
Наконец опубликовано описаниесистемы команд архитектуры IA-64
Свершилось! Intel и Hewlett-Packard, долгое время лишь по крохам выдававшие информацию о будущем микропроцессоре Merced, прервали обет молчания и представили компьютерной общественности объемистый документ IA-64 Application Instruction Set Architecture Guide, описывающий архитектуру и систему команд IA-64 с точки зрения прикладного программиста. Хотя это пока лишь улыбка Чеширского кота (самого кота, то есть Merсed, пока еще официально не существует), в ближайшие несколько месяцев можно ожидать его явление народу. Правда, это будет, вероятно, «пробный» экземпляр.
Хотя информация о системе команд ориентирована на профессионалов в достаточно узкой области, потенциальное место IA-64, претендующей на ниспровержение микропроцессорной RISC-архитектуры и монополию на рынке, сравнимую с монополией мэйнфреймов IBM в 70-е, способно вызвать интерес более широкого круга читателей. Кроме того, между строчками этого документа и пресс-релизов Intel и HP можно выудить определенные данные о микроархитектуре Merced, которая по-прежнему остается тайной за семью печатями.
 |
Осознавая невозможность осветить документ объемом с приличную книгу в рамках газетной статьи, вынужден ограничиться только некоторыми аспектами. Что касается сравнения с архитектурой других микропроцессоров, то сопоставление с Intel IA-32 и HP PA-RISC нам представляется нецелесообразным: в основных элементах IA-64 можно уловить лишь «тонкие запахи» этих архитектур. Хотя двоичная совместимость снизу вверх и обеспечивается (с PA-RISC — путем динамической трансляции объектных кодов), по сравнению с IA-32 в IA-64, как и следовало ожидать, переделано почти все. Этот решительный шаг был необходим, чтобы сбросить сдерживающие развитие «оковы» IA-32. Представители Intel сравнили этот переход с заменой 80286 на 80386, но, с моей точки зрения, изменения в IA-64 еще масштабнее. Единственное сопоставление, которым мы будем иногда пользоваться, — сравнение с отечественной разработкой процессора Elbrus E2K, имеющего во многом сходную с IA-64 архитектуру. Подробная статья о микроархитектуре E2K выйдет в июньском номере журнала «Открытые системы».
Регистры, регистры, регистры!
В IA-64, некоторые элементы которой близки к архитектуре VLIW (Very Large Instruction Word — сверхбольшое командное слово), предусмотрено множество разных регистров, в данном случае абсолютно необходимых. (Известно, что регистров программистам всегда не хватает: их, как и денег, никогда не бывает много.)
В IA-64 представлено 128 целочисленных регистров GR0-GR127, причем в режиме IA-32 его целочисленные регистры и регистры селекторов и описателей сегментов находятся в GR8-GR31. GR0-GR31 (GR0 содержит 0) — статические регистры, доступные для всех процедур. GR32-GR127 относятся к так называемому стекируемому поднабору регистров. Он локален для любой процедуры, и его реально доступный для процедуры размер может изменяться от 0 до 96, что задается командой alloc. Реально используемая процедурой часть стека GR является «окном» (register stack frame), через которое эти GR, собственно, и доступны.
Часть стекируемых регистров может «программно переименовываться» для ускорения работы циклов аналогично аппаратному переименованию регистров в ряде процессоров, например, SGI R10000. В IA-64 такое переименование называется вращением регистров, поскольку стек регистров циклически замкнут.
Регистров с плавающей запятой тоже 128: FR0-FR127, из них FR0-FR31 — cтатические (FR0=0.0, FR1=1.0), FR32-FR127 — вращаемые, то есть они могут программно переименовываться для ускорения циклов. В режиме IA-32 в FR8-FR31 содержатся вещественные и мультимедийные регистры этой архитектуры. Регистры FR являются 82-разрядными.
 |
Вместо одного кода условия, типичного для сегодняшних микропроцессоров, в IA-64 имеются 64 предикатных регистра PR длиной 1 разряд. Каждый предикат создается вместе со своим отрицанием, то есть фактически занимает 2 PR. Большинство команд IA-64 могут быть выполнены либо нет в зависимости от значения предикатного регистра, кодируемого в команде. PR0-PR15 — это статические регистры (PR0=1), а PR16-PR63 — вращаемые, и могут программно переименовываться. Применение PR позволяет избегать «нехороших» с точки зрения производительности команд условного перехода, так как вместо этого обычные команды выполняются «под предикатом». Иначе говоря, конструкция
if (a > b) then c=c+1 else d=d+1
«оттранслируется» в
pT,pF = compare (a,b); if (pT) c=c+1; if (pF) d=d+1;
Для неявного задания адреса перехода в IA-64 применяются регистры перехода BR0-BR7 длиной 64 разряда. Счетчик команд IP указывает на адрес «связки» (bundle), содержащей выполняемую команду. В IA-64 имеются также специальные прикладные регистры AR0-AR127, которые служат для разных целей: AR65 является 64-разрядным счетчиком циклов LC, а AR66 — 6-разрядным счетчиком «эпилога»; AR40 является словом состояния для расчетов с плавающей запятой, а AR44 — интервальным таймером, и т. д.
