
Инструменты складирования данных выпустили на волю информационные бури - стоило только убрать основное препятствие - недостаток полезности.
СКЛАДСКОЙ РЯД
ПОДДЕРЖКА ПРИНЯТИЯ РЕШЕНИЙ
ДИНАМИЧЕСКИЕ ДУЭТЫ?
ЗАПОЛНЕНИЕ СКЛАДА
ОТПИРАНИЕ ДВЕРЕЙ
МАССОВАЯ МИГРАЦИЯ
Рецепты Виджета По
ПРОЧЬ ОТ МЭЙНФРЕЙМА
Взаимная выгода
В течение десятилетий организациями создавались неисчислимые запасы служебных данных. Однако в некотором смысле эти запасы, засыпающие и заполняющие отведенное пространство, были завалами, недоступными по причине полного беспорядка. Администраторы информационных систем вместе с активно включившимися в работу поставщиками перепробовали множество подходов, пытаясь найти способ извлечь из залежей данных полезную информацию, но так до сих пор и не смогли добиться успеха.
Последнее поколение инструментов из разряда складов данных наконец-то расчистило завалы, главным образом благодаря тому, что они довольно отзывчивы и просты в управлении и быстры в доставке информации.
По мнению Виджета По, автора "Строительства склада данных для поддержки принятия решений" (Building a Data Warehouse for Decision Support, PTR Prentice Hall, 1995) и президента Strategic Business Solutions, есть две причины, почему этот вид баз данных так важен. "Во-первых, склады данных изменяют способ обработки данных и способ использования данных в бизнесе. Люди получают возможность работать с данными как с ресурсом, - говорит По, - во-вторых, с помощью данных могут быть найдены новые возможности в бизнесе - о чем многие до сих пор даже и не подозревают. Склады данных также важны как системы оперативной обратки транзакций (OLTP)". (Список рекомендаций для оценки складов данных см. во врезке "Рецепты Виджета По".)
Именно этот новый тип баз данных стал основопологающим компонентом системы оперативной аналитической обработки (OLAP). OLAP играет ту же роль в системах принятия решений, что и OLTP в стандартных бизнес-приложениях (например, в бухгалтерских системах).
Одним из вариантов решения проблемы складирования данных стали так называемые информационные системы руководителя, опирающиеся на допущение, что простые графы и диаграммы способны разрешить сложные проблемы бизнеса для руководителя. Недостаток таких систем состоял в том, что они метили слишком высоко, иными словами, были рассчитаны на высшее руководство, а не на аналитиков. Этот подход к тому же грешил упрощенностью, поскольку исходил из предположения, что одноэкранная консоль способна суммировать текущее положение дел на многомиллиардном предприятии - и это при объеме подлежащих обработке данных от 0,5 до 2 Гбайт и более.
Как и многие другие, щедрые на рекламную шумиху области информационных технологий, складирование данных породило множество громких слов и неологизмов. Ярмарка данных (data mart), псевдоаналогии типа ангара данных (data outhouse - неудавшийся проект склада данных), абстрактные рекомендации вроде визуализатора данных - вот только несколько примеров рекламных "завлекалочек". Впрочем, все это вполне соответствует апробированной схеме - авторы и консультационные компании изобретают новые слова для выражения старых идей.
И даже тем компаниям, которые найдут в себе силы разобраться с этой путаницей, придется потратить два-три года и свыше 2 миллионов долларов на то, чтобы организовать складирование данных должным образом.
СКЛАДСКОЙ РЯД
Преодолев излишнюю упрощенность первых продуктов, склады данных входят в моду. Их основной принцип формулируется следующим образом: ответы на сложные вопросы бизнеса можно найти только перелопатив большие объемы информации, причем эта информация должна рассматриваться и анализироваться с различных позиций. Если OLTP-системы сконцентрированы на узкоспециальных задачах, например на обработке инвентарных описей, то склады охватывают более широкую область и ищут решения среди нескольких направлений бизнеса. По определению, базы поддержки принятия решений доступны только для чтения, поэтому они дают картину деятельности компании в данный момент времени, тогда как системы на основе транзакций постоянно модифицируются.
