
Каково наилучшее решение для восстановления после аварии?
Ураганы. Потопы. Пожары. Землетрясения. Хакеры. Y2K... Год 1999 был щедр на катастрофы. Между тем перерывы в работе компьютерных систем и сетей все чувствительнее сказываются на деятельности коммерческих компаний.
Одна из причин такой возросшей чувствительности состоит в повсеместном распространении распределенных систем и ПК-серверов. В прошлом, когда все компьютерные системы находились в отдельных помещениях, менеджеры могли расположить это оборудование в географически безопасных местах. Они могли настелить фальшполы, установить безопасные для компьютеров системы пожаротушения и подключить резервные источники питания, чтобы критически важные системы при необходимости могли продолжать работать автономно в течение нескольких дней или недель. Такие меры практически невозможны сегодня, когда серверы усеивают офисный пейзаж, как одуванчики лужайку.
Другая причина - растущее число приложений для электронного ведения бизнеса, при котором минута простоя - огромное время, тем более что другой поставщик (конкурент!) находится на расстоянии всего одного щелчка мыши.
Какова бы ни была причина остановки сети, наличие плана восстановления после аварий должно помочь минимизировать потери как в данных, так и в бизнесе. В этой статье мы рассмотрим несколько решений по восстановлению после аварий, в том числе резервное копирование на магнитную ленту, электронную переброску данных и зеркальное копирование. Мы также обсудим преимущества и недостатки обращения к сторонним услугам. (Естественно, далеко не все потери данных связаны с естественными катастрофами. Неисправный жесткий диск также может вызвать отказ. О том, как поступать в этой ситуации, смотрите врезку "Ночь после трудного диска".)
ЕСЛИ СЛУЧИТСЯ НАИХУДШЕЕ
Первый шаг при реальном планировании восстановления после аварий состоит в оценке рисков на основе инвентаризации ресурсов ИТ и анализа последствий для них возможных аварий. В идеале такая оценка должна включать анализ последствий для бизнеса и план возобновления бизнеса, где бы определялось, как авария может повлиять на ведение дел в целом (а не только на инфраструктуру ИТ) и как возобновить работу после нее (см. Рисунок).
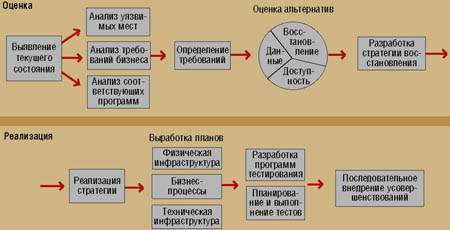 |
| Непрерывный бизнес-цикл. Для эффективного восстановления после аварий вначале необходимо выявить все могущие пострадать в случае аварии системы, а затем принять решение о способе реализации аварийных мероприятий - собственными силами или с помощью сторонних услуг. |
Планы должны также описывать общее кризисное управление, в том числе обеспечение безопасности сотрудников и взаимодействие с полицией, медиками, пожарными и другими специальными подразделениями.
Следующий шаг состоит в определении приемлемого времени восстановления для каждой сети или системы. Допустим ли простой системы в течение двух суток или даже одного часа чересчур много? Когда дело касается данных, компания должна также установить периодичность резервирования, оценив, может ли она позволить себе потерять транзакции за целый день?
Используя в качестве ориентира время восстановления и периодичность резервирования, компания затем должна выбрать техническое решение по восстановлению после аварий, и здесь у нее имеется широкий выбор - от резервного копирования на магнитную ленту до электронной переброски данных и зеркального копирования в оперативном режиме.
ВСЕ - НА МАГНИТНУЮ ЛЕНТУ
Традиционный план восстановления после аварий предусматривает полное ежедневное резервное копирование на магнитную ленту. После резервного копирования ленты отвозятся в надежное место. Предполагается, что в случае аварии ленты будут доставлены в другой офис, загружены на компьютер, и работа может быть продолжена.
