

Cognitive Technologies представила свои разработки и очертила перспективы
В конце июня компания Cog?nitive Technologies продемонстрировала свои научные достижения в области распознавания и анализа образов, построения баз данных и информационно-аналитических систем, кроме того, ее специалисты поведали о перспективных направлениях разработок.
|
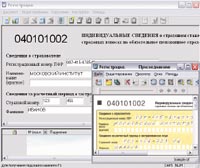
| С 1989 года Cognitive Technologies занимается созданием систем оптического распознавания бумажных документов, а в 1996-м она предложила решение Cognitive Forms, которое применяется при обработке разнообразных служебных документов, в частности налоговых деклараций |
Бумажные документы, пожалуй, — один из самых распространенных источников информации в современной деловой среде. С 1989 года Cognitive Technologies занимается созданием систем их распознавания, а в 1996-м она предложила решение Cognitive Forms, которое применяется при обработке разнообразных служебных документов, в частности налоговых деклараций. Компания постепенно переходила от настольных приложений к «промышленным» системам, решениям для массового ввода и обработки документов (Cognitive Forms Network), способным распознавать более 50 тыс. страниц в день, использующимся сейчас, например, в Пенсионном фонде РФ.
В Cognitive Forms применяется многопроходное и контекстно-зависимое распознавание документов. Это значит, что документ интерпретируется от более простых уровней (аналоговое и пиксельное представление) к более сложным (структура и содержание документа) и обратно. А сформированная системой гипотеза о документе (например, гипотеза о том, что это — паспорт, напечатанный на гербовой бумаге с определенным рисунком) помогает эффективнее распознать отдельные его части. Кроме того, в распознавании используются специализированные базы данных графических образов, содержащие десятки миллионов вариантов начертания символов и сотни тысяч страниц документов.
Лингвистические исследования компании направлены на извлечение полезной информации из неструктурированного или слабоструктурированного текста, каковым является большая часть информационных потоков в современном мире. Перед разработчиками стоит задача приблизиться к уровню автоматизированного «понимания» текста, для чего используется синтаксический анализ текстов, индексация, категоризация, выделение понятий, определение тематики произвольного текста, семантическая индексация текстовых объектов. Решения могут применяться в системах машинного перевода, поддержки пользователей (например, владельцев мобильных телефонов), распознавания речи и т. д. Среди практических применений лингвистических разработок специалисты компании назвали созданную ими для «Норильского никеля» систему анализа и прогноза конкурентноспособности предприятия на основе патентного анализа.
А информационно-аналитические системы, конструируемые компанией, направлены на предоставление экспертам инструментария для анализа и прогноза тенденций рынка. Они также включают полнотекстовый архив материалов по теме исследования, пополняемый как из бумажных СМИ путем распознавания, так и из электронных путем их автоматического отслеживания.
В ближайшей перспективе Cognitive Technologies — система машинного перевода, использующая для повышения точности перевод не отдельных слов, а осмысленных фрагментов текста. На стадии практического внедрения также находятся система автоматического распознавания языка текста и работающий с MS Word автоматизированный словарь для перевода.
Говоря о разработке системы управления базами данных, руководитель проектов компании Николай Емельянов отметил, что ее особенность — предоставление данных в формате XML. Технология xNika (XML+СУБД НИКА, собственный продукт компании, разработка которого ведется с 1978 года) позволяет работать с базой данных XML-документов практически любой сложности. Так, система на базе xNika, работающая с музейными экспонатами, имеет дело с объектами, обладающими 1,5 тыс. реквизитов.
Перспективными направлениями разработок компании в области СУБД являются также средства для проведения аналитических исследований сложных структур данных, а также «Технология единых форм», призванная привести к единым, автоматически обрабатываемым формам все основные виды документов. Например, из папки бумажных договоров предприятия за определенный срок с помощью этой технологии может быть создана база данных со всей значимой информацией по договорам. На основе этой базы, используя OLAP-модуль, можно будет провести автоматический анализ всех бизнес-процессов за данный срок.
Наконец, еще одной перспективной отраслью разработок в Cognitive Technologies назвали речевые технологии — методы распознавания, анализа и синтеза речи, а также создание речевых баз данных.