База данных лежит в основе любого склада данных, и отыскать хорошую схему (хорошую модель данных) в системах OLAP так же важно, как и в системах OLTP. Однако схема в этом случае кардинально другая. OLTP-таблицы ориентированы на детали, а OLAP использует совокупности, сводки и временно-зависимые структуры, намного лучше служащие намеченной цели. Если для OLTP характерна высокая степень упорядоченности, то в инсталлированной базе OLAP преобладает звездчатая структура. Запросы поддержки принятия решений, выполняемые в упорядоченных структурах, ведут к так называемому выходу из под контроля, а это может обернуться молчанием всего мэйнфрейма в течение суток и более, пока база данных пытается найти ответ. (Отчет об организации, решившейся на отказ от структуры на основе мэйнфрейма, см. во врезке "Взаимная выгода").
Извлечь данные со склада так же важно, как и поместить их туда; средства хранения и выборки данных должны быть удобны для тех, кто будет ими пользоваться. Рассмотрим такой случай: менеджеры по маркетингу и финансовые аналитики вряд ли обрадуются тому, что формулирование запросов требует глубокого знания SQL, им непременно понадобится инструментарий, отвечающий их запросам относительно пропускной способности, гибкости и поддержки.
По указывает, что инструменты и методы, заимствованные у систем искусственного интеллекта, являются ключевыми для достижения этой цели. Эта тема более подробно обсуждается в статье Шерил Кривды ("Раскопки сокрытых данных").
ПОДДЕРЖКА ПРИНЯТИЯ РЕШЕНИЙ
Помимо собственно базы данных склада полная инфраструктура поддержки принятия решений требует целого ряда других продуктов (см. Рис. 1 - Типичная физическая архитектура реализации склада аднных, помимо всего прочего, включает сервер отчетов и удаленный доступ). На вершине этой инфраструктуры находится источник или накопитель данных, поступающих от нескольких источников оперативных данных. Среди таких источников - клиент-серверные базы данных OLTP, плоские файлы на унаследованных мэйнфреймах и даже многопользовательские базы данных Btrieve пятилетней давности, хранимые на сервере NetWare. Обычно их связь со складом данных осуществляется при помощи некоего соединительного программного обеспечения - шлюза, тиражирования или подкачки данных.
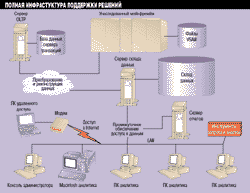 (1x1)
(1x1)
Рисунок 1.
Типичная физическая архитектура реализации склада данных, помимо всего
прочего, включает сервер отчетов и удаленный доступ.
Следующий шаг состоит в преобразовании и реструктурировании данных, поступающих часто из самых разнообразных источников, имеющих разную степень достоверности и разные определения полей. Этот процесс преобразования называется чисткой данных. Еще более осложняет ситуацию то обстоятельство, что структуры данных, хорошо подходящие для сущностей в транзакционной системе, представляют собою отнюдь не лучшее решение для склада данных. Ради ускорения доступа системы по мере зрелости начинают дублировать уже имеющиеся в других приложениях данные.
Итак, какую систему следует избрать в качестве организатора склада данных?
Ключевые поля часто загружаются вместе с информацией, а не присваиваются последовательно, как этого требует складирование данных. Вот почему на этапе преобразования необходимо позаботиться об "распаковке" этих полей. После такой, обычно автоматизированной, "чистки" данные можно поместить на склад.
Базу данных следует сделать доступной для сообщества пользователей. Эта часть инфраструктуры состоит из таких продуктов, как промежуточное обеспечение вроде драйверов ODBC, EDA/SQL и других, инструментов подачи запросов и анализа (составители отчетов, серверы отчетов, конструкторы запросов, графические средства), а также средств удаленного доступа. В связи с общим умопомешательством по поводу Internet некоторые организации ищут способы упростить удаленным пользователям доступ к системам поддержки принятия решений. Один из вариантов - создание страниц Web. В результате данные системы выдвигаются в категорию внешних интерфейсов, а для доступа к ним с удаленного узла необходима лишь хорошая программа просмотра.