Такой план соответствует ежесуточному резервированию данных и грозит потерей максимум за 24 часа (если авария происходит как раз перед тем, когда ленты должны быть перевезены в другое место). В этом случае время восстановления может составлять 48 часов: один день на доставку лент в другой офис и их загрузку и еще один день на запуск сети, диагностику и организацию работы. Последняя оценка дается в предположении о наличии "готового" альтернативного офиса, где вся компьютерная и сетевая инфраструктура уже установлена, и ее остается только сконфигурировать и запустить.
По оценкам Дона деМарко, директора по глобальному маркетингу и развитию бизнеса в IBM Business Continuity and Recovery Services (BCRS), свыше 75% систем и сетей в Соединенных Штатах резервируется посредством отправки магнитных лент на хранение в другое место.
Преимущества резервного копирования состоят в относительно низких затратах и наличии прошедших проверку временем процедур. Однако для многих компаний потеря данных за 24 часа неприемлема, а простой продолжительностью от 24 до 48 часов совершенно недопустим.
Сокращения простоев, связанных с резервным копированием на магнитную ленту, можно добиться за счет применения журнальной файловой системы или базы данных, куда записываются все изменения. Журнальные файлы могут пересылаться в другое место электронным образом или даже записываться напрямую на удаленный узел. Это позволяет приблизить момент восстановления, потому что после загрузки лент их содержимое может быть модифицировано с использованием всех запротоколированных транзакций; в результате потеряны будут только транзакции, выполнявшиеся в тот момент, когда на компьютере произошел сбой.
Однако даже при протоколировании время восстановления остается тем же, потому что ленты по-прежнему требуется доставить в другой офис и загрузить. Для сокращения времени восстановления компании в некоторых случаях могут прибегнуть к электронной переброске данных.
ПРЫЖОК В БЕЗОПАСНОСТЬ
В случае электронной переброски данные копируются по сети на удаленный узел. Некоторые компании используют этот метод как более автоматизированный и удобный (и, возможно, надежный) способ еженощного резервного копирования. Другие - для проведения более частых резервных копирований. Типичный период восстановления в этом случае составляет от двух до 12 часов.
Время восстановления можно сократить также за счет установки на узле, куда производится переброска данных, компьютера, вступающего в строй и берущего на себя часть или все функции отказавшей машины. Этот метод распространяется и на ситуации сбоя в критически важных системах транспортировки.
Замещающий компьютер может получать данные от нескольких машин. Для выполнения своей роли временного заместителя он должен иметь все необходимое прикладное программное обеспечение, иначе он не сможет заменить отказавшую машину.
Производительность может снизиться, если заместитель имеет меньшую вычислительную мощность или пропускную способность, чем отказавшая машина, а некоторые функции могут не поддерживаться, если он не имеет всего того же программного и аппаратного обеспечения, что и неработоспособный компьютер. Однако, по крайней мере, обслуживание не прекратится полностью на продолжительное время. Такой подход экономичен, потому что он сводит к минимуму число компьютеров, бездействующих до того момента, пока не случится нечто непредвиденное - и тем не менее он позволяет обеспечить частичное восстановление в течение нескольких минут.
Другой подход - заключить с провайдером услуг контракт на развертывание мобильного центра обработки данных или рабочих мест в вашем офисе с использованием машин с уже загруженными на них вашими данными или, по крайней мере, на прямую поставку машин к вам офис с последующей загрузкой на них информации. В случае мобильного центра обработки данных время восстановления, как правило, не превышает 48 часов. Однако прямая поставка обычно занимает больше времени (как правило, 96 часов) ввиду необходимости проведения инсталляции ПО и загрузки данных.
Продолжительность резервного копирования баз данных можно сократить за счет использования таких методов, как копирование только обновлений и добавлений, поскольку они составляют обычно малую долю от всей базы данных. Этот метод позволяет также сократить требуемую пропускную способность сети, плата за которую составляет основную статью расходов при электронной переброске данных.
Однако все равно электронная переброска данных обходится обычно по крайней мере в два раза дороже, чем резервное копирование на магнитную ленту, - как правило, она оказывается в три-четыре раза дороже.
