

Адекватная оценка текущих тенденций и бизнес-ситуаций стала одним из главных факторов успеха больших и малых компаний. По мнению аналитиков Forrester Research, все большее значение получает информационная поддержка принятия решений не только на стратегическом, но и на операционном уровне. Так, в платежной системе следует оценивать риски непосредственно при обращении клиента. Поставщику услуг при подготовке персонифицированного предложения нужно анализировать историю взаимоотношений с клиентом. Телекоммуникационной компании для выявления недобросовестных абонентов требуется просматривать миллионы записей о звонках за неделю, месяц или даже год. А в Internet-торговле необходим анализ действий пользователей при доступе к сайтам Web-магазинов [1].
Требования новые — технологии старые
Хранилища данных появились в те времена, когда информационные системы создавались на базе централизованных вычислительных центров, использовавших мэйнфреймы. По мере «взросления» клиент-серверных платформ вслед за системами, предназначенными для организации баз данных, на них мигрировали и хранилища данных. Сегодня в инфраструктуре корпоративной информационной «фабрики» причудливым образом соединяются и сосуществуют компоненты, созданные разными производителями. Это операционные системы, системы управления базами данных, серверы, запоминающие устройства и сетевые соединения, с помощью которых все компоненты взаимодействуют между собой и с внешним миром.
Объем высокопроизводительных решений для организации хранилищ данных, базирующихся на продуктах разных компаний (таких, как IBM/Informix, Oracle, Microsoft, NCR/Teradata, Sun/Sybase) и насчитывающих до тысяч процессоров и дисков, достигает десятков и сотен терабайтов. При создании подобных систем приходится состыковывать и конфигурировать разнородное оборудование, проводить тонкую настройку операционных систем и СУБД, разрабатывать схемы, индексы, запросы, процедуры загрузки баз данных. Решения такого масштаба весьма дорогостоящи, требуют услуг внешних консультантов и долгосрочной поддержки со стороны поставщиков. С ростом объемов данных и увеличением числа пользователей приходится регулярно приобретать новое оборудование, обновлять программное обеспечение, расходовать значительные средства на повседневный мониторинг и поддержание работоспособности системы.
Отвечая ожиданиям пользователей из сегмента среднего и малого бизнеса, ведущие поставщики решений для хранилищ данных наряду с продуктами общего назначения разрабатывают специальные версии СУБД. Они выпускают и готовые «стартовые» решения для создания хранилищ данных — предварительно сконфигурированные комплекты той или иной степени полноты (IBM Balanced Configuration Unit и DB2 Integrated Cluster Environment, Oracle Real Application Cluster и Oracle Database Pack, Sun-Sybase iForce Solutions, Unisys Business Intelligence Solutions).
Однако, вне зависимости от степени «фабричной обкатки», в условиях лавинообразного роста объемов корпоративных хранилищ информации, потоков данных и сложности запросов такие решения (в том числе базирующиеся на новейших многопроцессорных кластерных конфигурациях и версиях программного обеспечения) не являются идеальными — именно в силу своей универсальности. Серверы, процессоры и диски оптимизированы для решения «любых» задач, от научных расчетов до обработки изображений. Операционные системы и СУБД нацелены прежде всего на оперативную обработку бизнес-транзакций: данные считываются с диска, передаются порциями в оперативную память и лишь затем обрабатываются процессором. В крупномасштабных задачах бизнес-анализа и поддержки принятия решений разделяемые многими процессорами память, запоминающие устройства, шины ввода-вывода и сетевые соединения перестают справляться с извлечением, фильтрацией, классификацией и обобщением миллионов и миллиардов записей, что обусловлено рядом принципиальных ограничений.
- Архитектура параллельных систем баз данных, создаваемых из компонентов общего назначения, предполагает перемещение больших объемов сведений от запоминающих устройств к процессорам и в обратном направлении.
- Основная причина медленной обработки сложных запросов — недостаточная пропускная способность тракта «диск — память — процессор».
- Необходимость интеграции и тонкой настройки оборудования и программных компонентов обусловливает исключительно высокие требования к профессиональной подготовке обслуживающего персонала и требует постоянной внешней поддержки. В связи с этим растет стоимость реализации, настройки, эксплуатации и развития системы.