Подобно любой другой сложной структуре ИС, склад данных нуждается в администраторе. Использовать инструменты преобразования и структурирования данных невозможно без знаний о планировании, функциональных возможностях и языках сценариев. Современные продвинутые инструменты составления отчетов, формулирования запросов и анализа невозможно представить без словарей доступных пользователям синонимов для неудобопонятных имен полей. А ведь такие словари кто-то должен составлять, кто-то должен также определить и отношения между таблицами.
Склад данных сам по себе нуждается в не менее опытном кладовщике, чем администратор любой другой системы управления реляционной базы данных (РСУБД). Документирование доступных данных важно до чрезвычайности. Чтобы напрямую задавать таблицы и поля при создании нестандартных и стандартных запросов и отчетов, пользователи, обращающиеся к складу данных, должны понимать его структуру.
ДИНАМИЧЕСКИЕ ДУЭТЫ?
Большинство поставщиков серверов баз данных пытается убедить всех, что их обеспечение подходит как для систем OLTP, так и для систем OLAP. Не верьте им. Лишь у некоторых из них найдутся новые версии или дополнительные модули с OLAP-ориентированными средствами, все же остальные просто пускают пыль в глаза. Однако серверы, пригодные для использования под склады данных, все-таки есть.
На поддержке решений специализируются серверы двух типов: некоторые серверы управления реляционными базами данных и системы управления многомерными базами данных. Warehouse VPT компании Red Brick Systems, наверное, самая известная РСУБД OLAP. В декабре 1995 года компания выпустила четвертую версию с новым методом индексирования под названием TargetIndex. Один из первых пользователей утверждал, что эта версия выполняла запросы на поиск в базе данных объемом 125 Гбайт в 20 раз быстрее, чем предыдущая.
TargetIndex использует побитовые индексы (некоторые другие продукты также применяют или собираются применить такой подход), но Red Brick заявляет, что их реализация является первой, работающей с полями, имеющими много возможных значений. Продукты других поставщиков, как заявляет компания, могут обрабатывать поля лишь с несколькими значениями. Например, Warehouse VPT работает не только с двухзначными полями, например пол и семейное положение, но и с многозначными полями, в частности профессия и доход.
Целый ряд компаний, специализирующихся на многомерной СУБД (MDDBMS), предлагает свои продукты. Среди них Essbase компании Arbor Software, Lightship компании Pilot Software и PowerPlay компании Cognos. Если предлагаемые продукты и способны представить данные в любом разрезе, то достигается это за счет того, что они используют нестандартные форматы хранения и работают обычно только с собственными инструментами составления отчетов, формулирования запросов и анализа.
Сознавая, что в эпоху открытых систем закрытые архитектуры служат барьером для внедрения, эти поставщики создали вместе с MetaGroup Совет по метаданным. Совет поставил себе целью создание стандартов для определения метаданных (данных о данных или словарей данных), что позволит извлекать информацию всем без исключения программам.
Hyperion Software, поставщик продуктов для узлов с системой отчетности в клиент-серверной архитектуре, прекрасно понимает, что многие заказчики обратились к такого рода программам именно для работы с данными. Так, компания купила механизм OLAP у Sinper и собирается продавать его под вывеской Hyperion OLAP.
Перспектива расширения РСУБД посредством включения рутинных операций над складами данных не очень-то радовала Oracle. Поэтому компания приобрела программистский дивизион IRI Software и теперь продает многомерной СУБД под названием Express Server.
