

Мониторинг сети - ключ к ее бесперебойной работе. Предотвратить - и ликвидировать - проблемы с производительностью можно разными методами.
В современных высококритичных сетевых средах пользователи привыкли к производительной и надежной работе приложений. Таким высоким требованиям, ранее предъявлявшимся лишь к финансовым и некоторым другим критически важным приложениям, теперь должны соответствовать системы документооборота, программы учета ресурсов, бухгалтерские системы и приложения электронной почты, без которых деятельность многих организаций просто немыслима. Сбои и простои систем недопустимы, поскольку из-за них страдает репутация компании.
Управление производительностью позволяет не допустить подобных ситуаций, а также помогает быстро отреагировать в случае возникновения такого рода трудностей. Важнейшим аспектом этого процесса (особенно с точки зрения предотвращения снижения производительности) является тщательное планирование пропускной способности. Архитектура сети должна быть достаточно надежна, чтобы поддерживать развертываемые приложения и обеспечивать отказоустойчивость. (Дополнительную информацию о планировании производительности можно найти в статье того же автора "Азбука планирования нагрузки" в декабрьском номере LAN за прошлый год.)
Мониторинг и настройка параметров имеющейся сетевой инфраструктуры - еще один, не менее важный аспект управления производительностью. Для этого каждый компонент сети должен иметь контрольно-измерительные средства. Если они отсутствуют, обеспечить бесперебойную работу или даже выяснить причину снижения производительности вы не сможете. В конце концов, сеть ни при чем, когда на сервере, в сегменте, шлюзе или приложении возникает сбой.
В предлагаемой читателям статье мы остановимся на вопросах мониторинга и настройки, связанных с управлением производительностью, а также расскажем о методах и инструментальных средствах, которые мои коллеги и я используем для диагностики и разрешения проблем с производительностью, с которыми нам приходилось сталкиваться по роду своей деятельности. Мы также рассмотрим некоторые поучительные примеры и расскажем о том, как должным образом оснастить сеть контрольно-измерительными средствами.
ДИАГНОСТИКА СНИЖЕНИЯ ПРОИЗВОДИТЕЛЬНОСТИ
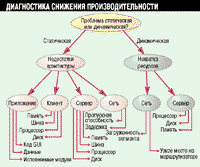
Если приложение в сети работает недостаточно производительно, то в первую очередь необходимо выявить причину проблемы. На Рисунке 1 показана блок-схема, разработанная специально для этой цели.
 (1x1)
(1x1)
Рисунок 1.
Эта блок-схема должна помочь в диагностике причин низкой производительности.
Если уровень производительности зависит от времени или месторасположения,
то это динамическая или связанная с ресурсами проблема. В противном случае
вы имеете дело со статической или связанной с архитектурой проблемой.
При определении причины недостаточной производительности сначала нужно выяснить, является ли она постоянной или временной. К примеру, всегда ли приложение работает непроизводительно или только во время периода пиковой нагрузки? Если верно первое, то имеет место статическое снижение производительности, если второе - динамическое.
Для того чтобы собрать требуемую информацию, следует встретиться с пользователями и выяснить природу проблемы. Во многих случаях выявить причину снижения производительности довольно сложно, поскольку проявляется оно лишь время от времени или только в работе конкретных пользователей. В этой ситуации вам необходимо установить связь замедленной реакции системы со временем дня и другими переменными. Без подробной беседы с пользователями провести точную техническую диагностику просто невозможно.
Как только вы определили, является ли падение производительности статическим или динамическим, можно начинать поиск возможных причин. Динамическое снижение производительности обычно указывает на недостаток ресурсов, к примеру пропускной способности разделяемой сети или циклов процессора хоста, и проблемы, с ними связанные, возникают, как правило, в разделяемых областях инфраструктуры: в сети или на серверах. Сетевые проблемы проявляются в сегментах сети или, что происходит заметно чаще, на промежуточных маршрутизаторах, коммутаторах или шлюзах. Серверные проблемы связаны с нехваткой таких ресурсов, как емкость памяти, мощность процессора или скорость обмена с диском. Динамическое падение производительности происходит в тех случаях, когда потребности в ресурсах превосходят возможности имеющихся ресурсов. Например, производительность бухгалтерских приложений может снижаться к концу месяца.