ЗЕРКАЛО, ЗЕРКАЛО
Для многих компаний время восстановления в 12 или 24 часа является неприемлемым. "Наши клиенты в области электронной коммерции требуют предотвращения потерь данных и восстановления за время от нескольких секунд до менее двух часов", - рассказывает Джон Джексон, президент Comdisco Continuity Services.
Такой короткий срок восстановления обычно недостижим в случае применения одной переброски данных: хотя каждой защищаемой системе часто выделяется отдельное устройство хранения, далеко не для каждой выделяется своя резервная система, готовая взять на себя выполнение операций.
Чтобы время восстановления не превышало одного часа, данные необходимо зеркально скопировать на идентичную выделенную систему. После этого на защищаемую машину устанавливается зонд, регулярно посылающий на зеркальную машину сообщения "Со мной все в порядке". Зеркальная машина вступает в строй, когда зонд посылает тревожное сообщение или не передает вообще никаких сообщений.
Теоретически это обеспечивает мгновенное прозрачное восстановление. Однако в случае крупномасштабной аварии всегда есть вероятность, что что-нибудь да помешает мгновенному восстановлению. Например, связь или Internet могут выйти из строя, у клиентского программного обеспечения могут возникнуть проблемы с переключением на новый сервер, или у ответственных лиц в этот момент могут оказаться более важные дела. Тем не менее при надлежащем планировании зеркальную систему обычно удается запустить в течение часа.
Компании могут добиться еще более высокого уровня защиты, если оба сервера будут функционировать параллельно. В этом случае клиенты прозрачным образом перенаправляются на наиболее доступный в данный момент сервер. Такое многолучевое решение позволяет повысить производительность в обычном режиме работы. Его недостаток в том, что оно потребляет дорогостоящую пропускную способность глобальной сети, а также управленческие ресурсы и силы в резервном офисе. Но даже при таких мерах некоторые транзакции могут быть потеряны.
По словам Джима Симмонса, главного исполнительного директора SunGard Recovery Services, многолучевые решения обычно берут на вооружение финансовые институты, такие, как банки, брокерские фирмы и фондовые биржи. К ним прибегают также компании, занимающиеся электронной коммерцией, чье преуспеяние всецело зависит от Web.
Однако многие компании считают такие методы защиты чрезмерными для большинства своих серверов. Как показал проведенный в ноябре 1999 года компанией Comdisco опрос 200 американских предприятий, только 19% из них на широкой основе используют удаленное зеркальное копирование или непрерывное резервное копирование своих корпоративных серверов. Для серверов локальных сетей эта цифра сокращается до 13%.
Однако Симмонс считает, что с распространением электронной коммерции и снижением стоимости хранения к этому методу станет прибегать все большее число компаний. Кроме того, по его словам, тенденция к размещению компьютеров в центрах обработки данных провайдера услуг по восстановлению после аварий способствует тиражированию, так как исключает затраты на одну из самых крупных статей расходов - глобальную сеть.
Некоторые компании тиражируют всего несколько критически важных серверов для обеспечения выполнения таких функций, как ввод заказов, управление цепочкой поставок и планирование корпоративных ресурсов (Enterprise Resource Planning, ERP). По данным Донна Скотта, аналитика из Gartner Group, в 2000 году 70% компаний из числа Fortune 500 будет использовать системы резервного копирования на базе тиражирования для 10% своих данных.
ОБРАЩЕНИЕ К СТОРОННИМ УСЛУГАМ?
Наряду с определением целей восстановления после аварий и принятием технических решений компания должна определиться с тем, как она собирается реализовывать восстановление после аварий - собственными силами или с помощью сторонних услуг. Например, случись катастрофа, сколько компаний пострадает одновременно с вами? Легко можно представить себе ситуацию, когда фирма по оказанию услуг восстановления после аварий окажется переполнена просьбами о помощи и вынуждена будет ранжировать их. Конечно, в своем собственном списке вы всегда первый...
