
Parallel Data Server продолжает работать даже при сбоях сети
Однако последняя ее версия в большей степени ориентирована все же на Web-сайты, на которых хранятся большие объемы информации.
В СУБД Clustra Parallel Data Server 3.0 включены механизмы, которые обеспечивают ее нормальное функционирование даже в случае отказов компьютеров и сбоев сети. Программное обеспечение создает копии данных, разбивает оригинал и полученные копии на фрагменты и распределяет их между разными процессорами. Каждому набору данных выделяется свой объем оперативной памяти и свое дисковое пространство. Если на каком-то из процессоров происходит сбой, СУБД автоматически перенаправляет запросы на другой.
Подобная «ничего не разделяющая» архитектура означает, что каждый процессор отвечает лишь за небольшую порцию данных, которую, впрочем, можно восстановить при сбое этого процессора.
На первых порах программное обеспечение Clustra использовалось поставщиками телекоммуникационных услуг для создания высокопроизводительных каталогов с большими объемами информации. Однако разработчики Clustra полагают, что наибольший эффект их программный продукт может дать на тех Web-сайтах, где системные ошибки приводят к снижению уровня удовлетворенности пользователей и их оттоку, а следовательно, к снижению доходов поставщика услуг.
«Сегодня построение отказоустойчивого Web-сайта требует очень больших затрат, — считает старший вице-президент Clustra Гэри Эберсоул. — Решая эту задачу, компании, как правило, тщательно подбирают отдельные фрагменты мозаики — компьютеры в определенных конфигурациях, конкретные версии баз данных, средства кластеризации и программное обеспечение, предназначенное для управления такими системами».
По словам Эберсоула, сервер Clustra Parallel Data Server проектировался с учетом того, что он будет простаивать (согласно плану или в связи с возникновением незапланированных обстоятельств) не более 2 минут в год.
Clustra предоставляет своим заказчикам необходимые гарантии. Если в течение месяца был зарегистрирован отказ сервера, пользователь автоматически освобождается от внесения платы за аренду ПО за этот месяц.
Другие разработчики баз данных отдают предпочтение иным подходам. К примеру, Informix предлагает полностью автономную базу данных, которая обеспечивает весьма высокий уровень готовности приложений. Однако ни один из конкурентов Clustra не решается дать гарантию поддержания надежности на уровне 99,999%.
ПО Clustra устанавливается на недорогих компьютерах с процессорами Intel, которые могут монтироваться в стойку. В настоящее время существуют версии ПО для операционных систем Linux, Windows NT 4.0 и FreeBSD.
«При используемом нами подходе операционная система вовсе не обязательно должна обеспечивать масштабируемость, — подчеркнул Эберсоул. — За нее это сделаем мы».
К концу года предполагается реализовать функции поддержки тиражирования данных между серверами Clustra на различных узлах. Уже в июне программисты смогут воспользоваться языком Java для написания хранимых процедур, которые фактически представляют собой небольшие приложения, размещающиеся в самой базе данных.
Приобрести ПО Clustra можно уже сейчас. Стартовая цена пакета составляет 75 тыс. долл. за лицензию для системы, которая состоит из четырех узлов на базе процессоров Intel. В перспективе разработчики намерены перенести свое программное обеспечение на компьютеры с RISC-процессорами, функционирующими под управлением ОС Sun Solaris или HP-UX.
Архитектура обеспечения надежности сервера Clustra
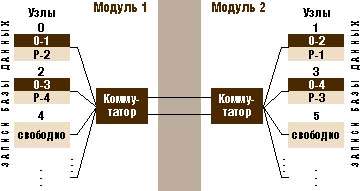
В пределах узла база данных распределена по серверным платформам, которые поддерживаются на физически независимых модулях. Клиентские компьютеры и серверы базы данных объединены по принципу кластера — через коммутаторы, которые, в свою очередь, соединены друг с другом. Что же касается записей базы данных, каждая имеет свою резервную копию, а оригинал и полученные копии разбиты на фрагменты и распределены для хранения в независимых участках памяти на основании алгоритма хэширования. На рисунке основные записи обозначены как «О», резервные — как «Р». Каждому набору данных выделяется свой объем оперативной памяти и свое дисковое пространство.
 |
Фундамент и коммуникации
Сервер Clustra Parallel Data Server основан на применении баз данных с параллельной архитектурой, в которой данные распределяются и тиражируются по кластеру серверов. Этот механизм действует в сочетании с принадлежащей Clustra технологией распределения данных и исправления ошибок в реальном времени, благодаря чему преодоление последствий сбоев происходит за доли секунды. Модернизацию аппаратного и программного обеспечения можно проводить во время работы Clustra Parallel Data Server.
Та же схема, по которой производится распределение данных, применена и к процессорной логике. Все узлы кластера принадлежат одному уровню, и каждый имеет такую конфигурацию, которая позволяет ему принять на себя управление обработкой транзакций и данными всей системы. Таким образом устраняются все узкие места и обеспечивается возможность балансировки нагрузки на базе клиента.
Типичная информационная система на базе Clustra состоит из двух модулей, соединенных избыточной сетью связи. Как правило, модули имеют одинаковое число узлов. Узлы и клиентские системы соединены между собой высокопроизводительным коммутатором, который осуществляет и связь с другим модулем. Для дополнительной гарантии высокой готовности модули располагаются в различных зданиях, дабы снизить вероятность сбоя из-за внешних причин. На каждом модуле размещен полный набор данных приложений. Защита от сбоев предусмотрена как на уровне модулей, так и на уровне узлов. Все узлы обеспечивают равный уровень обслуживания клиентских приложений.
Таблицы базы данных разбиваются по строкам на фрагменты равного объема при помощи технологии хэширования. Каждый фрагмент данных имеет две копии — основную и резервную.
Масштабируемость кластера достигается путем динамического распределения базы данных на новые узлы, которые добавляются непосредственно в процессе работы Clustra Parallel Data Server. Это перераспределение происходит абсолютно прозрачно и выполняется как распараллеленная и не вызывающая блокировок операция, которая не прерывает обработки пользовательских приложений. Можно просто добавлять новые серверы в качестве узлов в существующую систему.
— Татьяна Грачева, Computerworld Россия