- Чрезвычайно высокая стоимость хранилищ данных сдерживает полноценное применение средств бизнес-анализа в средних, а тем более мелких компаниях.
В поисках специализированного решения
Идея построения специализированной машины баз данных, предназначенной для высокоэффективного выполнения операций управления информацией, возникла в конце 60-х годов. В то время широко обсуждались проекты CASSM, CASS, RAP и др. [2], но возможности серийного оборудования были более чем скромными, а экзотические дорогие решения на основе уникальных компонентов оказались малопригодными для массового использования. Результаты исследований и разработок позволили в начале 1990-х годов сделать такой вывод: будущее принадлежит параллельным системам для организации баз данных, создаваемым на базе серийных процессоров, памяти и дисков [3]. Каждый такой процессор может работать только со своей областью базы данных и обмениваться сообщениями с другими процессорами через сетевое соединение или общую память. Это позволяет разбивать большие таблицы на меньшие и проводить их обработку параллельно.
Именно так были устроены экспериментальные прототипы Arbre, Bubba и Gamma. Эта архитектура обусловила успех первой промышленной многопроцессорной машины баз данных компании Teradata DBC/1012 (1984 год) — «родоначальницы» современных специализированных устройств для хранилищ данных. И она обеспечила более чем двадцатилетнее развитие СУБД Teradata и других систем.
На протяжении последних десятилетий развитие технологической инфраструктуры стимулировал поиск сбалансированных решений, обеспечивающих рост производительности и эффективности программного обеспечения и оборудования, а также масштабируемость, надежность отдельных компонентов и отказоустойчивость систем. Всякий раз, когда потребность рынка в ИТ-сервисах превышала возможности существующих продуктов, наступало время переоценки накопленного опыта, и появлялись новые технологии. Например, в конце 80-х годов возникла необходимость в более тесной интеграции разрозненных систем управления производством, бухгалтерским учетом, клиентской базой, поставщиками и партнерами и т.п., а потенциал самостоятельных разработок компании практически исчерпали. Тогда ИТ-индустрия, консолидировав опыт автоматизации отдельных видов деятельности и мобилизовав значительные интеллектуальные и материальные ресурсы, предложила интегрированные корпоративные системы классов ERP и CRM.
А ответом на отсутствие эффективного инструмента бизнес-анализа огромных потоков информации стало создание специализированных машин хранилищ данных (Data Warehouse Appliance). В ряде случаев они проще и дешевле традиционных платформ, легко вписываются в существующую систему и сразу после загрузки способны обрабатывать запросы к базам данных объемами десятки терабайтов не за дни и часы, а за минуты или даже секунды. «За треть или четверть обычной цены клиент получает значительно лучший результат», — утверждает Джит Саксена, директор компании Netezza, которая в 2003 году создала первую машину хранилищ данных. Вслед за ней о выпуске устройств этого класса объявили DATAllegro и Calpont.
Концептуально машина хранилища данных близка к сетевому устройству хранения — специализированному высокопроизводительному файл-серверу с массивами дисков, сервисами которого могут пользоваться приложения, исполняемые на других серверах и клиентах. Возможность реализации нового решения появилась в результате синтеза достижений в ряде смежных областей. Это архитектура многопроцессорных систем и параллельных баз данных, технологии серверов, запоминающих устройств и сетевых соединений, открытые операционные системы и СУБД, а также стандартизация интерфейсов доступа к базам данных и языка SQL. Облик нового устройства определили следующие требования.
- В нем должны объединяться операционная система, СУБД, сервер и запоминающие устройства.
- Высокая производительность достигается за счет фрагментации баз данных, распараллеливания процессов обработки запросов, их максимального «приближения» к устройствам хранения и оптимизации функций СУБД.
- Необходима высокая степень интеграции и эксплуатационной готовности конструкции: все компоненты должны быть взаимоувязаны и полностью конфигурированы. Требуется, чтобы устройство было готово к решению целевой задачи сразу после подключения и загрузки данных. Действия администратора баз данных и технических служб должны сводиться к минимуму.
- Взаимодействие внешних приложений с устройством должно быть прозрачным и осуществляться на основе стандартных интерфейсов подключения к базам данных.
