

«Хотелось бы узнать побольше о разработках корпоративных (закрытых) поисковых систем» — один из откликов на статью «Кто ищет?» (http://www.osp.ru/cw/ 1999/44/27.htm), посвященную поисковым системам. Именно с него, и началась работа над предлагаемым материалом.
 |
Вначале мы предполагали сравнить поисковые системы для корпоративного использования, благо их достаточно, и свободно распространяемых, и коммерческих. Однако более эффективным решением для компании является не просто поисковая система на внутреннем Web-сервере, а правильно построенная информационная система. Корпоративный поисковик — лишь попытка залатать дыру в плохо организованной системе работы с информацией. Поэтому целесообразнее обсудить принципы создания такой информационной системы, в которую можно органично интегрировать любую поисковую систему.
Подключившись к Сети, компания получает в свое распоряжение огромное количество информации, но часто не знает, что с ней делать. В то же время условия ведения бизнеса меняются так стремительно, что если вовремя не заметить каких-либо опасностей или преимуществ, то можно оказаться аутсайдером. В Internet информация, необходимая для успешного функционирования бизнеса, есть. Ее нужно только вовремя заметить и обработать. К сожалению, переработка больших объемов неструктурированных данных, хранящихся в Internet, — задача весьма ресурсоемкая. Данные надо не только вовремя найти, получить и отсортировать, но и успеть адекватно на них отреагировать. Постараемся показать, какие этапы поиска, обработки и сохранения информации проходит компания и как при этом должна быть организована ее информационная система.
Концепция
Можно выделить два типа данных: требующие немедленного реагирования и расчитанные на длительное использование. Характерной особенностью документов первого типа, которые мы в дальнейшем будем называть новостями, является то, что они быстро стареют — теряют актуальность и ценность для компании. Получив новость, в компании должны быстро оценить, насколько информация полезна, принять решение по ней и выполнить определенные действия. Для новостей можно указать время, после которого документ теряет ценность. Примерами документов, на которые нужно реагировать немедленно, являются сообщения о действиях конкурентов, о новых клиентах, политических или экономических событиях и др.
Хотя сама новость через некоторое время теряет свою актуальность, документы, подготовленные компанией при обработке новости, могут быть использованы в дальнейшем и поэтому относятся уже к другому типу — документам длительного хранения, или сведениям. Они обычно хранятся в архивах или библиотечных системах, что позволяет быстро находить нужную информацию. К сведениям относятся нормативные документы, различные регламенты, уставы, иная официальная и медленно меняющаяся информация. Впрочем, подборки новостей, классифицированных по какому-нибудь признаку, или аналитические отчеты также можно отнести к сведениям.
Естественно, для каждого из перечисленных типов информации нужна своя собственная система обработки. Кроме того, все их нужно получить, отсортировать и провести предварительную автоматическую обработку. Таким образом, в информационной системе любого предприятия можно выделить три компонента: сбор информации, быстрая обработка новостей и эффективное накопление сведений (см. схему «Структура информационной системы предприятия»). Каждый из них выполняет свои функции и имеет характерные особенности.
Сбор информации
Да, компания может получить огромное количество информации, но ее нужно вовремя найти и сделать доступной для сотрудников. Причем важно не только найти важные данные, но и передать именно тем, кто в них заинтересован. Желательно, чтобы информации было не очень много, поскольку в большом ее потоке можно пропустить нечто важное. Поэтому следует сделать систему сбора данных как можно более интеллектуальной. Для этого можно использовать различные методы автоматической обработки поступающего материала. Сформулируем несколько правил работы с информацией на этапе ее получения.
«Разделяй и властвуй». Входящий информационный поток необходимо структурировать. Его следует разделить по определенному признаку, например по отправителю или получателю. Механизм дальнейшей обработки документа может меняться в зависимости от параметров поступающей информации. Например, новость от агентства технических новостей направляется в технический отдел, а информация из госорганов — руководству. Иначе говоря, можно автоматически разделять поступающую информацию на тематические потоки еще до передачи ее во внутрикорпоративную сеть.
Агентство «Росбизнесконсалтинг» распределяет информационные потоки как по отправителю, так и по получателю. Компания сформировала входящие потоки так, чтобы документы, поступающие от разных ее партнеров, направлялись в разные отделы. В результате сотрудники агентства, специализируясь каждый на своем источнике информации, эффективно обрабатывают поступающий поток данных. Можно разделить их по получателю. Для этого компания должна завести несколько адресов электронной почты, каждый из которых соответствует определенному виду деятельности или отделу.