Кроме того, при реализации восстановления собственными силами компания может воспользоваться стратегиями экономии, недоступными в случае, когда она прибегает к помощи сторонней фирмы. Например, тестовая инфраструктура может использоваться в качестве резервной для рабочей инфраструктуры. В случае распределенных систем схожие машины в различных офисах могут обеспечивать взаимное восстановление после аварий. Различные подразделения или даже партнерские компании также могут резервировать друг друга.
С другой стороны, поддержание двух сред так, чтобы одна могла заменить другую, легче осуществить на словах, чем на деле. Оборудование, программное обеспечение и сеть должны быть совместимы, иначе переключение окажется невозможным.
"Мне приходилось сталкиваться с ситуациями, когда компании пытались восстановить NT на другом компьютере. И хотя оба компьютера базировались на платформе Intel, с первой попытки это часто не удавалось сделать из-за различий в конфигурации оборудования", - говорит Фред Джой, аналитик из META Group.
Обеспечить совместимость оказывается особенно тяжело, когда закупки оборудования производятся независимо. Конечно, если заказчик не уведомит своего провайдера услуг по восстановлению после аварий об изменениях в программном и аппаратном обеспечении, то восстановление в этом случае также может оказаться безуспешным.
"Приложения пополняются файлами, которые люди забывают добавить в список резервируемых", - замечает Джой. Иногда у компании может быть необходимая стратегия регулярного резервного копирования с отправкой копий в надежное место, но какой-нибудь сотрудник может проигнорировать введенные правила и оставить резервный носитель в центре обработки данных на случай сбоя устройства.
Реализация восстановления собственными силами может оказаться затруднена из-за расхождения интересов различных групп и отделов компании. "Все данные, в особенности вне мэйнфрейма, невозможно защитить в одинаковой мере", - замечает Джой. Во избежание внутренних конфликтов пользователи часто вынуждены прибегать к независимой третьей стороне, чтобы определить, какое оборудование, программное обеспечение и приложения должны быть восстановлены скорейшим образом, а что может подождать.
Далее, экономия затрат может оказаться иллюзорной, если поддержание конфигурации на случай необходимости восстановления отнимает у сотрудников значительное время и вынуждает модернизировать некоторые системы в более короткие сроки и в большей степени, чем того требуют обстоятельства.
Более того, попытки экономии денег неизбежно влекут за собой компромиссы. Конфигурацию обеих систем может потребоваться сделать избыточной, чтобы одна могла заменить другую без заметного снижения производительности. Иначе вам придется мириться с некоторым ухудшением производительности в случае аварии или отказаться на время кризиса от некоторых функций, например от разработки программного обеспечения.
При обращении же к сторонним услугам компания может использовать обычные конфигурации в обычных условиях, но тем не менее избежать снижения производительности и функциональности во время аварии.
Наконец, даже если инфраструктура переводится в аварийный режим без проблем, то как насчет людей? Будут ли у сотрудников резервного офиса время и знания, необходимые для предоставления всех услуг (составления отчетов, предоставления справок, оказания технической поддержки конечным пользователям) для возобновления деятельности компании? Или придется переводить сотрудников в другой офис, что, возможно, еще больше увеличит время восстановления?
Обращение к сторонним услугам дает наибольший эффект в случае мэйнфреймов. Избыточные конфигурации стоят чрезвычайно дорого. Опытных специалистов не хватает, а их услуги обходятся дорого. Приложения на мэйнфреймах обычно имеют критически важное значение для деятельности компании, и поэтому от них нельзя отказаться даже в период кризиса.
Однако чем дальше в сторону систем среднего уровня, распределенных сред и ПК-серверов, тем дешевле обходятся избыточные конфигурации, и тем проще найти персонал для контроля за восстановлением после аварий, и тем легче пожертвовать некоторыми функциями в случае нужды.
Соответственно, по оценкам Джоя, только в 10% случаев восстановление мэйнфреймов после аварий осуществляется собственными силами - против 20-25% в случае отличных от мэйнфреймов систем.