Правильное размещение в сети контрольно-измерительных средств (о чем мы поговорим подробнее ниже) позволило бы довольно быстро диагностировать и установить причину возникновения динамического снижения производительности, поскольку оно связано с очевидным недостатком ресурсов. Статическое снижение производительности устранить сложнее, так как очевидных ограничений на ресурсы в этом случае нет. Данные проблемы вызваны в основном недостатками архитектуры. К примеру, сеть не имеет необходимой пропускной способности, клиенты и серверы обладают недостаточной памятью, мощности процессора не хватает, а скорость внутренней шины обмена с диском низка. Неправильное размещение приложений и чрезмерный объем кода графического интерфейса, элементов данных и исполняемых модулей также относятся к изъянам архитектуры.
Зачастую для определения источника статических или архитектурных недостатков необходим сложный анализ, поскольку установленные датчики не всегда правильно указывают причину низкой производительности. В частности, с одной стороны, мониторы производительности, отслеживающие сетевой трафик или загрузку процессора на сервере, не обнаруживают перегрузки, а с другой - приложение не отвечает требованиям пользователей к производительности. Приложение, например, может производить слишком большое число обменов по сети в рамках одной транзакции или чересчур много небольших транзакций, связанных с чтением/записью на диск. Как только вы определили, в чем состоит проблема, необходимо решить, поможет ли модернизация оборудования (дорогой вариант), или придется изменить архитектуру приложения.
Поскольку диагностирование и устранение статического снижения производительности - вещь довольно сложная, думается, нелишне познакомиться с этой проблемой более детально. Рассмотрим три примера.
ИСКЛЮЧИТЕЛЬНЫЙ СЛУЧАЙ
В одном из филиалов банка сотрудники сетовали на низкую производительность системы автоматизированного контроля деловых процедур. В этой компании компьютеры конечных пользователей и сервер документооборота находились в разных сегментах сети Token Ring на 16 Мбит/с, связанных друг с другом магистралью FDDI на 100 Мбит/с. На сервере размещалась база данных, которая отслеживала работу системы. Вводимая информация (в данном случае - целые кипы чеков) представляла собой сканированные штрих-коды, а система контролировала местонахождение и состояние каждой партии в процессе ее обработки. Из беседы с пользователями стало ясно, что снижение производительности происходило при генерации отчетов о недостающих чеках. Генерация каждого отчета и создание резервной процедуры занимала 10-20 минут. Операторы вынуждены были отказаться от автоматизированной системы и вернуться к старой бумажной схеме.
Недостаточная производительность имела место все время, а не только в период пиковой нагрузки, из чего можно было заключить, что проблема имеет статическую природу. Более того, мы обнаружили, что клерки, которые располагались ближе к серверу базы данных и не пользовались корпоративной магистралью, были вполне довольны производительностью системы. Все признаки указывали на изъян архитектуры, связанный с магистральной сетью и приложением.
Чтобы определить причину низкой производительности, мы запустили генерацию отчетов об отсутствующих чеках с рабочей станции, на которой проявлялся этот недостаток, и проконтролировали полученный трафик с помощью портативного анализатора протоколов Hewlett-Packard Network Advisor. Тесты были проведены в пиковые рабочие часы. Измерения фонового трафика показали, что создаваемая им нагрузка минимальна.
