
Поэтому с точки зрения архитектуры наибольший интерес, конечно же, представляют серверы среднего и старшего классов с числом процессоров больше восьми. Среди компаний, заявивших о выпуске подобных серверов, Data General (см. Computerworld Россия, 1998, № 31) и Sequent, которые предлагают системы с архитектурой ccNUMA.
Из появившейся в отечественной печати информации можно было бы понять, что по этому пути пошла и Unisys, объявившая о новой архитектуре CMP (Cellular MultiProcessing) для своих будущих серверов на базе процессоров Intel. Однако анализ технической документации показал, что дело обстоит иначе: СMP - это перестраиваемая симметрично-многопроцессорная (SMP) архитектура, которая позволяет комбинировать SMP и кластерные технологии.
Из материалов Unisys видно, что разработчики внимательно изучили особенности архитектуры ccNUMA, но решили пойти своим путем. CMP - это никак не ccNUMA, поскольку в основе CMP лежит модель однородного поля оперативной памяти; CMP - это новая архитектура, собственная разработка Unisys. Что же именно предложила Unisys?
Описание архитектуры CMP
Строительные блоки в CMP - это процессорные элементы, называемые Unisys sub-pods (по-русски это, вероятно, что-то типа «подотсеков»). По всей видимости, CMP проектировалась в расчете на Merced, однако задержки с выпуском этого процессора и появление Xeon, призванного сменить Pentium Pro, привели к тому, что первые версии CMP-серверов будут использовать именно Xeon. Одновременно Unisys позаботилась о возможном сосуществовании процессоров Xeon и Merced в рамках одной CMP-системы. Пользователей уведомили, что они могут приобрести СMP-сервер c Xeon, а затем модернизировать конфигурацию, добавив процессоры Merced, после того как они появятся. Это в свою очередь означает сохранение инвестиций потребителя. Кроме того, предусматривается возможность модернизации с заменой Xeon на Merced, что может выполняться непосредственно у заказчика.
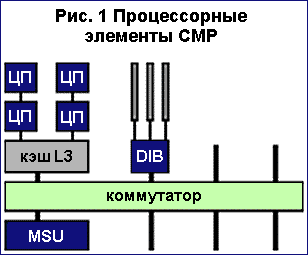
Интересно, что Unisys не использовала полностью возможности «многопроцессорной» шины Intel: на одну шину приходится всего по два процессора Xeon. Очевидно, это сделано с целью уменьшения вероятности потенциальных конфликтов на шине, которые могут возникнуть из-за недостаточной ее пропускной способности при большем числе процессоров, разделяющих шину. А всего в процессорном элементе имеется 4 процессора Xeon. Кроме имеющегося у каждого микропроцессора стандартного кэша второго уровня, соединенного выделенной шиной с Xeon, в архитектуру процессорного элемента Unisys включила разделяемый между 4 процессорами кэш третьего уровня. Его емкость составляет 16 Мбайт (в следующем поколении процессоров Intel - вероятно, в Merced - она возрастет до 32 Мбайт). Очевидно, что применение в CMP-серверах кэша третьего уровня, имеющего большую емкость, способно существенно поднять производительность, особенно в случае бизнес-приложений, для которых характерен интенсивный обмен данными с оперативной памятью. Что касается самой оперативной памяти, то она наращивается блоками по 128 Мбайт до максимальной емкости в 8 Гбайт на одно устройство управления оперативной памяти.
Данное устройство, подсистема ввода/вывода и процессоры в процессорном элементе связаны между собой при помощи коммутатора, а не посредством более традиционной системной шины. Технология коммутации, пришедшая из мира мэйнфреймов, уже давно применяется и в SMP-серверах как типичный архитектурный прием. Среди первых SMP-серверов, оснащенных коммутатором вместо шины, можно упомянуть Convex SPP1000 (ныне HP); все последующие поколения этих серверов также используют коммутатор. Преимуществом этой архитектуры перед шиной является устранение конфликтов на системной шине и соответственно отсутствие «перегрузок». В СМР-архитектуре коммутатор процессорного элемента является не блокирующимся и имеет 4 входа и 4 выхода.
