
NT-версия СУБД корпорации NCR обеспечивает высокую масштабируемость и производительность
Корпорация NCR перенесла на платформу NT свою СУБД Teradata, в результате чего получился отличный, богатый возможностями программный продукт, обладающий весьма высокой производительностью, надежностью и масштабируемостью. Teradata for NT (TNT) заслужила в моем тестировании высшую оценку, в чем немалую роль сыграла гибкая, масштабируемая архитектура СУБД.
Более десяти лет Teradata демонстрировала рекорды производительности в категории СУБД для Unix-систем. Крупнейшие организации всего мира доверяют ей управление сложнейшими хранилищами данных. NCR приступила к переносу Teradata с платформы Unix на Windows NT два года назад. TNT очень хорошо подходит для предприятий, которым требуется хранилище данных, обладающее высокой масштабируемостью и производительностью, но которым не по карману развертывание Unix-сред корпоративного уровня.
Снова BYNET
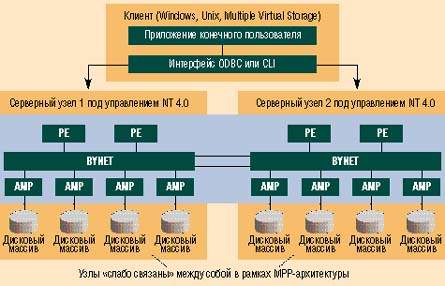
Teradata представляет собой реляционную СУБД с функциями поддержки принятия решений, рассчитанную на организации, имеющие потребности в хранении и анализе гигабайтов или даже терабайтов данных. Ключевой особенностью TNT является сочетание архитектуры массово-параллельной обработки (massive-parallel processing — MPP) и симметричной многопроцессорной обработки (symmetric multiprocessing — SMP; см. врезку «Архитектуры MPP и SMP»). TNT опирается на архитектуру BYNET, созданную NCR для Unix-версии СУБД и перенесенную из принадлежащей NCR версии Unix — MP-RAS. Архитектура BYNET соединяет до четырех SMP-узлов, работающих под управлением Windows NT, в слабосвязанную логически единую систему баз данных.
На каждом из NT-узлов функционируют так называемые виртуальные процессоры двух видов: PE (parser engine, механизм синтаксического разбора) и AMP (access module processor, процессор модуля доступа). PE-процессоры обрабатывают клиентские SQL-запросы и управляют сеансами связи с AMP-процессорами, которые, в свою очередь, управляют доступом к базе данных и обеспечивают параллелизм (см. схему).
Допустим, клиентское приложение выдает стандартную команду ANSI SQL SELECT, используемую для извлечения набора данных из базы данных Teradata. Команда принимается и обрабатывается PE-процессорами. Они осуществляют синтаксический разбор команд, оптимизируют планы запроса и передают его на AMP-процессор при помощи BYNET. Каждый из AMP-процессоров обрабатывает свою часть запроса и возвращает результаты PE-процессорам. Те объединяют результаты и возвращают набор ответов клиенту. Таким образом, даже при выполнении самых сложных запросов достигается очень высокая скорость извлечения информации.
В моем тестировании использовалась система NCR WorldMark 4800, состоящая из двух NT-узлов. Физическая конфигурация включала восемь 500-мегагерцевых микропроцессоров Pentium III Xeon, 2 Гбайт памяти и 80 дисков объемом по 9 Гбайт. TNT поддерживает работу с NT-узлами, содержащими до четырех процессоров, обеспечивая уровень производительности, сравнимый с Teradata, работающей на Unix-системе аналогичной конфигурации.
Тестирование началось с попытки поработать с утилитой Database Window, запущенной на консоли администратора. Database Window «сообщила», что на каждом из узлов функционируют по десять AMP- и по два PE-процессора. Утилита работает в символьном режиме, и потому покажется более привычной пользователям Unix-систем. Впрочем, NCR конфигурирует все свои системы перед доставкой заказчику (а также выполняет по его требованию любую модернизацию). Поэтому детальное изучение Database Window системному администратору может и не понадобиться.
Гораздо более удобным средством администрирования мне показался Teradata Manager. Он оснащен удобным графическим интерфейсом в стиле Windows, предоставляющим средства мониторинга производительности, управления предупреждениями, графического анализа, генерации отчетов и конфигурирования системы.
