В IBM не рассчитывают полностью исключить человеческий фактор, но стремятся к тому, чтобы работа специалистов по обслуживанию корпоративных ИТ-систем стала проще
Новая технология, которую совместно разрабатывают IBM и Cisco, призвана облегчить автоматическую диагностику отказов, возникающих в ИТ-системах (в том числе — их обнаружение и локализацию), а также восстановление корпоративных ИТ-инфраструктур после сбоев.
Директорам информационных служб хорошо известно, что на обнаружение причин сбоев и устранение их последствий тратится львиная доля рабочего времени ИТ-специалистов. В последнее время ценность данного ресурса существенно выросла, поскольку ИТ-бюджеты многих компаний сокращаются. Именно на это и рассчитывают в IBM и Cisco, предлагая новые решения, обеспечивающие самодиагностику и самовосстановление компьютерных сетей. По словам представителей IBM, эти решения не только дадут возможность автоматически обнаруживать сбои и устранять их последствия, но также и упростят обслуживание ИТ-систем. Согласитесь, это имеет не менее важное значение в современных условиях, когда ИТ-системы, особенно на крупных предприятиях, становятся все сложнее.
Стандартизация вызывает сомнения
Как недавно вновь заявил директор по архитектурам и технологиям бизнес-подразделения самоуправляющихся вычислительных систем корпорации IBM Рик Телфорд, в нынешней стратегии корпорации в данной области решения, обеспечивающие самодиагностику и самовосстановление ИТ-инфраструктур после сбоев играют основные роли. «Полностью исключить человеческий фактор, конечно же, не удастся, но даже в тех случаях, когда без участия человека не обойтись, мы стремимся к тому, чтобы работа специалистов по обслуживанию корпоративных ИТ-систем стала проще», — заметил Телфорд.
Простой пример — неправильное прохождение транзакций. Причина может быть скрыта в любом из множества аппаратных устройств и программных приложений, входящих в корпоративную ИТ-инфраструктуру. Найти, где именно случился сбой в работе, порой бывает чрезвычайно сложно. «Пример типовой, но он охватывает целый пласт проблем, с которыми сталкиваются компании, — отметил Телфорд. — На практике количество таких проблем постоянно растет».
Первоочередные цели, которые ставят перед собой IBM и Cisco в рамках их совместной программы, включают создание нового поколения интерфейсов и инструментальных средств для ведения журналов событий, а также разработку программного обеспечения, позволяющего системным администраторам отслеживать и анализировать возникающие проблемы. Компании планируют не только предлагать эти технологические решения в составе своих коммерческих продуктов, но также, сделав их открытыми, пытаться утвердить их в качестве отраслевых стандартов.
Однако у специалистов перспективы этой затеи пока вызывают сомнения. Слишком много в ИТ-индустрии существует разного рода разногласий и политических препятствий, чтобы можно было с уверенностью говорить о том, что две компании, пусть даже столь мощные, как IBM и Cisco, способны установить стандарты в области самодиагностики и самовосстановления ИТ-систем после сбоев. «Будет уже неплохо, если такие функции появятся в системах, где используются продукты IBM и Cisco. Само по себе это уже обеспечит экономию времени и средств ИТ-подразделений многих компаний», — отметила аналитик из компании Wohl Associates Эми Вохль. По ее мнению, создать все средства автоматического восстановления после всех возможных случаев сбоев в ИТ-системах попросту невозможно. Но если совместные разработки IBM и Cisco сделают жизнь системных администраторов хотя бы чуть полегче, это станет большим шагом вперед.
Как отслеживать и что анализировать
Предложенная IBM спецификация Common Base Event (CBE) определяет стандартные форматы ведения журналов сетевых событий, позволяющих отслеживать прохождение транзакций и иные виды действий в компьютерных сетях. Телфорд подчеркнул, что крайне важно, чтобы существовал общий формат ведения журналов, который может заменить собой существующий сегодня «винегрет» способов сохранения системной информации. По его словам, на практике приходилось сталкиваться с такими случаями, когда при обслуживании систем электронной коммерции ИТ-службам компаний требовалась поддержка около 40 журнальных форматов. Для того, чтобы устранять сбои в таких системах и анализировать их причины, необходимо наличие в компании как минимум нескольких ИТ-администраторов.
По словам Телфорда, за счет использования CBE обслуживание подобных систем может значительно упроститься. Для этого необходимы две вещи. Первое — в новых продуктах потребуется реализовать поддержку CBE как основного журнального формата. Второе — чтобы сохранить возможность работы с продуктами предыдущих поколений (в которых реализованы закрытые журнальные форматы), необходимо использовать так называемые log-адаптеры, обеспечивающие трансляцию файлов старых log-форматов в формат CBE. В настоящее время в IBM команда из 24 инженеров занята разработкой log-адаптеров для основных продуктов корпорации, как аппаратных, так и программных. При этом особое внимание уделяется решениям, входящим в состав систем хранения данных. По словам Телфорда, реализуя планы по стандартизации собственных технологий, в августе IBM представила спецификацию CBE на рассмотрение в OASIS.
