
Причины неустойчивой работы прикладного программного обеспечения в архитектуре с файловым сервером.
Почему прикладные программы, без особых проблем работающие в сотнях организаций, начинают периодически «сбоить», «зависать», терять данные и причинять другие неудобства пользователям именно в вашей компании? Почему локальная сеть, работающая если и не идеально, то, по крайней мере, устойчиво и быстро почти со всеми используемыми приложениями, вдруг начинает проявлять себя с не лучшей стороны, стоит лишь запустить вашу «любимую» программу? Однозначного ответа на эти вопросы не существует. Любая компания-разработчик прикладных программ — в той или иной мере сталкивается с подобными проблемами и пытается их тем или иным образом решить.
В ней мы попытались обобщить накопленный опыт решения проблем, связанных с эксплуатацией прикладного программного обеспечения (ПО) в локальных сетях, поиском и устранением причин его неудовлетворительной работы. Рассматриваемые вопросы одинаково актуальны как для сетей Novell NetWare, так и для сетей с серверами под управлением MS Windows или UNIX.
Для правильного понимания возможных причин некорректной работы прикладного ПО в локальной сети всю совокупность прикладного и системного ПО, а также технических средств сети необходимо рассматривать как систему. В процессе взаимодействия элементы системы оказывают влияние друг на друга. Если при определенных условиях один из элементов системы станет работать некорректно, то скорее всего это будет иметь негативные последствия для всей системы. Поэтому, рассматривая конкретные ситуации, связанные с неадекватной или некорректной работой отдельных элементов системы, мы будем описывать, каким образом это сказывается на работе всей системы. И наоборот, описывая неадекватное поведение системы в той или иной ситуации, мы собираемся искать его возможные причины, заключающиеся в некорректной работе или несогласованном взаимодействии элементов системы.
В настоящей статье мы постараемся рассказать о возможных недостатках всех элементов системы, показать на примерах «как не должно» и «как должно быть» и, по возможности, указать пути устранения этих недостатков.
КАК РАБОТАЕТ ПО
Прежде чем переходить к описанию возникающих проблем, мы хотели бы познакомить читателей с основными принципами работы прикладного ПО в локальной сети.
Основным недостатком файл-серверной архитектуры является прямая зависимость работы программы от канала связи между рабочими станциями и сервером. Тем не менее при небольшом количестве рабочих станций и наличии быстродействующего канала прикладное ПО, построенное на файл-серверной архитектуре, будет при прочих равных условиях работать быстрее, чем ПО, построенное на клиент-серверной архитектуре. Кроме того, оно будет значительно дешевле. Все это и предопределяет наличие на рынке большой доли файл-серверных программ.
Каковы же основные особенности файл-серверного ПО? В функционировании любой подобной прикладной программы можно выделить ряд общих моментов:
- для проведения операций записи подлежащая изменению часть базы данных должна быть заблокирована, чтобы другие пользователи не смогли в момент записи исказить записываемые данные;
- для проведения операций чтения часть базы данных также может быть заблокирована, чтобы не допустить искажения читаемых данных;
- при использовании блокировки базы данных по записи ни какой другой пользователь в это время не может ни прочитать, ни записать данные;
- при использовании блокировки базы данных по чтению на это время запрещаются только операции записи, читать данные могут все одновременно.
ШКВАЛ ЗАПРОСОВ
Теперь представим, что какая-либо из станций заблокировала базу данных с целью провести запись. Остальные станции получат от сервера отказ при попытке заблокировать соответствующие части базы данных с целью чтения или записи данных. С какой периодичностью они будут обращаться к серверу?
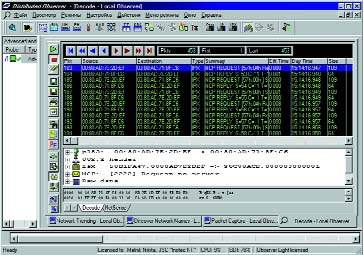 |
| Рисунок 1. Трасса обращений к серверу одной из рабочих станций при некорректном функционировании прикладной программы. |
Если периодичность запросов к серверу будет такой, как показано на Рисунке 1, то вместо того, что бы завершить операцию записи и освободить базу данных для дальнейшей работы, сервер будет вынужден все время заниматься ответами на запросы рабочих станций. Сколько станций он будет успевать обслуживать, зависит только от его (сервера) производительности, в том числе от пропускной способности файловой системы.