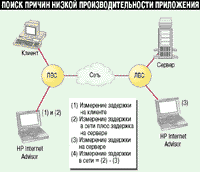
В нашей тестовой конфигурации мы установили анализатор компании HP на сервере и клиенте, после чего запустили генерацию идентичных отчетов с каждой станции (см. Рисунок 2). Анализ отметок о времени на пакетах показал, что 62% задержек приложения связано с задержкой в сети FDDI и на соответствующих многопротокольных маршрутизаторах. В целом падение производительности сети стало результатом или недостаточной пропускной способности, или чересчур больших задержек. Хотя магистраль FDDI имеет достаточную пропускную способность для поддержки такого трафика, связанные с ней маршрутизаторы обслуживают настолько большое число задач, что задержка каждого пакета составляет около 1,5 мс. Так как между клиентом и сервером были расположены два маршрутизатора, задержка возрастала до 3 мс. В сети Token Ring время передачи пакетов размером 350 байт, используемых приложением, составляло 0,175 мс (350*8/16 000 000). В целом сеть FDDI и маршрутизаторы увеличивают задержку пакета в 20 раз.
 (1x1)
(1x1)
Рисунок 2.
Если в сети имеет место статическая проблема, необходимо определить,
где возникает узкое место: на клиенте, сервере или в связывающей их сети.
Измерения, сделанные в двух точках при помощи анализатора протокола, и
тривиальные вычисления позволят вам найти виновного.
Мы провели также замеры на сервере. Роль сервера выполняла машина с процессором Pentium и операционной системой NetWare 3.x, где размещалось приложение базы данных с информацией о деловых процедурах. Мы запустили ServerTrak, инструментальное средство для мониторинга сервера компании Intrak, позволяющее контролировать загрузку процессора, использование памяти и ввода-вывода на диск. Мы определили фоновую загрузку процессора на сервере, а также нагрузку при генерации одного и нескольких отчетов. По нашим наблюдениям, уровень загрузки процессора составил от 0% до 5%, а каждая транзакция при генерации отчета занимала около 15% ресурсов процессора. Этот тест подтвердил, что дело здесь не в производительности сервера.
На основе наших измерений мы рекомендовали следующие решения. Запускать приложение автоматизации деловых процедур в сети на базе маршрутизаторов Novell с малой задержкой (маршрутизаторы Novell имеют очень невысокую задержку при обработке IPX-пакетов); использовать несколько серверов баз данных, расположив их как можно ближе к группе пользователей, сталкивающихся с недостатком производительности. В качестве долговременной цели - модернизировать корпоративную магистраль до ATM с малым временем ожидания или использовать технологию коммутации Уровня 3.
РАССЕРЖЕННЫЕ БУХГАЛТЕРЫ
Клиент-серверные бухгалтерские приложения зачастую весьма усложняют работу администраторов сети по нескольким причинам. Во-первых, время ответа в этих системах - параметр критический: отчеты, создаваемые в конце дня, месяца или квартала, должны быть готовы к определенному моменту времени. Во-вторых, для генерации требуемой информации часто необходимо выполнить большой объем вычислений. В-третьих, бухгалтерская деятельность сочетает в себе обработку транзакций и генерацию отчетов, выполняемых одновременно на одной машине.
Мы работали с организацией, у которой возникли подобные проблемы при использовании бухгалтерского пакета. Пользователи жаловались, что генерация кассовых отчетов, ведение главной бухгалтерской книги и отчеты по проверке баланса занимают слишком много времени. На основе своей методики мы установили, что снижение производительности является статическим. В бухгалтерии 12 сотрудников, и, в большинстве случаев, в каждый момент времени подобные отчеты генерирует только один из них. И несмотря на это система работала медленно.
Так как сеть недавно была модернизирована до Ethernet на 100 Мбит/с, было понятно, что причина не в пропускной способности сети. Мы исключили также маршрутизаторы в качестве возможного источника проблем, поскольку серверы и клиенты размещались в одном сегменте подсети. Проверка трафика приложения прояснила ситуацию. При запуске отчета по одной странице главной бухгалтерской книги сетевой трафик составил 25 Мбайт; т. е. приложение генерировало более 25 Мбайт сетевого трафика для этой одной транзакции. Информация в отчете занимала около 1-2 Кбайт текста. К сожалению, сетевой трафик приложения не был протестирован перед его инсталляцией. Такие непроизводительные приложения не редкость, так как разработчики стараются ускорить дату выпуска и создают плохо продуманную, не масштабируемую должным образом архитектуру. Другие приложения, протестированные нами, оказались очень эффективными, т. е. общий сетевой трафик лишь ненамного превышал объем информации, передаваемой конечному пользователю.