Анатомия машины хранилища данных
Конструктивно машина хранилища данных представляет собой смонтированную в стойку многопроцессорную систему, состоящую из главного и периферийных узлов. Они имеют процессоры, память, контроллеры, запоминающие устройства, порты ввода/вывода, оснащены полностью настроенными программными средствами и связаны между собой высокоскоростным сетевым соединением Infiniband (DATAllegro) или gigabit Ethernet (Netezza). Внешние приложения воспринимают машину хранилища данных как обычный сервер СУБД и взаимодействуют с ним через стандартные интерфейсы ODBC, JDBC и SQL 92/99. Схема обработки запросов с помощью специализированной машины показана на рис. 1.
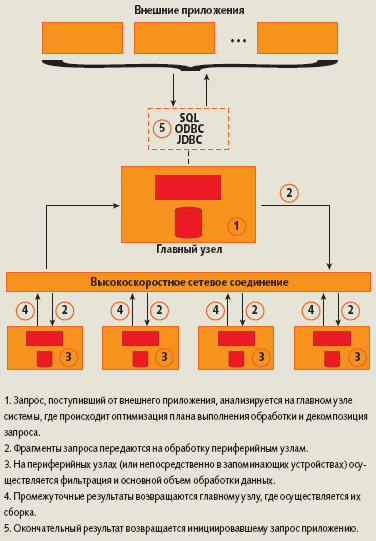 |
| Рис. 1. Схема обработки запросов с помощью специализированной машины |
В машинах хранилищ данных используется либо массивно-параллельная, либо гибридная схема мультипроцессирования. Иерархическая архитектура машин NPS (рис. 2, б) компании Netezza получила название ассиметричная массивно-параллельнаях (Asymmetric Massively Parallel). На первом уровне располагается основной узел, мощный SMP-сервер, а на втором — десятки и сотни параллельно работающих миниатюрных периферийных узлов (Snippet Processing Unit, SPU). Компания DATAllegro применяет массивно-параллельную схему мультипроцессирования без разделения ресурсов (Ultra Shared Nothing). В ее специализированных устройствах (рис. 2, а) главный и периферийных узлы — это полнофункциональные двухпроцессорные серверы СУБД на базе процессоров Intel Xeon, каждый из которых оснащен 12 дисками Raptor производства Western Digital.
Преимущества распределения обработки данных по периферийным узлам проиллюстрируем на основе гипотетического примера из области добычи полезных ископаемых. Чтобы получить всего несколько килограммов редкоземельного металла (результат запроса), сначала необходимо выдать на-гора тысячи тонн породы (исходные данные). Далее нужно построить магистрали и обзавестись должным количеством транспортных средств, чтобы доставить руду на обогатительный комбинат. Затем сырье подвергается соответствующей обработке (фильтрация исходных данных).
А что, если процесс обогащения (фильтрация данных) перенести как можно ближе к месту добычи (запоминающее устройство) и возить только концентрат? Тогда, во-первых, не потребуется транспорт большой грузоподъемности, а значит, упростится транспортная инфраструктура (сетевое соединение). Во-вторых, снизится нагрузка на перерабатывающее предприятие (главный узел).
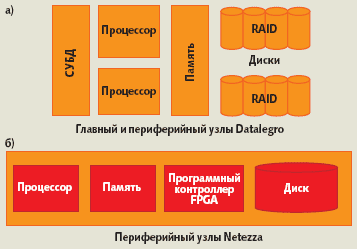 |
| Рис. 2. Примеры архитектур машин хранилищ данных |
Современное дисковое запоминающее устройство мощного сервера, настольного компьютера и ноутбука фактически представляет собой небольшой компьютер. В нем кроме дискового шпинделя имеются контроллер с достаточно мощным процессором, оперативная память и порты ввода/вывода. Как показали исследования и экспериментальные разработки в области так называемых «интеллектуальных» дисков, проводившиеся в 70-90-е годы, наряду с выполнением на физическом уровне элементарных операций ввода-вывода такие устройства могут взять на себя обработку более сложных инструкций, которая обычно возлагается на серверную часть СУБД [4, 5].
При обработке фрагмента запроса периферийный узел работает практически автономно. Здесь планируется вычислительный подпроцесс, происходят выделение и освобождение памяти, управление транзакциями, обработка контрольных точек и т.д. Все низкоуровневые операции на уровне записей (сопоставление значений, фильтрация, проекция, блокировка и журналирование) выполняются в непосредственной близости от места хранения данных. За счет этого радикально уменьшаются паразитный трафик и нагрузка на центральный узел, а управление системой упрощается. Операции сортировки, слияния и агрегирования промежуточных результатов выполняются, в зависимости от плана обработки запроса, на периферийных узлах или центральном сервере СУБД.