При подобной работе прикладного ПО может создаться парадоксальная ситуация «чем лучше — тем хуже». Иными словами, чем быстрее канал связи между рабочими станциями и сервером и чем производительнее рабочие станции — тем медленнее станет работать прикладное ПО. Подобная ситуация возникает в том случае, когда количество одновременно посылаемых запросов от рабочих станций таково, что сервер оказывается не способен обрабатывать эти запросы и одновременно выполнять файловые операции.
Пока количество одновременно работающих станций не превышает определенного числа, сервер успевает выполнить все запросы. Как только в работу включается новая рабочая станция, сервер уже не успевает обрабатывать запросы и отказывает рабочим станциям в возможности заблокировать базу данных. После получения отказа рабочие станции сразу же посылают следующий запрос. Вместо того чтобы завершить выполнение запроса от новой, только что включившейся в работу рабочей станции, сервер вынужден постоянно отвечать остальным рабочим станциям, что база данных не может быть заблокирована.
Конечно, это упрощенная модель ситуации, но она дает общее представление о причинах возникновения критической ситуации в результате некорректной работы прикладного ПО при ожидании освобождения базы данных. Теоретически, на сервере должна быть организована очередь запросов, и сервер сам должен определять интервал, через который он будет отвечать о невозможности блокировки определенного разделяемого ресурса.
На практике, например при использовании Novell TTS (Novell 3.x, и NetWare 4.x, и, возможно NetWare 5.x), сервер может установить бесконечно короткий интервал времени между запросом и своим ответом. Величина этого интервала будет зависеть в основном от загруженности сервера в данный момент времени.
Наилучший выход из описанной выше ситуации состоит в изменении прикладного ПО. В прикладном ПО принудительно задается задержка между моментом получения от сервера ответа о невозможности блокировать базу данных и моментом посылки следующего запроса. Время задержки может быть адаптивным, рассчитываемым по определенному алгоритму, или просто выбираться опытным путем. Наличие принудительной задержки между ответом сервера и следующим запросом рабочей станции позволит избавить сервер от лишней нагрузки, а канал связи — от большого числа коротких пакетов.
Однако если по каким-либо причинам очередь запросов на блокировку ресурсов на сервере не формируется, то после получения отказа в блокировке ресурса от сервера прикладная программа должна ждать некоторое время, прежде чем посылать следующий запрос. Время ожидания прикладной программы должно быть оптимизировано таким образом, чтобы, с одной стороны, не перегружать сервер и канал связи слишком частыми запросами, а с другой — не замедлять работу самой программы.
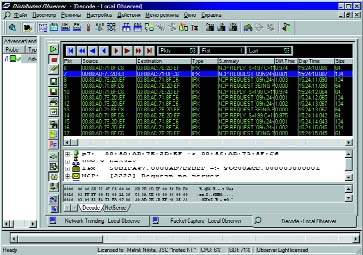 |
| Рисунок 2. Трасса обращений к серверу одной из рабочих станций при корректном функционировании прикладной программы. |
Пример корректной работы прикладной программы при попытке блокировки ресурса на сервере представлен на Рисунке 2. Между двумя запросами (пакеты 7 и 8) установлен интервал, равный примерно 1 с. В данном случае интервал был выбран опытным путем.
Если в прикладной программе есть возможность задавать интервал между запросами в соответствии с определенным алгоритмом, то мы рекомендуем воспользоваться отлично зарекомендовавшим себя алгоритмом, который активное оборудование Ethernet использует для доступа к разделяемой среде. Суть алгоритма, применительно к ПО, следующая: столкнувшись с невозможностью заблокировать базу данных, каждая рабочая станция, после некоторой задержки, пытается повторно произвести блокировку. После определенного числа попыток произвести блокировку рабочая станция выдает сообщение о том, что база данных постоянно занята. Величина задержки между попытками выбирается как равномерно распределенное случайное число из интервала, длина которого экспоненциально увеличивается с каждой попыткой. Такой алгоритм выбора величины задержки можно считать оптимальным для коллективной работы.
ЧЬЯ ОЧЕРЕДЬ
Следующей, не менее важной проблемой, мешающей нормальной работе прикладного ПО, может стать неэффективное использование очередей на блокировку ресурсов.