Поскольку, как было установлено ранее, сеть не являлась узким местом, причиной возникновения проблемы мог быть только сервер или клиент. Мы сравнили производительность двух клиентов, оснащенных процессорами Pentium/100 МГц и Pentium/166 МГц, и проанализировали сетевой трафик, генерируемый при подготовке отчета по главной бухгалтерской книге. Для того чтобы вычислить общую задержку приложения (TA) для каждой машины, мы сложили время ожидания сервера (TS), которое представляет собой время, необходимое серверу для доступа к блоку данных на диске, и время ожидания клиента (TC), т. е. время передачи данных клиентом в бухгалтерское приложение. Приложение выполнялось в пакетном режиме Novell, а вся транзакция разбивалась на блоки размером 16 Кбайт. Для клиента с процессором на 100 МГц TA для каждого блока объемом 16 Кбайт составила 0,0439 с (если TC+TS = TA, то 0,023 + 0,0209 = 0,0439 с). Так как весь отчет по главной бухгалтерской книге генерирует 25 Мбайт сетевого трафика, то для его исполнения требуется 69 с. Наше исследование на основе информации, собранной анализатором протоколов, показало, что каждый блок размером 16 Кбайт требует четырех обращений к диску на сервере, размер серверного блока составлял только 4 Кбайт.
На основе этих измерений мы рекомендовали два способа увеличения производительности. Во-первых, использовать более быстрых клиентов. Наши данные показали, что клиентский компьютер с процессором на 166 МГц работает почти в два раза производительнее, чем машина с процессором на 100 МГц, т. е. этот показатель лучше соотношения тактовых частот процессоров (166/100 = 1,66). Мы пришли к заключению, что дело тут в наличии более быстрой шины или памяти на ПК, имеющем процессор с тактовой частотой 166 МГц. Что касается сервера, то мы предложили увеличить размер блока на диске до 16 Кбайт, чтобы тот соответствовал размеру сетевого пакета - в этом случае для считывания пакета объемом 16 Кбайт понадобится только одно обращение к диску.
Бухгалтерами была выполнена только одна из рекомендаций. Они модернизировали свои машины с процессорами, имеющими тактовую частоту 100 МГц, что увеличило производительность в два раза. Однако это оказалось явно недостаточно, поскольку половина всей задержки в приложении приходилась на сервер, а другая половина - на клиент, использование сколь угодно быстрого клиента могло увеличить производительность лишь в два раза, а эта разница была не столь заметна конечному пользователю.
Обычно мы стараемся дать рекомендации, с помощью которых наши клиенты могли бы повысить производительность на порядок. Для этого часто требуется модернизация одновременно нескольких компонентов - клиентов, серверов и сети. В данном случае увеличить размер серверного блока оказалось невозможно, поскольку другие приложения, исполняемые на этом же сервере, требовали блока размером 4 Кбайт. Так что бухгалтеры предпочли поискать более эффективное бухгалтерское приложение.
УСТАНОВКА ДАТЧИКОВ В СЕТИ
Как правило, инструментальные средства, необходимые для управления производительностью, относятся к одной из трех категорий: инструментальные средства для измерения характеристик сети, для создания соответствующей нагрузки на сеть перед установкой новых приложений, а также для моделирования работы сети после добавления приложений. К другим инструментальным средствам относятся анализаторы протоколов, программное обеспечение мониторинга серверов и управляющие приложения для интерпретации данных.