NCR оснастила Teradata массой функций, так что пользователи, впервые столкнувшиеся с системой, вряд ли смогут быстро научиться работать с ней. Новичкам я рекомендую воспользоваться льготами на обучение, предоставляемыми в рамках лицензионного соглашения. Документация отличается доходчивостью и поставляется на одном компакт-диске в формате Adobe Acrobat 4.0, который прилагается.
Переходим к данным
Довольно много времени я уделил работе с двумя SQL-инструментами Teradata: WinDDI (Windows Data Dictionary Interface) и Queryman. Первый представляет собой графический интерфейс, позволяющий при помощи команд языка определения данных SQL DDL (Data Definition Language) управлять объектами и пользователями баз данных; второй предназначен для ввода запросов SQL. Пользуясь этими утилитами, я по-настоящему ощутил широту возможностей Teradata.
При помощи WinDDI я создал новую таблицу, используя команду CREATE TABLE. Особого внимания заслуживает процесс размещения таблицы в системе: используя другие реляционные СУБД, можно существенно повысить производительность за счет тщательного планирования физического размещения таблиц в базе данных. Однако в Teradata синтаксис команды, идентифицирующей место хранения таблицы, имеет вид PRIMARY INDEX (имя_поля); возможность указания сегмента или страницы не предусмотрена.
AMP-процессоры Teradata выбирают место размещения таблиц по имени поля, используя хэш-алгоритм. С точки зрения администратора процедура размещения таблиц в Teradata оказалась невероятно простой. Упрощая процесс администрирования, СУБД позволяет ускорить построение хранилища данных.
Процедура добавления пользователей к Teradata поначалу показалась мне несколько непонятной. Я рассчитывал, что WinDDI отобразит административные данные по каждой из баз данных, как это делает Microsoft SQL Server. Но вместо этого WinDDI отображает пользователей.
Новые пользователи создаются командой CREATE USER. Доступ к пользовательским таблицам осуществляется не по названию базы данных и имени таблицы, а по имени пользователя. Привязка таблиц к пользователям позволяет AMP-процессорам Teradata управлять содержимым таблиц вне зависимости от структуры базы данных. По описанию пользователя приложение может определить максимальный выделенный ему размер пространства в базе данных и выяснить, кому принадлежит таблица. Обеспечиваемую за счет этого простоту управления администраторы смогут оценить, познакомившись с Teradata получше.
Одно из окон Queryman, в котором я вводил команды SQL, оказалось крайне полезным. Я имею в виду список всех ранее сделанных запросов, выводящий по щелчку мыши подробную статистику. Эта функция очень помогла мне в тестировании — я многократно выбирал из этого списка запросы для повторного использования. Заслуживает также упоминания возможность параллельного выполнения нескольких запросов в одном окне. Я использовал ее несколько раз для сравнения результатов одиночного и множественных запросов. С точки зрения администратора, возможность параллельного выполнения запросов очень удобна; она позволяет задействовать максимум ресурсов базы данных и быстрее выполнить работу.
Все вводимые мною стандартные команды ANSI SQL работали как положено. Однако в Teradata нет встроенного языка хранимых процедур; NCR включила его поддержку лишь в следующую версию. Хранимые процедуры обычно применяются для того, чтобы перенести основную часть нагрузки с клиентского приложения на сервер баз данных. Teradata не нуждается в этом, так как за обработку запросов отвечают PE и AMP-процессоры. Единственное, что требуется от клиента, — выдать команду. В общем, отсутствие языка хранимых процедур не показалось мне серьезным упущением. Teradata содержит язык макросов, напоминающий процедурный, но ограниченный в возможностях.
Очень удобным оказалось использование производных таблиц в сложных запросах. Вместо того чтобы создавать временные таблицы, достаточно добавить команду SELECT в операторе FROM. Такая возможность заметно экономит время при построении запросов. Teradata поддерживает также функции RANK и QUANTILE, существенно облегчающие процесс составления запросов, выполняющих сложные вычисления.
В заключение тестирования я сгенерировал несколько отчетов при помощи Cognos Impromptu и Seagate Info. Оба продукта без затруднений удалось подключить к Teradata посредством интерфейса ODBC.