Подсистема ввода/вывода в СМР основывается на стандартных шинах PCI. Однако для повышения эффективности путем использования режима DMA три шины PCI, входящие в состав процессорного элемента, связаны с коммутатором через специальный мост ввода/вывода DIB (Direct I/O Bridge). Каждая PCI-шина имеет по 4 PCI-слота, то есть всего 12 cлотов на элемент.
Сам по себе процессорный элемент, таким образом, представляет собой «почти готовую» SMP-систему, использующую коммутатор вместо системной шины. В этом в общем-то нет ничего особенно оригинального. Подобные SMP-элементы имеются как в компьютерах ccNUMA-архитектуры (скажем, на платах SHV в серверах AV2x000 от Data General), так и в МРР-системах с распределенной оперативной памятью, построенных на базе SMP-блоков. Основными преимуществами архитектуры процессорных элементов CMP по сравнению, скажем, с SHV являются, во-первых, «разгрузка» многопроцессорной шины процессора Xeon и, во-вторых, применение трехуровневой кэш-памяти.
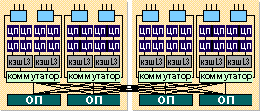
Основные отличия СМР, определяющие ее уникальность, обусловлены в первую очередь способом объединения процессорных элементов в СМР-сервере. Как мы увидим ниже, эту архитектурную особенность («межсоединение») можно было бы охарактеризовать как «наращиваемый коммутатор» (см. рис. 2). Похожую картинку архитектуры СMP приводит Unisys. Из данного рисунка ясно, что сервер СМР может включать до 4 коммутаторов и до 8 процессорных элементов, итого: до 32 процессоров Xeon (до 8 модулей кэша третьего уровня), до 32 Гбайт оперативной памяти и до 8 мостов ввода/вывода с суммарной пропускной способностью порядка 5 Гбайт/с. В этой схеме каждый модуль оперативной памяти имеет связь с любым коммутатором, обеспечивая однородное поле оперативной памяти.
Конечно, схема коммутации, обеспечивающая соединение всех «агентов» между собой, должна быть весьма дорога. Примененное в СМР «разделение» общего коммутатора в полностью укомплектованной 32-процессорной SMP-системе (здесь SMP - это не опечатка: то, что изображено на рис. 2, - это SMP-сервер!) на четыре отдельных коммутатора позволяет, очевидно, снизить цену серверов, имеющих меньшее число процессоров.
В симметричных системах с общей оперативной памятью, встает задача обеспечения когерентности кэшей. Для ее решения в СMP применяются развитые процедуры, основанные на так называемых директориях. Подобные процедуры показали свою эффективность в ccNUMA-системах SGI Origin 2000.
Очевидным преимуществом CMP перед ссNUMA является отсутствие дополнительных задержек при обращении к оперативной памяти. Однако ccNUMA потенциально способна обеспечить более высокий уровень масштабирования.
Под флагом кластеризации
Всего изложенного, пожалуй, было бы недостаточно, чтобы можно было говорить о CMP как о новой архитектурной парадигме. Однако разработчики Unisys заложили в CMP и другие уникальные особенности, обеспечивающие возможности статического и динамического парционирования (то есть разбиения) SMP-сервера, приводящие к преобразованию в кластер всей SMP-системы, в свою очередь построенный из SMP-серверов с числом процессоров, кратным 4. Мало того, и сам такой кластер является уникальным явлением в компьютерной индустрии: взаимодействие его узлов осуществляется... через общее поле оперативной памяти!