Портативные анализаторы протоколов наиболее полезны при настройке производительности сети. С годами возможности этих устройств существенно возросли, и теперь они могут предложить высокоуровневые декодеры приложений, в том числе SQL и HTTP. Декодеры прикладного уровня позволяют более точно оценить ситуацию, с которой пользователи сталкиваются на своих рабочих станциях. Еще одно преимущество обеспечивают точные отметки о времени на каждом пакете. Небольшая средняя задержка одного пакета может существенно возрасти при значительном увеличении числа пакетов. Аппаратные анализаторы, такие как Internet Advisor компании HP, обычно имеют высокую производительность. Программные анализаторы, например NetXRay компании Cinco Networks, не "дотягивают" до производительности своих аппаратных аналогов, однако они, как правило, дешевле.
Портативные анализаторы являются неотъемлемым компонентом инструментария управления производительностью, но постоянно переносить их с места на место просто невозможно. Поэтому контрольно-измерительные системы необходимо разместить в стратегических точках сети. И в первую очередь здесь требуется подходящая платформа сетевого управления. Это позволит контролировать и управлять концентраторами, коммутаторами и маршрутизаторами. На рынке крупных сетей доминируют такие продукты, как Cabletron SPECTRUM, HP OpenView, SunNet Manager и IBM NetView (теперь Tivoli TME10). Целевой инструментарий управления для сетей, серверов и клиентов должен встраиваться в вашу корпоративную платформу так, чтобы в конечном итоге всю инфраструктуру можно было просматривать с одного дисплея.
В небольших и средних сетях (от 250 до 500 пользователей) лучше использовать snmpc компании CastleRock Computing. Этот продукт прост в применении, работает под Windows 95 и стоит всего 795 долларов. Согласитесь, не так дорого, если учесть, что стоимость программного обеспечения составляет лишь малую часть цены оборудования, которым оно управляет.
Мы рекомендуем snmpc организациям, у которых сеть строится вокруг компактной магистрали в виде маршрутизатора Cisco 4700. Если на маршрутизаторе возникает перегрузка, производительность сети резко падает. Таким образом, для таких организаций постоянный мониторинг загруженности маршрутизатора имеет решающее значение. Мы использовали snmpc для мониторинга и генерации отчетов о загруженности процессора маршрутизатора (эта информация содержится во внутренней базе управляющей информации MIB компании Cisco). Для небольших пакетов узким местом может быть недостаточная производительность процессора маршрутизатора; для больших пакетов - объединительная панель маршрутизатора на 280 Мбит/с. Пиковая нагрузка процессора, по нашим наблюдениям, составила около 10%. Для сравнения нами была просмотрена и статистика интерфейсов маршрутизатора из MIB-2. Подсчитав общее число входящих и выходящих пакетов, мы разделили его на два, чтобы получить общий трафик через маршрутизатор в пакетах в секунду. Пиковая нагрузка маршрутизатора составила около 7 тыс пакетов в секунду. Спецификации Cisco для этой платформы определяют нагрузку в 50 тыс пакетов в секунду, без учета предоставления таких возможностей, как списки доступа. По нашим данным, нагрузка маршрутизатора составила 14%, что, в общем, согласовывалось с непосредственными измерениями для процессора.
Зонды RMON - еще один ценный источник информации о сети. Устройства RMON хранят информацию о трафике уровня MAC в зонде и загружают ее для анализа; это позволяет минимизировать сетевой управляющий трафик. Кроме того, диапазон информации, накапливаемой данными устройствами, шире, чем у MIB-2. Зонды для анализа данных предусматривают наличие соответствующего приложения RMON на управляющей станции.
Расстановку сил в этой сфере определяют две тенденции: встроенные RMON и RMON-2. Встроенный RMON - это полезный способ генерации прерываний на каждом порту на основе предупреждений, подаваемых трафиком, входящим и выходящим через конкретный порт. Многие производители коммутаторов, такие как Cabletron и Bay Networks, предлагают встроенный RMON для каждого порта в коммутаторах Ethernet старшего класса. RMON-2 добавляет к RMON возможность анализа на сетевом уровне, предлагая девять дополнительных групп, в том числе для анализа протоколов и сбора статистики о трафике сетевого уровня.