Предположим, что прикладная программа, основанная на файл-серверной архитектуре, использует как блокировку ресурсов базы данных на запись, так и блокировку на чтение. При этом если какой-либо ресурс базы данных заблокирован на запись, то другой пользователь не может производить с ним никаких действий. Если ресурс заблокирован на чтение, то все остальные могут производить только операции чтения.
Для доступа к ресурсам организована очередь. Первым в очереди стоит пользователь WS1, которому необходимо осуществить операцию чтения из базы данных, а следом за ним — пользователь WS2, которому нужно произвести запись в базу данных. Далее следуют пользователи WS3—WS6, которые хотят произвести чтение данных.
Как только подходит его очередь, пользователь WS1 блокирует необходимые ресурсы базы данных на чтение и начинает читать данные. Следующим в очереди стоит пользователь, которому необходимо произвести запись данных. Вследствие того, что база данных заблокирована на чтение, он продолжает оставаться в очереди, ожидая разблокирования ресурсов базы данных. Так как база данных заблокирована на чтение, то каждый из пользователей WS3—WS6 блокирует еще раз ресурсы базы данных на чтение и начинает операции чтения данных. В результате пользователь WS2 вынужден дожидаться, пока операции чтения не закончит последний из пользователей, находящихся в очереди. Таким образом, при достаточно большом количестве одновременно работающих пользователей произвести запись в базу данных может оказаться вообще невозможно.
Решить проблему можно путем расстановки приоритетов. Операции записи должны иметь более высокий приоритет по сравнению с операциями чтения. Такое решение является правильным еще и потому, что обычно число операций записи в единицу времени значительно меньше, чем число операций чтения. Присвоить «наивысший приоритет» операциям записи можно чисто программными средствами. Для этого перед тем, как начинать любую операцию чтения, необходимо проверить наличие в очереди задач, которые должны произвести запись в базу данных. Если такие задачи имеются, то их необходимо «пропустить вперед».
Конкретная реализация зависит от используемой СУБД. Если СУБД работает с Novell TTS, то для проверки очередей, а также блокировки ресурсов можно воспользоваться функциями Novell SDK.
Основная «хитрость» при проверке очереди блокировок состоит в следующем: каждая рабочая станция, заблокировавшая БД для чтения, проверяет, не остались ли в очереди другие рабочие станции. Если хотя бы одна рабочая станция в очереди собирается заблокировать базу данных для записи, то рабочая станция, заблокировавшая базу данных для чтения, приостанавливает работу и разблокирует базу данных. Аналогично поступают и другие рабочие станции, блокирующие базу данных на чтение. Рабочая станция, ждущая возможности осуществить запись в базу данных, блокирует БД на запись, выполняет все операции записи и разблокирует ее. После этого все продолжается по описанной выше схеме. Таким образом, операции записи получают более высокий приоритет, чем операции чтения.
ЧЕМ ДЛИННЕЕ, ТЕМ БЫСТРЕЕ
Еще одна важная проблема, не решив которой будет трудно добиться приемлемой работы прикладного ПО в сети, состоит в эффективном использовании канала связи. Для этого прикладная программа должна обмениваться с сервером сообщениями достаточно большой длины. Максимальная длина кадра в сети Ethernet (без преамбулы) составляет 1514 байт. Если сообщение длиннее 1514 байт, то оно разбивается на кадры, каждый из которых передается по сети самостоятельно. При передаче длинных сообщений свыше 1514 байт с целью уменьшения трафика включается режим Packet Burst.
В Novell NetWare 3.11 по умолчанию каждый переданный кадр квитируется, т. е. его получение подтверждается принимающей стороной. В Novell NetWare 3.12 и 4.х используется протокол Packet Burst Protocol, позволяющий без квитирования читать/писать данные объемом до 64 Кбайт. Размер окна (количество кадров, передаваемых без квитирования) является переменным и зависит от объема передаваемых данных и максимального размера пакета. Так, для передачи данных объемом 64 Кбайт при размере пакета 512 байт потребуется 128 кадров, а при размере пакета 1500 байт — 44 кадра. В квитанции на окно указываются номера полученных кадров, где были обнаружены ошибки. Передающая станция должна повторить передачу этих кадров. При увеличении числа кадров, принятых с ошибкой, NetWare автоматически уменьшает размер окна. Следует отметить, что использование протокола Packet Burst Protocol позволяет существенно сократить трафик в сети и тем самым повысить производительность системы. (В современных сетях MS Windows и UNIX имеются аналогичные средства для уменьшения трафика сети.)
