
Базы данных будущего станут сильно отличаться от того что описал Кодд

|
| Пат Селинджер считает, что Leo окажется полезен для крупных и сложных баз данных |
Теперь мы продвинулись еще на один шаг. Базы данных будут масштабироваться до гигантских размеров, охватывая множество офисов и поддерживая информацию в различных форматах. И они будут автономными и самонастраиваемыми. Ведущие производители баз данных добиваются этих целей разными способами.
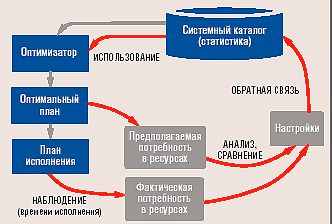
Тридцать лет назад научный сотрудник корпорации IBM Пат Селинджер разработала метод оптимизации запросов «на базе затрат» (cost-based). С помощью этого метода операции поиска в реляционных базах данных, таких как IBM DB2, сводили к минимуму использование компьютерных ресурсов за счет определения наиболее эффективных методов и маршрутов доступа. Теперь Селинджер, вице-президент IBM по технологии и архитектуре управления данными, возглавляет проект корпорации, получивший название Leo (сокращение от Learning Optimizer), который, по ее словам, позволит перевести оптимизацию в DB2 на новый уровень.
Вместо того чтобы один раз оптимизировать запрос в момент его компиляции, Leo будет анализировать бизнес-запросы по мере возникновения и настраивать их с учетом полученных знаний о взаимосвязях между данными и требованиями пользователей. «Эмпирическим путем из данных будут извлекаться полезные знания», — подчеркнула Селинджер. Например, Leo может выяснить, что ZIP-код ассоциирован только с одним штатом, или что модель Camry выпускает только корпорация Toyota, даже если эти правила заранее не сформулированы.
Селинджер считает, что Leo окажется весьма полезен для крупных и сложных баз данных, а также в базах данных, где внутренние связи между данными точно не указаны разработчиками. По ее словам, в ближайшие три года Leo, вероятно, будет включен в состав коммерческих версий DB2.
Представители Microsoft заявляют, что пользователи никогда не будут вынуждены хранить всю информацию — электронную почту, документы, аудио/видео, рисунки, электронные таблицы и тому подобное — в одной гигантской базе данных. В силу этого корпорация разрабатывает технологию, которая даст пользователю возможность в рамках одного запроса без усилий обращаться к множеству гетерогенных хранилищ данных.
Проект Unified Data корпорации Microsoft, по словам директора Microsoft SQL Server Стена Соренсена, включает в себя три этапа. На первом этапе будет подготовлена схема на основе XML, в которой определены типы данных. Затем она разработает методы для связи различных типов данных друг с другом и, наконец, создаст единый механизм обработки запросов для распределенных баз данных: «Предположим, к примеру, мне необходим документ со ссылкой на Microsoft и в процессе обработки этого документа выясняется, что в другом месте существует файл, в котором есть ссылка на Microsoft».
Данная технология должна быть интегрирована в SQL Server в ближайшие полтора года. Кроме того, впоследствии она будет добавлена в другие продукты Microsoft.
Представители Oracle подтвердили, что их клиенты все чаще и чаще создают хранилища данных, отличающиеся большими размерами и сложностью и распределенные по множеству офисов. Компания сообщила, что ее продукты в будущем не только выполнят такого рода задания, но и сделают это превосходно. «В ближайшей паре версий мы реализуем полностью автономные базы данных», — подчеркнул Роберт Шимп, вице-президент корпорации Oracle по маркетингу баз данных.
Кроме того, Oracle стремится поддержать совместную работу специалистов различных компаний, оперирующих множеством разных типов информации. «Сейчас отсутствует базовая инфраструктура, которая могла бы управлять всеми этими разнообразными типами данных, — заметил Шимп. — Нам необходимо иметь возможность связать все эти кластеризованные базы данных по всему земному шару в единое, унифицированное представление для конкретного пользователя».
Оптимизация запросов путем обучения
|
| Оптимизатор запросов Leo корпорации IBM наблюдает за ходом выполнения запросов и использует полученные сведения для оптимизации этого процесса по мере получения знаний о взаимоотношениях в данных и потребностях пользователей |