Система Network Health компании Concord дополняет зонды RMON или другие агенты на устройствах. Network Health периодически выгружает данные из этих агентов и организовывает их в ретроспективную базу данных, что позволяет выявлять тенденции изменения ситуации. Это программное обеспечение сохраняет информацию в течение нескольких месяцев или лет, позволяя наблюдать изменение трафика в конкретной сети. В результате вы можете предвидеть возникновение узких мест и предпринять соответствующие действия.
МОНИТОРИНГ ПРОИЗВОДИТЕЛЬНОСТИ СИСТЕМЫ
Достойный внимания и недорогой (всего 86 долларов) продукт для анализа производительности клиента Windows 95 - это Performance 95 компании BonAmi Software. Он позволяет увидеть ситуацию "изнутри" вашей настольной системы и точно определить, какие ресурсы каким процессом используются. Многозадачные операционные системы, такие как Windows 95 и NT, одновременно запускают несколько приложений, что может потребовать весьма значительных ресурсов процессора. Даже выполнение простых функций с использованием апплетов Java могут вызвать недостаток ресурсов. Мы применили Performance 95 для мониторинга нагрузки процессора компьютера с Pentium/90 МГц, отображающего обновляемые данные о котировках валют в Web; это пассивное приложение занимало до 30% доступных ресурсов процессора. Операционные системы, такие как Windows NT, имеют встроенные инструментальные средства контроля производительности системы, которые могут быть использованы для аналогичного анализа.
Серверы - это еще одно потенциальное узкое место, поэтому и они должны быть оснащены контрольно-измерительными системами. Ранее уже упоминалось, что мы с успехом применили ServerTrak компании Intrak для контроля производительности. Эта компания также предлагает TrendTrak, продукт для мониторинга изменения производительности на сервере с течением времени. Что касается систем старшего класса, то комплексные продукты, такие как TME10 компании Tivoli и Unicenter компании Computer Associates, предлагают модули для мониторинга самых разнообразных типов серверов с одной управляющей станции. Patrol компании BMC Software - еще одна серия продуктов, созданных специально для мониторинга производительности серверов. В состав Patrol входят интеллектуальный агент для сервера и модуль знаний, специфические для каждого типа сервера. Консоль управления позволяет вам контролировать Windows NT, NetWare и 15 версий UNIX в рамках всего предприятия. Вы можете использовать программное обеспечение консоли для генерации предупреждений о возникновении перегрузки на каком-либо сервере. Если у вас есть только один или два сервера, то вам, возможно, не нужны продукты типа Patrol. Однако по мере того, как ваше предприятие будет расти, они станут неотъемлемым инструментарием настройки производительности.
ОТВЕТ ПРИЛОЖЕНИЙ
Главная задача инструментальных средств мониторинга - это контроль приложений конечных пользователей. Если инструментальные средства и сбор статистики о сети, клиентах и серверах полезны для диагностики проблем, то инструментарий анализа работы приложения предназначен для контроля времени ответа приложений конечных пользователей и обнаружения снижения производительности сразу, как только оно происходит. Управляющее приложение TME10 компании Tivoli - лидер в области контроля производительности приложений. В его состав входит API под названием Application Response Management, используемый для контроля и управления приложениями. Компактный агент производит контроль и измерения работы приложений на клиенте, благодаря чему конечный пользователь может точно определить время реакции. Информация о производительности передается затем менеджерам среднего уровня. Администратор всей сети может контролировать ключевые параметры производительности, наиболее важные для конечных пользователей.
Еще один продукт, предназначенный для оценки производительности приложений, - Application Expert (AE) компании Optimal. Этот инструментальный набор приложений, позволяющих локализовать узкие места производительности и работающих по сценариям типа "что если", анализирует воздействие предполагаемых изменений. Данные из AE могут быть импортированы в механизм имитации дискретных событий Optimal Performance.