Выделение в IA-64 статических регистров GR и FR способствует в том числе и достижению совместимости с IA-32 и PA-RISC. Любопытно, что в отечественном микропроцессоре E2K имеется 256 64-разрядных регистров, которые могут выделяться как под целые, так и под вещественные числа, и 32 предикатных регистра. В E2K также предусмотрено окно регистров, сменяемое при вызове процедур, и вращение регистров для оптимизации циклов с постоянным шагом.
EPICурейцы, вперед!
EPIC (Explicitly Parallel Instruction Computing — явный параллелизм на уровне команд) — термин, введенный в IA-64. Данная концепция восходит к VLIW; близкие архитектурные решения применялись в отечественной суперЭВМ «Эльбрус-3». Введение параллелизма на уровень команды, возможное ввиду большого числа ресурсов процессора, в том числе регистров, в сочетании со спекулятивными и предикативными вычислениями являются основными преимуществами IA-64, позволяющими добиться высокой производительности.
По три обычных команды, имеющих длину 41 разрядов, объединяются в связки длиной 128 разрядов (см. рис.). Пять разрядов отводятся под так называемую маску (template), которые указывают на взаимозависимости команд в связке, препятствующие их одновременному выполнению, и на то, какие типы команд в каких разрядах связки находятся.
Всего имеется шесть типов команд (см. табл.), которым соответствуют типы исполнительных устройств микропроцессора, способные выполнить эти команды. Из описания не следует, что разные связки также не могут выполняться параллельно. Как бы то ни было, задача распараллеливания возлагается на компилятор, который должен генерировать «эффективные» связки (в суперскалярных микропроцессорах, напротив, распараллеливание выполнения осуществляет аппаратура). Разработать такой компилятор крайне сложно, и некоторые типовые математические алгоритмы для достижения максимальной производительности, как и ранее, придется, вероятно, писать на Ассемблере. Программистов, которые будут вручную сооружать связки во имя реализации идей EPIC, возможно, будут называть EPICурейцами.
Для сравнения укажем, что E2K применяет широкие команды, однако они имеют переменную длину — до 16 32-разрядных слогов. Типовые арифметические команды в IA-64 обычно трехадресные (типа add GR3=GR4, GR5), а в E2K — четырехадресные.
В IA-64 разнообразные команды сравнения устанавливают значения сразу двух PR. Команды загрузки регистров IA-64 бывают еще и в специальном спекулятивном виде. Имеются два типа команд спекулятивной загрузки. Компилятор может создавать коды, в которых будут спекулятивно загружаться данные одновременно для двух альтернатив в конструкции if-then-else. Предварительное выполнение этих команд до начала базовых блоков позволяет скрывать задержки при обращении в память. Вместе с возможностями спекулятивного выполнения двух ветвей конструкций if-then-else одновременно (вместо применения условных переходов), обеспечиваемыми применением предикатов, это сильно поднимает возможности спекулятивного выполнения команд в IA-64 по сравнению с современными суперскалярными микропроцессорами.
В IA-64 представлено несколько типов команд перехода, в том числе для вызова процедуры, перехода из режима IA-64 в IA-32, перехода по счетчику цикла и др. Для программно конвейеризованных циклов со счетчиком применяются регистры LC и EC.
В LC загружается число итераций минус 1, и содержимое этого регистра уменьшается на каждой итерации. Пока LC>0, в цикле используется вращение регистров. Когда LC=0, у цикла начинается эпилог, число стадий которого задается в ЕС. Необходимость в эпилоге цикла вызвана тем, что при исчерпании числа итераций цикла заполненный «программный конвейер» необходимо еще «протолкнуть» до конца (см. врезку). На каждой стадии EC уменьшается, пока не достигнет 1 — тогда цикл полностью завершается.
Хотя в IA-64 видно стремление упразднить обычные условные переходы, предусматриваются и возможности статического (компилятором) и динамического предсказания переходов. В IA-64 имеются также команды предварительной выборки в кэш и мультимедийные «параллельные» команды, команды пересылки данных между различными типами регистров и другие виды команд. Остановимся на работе с вещественными числами.