Другие поставщики реляционных баз данных также добавляют поддержку OLAP, главным образом в виде побитовых индексов и измененных оптимизаторов запросов. Online Dynamic Server компании Informix, например, различает транзакционные запросы и запросы поддержки принятия решений. Благодаря этому администраторы смогут по отдельности конфигурировать размещение данных в памяти и процессы, относящиеся к каждой из функций. Informix приобрела также Stanford Technology Group ради выпускаемого той продукта MetaCube OLAP.
Sybase собирается предложить Sybase IQ в качестве опции с побитовыми индексами. Компания объявила о планах создания собственной OLAP.
Microsoft планирует внести существенные измения в SQL Server 6.5 ради поддержки складирования данных. В числе таких изменений нестандартные расширения SQL (cube и rollup), многомерная кластеризация и использование вызовов удаленных процедур для сбора данных с нескольких серверов.
Сознавая, что, мягко говоря, трудновато иметь в штате специалистов по такому количеству предметов, корпорации, создающие системы поддержки принятия решений на базе складов данных, все чаще обращаются к консультантам. Среди компаний, предлагающих как программное обеспечение, так и консультации по складам данных, следует упомянуть IBM (Visual Warehouse), Hewlett-Packard (Intelligent Warehouse), AT&T (Enterprise Information Factory Quickstart) и Sun Microsystems.
ЗАПОЛНЕНИЕ СКЛАДА
Интерактивные приложения редко используются для размещения данных на складе. Наиболее общий подход - написание пакетной программы, извлекающей нужные строки из базы данных OLTP, складывающей, собирающей и перераспределяющей эти данные, а затем загружающей строки в базу данных склада. Это перемещение можно осуществить тремя способами. Перечислим их в порядке возрастания сложности - тиражирование, подкачка данных и заказные программы.
Тиражирование возможно обычно только в тех случаях, когда базы данных OLTP и OLAP от одного поставщика или когда средство тиражирования исходной базы данных OLTP совместимо с базой данных OLAP. Кроме того, тиражирование располагает ограниченными средствами для преобразования данных. Как следствие - таблицы склада данных не должны сильно отличаться от источника. После тиражирования преобразования можно производить непосредственно в складе данных при помощи таких мер, как хранимые процедуры или триггеры.
Генераторы подкачки данных, например Trinzic InfoPump и InfoHub компании Platinum Technology, представляют собой специализированные приложения, предоставляющие те или иные средства преобразования данных, в значительной мере независимые от СУБД. Это значительно расширяет возможность выбора. Большинство таких продуктов используют SQL, визуальные средства и языки сценариев для управления необходимой перекодировкой. PowerBuilder 4.0 от PowerSoft (подразделение Sybase) включает и базовую утилиту для подкачки данных.
Заказные программы обеспечивают наивысшую степень гибкости, но и стоят они соответственно. Такие приложения могут быть разработаны на любом языке, если тот, помимо манипуляции данными, имеет средства для связи с источниковой и целевой базой данных.
У некоторых источниковых систем нет четких стандартов для проверки достоверности данных, а ведь они очень важны для мониторинга перемещения данных между базами данных. Из-за отсутствия стандартов особенно страдают устаревшие приложения и системы с вводом данных с клавишного перфоратора. Эту проблему нужно решить так, чтобы склад данных не пострадал.
Средний процент ошибок одного приложения, которое мы заменили, составлял 20 процентов. Помочь в решении этой проблемы могут инструменты очистки данных, однако зачастую они весьма дороги и ограничены в применении.
Group 1 Software и Postalsoft разработали чистильщиков для имен и адресов. Apertus Technologies, Validy Technology и Gladstone Computer Services предлагают многофункциональные средства с задаваемыми пользователем правилами, сопоставлением шаблонов и обучаемыми алгоритмами для нахождения несоответствий и повторений. Эти продукты стоят около 250 тысяч долларов.
ОТПИРАНИЕ ДВЕРЕЙ
Сами по себе склады данных мало что значат: для доступа, форматирования и анализа хранимых в них данных нужны другие средства. Крупные поставщики баз данных предлагают собственные продукты, однако многие компании отказываются от них в пользу более открытых, мощных и гибких инструментов, продаваемых сторонними поставщиками.