Роль Cisco в совместной программе с IBM сводится в основном к выпуску продуктов, поддерживающих созданные «Голубым гигантом» технологии. Это, кстати, тоже не такая простая задача, как может показаться на первый взгляд. К примеру, в IBM рассчитывают, что в Cisco сумеют создать такие маршрутизаторы, которые позволяют отслеживать связь регистрируемых ими событий с теми, которые записываются в журналы программным обеспечением промежуточного уровня IBM.
Что дальше
В более отдаленной перспективе компании планируют заняться разработкой технологий для крупномасштабных сетей, которые позволяли бы компаниям, не имеющим полного контроля над всей инфраструктурой сети (или, скажем, всем маршрутом прохождения сложных транзакций), тем не менее отслеживать происходящие события и анализировать полученную информацию.
По мнению аналитиков, несмотря на активные действия IBM и Cisco по пропаганде своей программы совместных разработок в области решений для самодиагностики и самовосстановления ИТ-систем после сбоев, уникальными созданные технологии не будут. Нечто похожее уже предлагают Hewlett-Packard и Sun Microsystems. Поэтому, как считает, к примеру, Эми Вохль, по мере того, как на горизонте прояснятся очертания будущих отраслевых стандартов, политические баталии вокруг них, скорее всего, станут гораздо острее. В этих условиях, по ее мнению, важную роль в прекращении конфликтов могут сыграть пользовательские сообщества и крупные корпоративные заказчики. Выигрыш от применения технологий самодиагностики и самовосстановления столь же очевиден, сколь и велик.
Четыре «само»
Формирование и продвижение стандартов обнаружения неисправностей (в том числе формата Common Base Event), — одно из направлений практической реализации концепции так называемых «адаптивных систем». Относительно недавно сформировавшаяся концепция, описывающая системы, способные приспосабливаться к изменениям во внешней среде эксплуатации, рассматривается ведущими экспертами как фактор дальнейшего развития ИТ. Зародившиеся еще в недрах мэйнфреймов технологии повышения устойчивости компьютерных систем, сегодня снова оказались в центре внимания...
Если в эпоху мэйнфреймов их конструкторы больше были озабочены повышением надежности отдельной системы, то сегодня задача состоит в обеспечении автономного функционирования распределенных гетерогенных конфигураций, способных не только справляться с аппаратными сбоями, но и самостоятельно оптимально распределять имеющиеся ресурсы, предсказывать моменты увеличения нагрузки, осуществлять безболезненное масштабирование и т.п.
Между тем заказчики все чаще требуют гарантированного соблюдения соглашения об уровне обслуживания. Все это происходит на фоне увеличения сложности, которая уже сама по себе становится проблемой. Скажем, расширение сети требует новых инструментов для ее управления, более квалифицированных администраторов, что, однако, совсем не гарантирует защиту от ошибок. В результате растет стоимость решений — даже несмотря на то, что цена отдельных компонентов уменьшается. Кроме того, от ИТ-инфраструктуры требуется возможность оперативного переконфигурирования, которое невозможно при нынешней организации работ, когда все подобные решения принимает человек-администратор...
Между тем, в современных ИТ-системах только 5% оборудования ориентировано на решение задач адаптивного управления и обеспечение непрерывного функционирования...
Адаптивная система держится на четырех «китах»:
- самоконфигурирование - адаптация компонентов системы к изменениям ИТ-конфигурации (автоматическое подключение новых серверов, модернизация программного обеспечения и т.п.);
- самолечение - диагностика неисправностей, устранение их последствий, локализация ошибок, изоляция сбойных узлов, подключение избыточных модулей;
- самозащита - предотвращение сбоев в системе в результате нарушения работы программного обеспечения и целостности данных;
- самооптимизация - рациональное использование имеющихся ресурсов без вмешательства человека.
—Из статьи Дмитрия Волкова
«ИТ в эпоху ?демократизации?»,
журнал «Открытые системы», №10, 2003
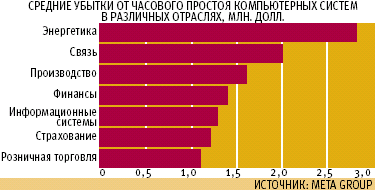
Убытки продолжают расти
Сложность компьютерных систем достигла сейчас такого уровня, что управление ими само стало источником ошибок, которые заметным образом влияют на экономические показатели работы отраслей