Как бы ни осуществлялось восстановление - собственными силами, с помощью провайдера услуг или с применением обоих подходов, вам тем не менее может понадобиться обратиться к консалтинговой компании для определения своих потребностей. Как считает Фил Бладуорт, глобальный партнер PricewaterhouseCoopers Global Risk Management Solutions по планированию непрерывности бизнеса, "сегодня крупные организации предпринимают углубленный анализ процессов для определения своих требований к процессу восстановления. Все больше времени, когда дело касается восстановления, тратится на определение бизнес-целей".
ВОССТАНОВЛЕНИЕ БОЛЬШОЕ И МАЛОЕ
Если американская компания решает обратиться за сторонними услугами по восстановлению после аварий, то она обычно обращается к помощи кого-либо из "большой тройки" - Comdisco Continuity Services, IBM BCRS и SunGard Recovery Services.
"Девяносто процентов операций осуществляется этой троицей", - говорит Джой.
Крупные компании обращаются преимущественно к одному из этих трех провайдеров, потому что более мелкие не имеют, как правило, достаточных ресурсов для удовлетворения их запросов. При прочих равных условиях чем крупнее провайдер, тем лучше, потому что он обладает большими ресурсами для удовлетворения внезапного шквала претензий - или, в данном случае, заявлений об авариях и катастрофах. В случае, если ваша компания решит обратиться к сторонним услугам, вы должны запросить подробные предложения сопоставления всех полученных от поставщиков расценок.
Кого из "большой тройки" выбрать - сложный вопрос. Они имеют отделения во многих регионах, поддерживают широкий спектр платформ и обладают богатым опытом. IBM - относительный новичок среди них, компания создала соответствующее подразделение около 10 лет назад, тогда как Comdisco и SunGard существуют уже около 20 лет.
Однако на этом рынке, где даже такие тяжеловесы, как Digital Equipment и Hewlett-Packard (в лице ее Business Recovery Services), занимают весьма узкую нишу, IBM добилась равного положения со столь сильными конкурентами благодаря своим связям с клиентами, большому опыту восстановления после аварий (накопленному еще до создания специализированного подразделения) и непререкаемому авторитету в области мэйнфреймов и систем AS/400. Кроме того, IBM располагает такими возможностями для получения замещающих машин, как свой лизинговый бизнес IBM Global Financing.
Одна из проблем выбора, в особенности среди провайдеров услуг меньшего размера, - получение независимой достоверной информации относительно их возможностей и обязательств. Из "большой тройки" только SunGard проводит независимый ежегодный аудит, выполняемый консультантами PricewaterhouseCoopers.
С другой стороны, все три компании имеют отличный послужной список восстановления данных для клиентов даже в экстремальных обстоятельствах. Например, когда на США в сентябре 1999 года обрушился ураган Флойд, самый серьезный из когда-либо имевших место тест для служб восстановления, Comdisco обслуживала одновременно 33 аварии, SunGuard - 26, а IBM помогла пережить шторм 46 своим клиентам.
Провайдеры услуг размещения информационного наполнения на своих серверах Web также могут оказывать клиентам услуги по восстановлению. Так, Exodus Communications имеет свыше 1700 клиентов и предоставляет свои услуги в шести регионах США. Компания осуществляет зеркальное копирование серверов Web между своими центрами обработки данных. Exodus предлагает как услуги по переброске данных, когда резервный сервер становится активным только при отказе основного сервера, так и многолучевые услуги, когда оба сервера предоставляют услуги Web одновременно.
Поставщик систем хранения Imation разворачивает собственную службу LiveVault для серверов NT. Предназначенная для малых и средних компаний и базирующая на программном обеспечении LiveVault от Network Integrity, служба Imation использует агентов на серверах NT своих клиентов для непрерывной пересылки изменений в базе данных по Internet на центральные серверы NT в центрах обработки данных Imation.
В отличие от службы Imation, программное обеспечение LiveVault не ограничено соединениями Internet. Как отмечает Крис Мидгли, ведущий инженер Network Integrity, программное обеспечение разрабатывалось с учетом недостаточной надежности и доступности Internet. Однако корпоративные соединения Internet редко остаются недоступными в течение более чем нескольких минут, так что это огромное улучшение по сравнению с ежедневным копированием.