Доступ к дискам может осуществляться в произвольном порядке (за одно обращение считывается страница памяти) или последовательно (смежные страницы обрабатываются непрерывно). Для целого ряда приложений бизнес-аналитики потоковая обработка (data streaming) предпочтительна, поскольку она не сопряжена с интенсивным перемещением головок и выполняется значительно быстрее. Но из-за широкого применения индексов, необходимости поддержки разных запоминающих устройств, операционных систем и СУБД в традиционных технологических платформах хранилищ данных приходится ориентироваться преимущественно на произвольный доступ.
Разработчики машин хранилищ данных применяют специальные механизмы сериализации, фактически обеспечивающие отказ от индексов и обработку данных непрерывным потоком. Среди таких механизмов — реализованная на уровне адаптации СУБД технология Direct Data Streaming компании DATAllegro и встраивание соответствующих функций управления данными в прошивку программируемой матрицы контроллера дисков периферийного узла SPU компании Netezza. Компания Calpont идет еще дальше: ее специализированные устройства вообще не имеют дисков. Данные хранятся в оперативной памяти, а аппаратная реализация СУБД, называемая машиной потоков данных (data flow engine), состоит из анализатора запросов (parser), обработчика плана запроса (execution tree engine) и процессора доступа (graph engine), с помощью которого осуществляются операции манипулирования данными.
Программное обеспечение машин хранилищ данных базируется на открытых операционных системах и системах управления базами данных. Этот выбор продиктован как инженерными, так и экономическими соображениями. Если компания-разработчик не владеет правами интеллектуальной собственности на соответствующие продукты и технологии, то для глубокой адаптации программного обеспечения к архитектуре системы и его интеграции с техническими средствами (в том числе встраивания функций управления данными в аппаратуру) ей требуется доступ к исходным кодам. Кроме того, необходима всесторонняя поддержка со стороны как поставщика программного решения, так и сообщества пользователей и разработчиков. Второе условие вызвано своеобразием модели «все в одном»: приобретая машину хранилища данных, потребитель должен получить готовое к эксплуатации изделие и не заботиться о покупке лицензий или подписок на программы. Поэтому на машинах NPS компании Netezza устанавливается операционная система Red Hat Linux Advanced Server, а на устройствах DATAllegro — Novell SUSE Linux.
Наряду с функциональной полнотой, высокими производительностью и надежностью важнейшими характеристиками СУБД для машин хранилищ данных являются эффективная реализация функций агрегирования отношений, загрузки данных и распараллеливания обработки, модульность и возможность адаптации к аппаратной платформе, разнообразие структур таблиц и индексов, обеспечение управления вводом/выводом на физическом уровне.
В качестве исходной системы в Netezza выбрали открытую СУБД PostgresSQL. В машинах NPS ее функции разделены между главным и периферийными узлами ;— операции высокого уровня реализуются серверным компонентом DBOS, а низкоуровневые встроены на аппаратном уровне в контроллеры периферийных узлов SPU. Дополнительные программные средства NPS включают в себя Windows- или Web-консоль администратора и утилиту массовой загрузки хранилища данных.
Компания DATAllegro в качестве СУБД использует существенно переработанную версию CA Ingres R3. Она имеет развитые средства оптимизации и параллельной обработки запросов, доступа к данным на физическом уровне, управления транзакциями и памятью. Возможности системы расширяет интеллектуальный маршрутизатор запросов Intelligent Query Router, с помощью которого можно создавать распределенные хранилища данных и встраиваемые в специализированные машины средства криптографической защиты информации.
Одно из ключевых требований к хранилищам данных — обеспечение целостности данных и отказоустойчивости системы. В машине хранилищ данных NPS основной механизм обеспечения целостности — полное дублирование данных таблиц, хранящихся на периферийных узлах SPU, с размещением зеркальной копии на альтернативном узле. Дополнительно реализуются требования атомарности, непротиворечивости, изолированности и сохраняемости, которым должны удовлетворять операции над базой данных, а также оперативного восстановления работоспособности после сбоев (с временной потерей производительности), получения моментальных снимков состояния базы данных, пошагового резервного копирования и восстановления изменений базы данных. В каждой стойке NPS есть источник бесперебойного питания, коммутатор Gigabit Ethernet и четыре резервных периферийных узла SPU. Единственным элементом, отказ которого приводит к выходу из строя всей системы, является главный узел, а потому в конфигурациях с повышенной отказоустойчивостью дублируется и этот компонент.