Наибольшей популярностью пользуются приложения с внешним интерфейсом для администратора, при помощи которого администратор может облегчить работу конечных пользователей со складом, с инструментами формулирования запросов и форматирования и, в некоторых случаях, с возможностью передачи обработки запросов назначенным серверам для сокращения времени отклика и снижения требования к ресурсам. Среди таких приложений - Impromptu компании Cognos, Crystal Reports от Crystal Services (подразделение Seagate), Focus for Windows от Information Builders и IQ Reports и IQ Objects от IQ Software.
Особенно интересен продукт BrioQuery компании Brio Technologies для платформ Windows и Macintosh. Он воплощен в трех вариантах: Explorer, Designer и Navigator. Explorer обеспечивает базовые для такого продукта возможности:
· доступ к большинству стандартных баз данных через родные драйверы или
ODBC;
· формулирование нестандартных запросов;
· обширные опции форматирования;
· документы с несколькими запросами и/или отчетами;
· интеграция с другими настольными приложениями через DDE и Publish/Subscribe.
BrioQuery обладает также мощными многомерными средствами перекрестных меток, благодаря чему пользователи могут выбирать несколько колонок на ось, например: время года и пол на одной оси против местонахождения и вида продукта на другой.
Версия Designer располагает такими административными функциями, как определение моделей данных. По сути, это аналог представлений SQL, но с дополнительной возможностью задания статических и динамических ограничений и предопределенных запросов. Среди других возможностей - средства создания справочной системы базы данных и ограничения доступа пользователей к метаданным.
Navigator во многом схож с Explorer - исключение в том, что в первом доступ к данным ограничен имеющимися моделями данных, в то время как второй имеет еще и доступ к нижележащим таблицам баз данных. BrioQuery имеет также встроенное средство написания сценариев для автоматического запуска отчетов и упрощения ввода запросов конечным пользователем.
Наиболее мощным, по мнению По из Strategic Business Solutions, комплектом инструментов является серия DSS компании MicroStrategy в составе DSS Agent, DSS Architect и DSS Server. Эти три продукта работают вместе с имеющимися системами над созданием полнофункциональной среды поддержки принятия решений, причем делают они это с гораздо меньшими усилиями, чем другие инструменты запросов. Серверный компонент осуществляет многомерные преобразования, избавляя от этого РСУБД.
Новым направлением, популярность которого со временем будет наверняка только расти, стало развертывание складов данных (или некоторых их подмножеств) в Internet с использованием серверов Web. Связь страницы Web с базой данных до сих пор не так то просто организовать, но Web настолько популярна, что несколько компаний уже начали выпускать инструменты для этих целей.
ParcPlace-Digitalk, ведущий поставщик продуктов SmallTalk, предлагает новую среду разработки VisualWave. VisualWave предназначена для создания сценариев HTML и CGI, поддержка Java будет добавлена в ближайшее время.
Spider компании Spider Technologies, способный заменить сценарии Perl, может похвастаться также и интегрированной средой разработки со средствами drag-and-drop. Illustra Information Technologies, недавно приобретенная Informix Software, поставляет расширения Web для своей объектной реляционной базы данных Web DataBlade. Продукт связывается с сервером Web через CGI. С его помощью пользователи могут создавать прикладные страницы, представляющие собою смесь HTML и SQL.
МАССОВАЯ МИГРАЦИЯ
Организации торопятся построить склады данных, для того чтобы их аналитическая мощь не пропала даром. Побудительные причины - ориентация на запросы клиентов, сокращение производственного цикла и разукрупнение. По мере того как все большее число компаний делают своим основополагающим принципом ориентацию на запросы клиентов, они начинают испытывать потребность в средствах быстрой дифференциации клиентов для проведения целевой маркетинговой компании.
