Шрифты
«Носителями» кодовых страниц в Windows являются шрифты. Программа «Таблица символов» позволяет рассмотреть первые 256 символов, которые отображаются с помощью данного шрифта. Одни из них, соответствующие кодовой странице Windows-1251, применяются для передачи текста, другие — математические, а третьи — просто значки для «разукрашивания» документа, хранящиеся в специальных шрифтах.
Пользователь может выбирать любой шрифт, работая практически во всех текстовых редакторах в среде Windows, за исключением Блокнота. Так, если для текста задать какой-нибудь символьный шрифт, например Wingdings, то получится последовательность значков вроде: ![]() , соответствующих кодам стоявших на их местах букв.
, соответствующих кодам стоявших на их местах букв.
Unicode
При использовании ранних версий ОС Windows в одну кодовую страницу нельзя было поместить больше 255 символов, поэтому был разработан новый стандарт таблицы символов — Unicode. Согласно ему каждый символ кодировался не восемью, а шестнадцатью битами информации, что позволяло получить до 65 536 знаков. Чтобы обеспечивалась совместимость со старыми стандартами, первые 256 символов Unicode соответствовали типовой кодовой таблице, а остальные предназначались для букв и знаков различных языков. В шрифте Unicode помещается несколько кодовых страниц сразу.
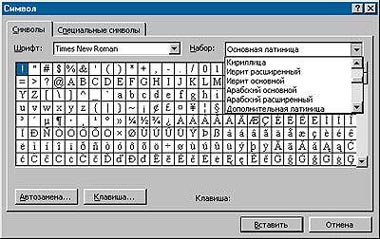 |
| Содержимое Unicode-шрифта Times New Roman |
Чтобы программы, не поддерживающие стандарт Unicode (например, Microsoft Word 6.0), могли работать с новыми шрифтами, ОС выполняет так называемую «подстановку шрифтов», т. е. «раскладывает» шрифт Unicode на отдельные кодовые страницы и выбирает ту, которая подходит установленной в системе. Параметры подстановки прописываются в системном реестре и в файле Win.ini, указывая программам, где искать соответствующие нужной кодовой странице символы.
Иногда возникает ситуация, когда в Word 97 текст на экране отображается корректно, а на принтер выводится последовательность каких-то квадратиков. Это происходит из-за того, что одни компоненты (Word 97) поддерживают новый стандарт, а другие нет. Чтобы разрешить такую проблему, следует установить новые драйверы к принтеру или в разделе KEY_CURRENT_USERSoftwareMicrosoftOffice8.0Word<имя принтера> системного реестра создать новую строковую переменную Flags со значением 8192, либо в разделе Font Substitution для всех русских букв тех шрифтов, при распечатке которых выводятся квадратики, написать: Font,0=Font,204 и Font,204=Font,204. То же самое надо проделать и в Win.ini.
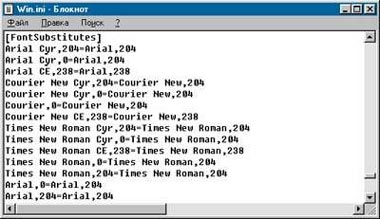 |
| Параметры подстановки шрифтов прописываются в системном реестре и в файле Win.ini |
KOI-8
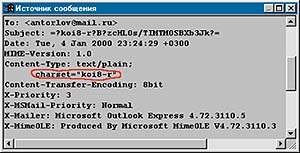 |
«Всемирная паутина» появилась и начала развиваться в Америке, поэтому вся система почтовых серверов была предназначена для работы с почтой англоязычных пользователей. Сначала по электронной почте отправлялись лишь текстовые сообщения, поэтому почтовые программы составлялись с использованием первой половины кодовой страницы — семибитной кодировки. Из-за этого те письма, в которых содержались символы с кодами, превышающими число 127, обрабатываться не могли. Чтобы они все же проходили через семибитные почтовые серверы, символы принудительно приводились к семибитному виду: обнулялся первый бит, указывающий на половину их кодовой страницы. Например, символ «е» (русская буква «е») переходил в «f», а символ «ш» — в «y».
 |
| На обоих экранах обведено указание на кодировку письма |
По-разному можно было выйти из сложившегося положения. Во-первых, что самое распространенное, писать письмо, используя транслитерацию, т. е. latinskimi bukvami. Хотя текст при этом выглядел некрасиво и плохо читался, сообщение всегда доходило в исходном виде. Поскольку не все почтовые серверы были семибитные, то была создана специальная кодировка под названием KOI-8 для электронной почты. Она отличалась тем, что на места кодов символов, превышающих 127, были проставлены русские символы, похожие по звучанию на английские, соответствующие кодам символов, номера которых были меньше на 128. Например, коды 225, 226, 227, 228 соответствовали символам «а», «б», «ц», «д», которые при семибитном преобразовании перешли бы в коды 97, 98, 99, 100 английских букв «a», «b», «c», «d». Слово «привет», написанное в такой кодировке, пройдя через семибитный почтовый сервер, преобразовалось бы в PRIWET.
Так как системы на основе Unix в основном были рассчитаны на работу с электронной почтой и международными сетями, новая кодировка стала стандартом для них. Чтобы облегчить переписку между пользователями разных типов ПК и ОС, KOI-8 была принята в качестве универсальной, т. е. любая почтовая программа обязана была уметь читать и отправлять в ней сообщения.