Для поддержания целостности данных в машине компании DATAllegro используются аналогичные средства, а также разработанный по аналогии с технологией RAID механизм избыточный массив недорогих хранилищ данных (Redundant Array of Inexpensive Warehouses, RAIW). Конструктивно все узлы этой системы идентичны, поэтому при выходе из строя главного узла его функции берет на себя один из периферийных.
Что привлекает пользователей
Согласно результатам опроса 3 тыс. руководителей компаний, который провел в середине прошлого года институт The Data Warehouse Institute (TDWI), 39% организаций уже используют или изучают целесообразность внедрения машин хранилищ данных. Есть несколько аргументов в пользу такого решения: это прозрачность, высокая производительность, простота эксплуатации и приемлемая общая стоимость. Последняя складывается из стоимости оборудования, развертывания системы и поддержания заданных операционных характеристик (до 80% общих затрат). «Регулярное общение с пользователями свидетельствует о том, интерес к машинам данных растет. Это инновационное решение сулит большие преимущества», — подчеркивает Филип Рассом, руководитель исследовательского подразделения TDWI [6].
По сравнению с системами, базирующимися на традиционных платформах, машины хранилищ данных обеспечивают 10-50-кратное ускорение обработки запросов. Не менее важны и сроки окупаемости (возврата инвестиций). Из-за того, что не нужны длительные конфигурирование и настройка оборудования, удается быстро получать аналитические отчеты и сводки. Благодаря прозрачности взаимодействия с современными продуктами для бизнес-анализа (Business Objects, Cognos, MicroStrategy, SAS, Unica и др.) и загрузки данных (Ascential, Informatica, Sunopsis) ИТ-подразделения могут гибко формировать хранилища данных и встраивать их в имеющуюся инфраструктуру. При этом не нарушается работоспособность систем, автоматизирующих основные виды деятельности компании.
Для телекоммуникационных фирм массовое применение средств бизнес-анализа стало неотъемлемой частью повседневных операций. Скажем, компания Caudwell Communications (Великобритания) предлагает пакеты услуг проводной связи частным лицам и бизнес-структурам. Конкуренция в этом сегменте рынка очень высока, и для того, чтобы формировать персонифицированные услуги и обеспечивать выгодные условия их получения, приходится детально анализировать записи об абонентах и востребованных ими сервисах. В Caudwell Communications решили создать хранилище данных. Оно должно было иметь приемлемую стоимость и обеспечить как хранение больших объемов информации, так и быструю обработку запросов и загрузку обновлений. Были поставлены три последовательные цели: максимум за четыре месяца развернуть хранилище, затем разработать интегрированную унифицированную модель данных фирмы, объединить разрозненные информационные системы и создать эффективные процедуры выборки, трансформации и загрузки данных. Такая стратегия должна была обеспечить высокие темпы разработки и окупаемости затрат [7].
В качестве проверки был предпринят сквозной перекрестный анализ базы данных, содержавшей 56 млн детальных записей и 57 тарифных планов. Машина хранилища данных NPS успешно выдала точный результат менее чем за полтора часа, в то время как обработка запроса на традиционной платформе продолжалась двое суток, а полученный отчет содержал ошибки. В конце 2003 года компания приобрела две машины хранилища данных NPS 8100: одна — для обработки производственных запросов и отчетов, а вторая — для разработки, отладки и резервного копирования хранилища. К началу 2005 года была построена модель данных, интегрирующая представления разрозненных систем управления взаимоотношениями с клиентами и биллинга, которыми пользовались разные подразделения. С помощью ETL платформы Sunopsis удалось реализовать процедуры выборки, трансформации и загрузки данных.
