

InfoWorld, США
Получить достоверное представление о состоянии технологии управления контентом на базе XML можно, проанализировав разработки самого низкого уровня: библиотеки баз данных XML, которые формируют основу для более крупных приложений управления информационным наполнением
Рассмотрим две библиотеки: Xindice компании Apache Software Foundation и Berkeley DB XML компании Sleepycat. Это библиотеки с открытым кодом, обе они бесплатные и предоставляют соответствующие стандартам функции работы с документами XML. Кроме того, обе являются мощными инструментами разработки, которые позволяют программистам хранить, выполнять запросы и извлекать документы XML.
Apache Xindice 1.0
Создание Apache Xindice начиналось как проект dbXML Core, но после 2001 года результаты этого проекта были переданы группе Xindice. В документации Xindice говорится о целевой аудитории данного продукта: он предназначен именно для разработчиков, которым необходимы решения для хранения и манипулирования XML-данными.
На сайте Xindice недвусмысленно сообщается об ограничениях, присущих пакету; в отличие от Berkeley DB XML, пакет Xindice не очень хорошо работает с крупными документами XML. Для Xindice лучше всего подходят документы небольшого и среднего объема, хотя четкого определения, что такое «XML-документы небольшого и среднего объема», не существует. Вероятно, имеется в виду размер не более 1 Мбайт.
Процедура установки проста. Инсталлируются серверный исполняемый модуль Xindice, инструментарий командной строки, документация, исходные тексты и несколько примеров. Xindice написан на Java, поэтому для работы Xindice JAR (Java Archive) необходимо установить JDK 1.3 или выше.
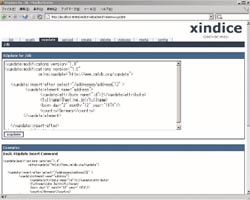
Программный интерфейс — DB XML API — также реализован на Java, но Xindice не ограничивается только языком Java. Он создан на основе архитектуры клиент-сервер и поддерживает XML-RPC API, поэтому доступ к серверу могут получать не только удаленные Java-клиенты, но и клиенты, написанные на других языках программирования.
Xindice организует хранение данных в виде «коллекций», причем все коллекции размещаются внутри корневого экземпляра «/db.» Коллекции можно представлять себе как вложенные папки файловой системы. Коллекции содержат «подколлекции» с любой глубиной вложенности. «Файлами» в этой аналогии являются документы XML. Запросы и обновления, как правило, применяются ко всей коллекции в целом, хотя можно уточнить область применения операции вплоть до отдельных документов.
Инструментарий командной строки в Xindice новые пользователи воспринимают как величайшее благо. Эксперименты с ним позволяют получить превосходное представление о возможностях Xindice и о прикладном программном интерфейсе, когда приходит время заняться разработкой. Инструментарий командной строки также полезен для того, чтобы быстро сформировать базу данных. Этот инструментарий создает новые коллекции, размещает в коллекциях XML-документы и даже целые иерархии подкаталогов Xindice.
Для выполнения запросов к коллекциям Xindice используется команда XPath, а для их обновления — XUpdate. Было бы неплохо, если бы поддерживался язык запросов XQuery, поскольку он открывает более богатые возможности организации запросов, но пока поддержка XQuery значится лишь в планах разработчиков Xindice. Инструментарий командной строки — прекрасный способ протестировать команды XPath и XUpdate, но, документация для этого пока неполна и наводит на ошибочное заключение о том, что XUpdate не поддерживается.
Несколько примеров программ на Java находятся в папке примеров вместе с соответствующими скриптами. Кроме того, имеется более крупное Web-приложение Addressbook, хотя для его работы придется установить Tomcat. Здесь, как и в случае с документацией по Xindice, не все продумано и придется изрядно поплутать.
Защитить базу данных Xindice можно с помощью пароля. Кроме того, реализована защита от коллизий при выполнении параллельных цепочек, поэтому, не опасаясь конфликтов, с продуктом могут одновременно работать несколько клиентов. Однако в Xindice нет встроенной поддержки транзакций. Это дополнительный пакет в DB XML API, и его можно будет добавить к серверу в дальнейшем.
Xindice — это проект Apache, поэтому он развивается теми темпами, которые определяет энтузиазм участников данного проекта. В некоторых случаях эти темпы на удивление высоки. Однако внутренне весь процесс несколько статичен, поэтому нет никакой гарантии того, что важные модификации или дополнения (такие как поддержка XML-файлов большого размера) будут сделаны.