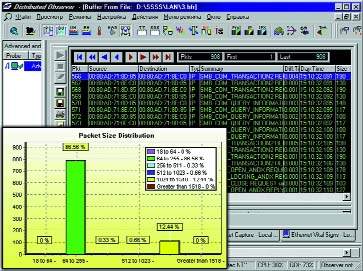 |
| Рисунок 3. Трасса обращений к серверу одной из рабочих станций при работе с базой данных при неэффективном использовании канала связи. |
На Рисунке 3 представлены трасса обращений к серверу одной из рабочих станций, осуществляющей чтение из базы данных, а также диаграмма с указанием доли пакетов различной длины в общем объеме трафика. Это один из примеров неэффективного использования канала связи прикладной программой. Программа обращается к базе данных, состоящей из множества файлов формата *.DBF. Информация из этих файлов считывается короткими фрагментами, что, с одной стороны, замедляет обмен с базой данных, а с другой — перегружает канал связи короткими сообщениями. Сообщения более чем в 85% случаев оказываются короткими (менее 255 байт), что приводит к снижению скорости работы программы и оказывает негативное влияние на работу всей системы.
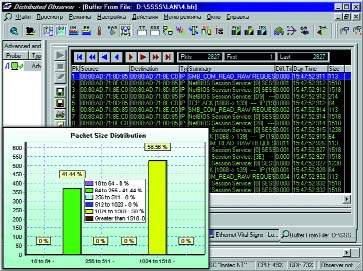 |
| Рисунок 4. Трасса обращений к серверу одной из рабочих станций при работе с базой данных при эффективном использовании канала связи. |
Надо заметить, что многие современные прикладные программы экономического и финансового назначения строятся на основе баз данных, использующих файлы *.DBF. В качестве системы управления базами данных для них выбираются обычно FoxPro, Clipper, Dbase и им подобные. Можно представить себе, какую нагрузку на канал связи дают подобные прикладные программы, а также каковы при этом скорость обработки информации и надежность работы, ведь для построения финансовых отчетов часто приходится обрабатывать не одну сотню мегабайт данных! Противоположный пример представлен на Рисунке 4. В этом случае программа достаточно эффективно использует канал связи. База данных состоит из нескольких больших файлов и имеет страничную организацию. Информация из базы данных читаются постранично, а так как размер страницы равен 4096 байт, каждая страница передается тремя кадрами длиной по 1518, 1518 и 1238 байт соответственно (кроме полезной кадры содержат также служебную информацию).
Теоретически, при увеличении размера страницы базы данных эффективность использования канала связи должна возрастать, так как данные будут передаваться более длинными сообщениями. Однако при этом возрастает и количество данных, переданных впустую, т. е. данных, содержащихся на переданной странице, но не используемых для работы. В указанной ситуации длина страницы может быть выбрана опытным путем. Здесь основным критерием эффективности будет скорость выполнения при одновременном функционировании определенного числа рабочих станций в локальной сети. Таким образом, прикладное ПО должно эффективно использовать канал связи между сервером и рабочей станцией, по возможности производя обмен данными достаточно длинными сообщениями.
На практике, однако, не всегда удается программным путем установить, сообщениями какой длины сервер обменивается с рабочими станциями, так как не все СУБД позволяют это сделать. В таком случае можно либо отказаться от используемой СУБД в пользу какой-либо другой, либо искать альтернативные варианты, или же просто закрыть глаза на некоторые проявления неоптимальной работы приложения.
ВМЕСТО ЗАКЛЮЧЕНИЯ
В данной статье описаны далеко не все проблемы, возникающие при эксплуатации прикладных программ, основанных на файл-серверной архитектуре. Обо всех задачах, которые приходится решать при оптимизации файл-серверного прикладного ПО, невозможно даже упомянуть в рамках отдельной статьи.
Тем не менее, если возникающие проблемы попытаться классифицировать по степени влияния на работоспособность прикладного ПО, их можно условно разделить на несколько уровней. В данной статье речь шла о верхнем уровне, т. е. о проблемах, без решения которых эффективная работа прикладного ПО просто невозможна.
Станислав Федоров — ведущий специалист «Инотек НТ», Никита Мельник — главный конструктор «Инотек НТ», Игорь Орлов — генеральный директор «Инотек НТ». С ними можно связаться по адресу: itb@inotec.ru.