Изображенный на рис. 2 SMP-сервер в архитектуре CMP может быть реконфигурирован в восемь 4-процессорных SMP-систем, или в четыре 8-процессорные SMP-системы, или в иную комбинацию SMP-систем с числом процессоров, кратным 4. Подобное реконфигурирование компьютера с выделением отдельных разделов давно известно в мире мэйнфреймов. Среди Unix-серверов такая доменная организация доступна, например, в серверах Sun Ultra Enterprise 10000. Наиболее «слабым» аналогом этого в SMP-серверах является выделение «процессорных наборов», доступное, в частности, в версиях Unix для HP/Convex SPP и SGI Challenge/Power Challenge.
В отличие от этих средств выделение разделов-доменов в СМР предполагает возможность работы в каждом из них своей операционной системы. В CMP-серверах это могут быть вообще разные операционные системы - скажем, NT или SCO UnixWare или иная версия Unix. Особенностью СМР является то, что физически вся оперативная память этих разделов является общей. При этом в СМР возможно три типа разделения поля оперативной памяти между разделами: а) каждая операционная система использует исключительно собственную память; б) каждая ОС имеет свою память и образуется еще одна общая для разных ОС область памяти; в) каждая ОС имеет свою память и образуется несколько областей памяти, разделяемых некоторыми ОС.
Взаимодействие между отдельными SMP-узлами осуществляется через общие области оперативной памяти. Фактически последняя выступает как «коммуникационная среда» для обмена информацией между SMP-узлами кластера. Очевидными преимуществами такого обмена данными являются низкие задержки и высокая пропускная способность. Unisys работает над созданием стека телекоммуникационных протоколов, использующих общую оперативную память. Приложения, использующие интерфейс Winsock API, получат прямую выгоду от такого высокоскоростного «соединения» узлов. Unisys разрабатывает также технологию VIA (Virtual Interface Architecture) для межузлового кластерного обмена. Цель такого использования CMP-разделов - обеспечение работоспособности стандартного кластерного программного обеспечения, в том числе MSCS (Microsoft Cluster Server).
Одно из типичных направлений кластеризации - построение систем, обладающих высоким уровнем готовности. Unisys также предлагает подобные кластеры на базе СMP, в которых, в частности, благодаря дублированию основных компонентов архитектуры отсутствует «общая точка» для потенциального места сбоя. Ограниченные рамки данной статьи не позволяют рассказать здесь и о целом ряде особенностей CMP, способствующих повышению отказоустойчивости и доступности.
Специально для «почемучек»
Если бы я был И. Северяниным, то для подзаголовка этого завершающего кусочка статьи использовал бы слово «почемучник» - а так, боюсь, наш литредактор не пропустит. При обилии всяких howto, FAQ и проч. такое нововведение представляется мне весьма привлекательным. Суть этого раздела - попробовать дать свою версию ответов на ряд довольно естественных вопросов, начинающихся с «почему?» .
1) Почему СМР ориентированы на процессоры Xeon? Потому что Merced пока за горизонтом, а предыдущие версии Pentium II уступали по пропускной способности кэша второго уровня процессору Pentium Pro (даже 400-мегагерцевая версия Pentium II имеет более медленный кэш, чем Pentium Pro/200 МГц; в Xeon же кэш второго уровня работает на частоте процессора).
2) Почему Unisys разработала CMP, а не выбрала путь ccNUMA? Вероятно, из любви к кластерам. Unisys известна своими разработками в этой области (укажем, например, кластерные системы CTOS и BTOS). Кроме того, применение Windows NT для ccNUMA - та еще задачка.
3) А почему Unisys выбрала Windows NT как генеральное направление операционных систем для CMP? Cпросили бы чего попроще... Unisys активно работает с NT. По утверждению представителей компании, она первая, еще в 1997 году, анонсировала 10-процессорную систему на базе Windows NT (ПК-серверы Aquanta). Кроме того, Unisys не отказывается и от Unix. В любом случае, интересно посмотреть, как NT будет жить на 32-процессорном сервере.
Михаил Кузьминский - старший научный сотрудник Центра компьютерного обеспечения Института химических исследований РАН. С ним можно связаться по телефону (095) 135-6388.