LiveVault экономно расходует пропускную способность, так как передает только изменения. Вообще, ПО LiveVault предназначено для баз данных объемом от 1 до 50 Гбайт. Линии DSL с пропускной способностью 1,5 Мбит/с оказываются при стоимости 300-400 долларов в месяц вполне эффективным по цене решением для резервного копирования больших объемов данных. Для получения большей пропускной способности они могут быть объединены. Клиент должен сам позаботиться о предоставлении серверов, на которых данные будут восстанавливаться. Услуга будет предоставляться с первого квартала 2000 года.
В октябре же 1999 года Imitation начала продавать программное обеспечение LiveVault корпорациям, при этом пока и центральные серверы, и клиенты выполняются на машинах заказчиков. Цена составляет 3600 долларов за программное обеспечение центрального сервера плюс 2400 долларов за каждого агента.
БУДЬ ГОТОВ
Ключом к эффективной реализации решения по восстановлению после аварий является правильное определение потребностей компании. Вряд ли кто-нибудь хочет столкнуться с неожиданными сюрпризами, когда случится авария. Вам следует провести тщательный анализ рисков, в том числе определить последствия для бизнеса и план восстановления деятельности компании. При наличии плана критически важные операции удается восстановить быстрее, чем при его отсутствии.
По какой бы причине сеть ни перестала функционировать, будь то землетрясение или отказ жесткого диска, даже небольшая предварительная подготовка может позволить избежать катастрофических последствий.
Майкл Гурвиц пишет о компьютерных и сетевых технологиях. С ним можно связаться по адресу: mhurwicz@psgroup.com.
Рассматриваемые продукты и услуги
Comdisco Continuity Services http://www.comdisco.com
Exodus Communications http://www.exodus.com
Hewlett-Packard Business Recovery Services http://www.hp.com/go/recovery/
IBM Business Continuity and Recovery Services (BCRS) http://www.ibm.com/services/continuity/
Imation http://www.imation.com
Network Integrity http://www.livevault.com
http://www.netint.com
ONTRACK Data International http://www.ontrack.com
PricewaterhouseCoopers Global Risk Management Solutions http://www.pwcglobal.com
SunGard Recovery Services http://www.e-recovery.com
Ночь после трудного диска
Если с такими разрушительными катастрофами, как наводнение, пожар или землетрясение, приходится иметь дело не так уж часто, то с невозможностью восстановления данных с жесткого диска приходится сталкиваться сплошь и рядом. У диска может сломаться головка или оказаться удаленным или испорченным раздел FAT, из-за чего ОС окажется не в состоянии обращаться к файлам. Какой бы ни была причина, результат один и тот же: резервной копии нет и данные оказываются безвозвратно утеряны. Или нет?
В большинстве случаев, если быстро принять меры, данные можно восстановить целиком или частично. Например, при удалении файла в DOS, Windows или Macintosh, ОС просто помечает файл как "удаленный". ОС в действительности не стирает данные, пока на их место не будет записан новый файл.
Восстановить удаленные, но не стертые файлы можно с помощью нескольких утилит. Кроме того, специальное программное обеспечение позволяет вернуть данные в исходное состояние после воздействия на них вирусов. Такие утилиты стоят от 50 до 500 долларов.
В случае внутреннего аппаратного сбоя диска его можно попытаться отдать в лабораторию, где работающие в специальных защищенных от пыли помещениях техники вскроют диск и извлекут данные.
Например, ONTRACK Data International взимает плату от 700 до 900 долларов за восстановление диска удаленным образом или в лаборатории в обычном, непылезащищенном помещении. Если же диск требуется вскрывать в пылезащищенном помещении, то цена возрастает на 400-500 долларов.
Грег Ольсон, директор по услугам восстановления данных в ONTRACK, советует не торопиться восстанавливать диск с резервной копии. Если резервная копия испорчена, то попытка восстановления может затруднить или сделать невозможным восстановление данных. Вместо этого восстановление следует сначала попытаться произвести на другой диск. Проблемный диск можно восстанавливать, только убедившись в сохранности копии. Если же резервная копия испорчена, то вам потребуется программа для лечения диска.