ИМИТАЦИИ И ИСПЫТАНИЯ
Как отмечалось в начале статьи, управление производительностью начинается с проектирования и планирования. Но каким образом убедиться в состоятельности архитектуры? Как экстраполировать нагрузку, возникающую при одновременной работе сотен, или даже тысяч, пользователей? Здесь в игру вступают инструментальные средства моделирования и пробной нагрузки. Испытание сети осуществляется обычно до внедрения нового приложения. Имитация производится тогда же, а также в случае снижения производительности. В последнем случае имитация может быть использована для локализации узких мест и анализа возможных решений.
Имитация - это искусство и наука создания компьютерной модели для вашей сети, включая серверы и клиенты. Как инструментальное средство управления производительностью, она может быть использована для предварительного определения уровня нагрузки, локализации узких мест и оценки предложенных решений по устранению узких мест с производительностью. К примеру, если скорость доступа к Web слишком мала, то вы можете смоделировать эффект перехода с линий T-1 до линий T-3.
Бытует мнение, что моделирование как средство настройки производительности, - дело чрезвычайно долгое, поскольку на работу, необходимую для получения результата, могут потребоваться многие часы. Новые продукты, такие как ComNet Predictor компании CACI Products, в состоянии смоделировать работу сложной сети за относительно небольшой период времени. Механизм имитации Predictor основан на аналитическом моделировании, которое, как правило, значительно быстрее дискретной имитации событий для каждого пакета отдельно. При аналитическом моделировании информация о трафике и топологии сети может быть импортирована с измерительных зондов, что ускоряет процесс анализа. Ключ к использованию аналитических моделей - корректная обработка пакетного трафика. Predictor применяет собственный алгоритм Flow Decomposition Algorithm, учитывающий параметры пакетного трафика. Predictor может выполнять сценарии "что если" за считанные минуты.
Испытание сети дополняет имитацию. При наличии информации о сети одной имитации вполне достаточно, а кроме того, это обходится дешевле. Создание компьютерной модели сети отнимает значительно меньше времени и средств, чем построение реальной сети (прикиньте стоимость аренды канала глобальной сети в Гонконг для того, чтобы протестировать новое приложение). Однако если вы не можете получить надежные параметры сети для вашей модели, то испытание все-таки предпочтительнее.
Система Chariot компании Ganymede Software - это инструментальное средство тестирования работы сети на прикладном уровне. Оно может создавать сетевой трафик с требуемыми характеристиками, причем он будет проходить по всем необходимым "сетевым маршрутам", обеспечивая соответствующий набор и объем нагрузок, присущих приложению. Chariot имеет сценарии наиболее распространенных приложений, таких как передача файлов, доступ к Web и т. д. Трафик реального времени генерируется между агентами, расположенными на пользовательских и главных узлах. Это позволяет собрать статистику о производительности сети, в частности о пропускной способности и задержке.
ПУСТЬ ПОЛЬЗОВАТЕЛИ ОСТАНУТСЯ ДОВОЛЬНЫ
Для того чтобы пользователи остались удовлетворены производительностью приложения, необходимо предпринять следующее. Во-первых, вы, как администратор, должны понять, какие требования предъявляют пользователи к производительности приложения, и затем заключить формальные соглашения об уровне сервиса. Во-вторых, спроектировать и спланировать сеть, чтобы она отвечала этим требованиям к производительности, в том числе к избыточности и отказоустойчивости - гибкость сети имеет высокий приоритет в большинстве сред. В-третьих, установите контрольно-измерительные системы в сети, чтобы узкие места можно было идентифицировать сразу же при их возникновении, так как поведение конечного пользователя невозможно предсказать со стопроцентной точностью. Наконец, используйте управляющие приложения, которые способны анализировать собранные вами данные и помочь быстро планировать изменения, необходимые для удовлетворения требований, предъявляемых пользователями.
Фредерик Шолл, президент компании Monarch Information Networks, предлагающей сетевые услуги, в частности моделирование работы высококритичных приложений организаций. С ним можно связаться по адресу: freds@monarch-info.com.