Непосредственными пользователями системы стали группа аналитиков и ряд сотрудников финансового отдела. Благодаря интеграции данных в хранилище они перестали замечать, что система CRM работает в среде Windows/SQLServer, а биллинговая система — на платформе Unix/Oracle. Теперь потребители оперируют обобщенными информационными объектами, которые адекватно отражают деятельность компании и ее клиентов. Обработка запросов существенно ускорилась и появилась возможность использования детальных данных о вызовах. Ежедневно обрабатывается до 1 тыс. запросов к хранилищу данных, насчитывающему около 1 млрд детальных записей. К началу каждого рабочего дня руководство получает свежие результаты анализа — согласованные и точные отчеты о деятельности компании и активности ее клиентов. Причем этот график никогда не нарушается, хотя объем хранилища данных постоянно увеличивается.
Создание хранилища данных на базе специализированного устройства позволило значительно улучшить качество решений, принимаемых менеджерами компании. Когда конкуренты объявляют о введении новых тарифов, специалисты Caudwell Communications могут оперативно анализировать альтернативные варианты и предлагать абонентам более выгодные условия. Появилась и возможность всесторонне исследовать процессы обработки массивов данных о заказах и выставленных счетах, а также гармонизировать информационные системы линейных подразделений.
Очередной бум или прообраз новой архитектуры?
Одновременно с переходом к хранилищам, вмещающим терабайты данных, изменяются методы работы с информацией и средства управления информацией. Судя по результатам успешных внедрений, машины хранилищ данных проявляют себя как жизнеспособный компонент согласованной программы развития ИТ-инфраструктуры, оправдывают ожидания руководства компаний и, видимо, займут свое место в портфеле технологий бизнес-анализа. Сочетание их высокой производительности, эффективного предоставления критически важных услуг бизнес-анализа с простотой и приемлемой стоимостью эксплуатации позволяет предположить, что новые устройства могут претендовать на роль технологического ядра корпоративного хранилища данных.
Тогда стратегия развития может быть такой. На основе данных существующего хранилища или действующих информационных систем с помощью новой технологии реализуются наиболее критичные, с точки зрения оперативной обработки аналитических запросов, специализированные хранилища, или витрины данных (data mart). В случае успеха в состав специализированного хранилища вводятся данные из других систем. По мере «разрастания» хранилища данных система масштабируется за счет добавления новых устройств или модулей. Когда достигнута «критическая масса» положительного опыта, подтверждающего гибкость и надежность выбранного решения, может быть поставлен вопрос о перемещении на новую платформу большинства аналитических задач компании.
Однако, несмотря на декларируемое поставщиками применение стандартных компонентов и программного обеспечения с открытым кодом, потребителей настораживает очевидная «замкнутость» специализированных решений. Прежде всего, это жесткая (аппаратная) реализация функций управления данными и проблематичность последующей модификации или повторного использования компонентов. А стоимость рассматриваемых устройств, хотя она и считается приемлемой в контексте значимости задач бизнес-анализа, все же исчисляется сотнями тысяч и миллионами долларов. Остается надеяться, что эти недостатки будут компенсированы выгодами применения результатов бизнес-анализа в основной деятельности компаний.
По оптимистичной оценке Билла Инмона, одного из основоположников концепции корпоративной информационной «фабрики», появление машин хранилищ данных (речь идет о продукции Netezza) указывает на зарождение принципиально новой ИТ-архитектуры. Она соответствует сервисной модели деятельности и обеспечивает развитие бизнеса компаний [8].
Литература
- Forrester Research, Process-Centric BI Emerges. December 2004, web2.forrester.com/Events/ Overview/0,5158,738,00.html.
- Э. Озкархан, Машины баз данных и управление базами данных. М.: Мир, 1989.
- Д. Девитт, Д. Грэй, Параллельные системы баз данных: будущее высокоэффективных систем баз данных. СУБД, 1995, № 2.
- K Bratbergsengen. Parallel Database Machines // Rivista di Informatica. — 1995, vol. XXV, №4.
- K. Keeton, D.A. Patterson, J. Hellerstein, A Case for Intelligent Disks. SIGMOD Record, 1998, 27 (3).
- Drivers for the Growing Data Warehouse Appliance Market. November 2005, www.tdwi.org/research.
- World Class Solution Award Winners: Caudwell Communications. www.dmreview.com/awards/wcs/ 2005/Caudwell.cfm.
- W. Inmon, R. Terdeman, Netezza: New Architecture Rising. www.netezza.com/analystReports/ 2002/inmon_report.pdf.