Слишком умные серверы
Наличие пяти различных кодировок для русского языка создавало определенные трудности, например потребовались специальные программы-перекодировщики. Однако самой большой проблемой стали российские почтовые серверы.
Казалось бы, нужно лишь одно — чтобы серверы обрабатывали сообщения в восьмибитных кодировках. Тогда тексты в любой кодировке всегда читались бы принимающей стороной с помощью программы, умеющей работать с ней. Но, увы, не все оказалось так просто. В некоторые почтовые серверы была встроена возможность автоматической перекодировки поступающих писем — вероятно, для определенной «стандартизации». Если поступало сообщение в кодировке Windows-1251 и сервер его так и воспринимал, то оно перекодировалось в KOI-8 и отправлялось дальше. Кодировка письма обычно указывалась в заголовке или прямо в тексте.
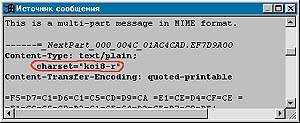
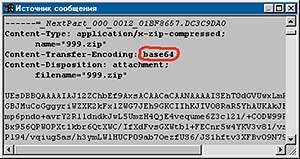 |
| Обведено указание на систему конвертации бинарных файлов |
Русифицированная версия Microsoft Outlook Express 5.0 по умолчанию для всех отправляемых сообщений ставит кодировку KOI-8 и отправляет их именно в ней. Однако некоторые почтовые программы могут делать ошибки, например письмо написано в KOI-8, а в заголовке письма проставляется, что оно имеет кодировку Windows-1251. Если такое письмо будет отправлено адресату, то оно не сможет сразу же правильно отобразиться в его почтовой программе — на экране появится мешанина из символов. Поскольку почти все почтовые программы позволяют просматривать одно и то же письмо в разных кодировках, то получатель прочитать его все же сможет, выбрав правильную кодировку. Но если письмо с не соответствующим содержанию заголовком попадет на перекодирующий почтовый сервер, то ситуация осложнится. По заголовку сервер решит, что раз оно написано в Windows-1251, как было указано, то его нужно перекодировать в стандартную для Сети (по мнению сервера и его создателей) кодировку KOI-8. Сообщение будет преобразовано из Windows-1251 в KOI-8, т. е. будут заменены соответствующие коды символов. Однако письмо-то уже изначально было в KOI-8! И что же получается? Автор письма написал фразу «Добро пожаловать», которая в KOI-8 записалась как «дНАПН ОНФЮКНБЮРЭ». А сервер снова перекодировал ее, но уже из Windows-1251 в KOI-8. В результате получилось: «Дмюом нмтчймачпщ», и понять что-либо стало уже невозможно. Если же на пути письма попалось несколько перекодирующих почтовых серверов, то его дешифрация становится крайне сложной задачей.
Вложенные файлы
Изначально по электронной почте нельзя было пересылать вложенные файлы (обычно это архивы), которые представляют собой двоичные данные, т. е. не раскладываются на вразумительную последовательность символов. Безусловно, можно было принудительно разбить последовательность данных в файле на группы по восемь бит и попытаться перевести их в текст. Можно проделать подобный эксперимент, переименовав какой-либо исполняемый файл или архив в файл с расширением «.txt» и загрузив его в Word 6.0 или 97. Однако после преобразований пересылаемая программа вряд ли бы заработала, а архив открылся бы, ведь их код стал бы испорченным и практически не поддавался бы восстановлению. Поэтому были разработаны специальные системы вложений в почтовые сообщения, основанные на конвертации двоичных данных в набор символов с кодами от 33 до 127. Впоследствии они могут быть подвергнуты обратному преобразованию. Было разработано несколько таких систем, самые распространенные из них — uuencode и base64. Почтовая программа, умеющая работать с вложениями, перед отправлением письма конвертировала вложенные файлы в одну из таких кодировочных систем (помещая перед вложением соответствующее указание), а после получения письма превращала вложенный фрагмент в исходный двоичный файл.
Вот, например, фрагмент письма с вложением, просматриваемый с помощью функции Microsoft Outlook Express «Свойства?Подробности?Исходное сообщение».
К этому письму приложен архив 999.zip, а также указан способ конвертации вложения — base64. Дальше идет набор символов первой половины кодовой таблицы — можно с уверенностью утверждать, что он пройдет через любые почтовые серверы неизмененным. При получении такого письма Outlook Express распознает наличие вставки base64, отобразит вложенный файл на панели вложений и позволит сохранить его на жесткий диск или прочитать, подвергнув обратному преобразованию из base64.
Таким образом, из-за наличия пяти кодовых страниц для русского языка требуется обеспечить две возможности. Во-первых, чтение текста, написанного в соответствии с одной кодовой страницей, в ОС с другой кодовой страницей, например текстов MS-DOS в Windows 95, во-вторых, расшифровку неоднократно перекодированных электронных писем. Чтобы решить эти проблемы, можно использовать специальные программы или компоненты программных пакетов. В следующей статье будет рассказано о некоторых из них.
Окончание в следующем номере.
Антон Александрович Орлов,
antorlov@mail.ru,
http://antorlov.chat.ru.