NCR тесно сотрудничает с Cognos и рядом других компаний, помогая им встраивать в свои программные продукты функции, полагающиеся на мощь Teradata. За счет переноса нагрузки по обработке результатов с клиентского приложения на СУБД удается значительно повысить скорость выполнения запроса. Сгенерированные при помощи Cognos отчеты, в которых использовались функции, оптимизированные для работы с Teradata, возвращали результаты в считанные минуты. В ожидании обработки отчетов, не содержавших оптимизированных функций, я успевал выпить чашечку кофе с булочкой. Надо, впрочем, признаться, что в тестировании мною использовались чрезвычайно сложные запросы.
Если вы до сих пор не считаете Windows NT пригодной для работы с приложениями корпоративного уровня, Teradata for NT, возможно, заставит вас переменить мнение. Функциональность и уровень масштабируемости Teradata сделали ее операционной системой, способной управлять корпоративными хранилищами данных, отвечающими высочайшим требованиям. Широкий ассортимент инструментов и утилит, входящих в комплект поставки СУБД, содержит все необходимое для формирования хранилища данных и управления им без перехода на новую среду.
Я поставил NCR Teradata NT оценку «превосходно», несмотря на отсутствие языка хранимых процедур. В недавно анонсированной версии СУБД появились хранимые процедуры и поддержка Windows 2000.
Аллан Холбрук — старший системный инженер Holbrook Consulting. Адрес его электронной почты allan@servillian.com.
Teradata 3.0.1 for Windows NT
Teradata for Windows NT — реляционная СУБД, реализующая функции поддержки принятия решений и обеспечивающая высочайшую производительность и масштабируемость. Перенеся данный программный продукт из среды Unix MP-RAS, корпорация NCR обеспечила уровень параллелизма, не достигнутый ни одной другой реляционной СУБД.
Достоинства: исключительная масштабируемость системы; простота администрирования и разработки баз данных; наличие полезных клиентских утилит
Недостатки: отсутствие языка хранимых процедур; для настройки системы требуется помощь производителя; несколько утилит работают в символьном режиме
Цена: 199 тыс. долл. за ПО и услуги
Производитель: NCR, www.ncr.com
Платформы: Windows NT 4.0 Server или Enterprise Edition с пакетом обновлений Service Pack 5
Архитектуры MPP и SMP
Чтобы разобраться в особенностях реализации Teradata for NT, следует понять разницу между технологиями массово-параллельной обработки (massive-parallel processing — MPP) и симметричной многопроцессорной обработки (symmetric multiprocessing — SMP).
SMP делит дисковое пространство между всеми процессорами системы. Такая архитектура называется «сильно связанной». Каждый SMP-узел Teradata NT на плтаформе Windows NT Enterprise Edition может содержать до четырех процессоров. SMP-системы хорошо масштабируются до фиксированного числа процессоров. По достижении этого порога непроизводительные затраты на управление системой сводят на нет преимущества, получаемые при добавлении нового процессора.
Максимальное число процессоров зависит от их модели. К примеру, при использовании процессоров Intel 486 предел составлял восемь; для SMP-систем на базе 500-мегагерцевых Pentium III Xeon максимум достигает 32.
Архитектура MPP «слабо связывает» два или более узлов (в их качестве могут выступать SMP-системы): каждая из них имеет собственную систему хранения.
Масштабируемость MPP-системы не ограничена. По мере добавления SMP-узлов непроизводительные затраты остаются на одном и том же уровне; масштабируемость возрастает линейно. Некоторые пользователи Teradata располагают MPP-системами, состоящими более чем из 150 процессоров.
NCR Teradata 3.0.1 NT объединяет технологии MPP и SMP, пользуясь преимуществами обеих архитектур. SMP-узлы на базе Windows NT, на которых функционирует Teradata, могут содержать до четырех процессоров, но MPP позволяет использовать с СУБД до четырех SMP-узлов.
Таким образом, Teradata NT масштабируется до 16 процессоров. Следующая версия СУБД будет поддерживать до 16 SMP-узлов, или до 64 процессоров.
Архитектура Teradata NT
Teradata устанавливается на вычислительную систему MPP-архитектуры, каждый узел которой работает под управлением Windows NT и может содержать до четырех процессоров. Процессоры модуля доступа (APM) отвечают за доступ к базе данных, а механизмы синтаксического разбора (PE) обрабатывают поступающие от клиента SQL-запросы, управляют сеансами с AMP и возвращают результаты запросов клиенту
 |