«Убрать все лишнее». Из входящего потока нужно исключить все лишнее — повторы и материалы, не соответствующие теме. Сейчас разрабатываются автоматические алгоритмы для удаления лишней информации. При исключении повторов нужно сделать так, чтобы автоматы умели преобразовывать информацию разных типов в единый стандарт и могли исключать документы, которые отличаются незначительно, например, по электронному адресу получателя или отправителя. Следует отметить, что при предварительном разделении входящего потока информации можно организовать автоматическое исключение документов, которые явно не соответствуют теме с помощью простых правил. В частности, это позволяет избавиться от «спама». Можно использовать и более сложные методы автоматического анализа, например построенные на основе поисковых технологий.
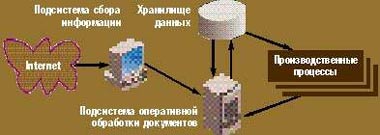 |
| Структура информационной системы предприятия |
«Не ждать милости от природы». Первоначальный сбор информации может быть не только пассивным, как, скажем, работа с электронной почтой. Компания имеет возможность активно искать новые данные в Web. Примером системы, основанной на поисковых агентах, является сервер Integrum Techno. Еще один способ получения информации об обновлениях Web-документов предоставляет поисковая система Яndex, которая предлагает подписаться на определенный запрос. Поисковая машина будет автоматически присылать новые документы, найденные при очередном сканировании Internet и соответствующие запросу.
Также есть технология контроля изменений информации на Web-сервере, которая, например, реализована в программе «ДИСКО Наблюдатель». Это приложение в определенные моменты запрашивает наблюдаемый ресурс и определяет, насколько он изменился. Таким образом, можно оперативно контролировать изменения содержания Web и передавать их в систему для дальнейшей обработки. Если система фильтрации хорошо настроена, она не пропустит лишних документов, сгенерированных на этапе автоматического поиска новостей.
Эти в общем-то нехитрые методы позволяют отбросить все лишнее и автоматически структурировать поступающий поток. Во многих компаниях подобные подходы уже частично реализованы, но важно понимать, насколько они адекватны поставленной задаче и не искажают ли информационный поток.
Групповая работа
После того как документ прошел первичную обработку и попал в информационную систему, нужно решить, что делать с ним дальше. Новости надо обрабатывать очень быстро, а сведения — тщательно. Часто от правильной классификации документов зависит эффективность их дальнейшего использования. Поэтому дальнейшую судьбу документа должен определять человек, причем достаточно квалифицированный.
Для начала рассмотрим работу с новостями. Именно новостями, как правило, и инициируются бизнес-процессы. В ответ на тендерную заявку начинается процесс подготовки проекта; агентство, получив новость, ее публикует; за поступлением заказа следует продажа товара. Таким образом, правильная и своевременная обработка новостей важна для деятельности предприятия.
Интенсивность поступления новостей может меняться, но обработать их нужно в оговоренное время. Поэтому модель работы с такой информацией не предполагает полноценного анализа документов и выделения метаданных — для этого нужны определенные ресурсы и время. Однако в процессе подготовки материалов для производственного цикла часто необходимы накопленные компанией сведения: типовые решения, цены на товар, аналитические обзоры рынка и многое другое. Эти документы должны быть хорошо структурированы и легко доступны.
Обсудим модель обработки новостей (см. рис. «Структура для работы с новостями»). Автоматически можно обработать только небольшую и хорошо формализованную новость. Например, запрос на получение товара, сгенерированный Internet-магазином. Большинство же новостей приходится обрабатывать вручную. После прохода документа через систему первоначального сбора информации он, как правило, попадает к руководителю, который может быстро определить его ценность. Решив принять документ в производство, он определяет его дальнейшую судьбу. На этом этапе перед сотрудниками ставится определенная задача.
К этому времени должны быть подготовлены все документы, необходимые для успешного выполнения выбранного производственного цикла. Подготовка именно этих документов и является целью системы обработки новостей. Характерными особенностями такой системы являются жесткие временные рамки, быстрая экспертная оценка документа, объединение в группу тех специалистов, которые будут обрабатывать документ, передача им документа на более глубокое изучение и принятие окончательного решения.
Для реализации системы обработки новостей можно использовать ПО для групповой работы. Например, на базе Lotus Notes такую систему разрабатывают в компании «Интертраст». Можно использовать и альтернативный подход: язык разметки XML позволяет построить систему из разрозненных компонентов на основе Internet-технологий. Поступающие документы снабжаются соответствующим XML-описанием и помещаются на внутренний сервер компании, откуда они могут быть получены сотрудниками и преобразованы в необходимый формат.
