокой степени интеграции данных. Размещение тиражируемых серверов в различных географических областях исключает вероятность отказа всей системы из-за сбоя в каком-либо одном ее компоненте и таким образом повышает общую доступность. Еще одно преимущество этого подхода — в автоматическом распределении нагрузки в сети. С достижением пороговой величины трафика к какому-либо из узлов весь последующий трафик направляется на другой узел.
Третье преимущество — масштабируемость. Вне зависимости от выбранной стратегии тиражирования вы всегда имеете возможность добавить новые серверы. Это особенно полезно для быстрорастущих узлов Web, где планирование емкости приходится проводить чуть ли не ежедневно и где необходимо оперативно реагировать на изменения в картине трафика.
Конечно, некоторые из этих преимуществ нивелируются скоростью шины ввода/вывода сервера. Каким бы быстрым ни был сетевой канал, медленная шина ввода/вывода ограничивает производительность и масштабируемость. Процессоры на базе Intel, где используется старая архитектура шин DMA, особенно часто служат причиной возникновения узких мест. В этом контексте вложение средств в усовершенствованные шинные архитектуры представляется вполне оправданной идеей, так как серверы очень часто имеют весьма ограниченные возможности ввода/вывода.
Ресурсы Internet
Resonate разместила две любопытные популярные статьи на своем сервере Web. Статьи «Максимальная производительность в сочетании с детальным контролем: обязательное требование для приложений и сервисов электронной коммерции» и «Возможности распределенного программного управления для управления трафиком к узлу Internet» можно прочитать на http://www.resonate.com/products/white_papers.html.
Ряд статей о технологиях SAN можно найти на http://www.fccommunity.org/SAN/white-papers/default.htm.
Дополнительную информацию о SAN можно получить на Web-сервере Storage Networking Industry Association на http://www.snia.org.
Отчет под названием «Конкурентный анализ надежности, доступности, обслуживаемости и кластерных возможностей и функций» помещен на http://www.dhbrown.com.