Sleepycat Berkeley DB XML 2.0
Sleepycat недавно выпустила вторую версию своей СУБД. Berkeley DB XML создана на основе Berkeley DB и унаследовала от нее поддержку транзакций, восстановление после сбоев, выявление взаимной блокировки, шифрование и другие возможности. Фактически можно совершенно свободно объединять базы данных DB XML и «обычные» базы данных Berkeley DB в одном и том же приложении, не подключая к нему дополнительные библиотеки.
|
| Berkeley DB XML создана на основе Berkeley DB и унаследовала от нее поддержку транзакций, восстановление после сбоев, выявление взаимной блокировки, шифрование и другие возможности. Фактически можно совершенно свободно объединять базы данных DB XML и «обычные» базы данных Berkeley DB в одном и том же приложении, не подключая к нему дополнительные библиотеки |
Berkeley DB XML — свободно распространяемый инструментарий, хотя существуют определенные лицензионные ограничения, которые варьируются в зависимости от того, как используются и распространяются приложения, созданные на его основе.
В отличие от Xindice, DB XML не является клиент-серверной системой. Это библиотека, которая подключается (и работает в пространстве процесса) к приложению. Связывание поддерживается для многих языков, в том числе Java, C++, Perl, Python, Tcl и PHP. Кроме того, для ряда других языков такое связывание поддерживается с помощью решений сторонних производителей.
В версии 2.0 учтены пожелания пользователей, большая часть нового — это прямой результат обратной связи с ними.
Предыдущая версия обрабатывала документы как единые объекты, передавая верхний предел размера документа, который DB XML способна поддерживать (этот верхний предел, как правило, определяется емкостью имеющейся памяти и любой XML-документ, превосходящий данный предел, скорее всего, стал бы неплохим кандидатом на переработку).
В этой версии DB XML позволяет сохранять документы либо целиком (как раньше), либо разделяя их на фрагменты.
Если выбирается сохранение по узлам, документы разделяются, и их узлы сохраняются в специальных записях в базе данных. Как следствие, единственное реальное ограничение размера обрабатываемого документа — это доступное дисковое пространство. Berkeley DB может работать с базами данных объемом до 256 Тбайт, но мало кому удастся достичь этих пределов.
Как и в Xindice, при хранении в DB XML используется парадигма коллекций. Устанавливается режим хранения (целиком или по узлам) для данной коллекции. Все документы в этой коллекции сохраняются в таком же режиме.
Сохранение целого документа удобнее, если документы достаточно малы (их размер не превышает 1 Мбайт) и необходимо обрабатывать каждый документ целиком.
Кроме того, документы, извлекаемые из памяти с таким режимом хранения, побайтно идентичны документу, который был помещен на хранение. Это важно, если необходимо убедиться в том, что информационное наполнение документа не было изменено, например, если к документу добавлена цифровая подпись.
Поузловое хранение позволяет быстрее выполнять запросы и обновления, поскольку для обработки не нужно читать весь документ целиком. И, как уже отмечалось, это дает возможность работать с очень большими по размеру XML-документами.
DB XML 2.0 также имеет новый инструментарий командной строки. Как и в случае Xindice, такой инструментарий представляет собой прекрасный способ ознакомиться с функциональностью базы данных.
DB XML 2.0 поддерживает XPath и XUpdate, а также XQuery. Как и в случае с Xindice, можно использовать инструментарий командной строки для ознакомления с синтаксисом этих вариантов языка для формулировки запросов и обновлений. И так же, как и Xindice, DB XML 2.0 сопровождают многочисленные примеры, которые имеет смысл опробовать и изучить.
Гармоничная пара
И Apache Xindice, и Sleepycat Berkeley DB XML позволяют присоединять индексы к базам данных, обеспечивающие ускорение выполнения запросов. Однако DB XML предлагает более тесный контроль типа индекса и тем самым дает возможность точнее настроить параметры индекса в соответствии с теми видами запросов, которые, скорее всего, будут применяться.
Вдобавок инструментарий командной строки DB XML сообщает время, которое потребовалось на выполнение запроса, благодаря чему можно экспериментировать с различными видами индексов и стратегиями выполнения запросов для того, чтобы оптимизировать производительность.
Xindice и DB XML 2.0 — превосходные библиотеки; впрочем, DB XML предлагает более широкий спектр возможностей и выглядит лучше. Список возможностей проекта Xindice со временем обещает расти. Любые улучшения в Xindice пойдут на пользу растущему сообществу создателей и пользователей баз данных XML.