Системы, основанные на обоих подходах, легко интегрируются с производственными системами и архивными приложениями. Уже есть необходимые приложения для публикации документов, организации поиска по ним и работы с хранилищами сведений. Основанная на традиционных средствах групповой работы система может выполнять те же функции; она является интегрированной, но менее гибкой. XML позволяет использовать программное обеспечение различных производителей, но всю систему придется собирать из разрозненных элементов и настраивать. Можно найти свободно распространяемые компоненты для построения XML-системы, но для того, чтобы заставить их работать вместе, придется потратить определенные ресурсы и время. Решение же на основе средств групповой работы уже включает все необходимые элементы, но и стоит дороже.
Характерным примером компании, которой приходится обрабатывать большой поток новостей, является информационное агентство. Для большинства же предприятий поток краткосрочных документов незначителен и поэтому не требует больших ресурсов на свое поддержание. На предприятии обычно не бывает большого количества короткоживущих документов, и, вероятно, такая ситуация сложилась только потому, что их руководство не осознало, как можно от них получать реальные деньги. Тот, кто первым начнет быстро и адекватно реагировать на новости, получит огромное преимущество перед конкурентами.
Накопление сведений
Сведения — основной капитал компании. Сведения нужно хранить так, чтобы ими можно было быстро и эффективно воспользоваться. Поэтому подсистема управления сведениями является одним из основных элементов информационной системы компании. Важная особенность сведений в том, что их тяжело создать, но легко использовать. То есть ресурсы, затраченные на создание новых сведений, должны окупаться при последующих обращениях к ним. Если таких обращений будет много, то экономия средств и времени на каждое обращение приведет к значительной экономии ресурсов и времени. Чтобы превратить обычный документ в сведения, нужно снабдить его значительным количеством дополнительной информации, которую в дальнейшем можно будет использовать для быстрого доступа к нему.
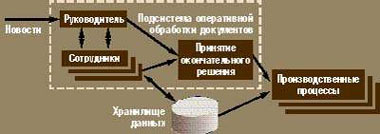 |
| Структура для работы с новостями |
Фактически работа со сведениями разделяется на две фазы — подготовка документа и последующее его использование. На начальном этапе тратятся значительные ресурсы для получения как можно более детального описания документа. В процессе обработки информации появляются дополнительные метаданные, которые позволяют в дальнейшем легко искать и обрабатывать сведения. Здесь устанавливаются связи между различными документами и их частями, которые в дальнейшем можно будет использовать для эффективного поиска нужной информации. Автоматизированных систем для качественного выделения метаданных практически нет, поэтому эту часть работы, как правило, приходится выполнять вручную. Впрочем, для этого не обязательно иметь высокопрофессиональный персонал. Как только документ снабжен большим количеством метаданных, его обработку и поиск можно эффективно автоматизировать.
Подсистему управления сведениями обычно используют для анализа накопленных сведений — бизнес-планирования, маркетинговых исследований и др. Ее также можно применять для библиотечных систем или порталов. Хотя отдельный пользователь не анализирует всех данных, а запрашивает что-нибудь одно, заказчиков так много, что система просто захлебнется, если будет тратить много времени на выдачу результатов. Таким образом, область применения системы управления сведениями достаточно широка.
На стыке подсистем обработки новостей и управления сведениями можно предусмотреть систему унифицированного доступа к обоим типам информации. Единый интерфейс позволит легко получать информацию как о новых, так и о накопленных данных. С его помощью также создается тематическая подборка. Она, как правило, готовится долго, уточняется и обрабатывается, а после завершения работы ее можно присоединить к документу любого типа. Это может быть, например, список литературы или же подборка материалов для подготовки аналитического отчета.
Одной из наиболее удобных технологий хранения метаданных является язык XML, очень хорошо подходящий для создания подсистем управления сведениями.
Вадим Федоров из компании «Интертраст», разработчик системы Knowledge Pump, реализующей описанную модель работы с документами, признается, что хочет переделать свою систему под XML: «Есть много зрелых стандартов для построения подобной системы. Прежде всего, это Resource Definition Framework, метаданные Web».
Впрочем, можно реализовывать похожую систему и на предшественнике XML — языке SGML. Для него уже разработано большое количество различных приложений — текстовых редакторов, браузеров, поисковых машин и других элементов, которые позволяют в кратчайшие сроки собрать систему из отдельных компонентов.
Вполголоса о бизнес-интеллекте
Мы намеренно не употребляли выражение «бизнес-интеллект» (Business Intelligence), фактически говоря именно об этом. Этот термин еще не получил точного определения. Он частично обозначает и многомерные базы данных, и сложные системы поиска, в том числе и с помощью интеллектуальных агентов, и экспертные системы, и многое другое. В понятие Business Intelligence объединяются фрагменты технологий, появившихся в разных сегментах рынка, которые в свою очередь сами складываются в самостоятельный рынок. Впрочем, сейчас этот рынок лишь складывается.