Поддерживаемые форматы чисел с плавающей запятой включают cтандарт IEEE754 (одинарная и двойная точность, а также 80-разрядный расширенный формат, используемый в x86). Кроме того, поддерживаются операции с 64-разрядными целыми со знаком и без знака, расположенными в регистрах FR. IA-64 вообще не предусматривает умножение 64-разрядных целых чисел в GR-регистрах, но можно воспользоваться умножением целых, расположенных в FR. В FR могут располагаться и пары 32-разрядных вещественных чисел, используемых в операциях с двумерными векторами по типу SIMD-расширения команд Pentium III.
В IA-64 появилась команда типа fma — «умножить-и-сложить», которая может давать два результата с плавающей запятой за такт. В своем пресс-релизе Intel указала на оценку пиковой производительности Merced в 6 GFLOPS. Эта оценка относится к тактовой частоте 1 ГГц. Если предположить, что исполнительные устройства выдают два результата за такт, то для 6 GFLOPS потребуется три таких устройства (Intel и HP пока не разглашают данные о числе исполнительных устройств Merced!). Отметим, что в E2K запланировано четыре таких устройства.
Сегодняшние микропроцессоры не смогли преодолеть рубежа 2 GFLOPS. Создатели Merced готовятся нанести решительный удар. RISC-процессоры, готовьтесь!
Михаил Кузьминский — старший научный сотрудник Центра компьютерного обеспечения Института химических исследований РАН. С ним можно связаться по телефону (095) 135-6388.Регистры - программное переименование
Типичным примером, подтверждающим эффективность программного переименования регистров, является известная схема оптимизации при компиляции, называемая software pipelining. При этом каждая итерация цикла является аналогом стадии аппаратного конвейера исполнительного устройства (предполагается, что параллельно могут исполняться сразу несколько команд из цикла). В качестве примера приведем иллюстрацию части цикла, покомпонентно умножающего массив A на массив B (результат — в массиве С, все массивы — 64-разрядные, с плавающей запятой). Если этот цикл «раскрутить», то на первых четырех итерациях для достижения параллельности их выполнения мы должны иметь следующие фрагменты цикла:
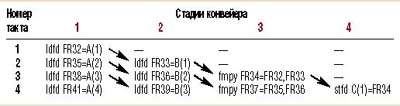 |
Здесь представлены по две команды загрузки регистров, их умножение и запись результата в память, причем для простоты мы опускаем детали адресации к элементам массива. Предположим для простоты, что все команды выполняются за один такт. Тогда развертка конвейеризованного цикла по времени будет выглядеть следующим образом:
| ИТЕРАЦИЯ 1 | ИТЕРАЦИЯ 2 | ИТЕРАЦИЯ 3 | ИТЕРАЦИЯ 4 |
| ldfd FR32=A(1) | ldfd FR32=A(2) | ldfd FR32=A(3) | ldfd FR32=A(4) |
| ldfd FR33=B(1) | ldfd FR32=B(2) | ldfd FR32=B(3) | ldfd FR32=B(4) |
| fmpy FR34=FR32, FR33 | FR37=FR35, FR36 | FR40=FR38, FR39 | FR43=FR41, FR42 |
| stfd C(1)=FR34 | stfd C(2)=FR37 | stfd C(3)=FR40 | stfd C(4)=FR43 |
Видно, что к четвертой стадии программный конвейер заполняется. Поскольку мы используем разные FR в разных итерациях цикла, эти стадии конвейера могут исполняться одновременно. Чтобы автоматизировать выделение FR из стека регистров, компилятор должен их автоматически переименовывать (заменять FR32 на FR35, FR33 — на FR36 и т. д.). Вместо этого IA-64 имеет базу вращаемых регистров (rrb), которая сдвигает номера регистров на заданное ей приращение (в данном случае — на 3).
Вращение регистров применяется и для ускорения вызова процедур/возврата (поскольку накладные расходы на сохранение/восстановление большого числа регистров были бы велики). Для этого используется маркер текущего окна регистров CFM, в котором описывается состояние стека GR и других вращаемых регистров.
Каждая процедура работает со своим окном стека GR, которое включает так называемые локальную и выходную области. При вызове процедуры, то есть выполнении команды перехода соответствующего типа, размер выходной области процедуры-«потомка» — такой же, как у выходной области «предка», и перекрывается с ней, а размер локальной области потомка равен 0. Число регистров локальной области потомок может установить командой alloc.
При вызове процедуры CFM автоматически копируется в поле предыдущего окна регистров PFM, расположенном в одном из прикладных регистров. Стекируемые регистры автоматически переименовываются. Значения регистров выходной области предка «видны» для потомка, что позволяет передавать параметры и возвращать результаты через эти регистры. При возврате CFM восстанавливается из PFM, и происходит «обратное переименование» регистров. Статические же регистры приходится сохранять/восстанавливать отдельно.