В прошлом производственный цикл большинства продуктов занимал минимум несколько лет. Однако сегодня во многих отраслях этот цикл сократился до полугода. Без быстрого определения новых успешных продуктов компаниям просто напросто не выжить.
Популярность складов данных объясняется еще и тем, что значительную долю ответственности организации передают непосредственным исполнителям, а для успешного выполнения поставленных задач таким сотрудникам нужен быстрый и умный электронный помощник.
Предыдущие попытки использования обширных баз данных о деятельности компании - информационные системы руководителя и системы поддержки принятия решений - не достигли успеха, потому что они либо использовали чересчур упрощенный подход, либо ориентировались не на тот рынок. Правильная реализация склада данных позволит не только получить нужную информацию, но и обеспечит пользователей средствами определения и даже варьирования уровня и организации данных наилучшим образом. Вывод напрашивается сам собою - склады данных будут появляться, совершенствоваться и расширяться как важнейшие продукты информационных систем.
Билл Лазарь - автор статей о компьютерных технологиях и руководитель проекта разработки программного обеспечения для глобального предприятия. С ним можно связаться через Internet по адресу: blazar@gnn.com
ПОДДЕРЖАНИЕ СКЛАДА ДАННЫХ В ПОРЯДКЕ
Рецепты Виджета По
1. Ясно представляйте себе, зачем вам нужен склад данных - какие вопросы деятельности компании он призван будет решить?
2. Разберитесь в архитектуре данных выбранного склада данных.
3. Убедитесь в наличии технической инфраструктуры.
4. Распределите ответственность между работающими над проектом членами
команды и определите сроки.
5. Установите отличия между оперативной информацией и данными для поддержки
решений.
6. Пройдите необходимое обучение.
7. Добудьте нужные ресурсы.
8. Выбирайте программное обеспечение для доступа к данным в зависимости от потребностей и способностей пользователей.
Заимствовано из книги Виджета По "Building a Data Warehouse for Decision Support", перепечатано с разрешения издательства PTR Prentice Hall, 1995. С автором можно связаться по адресу: warehs@aol.com
ПРОЧЬ ОТ МЭЙНФРЕЙМА
ВЗАИМНАЯ ВЫГОДА
В 1990 году в медицинской страховой компании Community Mutual Insurance осознали, что имеющаяся система поддержки решений на базе мэйнфрейма больше не в состоянии удовлетворить потребности компании в анализе информации. Извлечение и форматирование данных занимало 90 процентов времени анализа, а внесение изменений и вывод были весьма дорогостоящей процедурой.
Компания сформировала действующую до сих пор группу для определения реальных нужд управления и конструирования архитектуры и набора систем, отвечающей этим требованиям. Основное требование - архитектура должна быть достаточно гибкой, чтобы эволюционировать вместе с компанией.
Группа провела ряд заседаний, в результате которых она разработала модель "сущность-связь" с учетом интересов различных подразделений и филиалов компании. Используя имеющиеся в то время на рынке продукты (шел уже 1992 год), группа выбрала машину Teradata MPP и базу данных для размещения склада данных.
Четыреста пользователей были разделены на три категории:
· Группа аналитиков - 25 человек с опытом создания отчетов для SAS Institute (они были первыми пользователями склада). Аналитики прошли трехдневное обучение языку SQL и затем приступили непосредственно к работе с базой данных Teradata.
· Пользователи среднего уровня, умеющие формулировать нестандартные запросы с использованием параметров; их обучили пользоваться доступными множествами данных и графическим инструментом анализа и отчетов Andyne SQL.
· Случайные пользователи, которым был предоставлен ряд заказных приложений, написанных на Visual Basic.
Базовая реализация удовлетворила потребности в данных для поддержи решений поначалу где-то на 85, а со временем и на все 100 процентов, при этом, в соответствии с конкретными требованиями отчетности, были добавлены многочисленные суммарные таблицы.
Community Mutual организовала также несколько групп для расширения и обеспечения развития и поддержки склада (например, группу ключевых пользователей). Кроме того, компания создала специализированную справочную систему.